
最新刊期
2019 年 第 24 卷 第 12 期
-
 摘要:目标跟踪是利用一个视频或图像序列的上下文信息,对目标的外观和运动信息进行建模,从而对目标运动状态进行预测并标定目标位置的一种技术,是计算机视觉的一个重要基础问题,具有重要的理论研究意义和应用价值,在智能视频监控系统、智能人机交互、智能交通和视觉导航系统等方面具有广泛应用。大数据时代的到来及深度学习方法的出现,为目标跟踪的研究提供了新的契机。本文首先阐述了目标跟踪的基本研究框架,从观测模型的角度对现有目标跟踪的历史进行回顾,指出深度学习为获得更为鲁棒的观测模型提供了可能;进而从深度判别模型、深度生成式模型等方面介绍了适用于目标跟踪的深度学习方法;从网络结构、功能划分和网络训练等几个角度对目前的深度目标跟踪方法进行分类并深入地阐述和分析了当前的深度目标跟踪方法;然后,补充介绍了其他一些深度目标跟踪方法,包括基于分类与回归融合的深度目标跟踪方法、基于强化学习的深度目标跟踪方法、基于集成学习的深度目标跟踪方法和基于元学习的深度目标跟踪方法等;之后,介绍了目前主要的适用于深度目标跟踪的数据库及其评测方法;接下来从移动端跟踪系统,基于检测与跟踪的系统等方面深入分析与总结了目标跟踪中的最新具体应用情况,最后对深度学习方法在目标跟踪中存在的训练数据不足、实时跟踪和长程跟踪等问题进行分析,并对未来的发展方向进行了展望。关键词:视觉目标跟踪;深度神经网络;相关滤波器;深度孪生网络;强化学习;生成对抗网络395|311|58更新时间:2024-05-07
摘要:目标跟踪是利用一个视频或图像序列的上下文信息,对目标的外观和运动信息进行建模,从而对目标运动状态进行预测并标定目标位置的一种技术,是计算机视觉的一个重要基础问题,具有重要的理论研究意义和应用价值,在智能视频监控系统、智能人机交互、智能交通和视觉导航系统等方面具有广泛应用。大数据时代的到来及深度学习方法的出现,为目标跟踪的研究提供了新的契机。本文首先阐述了目标跟踪的基本研究框架,从观测模型的角度对现有目标跟踪的历史进行回顾,指出深度学习为获得更为鲁棒的观测模型提供了可能;进而从深度判别模型、深度生成式模型等方面介绍了适用于目标跟踪的深度学习方法;从网络结构、功能划分和网络训练等几个角度对目前的深度目标跟踪方法进行分类并深入地阐述和分析了当前的深度目标跟踪方法;然后,补充介绍了其他一些深度目标跟踪方法,包括基于分类与回归融合的深度目标跟踪方法、基于强化学习的深度目标跟踪方法、基于集成学习的深度目标跟踪方法和基于元学习的深度目标跟踪方法等;之后,介绍了目前主要的适用于深度目标跟踪的数据库及其评测方法;接下来从移动端跟踪系统,基于检测与跟踪的系统等方面深入分析与总结了目标跟踪中的最新具体应用情况,最后对深度学习方法在目标跟踪中存在的训练数据不足、实时跟踪和长程跟踪等问题进行分析,并对未来的发展方向进行了展望。关键词:视觉目标跟踪;深度神经网络;相关滤波器;深度孪生网络;强化学习;生成对抗网络395|311|58更新时间:2024-05-07 -
 摘要:单幅图像深度估计是计算机视觉中的经典问题,对场景的3维重建、增强现实中的遮挡及光照处理具有重要意义。本文回顾了单幅图像深度估计技术的相关工作,介绍了单幅图像深度估计常用的数据集及模型方法。根据场景类型的不同,数据集可分为室内数据集、室外数据集与虚拟场景数据集。按照数学模型的不同,单目深度估计方法可分为基于传统机器学习的方法与基于深度学习的方法。基于传统机器学习的单目深度估计方法一般使用马尔可夫随机场(MRF)或条件随机场(CRF)对深度关系进行建模,在最大后验概率框架下,通过能量函数最小化求解深度。依据模型是否包含参数,该方法又可进一步分为参数学习方法与非参数学习方法,前者假定模型包含未知参数,训练过程即是对未知参数进行求解;后者使用现有的数据集进行相似性检索推测深度,不需要通过学习来获得参数。对于基于深度学习的单目深度估计方法本文详细阐述了国内外研究现状及优缺点,同时依据不同的分类标准,自底向上逐层级将其归类。第1层级为仅预测深度的单任务方法与同时预测深度及语义等信息的多任务方法。图片的深度和语义等信息关联密切,因此有部分工作研究多任务的联合预测方法。第2层级为绝对深度预测方法与相对深度关系预测方法。绝对深度是指场景中的物体到摄像机的实际距离,而相对深度关注图片中物体的相对远近关系。给定任意图片,人的视觉更擅于判断场景中物体的相对远近关系。第3层级包含有监督回归方法、有监督分类方法及无监督方法。对于单张图片深度估计任务,大部分工作都关注绝对深度的预测,而早期的大多数方法采用有监督回归模型,即模型训练数据带有标签,且对连续的深度值进行回归拟合。考虑到场景由远及近的特性,也有用分类的思想解决深度估计问题的方法。有监督学习方法要求每幅RGB图像都有其对应的深度标签,而深度标签的采集通常需要深度相机或激光雷达,前者范围受限,后者成本昂贵。而且采集的原始深度标签通常是一些稀疏的点,不能与原图很好地匹配。因此不用深度标签的无监督估计方法是研究趋势,其基本思路是利用左右视图,结合对极几何与自动编码机的思想求解深度。关键词:机器学习;深度估计;3维重建;深度学习110|374|15更新时间:2024-05-07
摘要:单幅图像深度估计是计算机视觉中的经典问题,对场景的3维重建、增强现实中的遮挡及光照处理具有重要意义。本文回顾了单幅图像深度估计技术的相关工作,介绍了单幅图像深度估计常用的数据集及模型方法。根据场景类型的不同,数据集可分为室内数据集、室外数据集与虚拟场景数据集。按照数学模型的不同,单目深度估计方法可分为基于传统机器学习的方法与基于深度学习的方法。基于传统机器学习的单目深度估计方法一般使用马尔可夫随机场(MRF)或条件随机场(CRF)对深度关系进行建模,在最大后验概率框架下,通过能量函数最小化求解深度。依据模型是否包含参数,该方法又可进一步分为参数学习方法与非参数学习方法,前者假定模型包含未知参数,训练过程即是对未知参数进行求解;后者使用现有的数据集进行相似性检索推测深度,不需要通过学习来获得参数。对于基于深度学习的单目深度估计方法本文详细阐述了国内外研究现状及优缺点,同时依据不同的分类标准,自底向上逐层级将其归类。第1层级为仅预测深度的单任务方法与同时预测深度及语义等信息的多任务方法。图片的深度和语义等信息关联密切,因此有部分工作研究多任务的联合预测方法。第2层级为绝对深度预测方法与相对深度关系预测方法。绝对深度是指场景中的物体到摄像机的实际距离,而相对深度关注图片中物体的相对远近关系。给定任意图片,人的视觉更擅于判断场景中物体的相对远近关系。第3层级包含有监督回归方法、有监督分类方法及无监督方法。对于单张图片深度估计任务,大部分工作都关注绝对深度的预测,而早期的大多数方法采用有监督回归模型,即模型训练数据带有标签,且对连续的深度值进行回归拟合。考虑到场景由远及近的特性,也有用分类的思想解决深度估计问题的方法。有监督学习方法要求每幅RGB图像都有其对应的深度标签,而深度标签的采集通常需要深度相机或激光雷达,前者范围受限,后者成本昂贵。而且采集的原始深度标签通常是一些稀疏的点,不能与原图很好地匹配。因此不用深度标签的无监督估计方法是研究趋势,其基本思路是利用左右视图,结合对极几何与自动编码机的思想求解深度。关键词:机器学习;深度估计;3维重建;深度学习110|374|15更新时间:2024-05-07 - 摘要:航天科技是国家综合国力和科技实力的重要体现,而卫星遥感则是航天科技转化为生产力最直接、最现实的途径之一。遥感数据获取与分发、数据处理与信息提取是卫星遥感应用的两个基本步骤。随着国家民用空间基础设施规划中的遥感卫星体系稳步推进,以及商业卫星遥感的蓬勃发展,我国的卫星遥感数据获取能力呈现质量齐升之势。但同时,作为卫星遥感应用的基础设施和关键工具,遥感图像处理系统平台逐渐成为制约自主卫星数据应用和空间信息业务发展的重要因素之一。本文围绕卫星遥感对地观测主题,从卫星遥感数据获取能力、卫星遥感数据处理系统平台两方面,对国内外现状进行综述,在此基础上分析了卫星遥感的发展趋势。关键词:卫星遥感;图像处理;云计算;遥感应用89|148|20更新时间:2024-05-07
综述

-
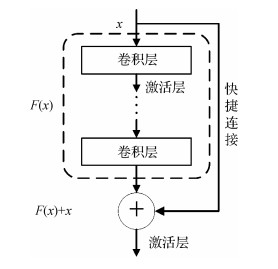 摘要:目的颜色恒常性通常指人类在任意光源条件下正确感知物体颜色的自适应能力,是实现识别、分割、3维视觉等高层任务的重要前提。对图像进行光源颜色估计是实现颜色恒常性计算的主要途径之一,现有光源颜色估计方法往往因局部场景的歧义颜色导致估计误差较大。为此,提出一种基于深度残差学习的光源颜色估计方法。方法将输入图像均匀分块,根据局部图像块的光源颜色估计整幅图像的全局光源颜色。算法包括光源颜色估计和图像块选择两个残差网络:光源颜色估计网络通过较深的网络层次和残差结构提高光源颜色估计的准确性;图像块选择网络按照光源颜色估计误差对图像块进行分类,根据分类结果去除图像中误差较大的图像块,进一步提高全局光源颜色估计精度。此外,对输入图像进行对数色度预处理,可以降低图像亮度对光源颜色估计的影响,提高计算效率。结果在NUS-8和重处理的ColorChecker数据集上的实验结果表明,本文方法的估计精度和稳健性较好;此外,在相同条件下,对数色度图像比原始图像的估计误差低10% 15%,图像块选择网络能够进一步使光源颜色估计网络的误差降低约5%。结论在两组单光源数据集上的实验表明,本文方法的总体设计合理有效,算法精度和稳健性好,可应用于需要进行色彩校正的图像处理和计算机视觉等领域。关键词:视觉光学;颜色恒常性;光源颜色估计;深度残差学习;对数色度35|35|3更新时间:2024-05-07
摘要:目的颜色恒常性通常指人类在任意光源条件下正确感知物体颜色的自适应能力,是实现识别、分割、3维视觉等高层任务的重要前提。对图像进行光源颜色估计是实现颜色恒常性计算的主要途径之一,现有光源颜色估计方法往往因局部场景的歧义颜色导致估计误差较大。为此,提出一种基于深度残差学习的光源颜色估计方法。方法将输入图像均匀分块,根据局部图像块的光源颜色估计整幅图像的全局光源颜色。算法包括光源颜色估计和图像块选择两个残差网络:光源颜色估计网络通过较深的网络层次和残差结构提高光源颜色估计的准确性;图像块选择网络按照光源颜色估计误差对图像块进行分类,根据分类结果去除图像中误差较大的图像块,进一步提高全局光源颜色估计精度。此外,对输入图像进行对数色度预处理,可以降低图像亮度对光源颜色估计的影响,提高计算效率。结果在NUS-8和重处理的ColorChecker数据集上的实验结果表明,本文方法的估计精度和稳健性较好;此外,在相同条件下,对数色度图像比原始图像的估计误差低10% 15%,图像块选择网络能够进一步使光源颜色估计网络的误差降低约5%。结论在两组单光源数据集上的实验表明,本文方法的总体设计合理有效,算法精度和稳健性好,可应用于需要进行色彩校正的图像处理和计算机视觉等领域。关键词:视觉光学;颜色恒常性;光源颜色估计;深度残差学习;对数色度35|35|3更新时间:2024-05-07 -
 摘要:目的搜索式无载体信息隐藏容量小、搜索量大,涉及大量载体密集传输;纹理构造式隐藏只能生成简单非自然纹理;纹理合成式隐藏存在固定映射以及编码、非编码小块的明显区别特征,且未考虑样本小块差异度和遭受攻击时的类别提取错误,抵抗攻击能力十分有限。针对以上问题,提出一种差异聚类和误差纹理合成的生成式信息隐藏。方法在嵌入时,通过差异均值聚类获取编码样本小块,结合多重映射将代表秘密信息的编码样本小块随机放置在空白图像上,按最小误差优先拼接策略生成含密纹理。在提取时,通过密钥截取样本小块,寻找最接近编码样本小块,并结合秘密信息MD5(message-digest algorithm 5)值和随机坐标来恢复秘密信息。结果所提方法与MD5值和密钥紧密绑定,密钥参数、MD5值以及样例图的改变都将导致秘密信息的提取误码率趋近于0.5。同现有方法相比,结合最小误差优先拼接策略,所提方法的像素累计差异更小,含密纹理视觉质量较好且对密钥极度敏感,以实验样本为例,当遭受质量因子为5070的JPEG压缩和5% 15%的椒盐噪声攻击时,秘密信息可完整提取。即使遭受25% 40%的椒盐噪声攻击,提取误码率低于7%。结论所提方法避免了固定映射和编码、非编码小块的区别特征,含密掩体视觉质量较好且具有较强的抗攻击能力。关键词:差异聚类;纹理生成;信息隐藏;最小误差;图像缝合;样例纹理合成28|148|2更新时间:2024-05-07
摘要:目的搜索式无载体信息隐藏容量小、搜索量大,涉及大量载体密集传输;纹理构造式隐藏只能生成简单非自然纹理;纹理合成式隐藏存在固定映射以及编码、非编码小块的明显区别特征,且未考虑样本小块差异度和遭受攻击时的类别提取错误,抵抗攻击能力十分有限。针对以上问题,提出一种差异聚类和误差纹理合成的生成式信息隐藏。方法在嵌入时,通过差异均值聚类获取编码样本小块,结合多重映射将代表秘密信息的编码样本小块随机放置在空白图像上,按最小误差优先拼接策略生成含密纹理。在提取时,通过密钥截取样本小块,寻找最接近编码样本小块,并结合秘密信息MD5(message-digest algorithm 5)值和随机坐标来恢复秘密信息。结果所提方法与MD5值和密钥紧密绑定,密钥参数、MD5值以及样例图的改变都将导致秘密信息的提取误码率趋近于0.5。同现有方法相比,结合最小误差优先拼接策略,所提方法的像素累计差异更小,含密纹理视觉质量较好且对密钥极度敏感,以实验样本为例,当遭受质量因子为5070的JPEG压缩和5% 15%的椒盐噪声攻击时,秘密信息可完整提取。即使遭受25% 40%的椒盐噪声攻击,提取误码率低于7%。结论所提方法避免了固定映射和编码、非编码小块的区别特征,含密掩体视觉质量较好且具有较强的抗攻击能力。关键词:差异聚类;纹理生成;信息隐藏;最小误差;图像缝合;样例纹理合成28|148|2更新时间:2024-05-07 -
 摘要:目的在日常的图像采集工作中,由于场景光照条件差或设备的补光能力不足,容易产生低照度图像。为了解决低照度图像视觉感受差、信噪比低和使用价值低(难以分辨图像内容)等问题,本文提出一种基于条件生成对抗网络的低照度图像增强方法。方法本文设计一个具备编解码功能的卷积神经网络(CNN)模型作为生成模型,同时加入具备二分类功能的CNN作为判别模型,组成生成对抗网络。在模型训练的过程中,以真实的亮图像为条件,依靠判别模型监督生成模型以及结合判别模型与生成模型间的相互博弈,使得本文网络模型具备更好的低照度图像增强能力。在本文方法使用过程中,无需人工调节参数,图像输入模型后端到端处理并输出结果。结果将本文方法与现有方法进行比较,利用本文方法增强的图像在亮度、清晰度以及颜色还原度等方面有了较大的提升。在峰值信噪比、直方图相似度和结构相似性等图像质量评价指标方面,本文方法比其他方法的最优值分别提高了0.7 dB、3.9%和8.2%。在处理时间上,本文方法处理图像的速度远远超过现有的传统方法,可达到实时增强的要求。结论通过实验比较了本文方法与现有方法对于低照度图像的处理效果,表明本文方法具有更优的处理效果,同时具有更快的处理速度。关键词:图像处理;低照度图像增强;卷积神经网络;条件生成对抗网络;深度学习37|134|10更新时间:2024-05-07
摘要:目的在日常的图像采集工作中,由于场景光照条件差或设备的补光能力不足,容易产生低照度图像。为了解决低照度图像视觉感受差、信噪比低和使用价值低(难以分辨图像内容)等问题,本文提出一种基于条件生成对抗网络的低照度图像增强方法。方法本文设计一个具备编解码功能的卷积神经网络(CNN)模型作为生成模型,同时加入具备二分类功能的CNN作为判别模型,组成生成对抗网络。在模型训练的过程中,以真实的亮图像为条件,依靠判别模型监督生成模型以及结合判别模型与生成模型间的相互博弈,使得本文网络模型具备更好的低照度图像增强能力。在本文方法使用过程中,无需人工调节参数,图像输入模型后端到端处理并输出结果。结果将本文方法与现有方法进行比较,利用本文方法增强的图像在亮度、清晰度以及颜色还原度等方面有了较大的提升。在峰值信噪比、直方图相似度和结构相似性等图像质量评价指标方面,本文方法比其他方法的最优值分别提高了0.7 dB、3.9%和8.2%。在处理时间上,本文方法处理图像的速度远远超过现有的传统方法,可达到实时增强的要求。结论通过实验比较了本文方法与现有方法对于低照度图像的处理效果,表明本文方法具有更优的处理效果,同时具有更快的处理速度。关键词:图像处理;低照度图像增强;卷积神经网络;条件生成对抗网络;深度学习37|134|10更新时间:2024-05-07
图像处理和编码
-
 摘要:目的复杂背景中的红外小目标检测易受背景杂波与噪声的干扰,直接利用现有的低秩约束与稀疏表示联合模型存在准确率低、虚警率高及检测速度慢等不足。为了解决这些问题,提出一种基于多尺度红外超像素图像模型的小目标检测方法。方法首先,采用超像素方法分割原始红外图像,得到无重叠区域的超像素图像,充分利用红外图像的局部空间相关性;然后,引入多尺度理论,融合多个不同尺度下检测的目标图像,增强该方法检测不同尺寸目标的稳健性。结果针对多幅不同场景下的红外小目标图像进行了实验验证,并选取信杂比增益、背景抑制因子及检测时间作为定量评价指标,以此衡量背景抑制效果及算法运行速度。大量实验结果表明,与Top-Hat、Max-Median、二维最小均方、局部显著性图、红外块图像、加权红外块图像等方法相比,本文方法能有效地去除各种干扰,在背景抑制方面具有更好的效果,且所得背景抑制因子为其他方法的数十倍;与同类方法相比,红外超像素图像模型减少了至少78.2%的检测时间。结论本文将超像素图像分割与多尺度理论引入低秩约束与稀疏表示联合模型,能够取得更好的背景抑制效果,并且可以适应不同大小目标的检测,实现复杂背景中红外小目标的准确检测。关键词:小目标检测;红外图像;低秩约束;稀疏表示;超像素;多尺度56|88|2更新时间:2024-05-07
摘要:目的复杂背景中的红外小目标检测易受背景杂波与噪声的干扰,直接利用现有的低秩约束与稀疏表示联合模型存在准确率低、虚警率高及检测速度慢等不足。为了解决这些问题,提出一种基于多尺度红外超像素图像模型的小目标检测方法。方法首先,采用超像素方法分割原始红外图像,得到无重叠区域的超像素图像,充分利用红外图像的局部空间相关性;然后,引入多尺度理论,融合多个不同尺度下检测的目标图像,增强该方法检测不同尺寸目标的稳健性。结果针对多幅不同场景下的红外小目标图像进行了实验验证,并选取信杂比增益、背景抑制因子及检测时间作为定量评价指标,以此衡量背景抑制效果及算法运行速度。大量实验结果表明,与Top-Hat、Max-Median、二维最小均方、局部显著性图、红外块图像、加权红外块图像等方法相比,本文方法能有效地去除各种干扰,在背景抑制方面具有更好的效果,且所得背景抑制因子为其他方法的数十倍;与同类方法相比,红外超像素图像模型减少了至少78.2%的检测时间。结论本文将超像素图像分割与多尺度理论引入低秩约束与稀疏表示联合模型,能够取得更好的背景抑制效果,并且可以适应不同大小目标的检测,实现复杂背景中红外小目标的准确检测。关键词:小目标检测;红外图像;低秩约束;稀疏表示;超像素;多尺度56|88|2更新时间:2024-05-07 -
 摘要:目的水岸线既是水利行业视频监控分析的基础,也是无人水面艇实现自主航行的关键。现有的许多水岸线检测的图像识别方法,不仅无法克服水面波纹、水面倒影等因素的影响,而且不具有适应性,无法同时适用于多个水岸场景分析。为此,本文采用多个复杂的水岸场景图像,训练了用于水岸分割的Deeplab v3+网络,并综合考虑分割性能和计算速度,对Deeplab v3+进行简化与改进,提出了基于改进的Deeplab v3+分割水面图像提取水岸线的检测方法。方法采集不同水岸场景图像作为训练及验证图集,并利用伽马函数扩充样本;接着修改Deeplab v3+网络,对xception结构进行微调,同时在decoder时多增加一路低级特征(low-level feature),增加特征信息;然后依据图像信息设置损失权重系数,设置可视化参数,基于改进的Deeplab v3+网络针对自己的数据集进行训练。利用训练好的PB模型在Linux操作系统调用TensorFlow的C++接口对测试图像进行区域分割。最后基于提取出的水面区域通过边缘检测算子检测水岸线,将水岸线叠加到原图。结果本文采集了不同光照强度、不同波纹程度以及不同阴影程度的水面图像进行水岸线检测实验,并与现有算法进行比较。实验结果表明本文算法可以在不同的水岸图像中检测出较为清晰完整的水岸线,准确率达93.98%,实时性达到8帧/s。结论本文算法能克服水岸边缘严重不规则、不同水岸场景差异大和复杂水岸场景中光照、波纹、倒影等因素的干扰,提升水岸图像分割准确度及效率,检测出轮廓清晰完整的水岸线,服务于水利行业的智能监控分析。关键词:水利视频监控;Deeplab v3+;水岸图像分割;边缘检测;水岸线检测15|5|2更新时间:2024-05-07
摘要:目的水岸线既是水利行业视频监控分析的基础,也是无人水面艇实现自主航行的关键。现有的许多水岸线检测的图像识别方法,不仅无法克服水面波纹、水面倒影等因素的影响,而且不具有适应性,无法同时适用于多个水岸场景分析。为此,本文采用多个复杂的水岸场景图像,训练了用于水岸分割的Deeplab v3+网络,并综合考虑分割性能和计算速度,对Deeplab v3+进行简化与改进,提出了基于改进的Deeplab v3+分割水面图像提取水岸线的检测方法。方法采集不同水岸场景图像作为训练及验证图集,并利用伽马函数扩充样本;接着修改Deeplab v3+网络,对xception结构进行微调,同时在decoder时多增加一路低级特征(low-level feature),增加特征信息;然后依据图像信息设置损失权重系数,设置可视化参数,基于改进的Deeplab v3+网络针对自己的数据集进行训练。利用训练好的PB模型在Linux操作系统调用TensorFlow的C++接口对测试图像进行区域分割。最后基于提取出的水面区域通过边缘检测算子检测水岸线,将水岸线叠加到原图。结果本文采集了不同光照强度、不同波纹程度以及不同阴影程度的水面图像进行水岸线检测实验,并与现有算法进行比较。实验结果表明本文算法可以在不同的水岸图像中检测出较为清晰完整的水岸线,准确率达93.98%,实时性达到8帧/s。结论本文算法能克服水岸边缘严重不规则、不同水岸场景差异大和复杂水岸场景中光照、波纹、倒影等因素的干扰,提升水岸图像分割准确度及效率,检测出轮廓清晰完整的水岸线,服务于水利行业的智能监控分析。关键词:水利视频监控;Deeplab v3+;水岸图像分割;边缘检测;水岸线检测15|5|2更新时间:2024-05-07 -
 摘要:目的基于深度学习的目标跟踪算法,利用卷积深层作为特征,虽然精度高但无法做到实时跟踪;基于相关滤波的跟踪算法,利用HOG(histogram of oriented gridients)、CN(color name)和颜色直方图作为特征,速度快但精度较差。为兼顾目标跟踪算法的实时性与准确性,提出了一种基于双模型核相关滤波算法。方法提出了自适应的双特征模型选择机制,主特征模型采用浅层纹理特征HOG,辅助特征模型采用包含深层语意信息的CNN(convolutional neural networks)特征,二者协同作用,产生更加稳定的相关滤波器。为了提高算法的速度,采用主成分分析(PCA)技术对高维的CNN特征进行降维,并通过尺度优化、最优解求解方式优化等方法提高跟踪算法的准确性。结果在公开数据集OTB-2013上,本文算法与目前先进且速度能达到实时的SiamFC(fully-convolutional Siamese networks)、MEEM(multiple experts using entropy minimization)、SAMF(scale adaptive multiple features)、DSST(discriminative scale space tracking)等跟踪算法进行比较,一次成功率(OPE)结果显示,本文算法在距离精准度指标中综合排名第一,与KCF(kernel correlation filter)算法相比,本文算法的距离精准度提高了25.2%,重叠成功率提高了25.6%,平均速度达到38帧/s。结论本文提出的双模型自适应机制,针对主特征模型的置信响应自适应调用最优模型策略,并且实时更新模型,在综合考虑跟踪准确性和跟踪实时性的情况下,本文提出的目标跟踪算法的性能优于目前的跟踪算法。关键词:目标跟踪;自适应特征;卷积神经网络;相关滤波;主成分分析12|4|2更新时间:2024-05-07
摘要:目的基于深度学习的目标跟踪算法,利用卷积深层作为特征,虽然精度高但无法做到实时跟踪;基于相关滤波的跟踪算法,利用HOG(histogram of oriented gridients)、CN(color name)和颜色直方图作为特征,速度快但精度较差。为兼顾目标跟踪算法的实时性与准确性,提出了一种基于双模型核相关滤波算法。方法提出了自适应的双特征模型选择机制,主特征模型采用浅层纹理特征HOG,辅助特征模型采用包含深层语意信息的CNN(convolutional neural networks)特征,二者协同作用,产生更加稳定的相关滤波器。为了提高算法的速度,采用主成分分析(PCA)技术对高维的CNN特征进行降维,并通过尺度优化、最优解求解方式优化等方法提高跟踪算法的准确性。结果在公开数据集OTB-2013上,本文算法与目前先进且速度能达到实时的SiamFC(fully-convolutional Siamese networks)、MEEM(multiple experts using entropy minimization)、SAMF(scale adaptive multiple features)、DSST(discriminative scale space tracking)等跟踪算法进行比较,一次成功率(OPE)结果显示,本文算法在距离精准度指标中综合排名第一,与KCF(kernel correlation filter)算法相比,本文算法的距离精准度提高了25.2%,重叠成功率提高了25.6%,平均速度达到38帧/s。结论本文提出的双模型自适应机制,针对主特征模型的置信响应自适应调用最优模型策略,并且实时更新模型,在综合考虑跟踪准确性和跟踪实时性的情况下,本文提出的目标跟踪算法的性能优于目前的跟踪算法。关键词:目标跟踪;自适应特征;卷积神经网络;相关滤波;主成分分析12|4|2更新时间:2024-05-07 -
 摘要:目的针对基于区域的语义分割方法在进行语义分割时容易缺失细节信息,造成图像语义分割结果粗糙、准确度低的问题,提出结合上下文特征与卷积神经网络(CNN)多层特征融合的语义分割方法。方法首先,采用选择搜索方法从图像中生成不同尺度的候选区域,得到区域特征掩膜;其次,采用卷积神经网络提取每个区域的特征,并行融合高层特征与低层特征。由于不同层提取的特征图大小不同,采用RefineNet模型将不同分辨率的特征图进行融合;最后将区域特征掩膜和融合后的特征图输入到自由形式感兴趣区域池化层,经过softmax分类层得到图像的像素级分类标签。结果采用上下文特征与CNN多层特征融合作为算法的基本框架,得到了较好的性能,实验内容主要包括CNN多层特征融合、结合背景信息和融合特征以及dropout值对实验结果的影响分析,在Siftflow数据集上进行测试,像素准确率达到82.3%,平均准确率达到63.1%。与当前基于区域的端到端语义分割模型相比,像素准确率提高了10.6%,平均准确率提高了0.6%。结论本文算法结合了区域的前景信息和上下文信息,充分利用了区域的语境信息,采用弃权原则降低网络的参数量,避免过拟合,同时利用RefineNet网络模型对CNN多层特征进行融合,有效地将图像的多层细节信息用于分割,增强了模型对于区域中小目标物体的判别能力,对于有遮挡和复杂背景的图像表现出较好的分割效果。关键词:语义分割;卷积神经网络;特征融合;选择搜索;RefineNet模型13|4|2更新时间:2024-05-07
摘要:目的针对基于区域的语义分割方法在进行语义分割时容易缺失细节信息,造成图像语义分割结果粗糙、准确度低的问题,提出结合上下文特征与卷积神经网络(CNN)多层特征融合的语义分割方法。方法首先,采用选择搜索方法从图像中生成不同尺度的候选区域,得到区域特征掩膜;其次,采用卷积神经网络提取每个区域的特征,并行融合高层特征与低层特征。由于不同层提取的特征图大小不同,采用RefineNet模型将不同分辨率的特征图进行融合;最后将区域特征掩膜和融合后的特征图输入到自由形式感兴趣区域池化层,经过softmax分类层得到图像的像素级分类标签。结果采用上下文特征与CNN多层特征融合作为算法的基本框架,得到了较好的性能,实验内容主要包括CNN多层特征融合、结合背景信息和融合特征以及dropout值对实验结果的影响分析,在Siftflow数据集上进行测试,像素准确率达到82.3%,平均准确率达到63.1%。与当前基于区域的端到端语义分割模型相比,像素准确率提高了10.6%,平均准确率提高了0.6%。结论本文算法结合了区域的前景信息和上下文信息,充分利用了区域的语境信息,采用弃权原则降低网络的参数量,避免过拟合,同时利用RefineNet网络模型对CNN多层特征进行融合,有效地将图像的多层细节信息用于分割,增强了模型对于区域中小目标物体的判别能力,对于有遮挡和复杂背景的图像表现出较好的分割效果。关键词:语义分割;卷积神经网络;特征融合;选择搜索;RefineNet模型13|4|2更新时间:2024-05-07 -
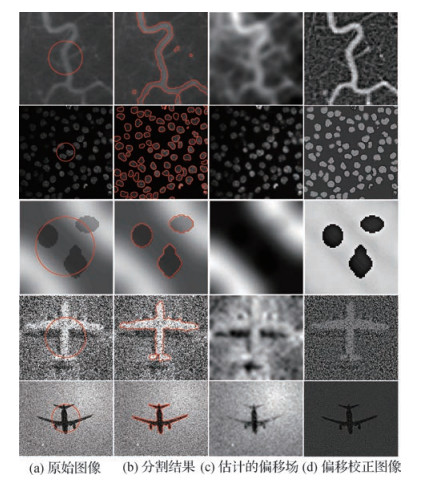 摘要:目的由于灰度不均匀图像在不同目标区域的灰度分布存在严重的重叠,对其进行分割仍然是一个难题;同时,图像中的噪声严重降低了图像分割的准确性。因此,传统水平集方法无法鲁棒、精确、快速地对具有灰度不均匀性和噪声的图像进行分割。针对这一问题,提出一种基于局部区域信息的快速水平集图像分割方法。方法灰度不均匀图像通常被描述为一个分段常数图像乘以一个缓慢变化的偏移场。首先,通过一个经过微调的多尺度均值滤波器来估计图像的偏移场,并对图像进行预处理以减轻图像的不均匀性;然后,利用基于偏移场校正的方法和基于局部区域信息拟合的方法分别构建能量项,并利用演化曲线轮廓内外图像灰度分布的重叠程度,构建权重函数自适应调整两个能量项之间的权重;最后,引入全方差规则项对水平集进行约束,增强了数值计算的稳定性和对噪声的鲁棒性,并通过加性算子分裂策略实现水平集快速演化。结果在具有不同灰度不均匀性和噪声图像上的分割结果表明,所提方法不但对初始轮廓的位置、灰度不均匀性和各种噪声具有较强的鲁棒性,而且具有高达94.5%的分割精度和较高的分割效率,与传统水平集方法相比分割精度至少提高了20.6%,分割效率是LIC(local intensity clustering)模型的9倍;结论本文提出一种基于局部区域信息的快速水平集图像分割方法。实验结果表明,与传统水平集方法相比具有较高的分割精度和分割效率,可以很好地应用于具有灰度不均匀和噪声的医学、红外和自然图像等的分割。关键词:图像分割;快速水平集方法;灰度不均匀;多尺度均值滤波;局部区域信息11|4|0更新时间:2024-05-07
摘要:目的由于灰度不均匀图像在不同目标区域的灰度分布存在严重的重叠,对其进行分割仍然是一个难题;同时,图像中的噪声严重降低了图像分割的准确性。因此,传统水平集方法无法鲁棒、精确、快速地对具有灰度不均匀性和噪声的图像进行分割。针对这一问题,提出一种基于局部区域信息的快速水平集图像分割方法。方法灰度不均匀图像通常被描述为一个分段常数图像乘以一个缓慢变化的偏移场。首先,通过一个经过微调的多尺度均值滤波器来估计图像的偏移场,并对图像进行预处理以减轻图像的不均匀性;然后,利用基于偏移场校正的方法和基于局部区域信息拟合的方法分别构建能量项,并利用演化曲线轮廓内外图像灰度分布的重叠程度,构建权重函数自适应调整两个能量项之间的权重;最后,引入全方差规则项对水平集进行约束,增强了数值计算的稳定性和对噪声的鲁棒性,并通过加性算子分裂策略实现水平集快速演化。结果在具有不同灰度不均匀性和噪声图像上的分割结果表明,所提方法不但对初始轮廓的位置、灰度不均匀性和各种噪声具有较强的鲁棒性,而且具有高达94.5%的分割精度和较高的分割效率,与传统水平集方法相比分割精度至少提高了20.6%,分割效率是LIC(local intensity clustering)模型的9倍;结论本文提出一种基于局部区域信息的快速水平集图像分割方法。实验结果表明,与传统水平集方法相比具有较高的分割精度和分割效率,可以很好地应用于具有灰度不均匀和噪声的医学、红外和自然图像等的分割。关键词:图像分割;快速水平集方法;灰度不均匀;多尺度均值滤波;局部区域信息11|4|0更新时间:2024-05-07 -
 摘要:目的在脑部肿瘤图像的分析过程中,准确分割出肿瘤区域对于计算机辅助脑部肿瘤疾病的诊断及治疗过程具有重要意义。然而,由于脑部图像常存在结构复杂、边界模糊、灰度不均以及肿瘤内部存在明暗区域的问题,使得肿瘤图像分割工作面临严峻挑战。为了克服上述困难,更好地实现脑部肿瘤图像分割,提出一种基于稀疏形状先验的脑肿瘤图像分割算法。方法首先,研究脑部肿瘤图像的配准与形状描述,并以此为基础构建脑部肿瘤的稀疏形状先验约束模型;继而,将该稀疏形状先验约束模型与区域能量描述方法相结合,构建基于稀疏形状先验的能量函数;最后,对能量函数进行优化及迭代,输出脑部肿瘤区域分割结果。结果本文使用脑胶质瘤公开数据集BraTS2017进行算法测试,本文算法的分割结果与真实数据之间的平均相似度达到93.97%,灵敏度达到91.3%,阳性预测率达到95.9%。本文算法的实验准确度较高,误判率较低,鲁棒性较强。结论本文算法能够结合水平集方法在拓扑结构描述和稀疏表达方法在复杂形状表达方面的优势,同时由于加入了形状约束,能够有效削弱肿瘤内部明暗区域对分割结果造成的影响,从而更准确和稳定地实现脑部肿瘤图像分割。关键词:脑肿瘤;图像分割;稀疏约束;形状先验;水平集31|51|2更新时间:2024-05-07
摘要:目的在脑部肿瘤图像的分析过程中,准确分割出肿瘤区域对于计算机辅助脑部肿瘤疾病的诊断及治疗过程具有重要意义。然而,由于脑部图像常存在结构复杂、边界模糊、灰度不均以及肿瘤内部存在明暗区域的问题,使得肿瘤图像分割工作面临严峻挑战。为了克服上述困难,更好地实现脑部肿瘤图像分割,提出一种基于稀疏形状先验的脑肿瘤图像分割算法。方法首先,研究脑部肿瘤图像的配准与形状描述,并以此为基础构建脑部肿瘤的稀疏形状先验约束模型;继而,将该稀疏形状先验约束模型与区域能量描述方法相结合,构建基于稀疏形状先验的能量函数;最后,对能量函数进行优化及迭代,输出脑部肿瘤区域分割结果。结果本文使用脑胶质瘤公开数据集BraTS2017进行算法测试,本文算法的分割结果与真实数据之间的平均相似度达到93.97%,灵敏度达到91.3%,阳性预测率达到95.9%。本文算法的实验准确度较高,误判率较低,鲁棒性较强。结论本文算法能够结合水平集方法在拓扑结构描述和稀疏表达方法在复杂形状表达方面的优势,同时由于加入了形状约束,能够有效削弱肿瘤内部明暗区域对分割结果造成的影响,从而更准确和稳定地实现脑部肿瘤图像分割。关键词:脑肿瘤;图像分割;稀疏约束;形状先验;水平集31|51|2更新时间:2024-05-07 -
 摘要:目的在视觉引导的工业机器人自动拾取研究中,关键技术难点之一是机器人抓取目标区域的识别问题。特别是金属零件,其表面的反光、随意摆放时相互遮挡等非结构化因素都给抓取区域的识别带来巨大的挑战。因此,本文提出一种结合深度学习和支持向量机的抓取区域识别方法。方法分别提取抓取区域的方向梯度直方图(HOG)和局部二进制模式(LBP)特征,利用主成分分析法(PCA)对融合后的特征进行降维,以此来训练支持向量机(SVM)分类器。通过训练Mask R-CNN(regions with convolutional neural network)神经网络完成抓取区域的初步分割。然后利用SVM对Mask R-CNN识别的抓取区域进行二次分类,完成对干扰区域的剔除。最后计算掩码完成实例分割,以此达到对抓取区域的精确识别。结果对于随机摆放的铜质金属零件,本文算法与单一的Mask R-CNN及多特征融合的SVM算法就识别准确率、错检率、漏检率3个指标进行了比较,结果表明本文算法在识别准确率上较Mask R-CNN和SVM算法分别提高了7%和25%,同时有效降低了错检率与漏检率。结论本文算法结合了Mask R-CNN与SVM两种方法,对于反光和遮挡情况具有一定的鲁棒性,同时有效地提升了目标识别的准确率。关键词:目标识别;多特征融合;支持向量机;深度学习;实例分割22|6|4更新时间:2024-05-07
摘要:目的在视觉引导的工业机器人自动拾取研究中,关键技术难点之一是机器人抓取目标区域的识别问题。特别是金属零件,其表面的反光、随意摆放时相互遮挡等非结构化因素都给抓取区域的识别带来巨大的挑战。因此,本文提出一种结合深度学习和支持向量机的抓取区域识别方法。方法分别提取抓取区域的方向梯度直方图(HOG)和局部二进制模式(LBP)特征,利用主成分分析法(PCA)对融合后的特征进行降维,以此来训练支持向量机(SVM)分类器。通过训练Mask R-CNN(regions with convolutional neural network)神经网络完成抓取区域的初步分割。然后利用SVM对Mask R-CNN识别的抓取区域进行二次分类,完成对干扰区域的剔除。最后计算掩码完成实例分割,以此达到对抓取区域的精确识别。结果对于随机摆放的铜质金属零件,本文算法与单一的Mask R-CNN及多特征融合的SVM算法就识别准确率、错检率、漏检率3个指标进行了比较,结果表明本文算法在识别准确率上较Mask R-CNN和SVM算法分别提高了7%和25%,同时有效降低了错检率与漏检率。结论本文算法结合了Mask R-CNN与SVM两种方法,对于反光和遮挡情况具有一定的鲁棒性,同时有效地提升了目标识别的准确率。关键词:目标识别;多特征融合;支持向量机;深度学习;实例分割22|6|4更新时间:2024-05-07 -
 摘要:目的针对深度学习严重依赖大样本的问题,提出多源域混淆的双流深度迁移学习方法,提升了传统深度迁移学习中迁移特征的适用性。方法采用多源域的迁移策略,增大源域对目标域迁移特征的覆盖率。提出两阶段适配学习的方法,获得域不变的深层特征表示和域间分类器相似的识别结果,将自然光图像2维特征和深度图像3维特征进行融合,提高小样本数据特征维度的同时抑制了复杂背景对目标识别的干扰。此外,为改善小样本机器学习中分类器的识别性能,在传统的softmax损失中引入中心损失,增强分类损失函数的惩罚监督能力。结果在公开的少量手势样本数据集上进行对比实验,结果表明,相对于传统的识别模型和迁移模型,基于本文模型进行识别准确率更高,在以DenseNet-169为预训练网络的模型中,识别率达到了97.17%。结论利用多源域数据集、两阶段适配学习、双流卷积融合以及复合损失函数,构建了多源域混淆的双流深度迁移学习模型。所提模型可增大源域和目标域的数据分布匹配率、丰富目标样本特征维度、提升损失函数的监督性能,改进任意小样本场景迁移特征的适用性。关键词:小样本;迁移学习;多源域;双流卷积融合;域混淆12|4|0更新时间:2024-05-07
摘要:目的针对深度学习严重依赖大样本的问题,提出多源域混淆的双流深度迁移学习方法,提升了传统深度迁移学习中迁移特征的适用性。方法采用多源域的迁移策略,增大源域对目标域迁移特征的覆盖率。提出两阶段适配学习的方法,获得域不变的深层特征表示和域间分类器相似的识别结果,将自然光图像2维特征和深度图像3维特征进行融合,提高小样本数据特征维度的同时抑制了复杂背景对目标识别的干扰。此外,为改善小样本机器学习中分类器的识别性能,在传统的softmax损失中引入中心损失,增强分类损失函数的惩罚监督能力。结果在公开的少量手势样本数据集上进行对比实验,结果表明,相对于传统的识别模型和迁移模型,基于本文模型进行识别准确率更高,在以DenseNet-169为预训练网络的模型中,识别率达到了97.17%。结论利用多源域数据集、两阶段适配学习、双流卷积融合以及复合损失函数,构建了多源域混淆的双流深度迁移学习模型。所提模型可增大源域和目标域的数据分布匹配率、丰富目标样本特征维度、提升损失函数的监督性能,改进任意小样本场景迁移特征的适用性。关键词:小样本;迁移学习;多源域;双流卷积融合;域混淆12|4|0更新时间:2024-05-07 -
 摘要:目的研究不同植物形态之间的相似度是有效区分植物种类或科属的一个重要依据。目前的植物形态相似度计算方法,大多只考虑了植物拓扑结构或者外围轮廓等几何形状方面的相似性,而未涉及叶片颜色、冠层叶片的稠密状态及株型的松散状态等因素。因此,基于植物图像的形状特征和颜色特征,本文提出一种基于图像特征的植物形态相似度计算方法。方法首先,获取图像的轮廓特征和区域特征。轮廓特征用植物枝条的松散程度表示,具体包括植物的高宽比、轮廓四边形和第1个1级侧枝的高度;区域特征用叶片稠密度表示,计算叶片所占整个包围矩形面积的比例。其次,获取图像的颜色特征,使用基于HSV和YUV颜色空间的颜色直方图,统计图像的颜色分布。最后,利用信息熵分析数据的离散程度,据此确定各部分对应的权重大小,加权得到总体的相似度值。结果实验在人工采集的数据集上进行,得出松散度、稠密度和颜色对应的权重分别为0.62、0.17和0.21。在此基础上得到的相似度计算结果符合实际,可以有效度量植物之间的相似程度。同时,将提出的算法应用于图像检索,并与常见的5种方法进行比较。实验得出该算法查准率都在0.747 7以上。在同一查准率水平下,相比于其他方法,查全率也都处于较高水平。尤其在相似度阈值大于0.8时,查准率可以达到0.910 8以上。另外,该方法对植物图像缩放不敏感,同类植物的相似度依然接近于1。结论本文提出的植物形态相似度算法,结合了形状特征和颜色特征,计算结果符合人的视觉感受。与其他方法相比,可以更有效区分植物种类或科属。算法主要适用于背景单一的单株植物图像,可为研究植物形态的相似性提供技术参考。关键词:植物形态;图像相似度;视觉特征;权重设置;信息熵17|4|3更新时间:2024-05-07
摘要:目的研究不同植物形态之间的相似度是有效区分植物种类或科属的一个重要依据。目前的植物形态相似度计算方法,大多只考虑了植物拓扑结构或者外围轮廓等几何形状方面的相似性,而未涉及叶片颜色、冠层叶片的稠密状态及株型的松散状态等因素。因此,基于植物图像的形状特征和颜色特征,本文提出一种基于图像特征的植物形态相似度计算方法。方法首先,获取图像的轮廓特征和区域特征。轮廓特征用植物枝条的松散程度表示,具体包括植物的高宽比、轮廓四边形和第1个1级侧枝的高度;区域特征用叶片稠密度表示,计算叶片所占整个包围矩形面积的比例。其次,获取图像的颜色特征,使用基于HSV和YUV颜色空间的颜色直方图,统计图像的颜色分布。最后,利用信息熵分析数据的离散程度,据此确定各部分对应的权重大小,加权得到总体的相似度值。结果实验在人工采集的数据集上进行,得出松散度、稠密度和颜色对应的权重分别为0.62、0.17和0.21。在此基础上得到的相似度计算结果符合实际,可以有效度量植物之间的相似程度。同时,将提出的算法应用于图像检索,并与常见的5种方法进行比较。实验得出该算法查准率都在0.747 7以上。在同一查准率水平下,相比于其他方法,查全率也都处于较高水平。尤其在相似度阈值大于0.8时,查准率可以达到0.910 8以上。另外,该方法对植物图像缩放不敏感,同类植物的相似度依然接近于1。结论本文提出的植物形态相似度算法,结合了形状特征和颜色特征,计算结果符合人的视觉感受。与其他方法相比,可以更有效区分植物种类或科属。算法主要适用于背景单一的单株植物图像,可为研究植物形态的相似性提供技术参考。关键词:植物形态;图像相似度;视觉特征;权重设置;信息熵17|4|3更新时间:2024-05-07
图像分析和识别
-
 摘要:目的有关艺术作品审美感受的量化或计算,在心理学上已有许多研究。近年来,人工智能的研究成为热点,而对人类感知的定量分析也随之受到极大关注,例如基于图片或者音乐内容的情感计算等。美感作为一种艺术化的审美情感,与之相关的定量研究有较大潜力。为便于进行中国文化背景下的审美研究,同时为丰富图像情感与审美计算相关研究的数据基础,需建立一个国画美感和情感分析所用的图像数据库。方法从多种渠道收集筛选511幅国画素材及350个国画美感形容词,通过词汇筛选和因子分析获得国画美感主要因子;采用离散词汇和PAD(pleasure-arousal-dominance)情感连续维度空间这两种描述方式对国画的审美感受进行标注;对数据库进行情感和美感的模式分类,从而验证其实用性。结果获得5个国画美感主要语义标签:气势、清幽、生机、雅致和萧瑟;标注数据结果满足有效性验证;不同美感的PAD情感分布呈现一定极化;经测试,情感分类精度平均可达0.68,美感分类精度最高可达0.77。结论本文得到的5个国画美感评价范畴,可基本概括国画的审美感受;所建立的数据库,能为视觉美感及情感的定量研究或者计算机视觉、实验美学等领域的研究提供有效数据基础;PAD分布对美感有较好区分性。下一步将进一步扩充数据库,以解决数据分布不均问题,同时进一步挖掘PAD分布与美感分布之间的关联。关键词:情感;美感;数据库;中国画31|11|3更新时间:2024-05-07
摘要:目的有关艺术作品审美感受的量化或计算,在心理学上已有许多研究。近年来,人工智能的研究成为热点,而对人类感知的定量分析也随之受到极大关注,例如基于图片或者音乐内容的情感计算等。美感作为一种艺术化的审美情感,与之相关的定量研究有较大潜力。为便于进行中国文化背景下的审美研究,同时为丰富图像情感与审美计算相关研究的数据基础,需建立一个国画美感和情感分析所用的图像数据库。方法从多种渠道收集筛选511幅国画素材及350个国画美感形容词,通过词汇筛选和因子分析获得国画美感主要因子;采用离散词汇和PAD(pleasure-arousal-dominance)情感连续维度空间这两种描述方式对国画的审美感受进行标注;对数据库进行情感和美感的模式分类,从而验证其实用性。结果获得5个国画美感主要语义标签:气势、清幽、生机、雅致和萧瑟;标注数据结果满足有效性验证;不同美感的PAD情感分布呈现一定极化;经测试,情感分类精度平均可达0.68,美感分类精度最高可达0.77。结论本文得到的5个国画美感评价范畴,可基本概括国画的审美感受;所建立的数据库,能为视觉美感及情感的定量研究或者计算机视觉、实验美学等领域的研究提供有效数据基础;PAD分布对美感有较好区分性。下一步将进一步扩充数据库,以解决数据分布不均问题,同时进一步挖掘PAD分布与美感分布之间的关联。关键词:情感;美感;数据库;中国画31|11|3更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的海量城市交通事故数据可能蕴含有交通事故的空间模式,挖掘出交通事故的空间模式有助于开展交通事故的防治工作。目前交通管理部门虽然记录了交通事故发生地的空间位置信息,但没有对事故发生地进行空间语义描述,从而影响对交通事故空间模式的深入分析。因此,提出一种交通事故数据空间语义增强方法,并设计了一套可视分析系统。方法基于城市兴趣点来增强交通事故数据的空间语义。以事故发生点为中心获取周围城市兴趣点,使用特征向量刻画兴趣点的数量、类别及其与事故发生点的距离,并称此向量为空间语义特征向量。将空间语义特征向量和相应的交通事故关联,以达到增强其空间语义的目的。然后,基于空间语义特征向量,使用自组织映射聚类算法对交通事故进行聚类分析,根据其空间语义特征将交通事故分为若干类别。最后,通过使用地图视图展示事故点数据、聚类视图和平行坐标视图展示聚类分析的结果及其空间语义特征的可视化方法,对交通事故的空间模式进行分析。结果针对空间语义增强的交通事故数据以及相关分析任务,有效地使用上述数据分析方法与可视化技术,设计并实现了一套多视图关联的可视分析系统,提供了便捷的交互方式辅助用户分析。通过研发人员和交通警察共同对安徽省合肥市2018年的交通事故数据进行分析,将交通事故发生地划分9类并指出每类地点的空间语义特点,进一步分析出了事故高发区域的空间语义特性。结论本文提出的交通事故数据空间语义增强方法和可视分析方法可以帮助用户揭示交通事故的空间语义模式,有助于深入分析和认识交通事故的成因,能为交通事故防治相关的城市建设工作提供建议。关键词:可视分析;交通事故;空间语义;兴趣点;自组织映射13|23|1更新时间:2024-05-07
摘要:目的海量城市交通事故数据可能蕴含有交通事故的空间模式,挖掘出交通事故的空间模式有助于开展交通事故的防治工作。目前交通管理部门虽然记录了交通事故发生地的空间位置信息,但没有对事故发生地进行空间语义描述,从而影响对交通事故空间模式的深入分析。因此,提出一种交通事故数据空间语义增强方法,并设计了一套可视分析系统。方法基于城市兴趣点来增强交通事故数据的空间语义。以事故发生点为中心获取周围城市兴趣点,使用特征向量刻画兴趣点的数量、类别及其与事故发生点的距离,并称此向量为空间语义特征向量。将空间语义特征向量和相应的交通事故关联,以达到增强其空间语义的目的。然后,基于空间语义特征向量,使用自组织映射聚类算法对交通事故进行聚类分析,根据其空间语义特征将交通事故分为若干类别。最后,通过使用地图视图展示事故点数据、聚类视图和平行坐标视图展示聚类分析的结果及其空间语义特征的可视化方法,对交通事故的空间模式进行分析。结果针对空间语义增强的交通事故数据以及相关分析任务,有效地使用上述数据分析方法与可视化技术,设计并实现了一套多视图关联的可视分析系统,提供了便捷的交互方式辅助用户分析。通过研发人员和交通警察共同对安徽省合肥市2018年的交通事故数据进行分析,将交通事故发生地划分9类并指出每类地点的空间语义特点,进一步分析出了事故高发区域的空间语义特性。结论本文提出的交通事故数据空间语义增强方法和可视分析方法可以帮助用户揭示交通事故的空间语义模式,有助于深入分析和认识交通事故的成因,能为交通事故防治相关的城市建设工作提供建议。关键词:可视分析;交通事故;空间语义;兴趣点;自组织映射13|23|1更新时间:2024-05-07
计算机图形学
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0