
最新刊期
2019 年 第 24 卷 第 10 期
-
 摘要:人群应急疏散可视仿真是用智能体来模拟具有自主感知、情绪和行为能力的人群个体,并采用3维可视的方式来直观呈现人群应急疏散情景,可以为制定人群应急预案提供形象直观的分析方法。本文从人群仿真数据的来源、人群导航模型的构建、人群行为模型、人群情绪感染、人群渲染5个方面概述目前研究的进展,然后从仿真模型的可验证性、人群疏散导航模型的构建、人与环境的物理模型、动物逃生实验与仿真、疏散中的社会行为表现以及人群情绪的可视计算6个角度讨论需要进一步研究的问题。针对需要深入研究的问题,指出借助于紧急事件的视频监控分析和虚拟人群情景的用户调查,有助于完善人群仿真模型。结合物理模型,可以更准确地描述人群应急疏散场景。开展动物逃生实验分析,有助于完善人群运动导航算法。建立人群社会行为模型,可以更详细描述疏散中人群行为的多样性。构建基于多通道感知的人群情绪感染计算方法,可以详尽描述情绪感染的过程。人群应急疏散行为的可视仿真研究在城市的安全管理方面具有重要的应用前景,但其研究仍存在很多亟待解决的问题,综合地运用多学科知识,完善实验手段是进一步推动研究的关键所在。关键词:人群应急疏散;可视仿真;情绪感染;人群行为;人群导航16|75|1更新时间:2024-05-07
摘要:人群应急疏散可视仿真是用智能体来模拟具有自主感知、情绪和行为能力的人群个体,并采用3维可视的方式来直观呈现人群应急疏散情景,可以为制定人群应急预案提供形象直观的分析方法。本文从人群仿真数据的来源、人群导航模型的构建、人群行为模型、人群情绪感染、人群渲染5个方面概述目前研究的进展,然后从仿真模型的可验证性、人群疏散导航模型的构建、人与环境的物理模型、动物逃生实验与仿真、疏散中的社会行为表现以及人群情绪的可视计算6个角度讨论需要进一步研究的问题。针对需要深入研究的问题,指出借助于紧急事件的视频监控分析和虚拟人群情景的用户调查,有助于完善人群仿真模型。结合物理模型,可以更准确地描述人群应急疏散场景。开展动物逃生实验分析,有助于完善人群运动导航算法。建立人群社会行为模型,可以更详细描述疏散中人群行为的多样性。构建基于多通道感知的人群情绪感染计算方法,可以详尽描述情绪感染的过程。人群应急疏散行为的可视仿真研究在城市的安全管理方面具有重要的应用前景,但其研究仍存在很多亟待解决的问题,综合地运用多学科知识,完善实验手段是进一步推动研究的关键所在。关键词:人群应急疏散;可视仿真;情绪感染;人群行为;人群导航16|75|1更新时间:2024-05-07
学者观点

-
 摘要:在烟雾检测系统中,采用机器学习的视觉技术暂未广泛替代传感器的主要原因在于其误报与漏报较高。计算力度的提高、存储设备的发展,使得传统视觉技术中存在的问题逐渐得到改善或解决,但也迎来了新的挑战。为反映用于森林火灾预警的烟雾识别、检测等技术的最新研究进展,本文重点对2017—2019年国内外公开发表的相关文献进行梳理和分析。从监控角度出发,基于对此领域的长期研究与广泛文献调研,将利用烟雾的森林火灾预警任务分为烟雾识别、检测、分割这3类不同的粒度,分别介绍实现这些任务的传统方法及深度方法。依照当前研究热度,主要关注视频烟雾检测与分割这两个细粒度任务。其中烟雾区域的粗提取与二次提取方法是检测与分割的关键,因此将探索这些方法如何提取、利用烟雾的动态与静态特征。此外,由于深度学习框架主要实现端对端的任务,无法分离出关键步骤,故对基于深度学习的烟雾监控任务进行单独梳理,不关注单步细节,主要体现文献思路。最后,对实现烟雾识别、检测、分割任务具体方法中的优缺点、烟雾监控任务中常用的指标、研究常用的数据库进行总结,并对发展前景进行展望。为基于烟雾的森林火灾预警技术提供更多的发展方向。关键词:烟雾识别;烟雾检测;烟雾分割;深度学习;综述79|154|10更新时间:2024-05-07
摘要:在烟雾检测系统中,采用机器学习的视觉技术暂未广泛替代传感器的主要原因在于其误报与漏报较高。计算力度的提高、存储设备的发展,使得传统视觉技术中存在的问题逐渐得到改善或解决,但也迎来了新的挑战。为反映用于森林火灾预警的烟雾识别、检测等技术的最新研究进展,本文重点对2017—2019年国内外公开发表的相关文献进行梳理和分析。从监控角度出发,基于对此领域的长期研究与广泛文献调研,将利用烟雾的森林火灾预警任务分为烟雾识别、检测、分割这3类不同的粒度,分别介绍实现这些任务的传统方法及深度方法。依照当前研究热度,主要关注视频烟雾检测与分割这两个细粒度任务。其中烟雾区域的粗提取与二次提取方法是检测与分割的关键,因此将探索这些方法如何提取、利用烟雾的动态与静态特征。此外,由于深度学习框架主要实现端对端的任务,无法分离出关键步骤,故对基于深度学习的烟雾监控任务进行单独梳理,不关注单步细节,主要体现文献思路。最后,对实现烟雾识别、检测、分割任务具体方法中的优缺点、烟雾监控任务中常用的指标、研究常用的数据库进行总结,并对发展前景进行展望。为基于烟雾的森林火灾预警技术提供更多的发展方向。关键词:烟雾识别;烟雾检测;烟雾分割;深度学习;综述79|154|10更新时间:2024-05-07 -
 摘要:目的检测烟雾可以预警火灾。视频监控烟雾比传统的单点探测器监控范围更广、反应更灵敏,对环境和安装的要求也更低。但是目前的烟雾检测算法,无论是利用烟雾的色彩、纹理等静态特征和飘动、形状变化或者频域变化等动态特征的传统方法,还是采用卷积神经网络、循环神经网络等深度学习的方法,准确率和敏感性都不高。方法本文着眼于烟雾的升腾特性,根据烟雾运动轨迹的右倾直线特性、连续流线型特性、低频特性、烟源固定特性和比例特性,采用切片的方式用卷积神经网络(CNN)抽取时间压缩轨迹的动态特征,用循环神经网络(RNN)抽取长程的时间关联关系,采用分块的方式提高空间分辨能力,能准确、迅速地识别烟雾轨迹并发出火灾预警。结果对比CNN、C3D(3d convolutional networks)、traj+SVM(trajectory by support vector machine)、traj+RNNs(trajectory by recurrent neural network)和本文方法traj+CNN+RNNs(trajectory by convolutional neural networks and recurrent neural network)以验证效果。CNN和C3D先卷积抽取特征,后分类。traj+SVM采用SVM辨识视频时间压缩图像中的烟雾轨迹,traj+RNNs采用RNNs分辨烟雾轨迹,traj+CNN+RNNs结合CNN和RNNs识别轨迹。实验表明,与traj+SVM相比,traj+CNN+RNNs准确率提高了35.2%,真负率提高15.6%。但是深度学习的方法往往计算消耗很大,traj+CNN+RNNs占用内存2.31 GB,网络权重261 MB,前向分析时帧率49帧/s,而traj+SVM帧率为178帧/s。但与CNN、C3D相比,本文方法较轻较快。为了进一步验证方法的有效性,采用一般方法难以识别的数据进一步测试对比这5个方法。实验结果表明,基于轨迹的方法仍然取得较好的效果,traj+CNN+RNNs的准确率、真正率、真负率和帧率还能达到0.853、0.847、0.872和52帧/s,但是CNN、C3D的准确率下降到0.585、0.716。结论从视频的时间压缩轨迹可以辨认出烟雾的轨迹,即便是早期的弱小烟雾也能准确识别,因此traj+CNN+RNNs辨识轨迹的方法有助于预警早期火灾。本文方法能够在较少的资源耗费下大幅度提高烟雾检测的准确性和敏感性。关键词:火灾;烟雾;时间压缩轨迹;特征识别;深度学习;循环神经网络22|43|3更新时间:2024-05-07
摘要:目的检测烟雾可以预警火灾。视频监控烟雾比传统的单点探测器监控范围更广、反应更灵敏,对环境和安装的要求也更低。但是目前的烟雾检测算法,无论是利用烟雾的色彩、纹理等静态特征和飘动、形状变化或者频域变化等动态特征的传统方法,还是采用卷积神经网络、循环神经网络等深度学习的方法,准确率和敏感性都不高。方法本文着眼于烟雾的升腾特性,根据烟雾运动轨迹的右倾直线特性、连续流线型特性、低频特性、烟源固定特性和比例特性,采用切片的方式用卷积神经网络(CNN)抽取时间压缩轨迹的动态特征,用循环神经网络(RNN)抽取长程的时间关联关系,采用分块的方式提高空间分辨能力,能准确、迅速地识别烟雾轨迹并发出火灾预警。结果对比CNN、C3D(3d convolutional networks)、traj+SVM(trajectory by support vector machine)、traj+RNNs(trajectory by recurrent neural network)和本文方法traj+CNN+RNNs(trajectory by convolutional neural networks and recurrent neural network)以验证效果。CNN和C3D先卷积抽取特征,后分类。traj+SVM采用SVM辨识视频时间压缩图像中的烟雾轨迹,traj+RNNs采用RNNs分辨烟雾轨迹,traj+CNN+RNNs结合CNN和RNNs识别轨迹。实验表明,与traj+SVM相比,traj+CNN+RNNs准确率提高了35.2%,真负率提高15.6%。但是深度学习的方法往往计算消耗很大,traj+CNN+RNNs占用内存2.31 GB,网络权重261 MB,前向分析时帧率49帧/s,而traj+SVM帧率为178帧/s。但与CNN、C3D相比,本文方法较轻较快。为了进一步验证方法的有效性,采用一般方法难以识别的数据进一步测试对比这5个方法。实验结果表明,基于轨迹的方法仍然取得较好的效果,traj+CNN+RNNs的准确率、真正率、真负率和帧率还能达到0.853、0.847、0.872和52帧/s,但是CNN、C3D的准确率下降到0.585、0.716。结论从视频的时间压缩轨迹可以辨认出烟雾的轨迹,即便是早期的弱小烟雾也能准确识别,因此traj+CNN+RNNs辨识轨迹的方法有助于预警早期火灾。本文方法能够在较少的资源耗费下大幅度提高烟雾检测的准确性和敏感性。关键词:火灾;烟雾;时间压缩轨迹;特征识别;深度学习;循环神经网络22|43|3更新时间:2024-05-07 -
 摘要:目的视频烟雾检测在火灾预警中起到重要作用,目前基于视频的烟雾检测方法主要利用结构化模型提取烟雾区域的静态和动态特征,在时间和空间上对烟雾信息作同等或相似处理,忽略了视频数据在时间线上的连续性和特征的非结构化关系。图卷积网络(GCN)与神经常微分方程(ODE)在非欧氏结构与连续模型处理上具有突出优势,因此将二者结合提出了一种基于视频流和连续时间域的图烟雾检测模型。方法目前主流的视频烟雾检测模型仍以离散模型为基础,以规则形式提取数据特征,利用ODE网络构建连续时间模型,捕捉视频帧间的隐藏信息,将原本固定时间跨度的视频帧作为连续时间轴上的样本点,充分利用模型的预测功能,补充帧间丢失信息并对未来帧进行一定程度的模拟预测,生成视频帧的特征并交给图卷积网络对其重新建模,最后使用全监督和弱监督两种方法对特征进行分类。结果分别在2个视频和4个图像数据集上进行训练与测试,并与最新的主流深度方法进行了比较,在KMU(Korea Maritime University)视频数据集中,相比于性能第2的模型,平均正样本正确率(ATPR值)提高了0.6%;在2个图像数据集中,相比于性能第2的模型,正确率分别提高了0.21%和0.06%,检测率分别提升了0.54%和0.28%,在视频单帧图像集上正确率高于第2名0.88%。同时也在Bilkent数据集中进行了对比实验,以验证连续隐态模型在烟雾动态和起烟点预测上的有效性,对比实验结果表明所提连续模型能够有效预测烟雾动态并推测烟雾起烟点位置。结论提出的连续图卷积模型,综合了结构化与非结构化模型的优势,能够获得烟雾动态信息,有效推测烟雾起烟点位置,使烟雾检测结果更加准确。关键词:视频烟雾检测;烟雾识别;图卷积网络;神经常微分方程;度量学习;弱监督学习23|42|2更新时间:2024-05-07
摘要:目的视频烟雾检测在火灾预警中起到重要作用,目前基于视频的烟雾检测方法主要利用结构化模型提取烟雾区域的静态和动态特征,在时间和空间上对烟雾信息作同等或相似处理,忽略了视频数据在时间线上的连续性和特征的非结构化关系。图卷积网络(GCN)与神经常微分方程(ODE)在非欧氏结构与连续模型处理上具有突出优势,因此将二者结合提出了一种基于视频流和连续时间域的图烟雾检测模型。方法目前主流的视频烟雾检测模型仍以离散模型为基础,以规则形式提取数据特征,利用ODE网络构建连续时间模型,捕捉视频帧间的隐藏信息,将原本固定时间跨度的视频帧作为连续时间轴上的样本点,充分利用模型的预测功能,补充帧间丢失信息并对未来帧进行一定程度的模拟预测,生成视频帧的特征并交给图卷积网络对其重新建模,最后使用全监督和弱监督两种方法对特征进行分类。结果分别在2个视频和4个图像数据集上进行训练与测试,并与最新的主流深度方法进行了比较,在KMU(Korea Maritime University)视频数据集中,相比于性能第2的模型,平均正样本正确率(ATPR值)提高了0.6%;在2个图像数据集中,相比于性能第2的模型,正确率分别提高了0.21%和0.06%,检测率分别提升了0.54%和0.28%,在视频单帧图像集上正确率高于第2名0.88%。同时也在Bilkent数据集中进行了对比实验,以验证连续隐态模型在烟雾动态和起烟点预测上的有效性,对比实验结果表明所提连续模型能够有效预测烟雾动态并推测烟雾起烟点位置。结论提出的连续图卷积模型,综合了结构化与非结构化模型的优势,能够获得烟雾动态信息,有效推测烟雾起烟点位置,使烟雾检测结果更加准确。关键词:视频烟雾检测;烟雾识别;图卷积网络;神经常微分方程;度量学习;弱监督学习23|42|2更新时间:2024-05-07
火情与烟雾专栏
-
 摘要:目的心率是反映人体心血管状况和心理状态的重要生理参数。最近的研究表明,光电容积成像技术可以在不接触人体的情况下,利用消费级的摄像机捕获面部表皮颜色的变化进而估计心率。然而,在实际环境中,面部运动带来的干扰会导致心率检测的准确性下降。近年来,国内外学者已经提出了一些方法来去除运动噪声,但是效果均不理想。为了解决上述问题,提出一种可以抗面部运动干扰的新方法。方法首先检测和跟踪受试者的脸部。然后将脸部区域分块,并提取各块的色度特征建立原始血液容积脉冲矩阵,利用自适应信号恢复算法从原始血液容积脉冲矩阵中分离出低秩矩阵并构建期望血液容积脉冲信号。最后通过功率谱密度估计心率。结果在环境光作为光源的条件下,利用网络摄像头采集30名受试者的人脸视频进行实验分析。结果显示,提出的方法测得的心率与参考值具有很强的相关性:在静态场景中皮尔森相关系数
摘要:目的心率是反映人体心血管状况和心理状态的重要生理参数。最近的研究表明,光电容积成像技术可以在不接触人体的情况下,利用消费级的摄像机捕获面部表皮颜色的变化进而估计心率。然而,在实际环境中,面部运动带来的干扰会导致心率检测的准确性下降。近年来,国内外学者已经提出了一些方法来去除运动噪声,但是效果均不理想。为了解决上述问题,提出一种可以抗面部运动干扰的新方法。方法首先检测和跟踪受试者的脸部。然后将脸部区域分块,并提取各块的色度特征建立原始血液容积脉冲矩阵,利用自适应信号恢复算法从原始血液容积脉冲矩阵中分离出低秩矩阵并构建期望血液容积脉冲信号。最后通过功率谱密度估计心率。结果在环境光作为光源的条件下,利用网络摄像头采集30名受试者的人脸视频进行实验分析。结果显示,提出的方法测得的心率与参考值具有很强的相关性:在静态场景中皮尔森相关系数$r$ $r$ 关键词:光电容积成像技术;面部运动;心率检测;自适应信号恢复(SSR);期望血液容积脉冲信号37|115|3更新时间:2024-05-07
图像处理和编码
-
 摘要:目的行人检测在自动驾驶、视频监控领域中有着广泛应用,是一个热门的研究话题。针对当前基于深度学习的行人检测算法在分辨率较低、行人尺度较小的情况下存在误检和漏检问题,提出一种融合多层特征的多尺度的行人检测算法。方法首先,针对行人检测问题,删除了深度残差网络的一部分,仅采用深度残差网络的3个区域提取特征图,然后采用最邻近上采样法将最后一层提取的特征图放大两倍后再用相加法,将高层语义信息丰富的特征和低层细节信息丰富的特征进行融合;最后将融合后的3层特征分别输入区域候选网络中,经过softmax分类,得到带有行人的候选框,从而实现行人检测的目的。结果实验结果表明,在Caltech行人检测数据集上,在每幅图像虚警率(FPPI)为10%的条件下,本文算法丢失率仅为57.88%,比最好的模型之一——多尺度卷积神经网络模型(MS-CNN)丢失率(60.95%)降低3.07%。结论深层的特征具有高语义信息且感受野较大的特点,而浅层的特征具有位置信息且感受野较小的特点,融合两者特征可以达到增强深层特征的效果,让深层的特征具有较为丰富的目标位置信息。融合后的多层特征图具有不同程度的细节和语义信息,对检测不同尺度的行人有较好的效果。所以利用融合后的特征进行行人检测,能够提高行人检测性能。关键词:目标检测;行人检测;特征融合;多尺度行人;多层特征37|303|5更新时间:2024-05-07
摘要:目的行人检测在自动驾驶、视频监控领域中有着广泛应用,是一个热门的研究话题。针对当前基于深度学习的行人检测算法在分辨率较低、行人尺度较小的情况下存在误检和漏检问题,提出一种融合多层特征的多尺度的行人检测算法。方法首先,针对行人检测问题,删除了深度残差网络的一部分,仅采用深度残差网络的3个区域提取特征图,然后采用最邻近上采样法将最后一层提取的特征图放大两倍后再用相加法,将高层语义信息丰富的特征和低层细节信息丰富的特征进行融合;最后将融合后的3层特征分别输入区域候选网络中,经过softmax分类,得到带有行人的候选框,从而实现行人检测的目的。结果实验结果表明,在Caltech行人检测数据集上,在每幅图像虚警率(FPPI)为10%的条件下,本文算法丢失率仅为57.88%,比最好的模型之一——多尺度卷积神经网络模型(MS-CNN)丢失率(60.95%)降低3.07%。结论深层的特征具有高语义信息且感受野较大的特点,而浅层的特征具有位置信息且感受野较小的特点,融合两者特征可以达到增强深层特征的效果,让深层的特征具有较为丰富的目标位置信息。融合后的多层特征图具有不同程度的细节和语义信息,对检测不同尺度的行人有较好的效果。所以利用融合后的特征进行行人检测,能够提高行人检测性能。关键词:目标检测;行人检测;特征融合;多尺度行人;多层特征37|303|5更新时间:2024-05-07 -
 摘要:目的基于图像的人体姿态估计是计算机视觉领域中一个非常重要的研究课题,并广泛应用于人机交互、监控以及图像检索等方面。但是,由于人体视觉外观的多样性、遮挡和混杂背景等因素的影响,导致人体姿态估计问题一直是计算机视觉领域的难点和热点。本文主要关注于初始特征对关节点定位的作用,提出一种跨阶段卷积姿态机(CSCPM)。方法首先,采用VGG(visual geometry group)网络获得初步的图像初始特征,该初始特征既是图像关节点定位的基础,同时,也由于受到自遮挡和混杂背景的干扰难以学习。其次,在初始特征的基础上,构建多层模型学习不同尺度下的结构特征,同时为了解决深度学习中的梯度消失问题,在后续的各层特征中都串联该初始特征。最后,设计了多尺度关节点定位的联合损失,用于学习深度网络参数。结果本文实验在两大人体姿态数据集MPII(MPII human pose dataset)和LSP(leeds sport pose)上分别与近3年的人体姿态估计方法进行了定性与定量比较,在MPII数据集中,模型的总检测率为89.1%,相比于性能第2的模型高出了0.7%;在LSP数据集中,模型的总检测率为91.0%,相比于性能第2的模型高出了0.5%。结论实验结果表明,初始特征学习能够有效判断关节点的自遮挡和混杂背景干扰情况,引入跨阶段结构的CSCPM姿态估计模型能够胜出现有人体姿态估计模型。关键词:跨阶段结构;初始特征;置信度图;人体姿态估计;深度学习28|5|2更新时间:2024-05-07
摘要:目的基于图像的人体姿态估计是计算机视觉领域中一个非常重要的研究课题,并广泛应用于人机交互、监控以及图像检索等方面。但是,由于人体视觉外观的多样性、遮挡和混杂背景等因素的影响,导致人体姿态估计问题一直是计算机视觉领域的难点和热点。本文主要关注于初始特征对关节点定位的作用,提出一种跨阶段卷积姿态机(CSCPM)。方法首先,采用VGG(visual geometry group)网络获得初步的图像初始特征,该初始特征既是图像关节点定位的基础,同时,也由于受到自遮挡和混杂背景的干扰难以学习。其次,在初始特征的基础上,构建多层模型学习不同尺度下的结构特征,同时为了解决深度学习中的梯度消失问题,在后续的各层特征中都串联该初始特征。最后,设计了多尺度关节点定位的联合损失,用于学习深度网络参数。结果本文实验在两大人体姿态数据集MPII(MPII human pose dataset)和LSP(leeds sport pose)上分别与近3年的人体姿态估计方法进行了定性与定量比较,在MPII数据集中,模型的总检测率为89.1%,相比于性能第2的模型高出了0.7%;在LSP数据集中,模型的总检测率为91.0%,相比于性能第2的模型高出了0.5%。结论实验结果表明,初始特征学习能够有效判断关节点的自遮挡和混杂背景干扰情况,引入跨阶段结构的CSCPM姿态估计模型能够胜出现有人体姿态估计模型。关键词:跨阶段结构;初始特征;置信度图;人体姿态估计;深度学习28|5|2更新时间:2024-05-07 -
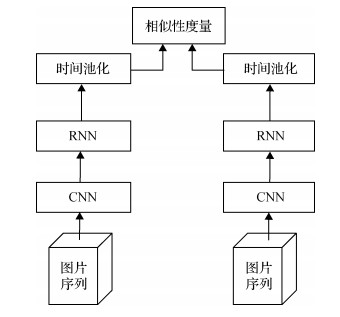 摘要:目的跨摄像头跨场景的视频行人再识别问题是目前计算机视觉领域的一项重要任务。在现实场景中,光照变化、遮挡、观察点变化以及杂乱的背景等造成行人外观的剧烈变化,增加了行人再识别的难度。为提高视频行人再识别系统在复杂应用场景中的鲁棒性,提出了一种结合双向长短时记忆循环神经网络(BiLSTM)和注意力机制的视频行人再识别算法。方法首先基于残差网络结构,训练卷积神经网络(CNN)学习空间外观特征,然后使用BiLSTM提取双向时间运动信息,最后通过注意力机制融合学习到的空间外观特征和时间运动信息,以形成一个有判别力的视频层次表征。结果在两个公开的大规模数据集上与现有的其他方法进行了实验比较。在iLIDS-VID数据集中,与性能第2的方法相比,首位命中率Rank1指标提升了4.5%;在PRID2011数据集中,相比于性能第2的方法,首位命中率Rank1指标提升了3.9%。同时分别在两个数据集中进行了消融实验,实验结果验证了所提出算法的有效性。结论提出的结合BiLSTM和注意力机制的视频行人再识别算法,能够充分利用视频序列中的信息,学习到更鲁棒的序列特征。实验结果表明,对于不同数据集,均能显著提升识别性能。关键词:计算机视觉;行人再识别;卷积神经网络;双向长短时记忆循环神经网络(BiLSTM);注意力机制15|4|4更新时间:2024-05-07
摘要:目的跨摄像头跨场景的视频行人再识别问题是目前计算机视觉领域的一项重要任务。在现实场景中,光照变化、遮挡、观察点变化以及杂乱的背景等造成行人外观的剧烈变化,增加了行人再识别的难度。为提高视频行人再识别系统在复杂应用场景中的鲁棒性,提出了一种结合双向长短时记忆循环神经网络(BiLSTM)和注意力机制的视频行人再识别算法。方法首先基于残差网络结构,训练卷积神经网络(CNN)学习空间外观特征,然后使用BiLSTM提取双向时间运动信息,最后通过注意力机制融合学习到的空间外观特征和时间运动信息,以形成一个有判别力的视频层次表征。结果在两个公开的大规模数据集上与现有的其他方法进行了实验比较。在iLIDS-VID数据集中,与性能第2的方法相比,首位命中率Rank1指标提升了4.5%;在PRID2011数据集中,相比于性能第2的方法,首位命中率Rank1指标提升了3.9%。同时分别在两个数据集中进行了消融实验,实验结果验证了所提出算法的有效性。结论提出的结合BiLSTM和注意力机制的视频行人再识别算法,能够充分利用视频序列中的信息,学习到更鲁棒的序列特征。实验结果表明,对于不同数据集,均能显著提升识别性能。关键词:计算机视觉;行人再识别;卷积神经网络;双向长短时记忆循环神经网络(BiLSTM);注意力机制15|4|4更新时间:2024-05-07 -
 摘要:目的为了提高以正交多项式为核函数构造的高阶矩数值的稳定性,增强低阶矩抗噪和滤波的能力,将仅具有全局描述能力的常规正交矩推广到可以局部化提取图像特征的矩模型,从频率特性分析的角度定义一种参数可调的通用半正交矩模型。方法首先,对传统正交矩的核函数进行合理的修正,以修正后的核函数(也称基函数)替代传统正交矩中的原核函数,使其成为修改后的特例之一。经过修正后的基函数可以有效消除图像矩数值不稳定现象。其次,采用时域的分析方法能够对图像的低阶矩作定量的分析,但无法对图像的高频部分(对应的高阶矩)作更合理的表述。因此提出一种时—频对应的方法来分析和增强不同阶矩的稳定性,通过对修正后核函数的频带宽度微调可以建立性能更优的不同阶矩。最后,利用构建的半正交—三角函数矩研究和分析了通用半正交矩模型的特点及性质。结果将三角函数为核函数的图像矩与现有的Zernike、伪Zernike、正交傅里叶—梅林矩及贝塞尔—傅里叶矩相比,由于核函数组成简单,且其值域恒定在[-1, 1]区间,因此在图像识别领域具有更快的计算速度和更高的稳定性。结论理论分析和一系列相关图像的仿真实验表明,与传统的正交矩相比,在数值稳定性、图像重构、图像感兴趣区域(ROI)特征检测、噪声鲁棒性测试及不变性识别方面,通用的半正交矩性能及效果更优。关键词:半正交;正交矩;图像重构;数值稳定性;不变性识别11|4|0更新时间:2024-05-07
摘要:目的为了提高以正交多项式为核函数构造的高阶矩数值的稳定性,增强低阶矩抗噪和滤波的能力,将仅具有全局描述能力的常规正交矩推广到可以局部化提取图像特征的矩模型,从频率特性分析的角度定义一种参数可调的通用半正交矩模型。方法首先,对传统正交矩的核函数进行合理的修正,以修正后的核函数(也称基函数)替代传统正交矩中的原核函数,使其成为修改后的特例之一。经过修正后的基函数可以有效消除图像矩数值不稳定现象。其次,采用时域的分析方法能够对图像的低阶矩作定量的分析,但无法对图像的高频部分(对应的高阶矩)作更合理的表述。因此提出一种时—频对应的方法来分析和增强不同阶矩的稳定性,通过对修正后核函数的频带宽度微调可以建立性能更优的不同阶矩。最后,利用构建的半正交—三角函数矩研究和分析了通用半正交矩模型的特点及性质。结果将三角函数为核函数的图像矩与现有的Zernike、伪Zernike、正交傅里叶—梅林矩及贝塞尔—傅里叶矩相比,由于核函数组成简单,且其值域恒定在[-1, 1]区间,因此在图像识别领域具有更快的计算速度和更高的稳定性。结论理论分析和一系列相关图像的仿真实验表明,与传统的正交矩相比,在数值稳定性、图像重构、图像感兴趣区域(ROI)特征检测、噪声鲁棒性测试及不变性识别方面,通用的半正交矩性能及效果更优。关键词:半正交;正交矩;图像重构;数值稳定性;不变性识别11|4|0更新时间:2024-05-07 -
 摘要:目的视频行为识别一直广受计算机视觉领域研究者的关注,主要包括个体行为识别与群体行为识别。群体行为识别以人群动作作为研究对象,对其行为进行有效表示及分类,在智能监控、运动分析以及视频检索等领域有重要的应用价值。现有的算法大多以多层递归神经网络(RNN)模型作为基础,构建出可表征个体与所属群体之间关系的群体行为特征,但是未能充分考虑个体之间的相互影响,致使识别精度较低。为此,提出一种基于非局部卷积神经网络的群体行为识别模型,充分利用个体间上下文信息,有效提升了群体行为识别准确率。方法所提模型采用一种自底向上的方式来同时对个体行为与群体行为进行分层识别。首先从原始视频中沿着个人运动的轨迹导出个体附近的图像区块;随后使用非局部卷积神经网络(CNN)来提取包含个体间影响关系的静态特征,紧接着将提取到的个体静态特征输入多层长短期记忆(LSTM)时序模型中,得到个体动态特征并通过个体特征聚合得到群体行为特征;最后利用个体、群体行为特征同时完成个体行为与群体行为的识别。结果本文在国际通用的Volleyball Dataset上进行实验。实验结果表明,所提模型在未进行群体精细划分条件下取得了77.6%的准确率,在群体精细划分的条件下取得了83.5%的准确率。结论首次提出了面向群体行为识别的非局部卷积网络,并依此构建了一种非局部群体行为识别模型。所提模型通过考虑个体之间的相互影响,结合个体上下文信息,可从训练数据中学习到更具判别性的群体行为特征。该特征既包含个体间上下文信息、也保留了群体内层次结构信息,更有利于最终的群体行为分类。关键词:行为识别;群体行为识别;非局部网络;特征表达;深度学习16|4|1更新时间:2024-05-07
摘要:目的视频行为识别一直广受计算机视觉领域研究者的关注,主要包括个体行为识别与群体行为识别。群体行为识别以人群动作作为研究对象,对其行为进行有效表示及分类,在智能监控、运动分析以及视频检索等领域有重要的应用价值。现有的算法大多以多层递归神经网络(RNN)模型作为基础,构建出可表征个体与所属群体之间关系的群体行为特征,但是未能充分考虑个体之间的相互影响,致使识别精度较低。为此,提出一种基于非局部卷积神经网络的群体行为识别模型,充分利用个体间上下文信息,有效提升了群体行为识别准确率。方法所提模型采用一种自底向上的方式来同时对个体行为与群体行为进行分层识别。首先从原始视频中沿着个人运动的轨迹导出个体附近的图像区块;随后使用非局部卷积神经网络(CNN)来提取包含个体间影响关系的静态特征,紧接着将提取到的个体静态特征输入多层长短期记忆(LSTM)时序模型中,得到个体动态特征并通过个体特征聚合得到群体行为特征;最后利用个体、群体行为特征同时完成个体行为与群体行为的识别。结果本文在国际通用的Volleyball Dataset上进行实验。实验结果表明,所提模型在未进行群体精细划分条件下取得了77.6%的准确率,在群体精细划分的条件下取得了83.5%的准确率。结论首次提出了面向群体行为识别的非局部卷积网络,并依此构建了一种非局部群体行为识别模型。所提模型通过考虑个体之间的相互影响,结合个体上下文信息,可从训练数据中学习到更具判别性的群体行为特征。该特征既包含个体间上下文信息、也保留了群体内层次结构信息,更有利于最终的群体行为分类。关键词:行为识别;群体行为识别;非局部网络;特征表达;深度学习16|4|1更新时间:2024-05-07 -
 摘要:目的随着3D扫描技术和虚拟现实技术的发展,真实物体的3D识别方法已经成为研究的热点之一。针对现有基于深度学习的方法训练时间长,识别效果不理想等问题,提出了一种结合感知器残差网络和超限学习机(ELM)的3D物体识别方法。方法以超限学习机的框架为基础,使用多层感知器残差网络学习3D物体的多视角投影特征,并利用提取的特征数据和已知的标签数据同时训练了ELM分类层、K最近邻(KNN)分类层和支持向量机(SVM)分类层识别3D物体。网络使用增加了多层感知器的卷积层替代传统的卷积层。卷积网络由改进的残差单元组成,包含多个卷积核个数恒定的并行残差通道,用于拟合不同数学形式的残差项函数。网络中半数卷积核参数和感知器参数以高斯分布随机产生,其余通过训练寻优得到。结果提出的方法在普林斯顿3D模型数据集上达到了94.18%的准确率,在2D的NORB数据集上达到了97.46%的准确率。该算法在两个国际标准数据集中均取得了当前最好的效果。同时,使用超限学习机框架使得本文算法的训练时间比基于深度学习的方法减少了3个数量级。结论本文提出了一种使用多视角图识别3D物体的方法,实验表明该方法比现有的ELM方法和深度学习等最新方法的识别率更高,抗干扰性更强,并且其调节参数少,收敛速度快。关键词:多层感知器残差网络;多通道分类器;超限学习机;3D物体识别;特征提取15|19|0更新时间:2024-05-07
摘要:目的随着3D扫描技术和虚拟现实技术的发展,真实物体的3D识别方法已经成为研究的热点之一。针对现有基于深度学习的方法训练时间长,识别效果不理想等问题,提出了一种结合感知器残差网络和超限学习机(ELM)的3D物体识别方法。方法以超限学习机的框架为基础,使用多层感知器残差网络学习3D物体的多视角投影特征,并利用提取的特征数据和已知的标签数据同时训练了ELM分类层、K最近邻(KNN)分类层和支持向量机(SVM)分类层识别3D物体。网络使用增加了多层感知器的卷积层替代传统的卷积层。卷积网络由改进的残差单元组成,包含多个卷积核个数恒定的并行残差通道,用于拟合不同数学形式的残差项函数。网络中半数卷积核参数和感知器参数以高斯分布随机产生,其余通过训练寻优得到。结果提出的方法在普林斯顿3D模型数据集上达到了94.18%的准确率,在2D的NORB数据集上达到了97.46%的准确率。该算法在两个国际标准数据集中均取得了当前最好的效果。同时,使用超限学习机框架使得本文算法的训练时间比基于深度学习的方法减少了3个数量级。结论本文提出了一种使用多视角图识别3D物体的方法,实验表明该方法比现有的ELM方法和深度学习等最新方法的识别率更高,抗干扰性更强,并且其调节参数少,收敛速度快。关键词:多层感知器残差网络;多通道分类器;超限学习机;3D物体识别;特征提取15|19|0更新时间:2024-05-07 -
 摘要:目的引入视觉信息流的整体和局部处理机制,提出了一种多路径卷积神经网络的轮廓感知新方法。方法利用高斯金字塔尺度分解获得低分辨率子图,用来表征视觉信息中的整体轮廓;通过2维高斯导函数模拟经典感受野的方向选择性,获得描述细节特征的边界响应子图;构建多路径卷积神经网络,利用具有稀疏编码特性的子网络(Sparse-Net)实现对整体轮廓的快速检测;利用具有冗余度增强编码特性的子网络(Redundancy-Net)实现对局部细节特征提取;对上述多路径卷积神经网络响应进行融合编码,以实现轮廓响应的整体感知和局部检测融合,获取轮廓的精细化感知结果。结果以美国伯克利大学计算机视觉组提供的数据集BSDS500图库为实验对象,在GTX1080Ti环境下本文Sparse-Net对整体轮廓的检测速度达到42幅/s,为HFL方法1.2幅/s的35倍;而Sparse-Net和Redundancy-Net融合后的检测指标数据集尺度上最优(ODS)、图片尺度上最优(OIS)、平均精度(AP)分别为0.806、0.824、0.846,优于HED(holistically-nested edge detection)方法和RCF(richer convolution features for edge detection)方法,结果表明本文方法能有效突出主体轮廓并抑制纹理背景。结论多路径卷积神经网络的轮廓感知应用,将有助于进一步理解视觉感知机制,并对减弱卷积神经网络的黑盒特性有着重要的意义。关键词:轮廓检测;空洞卷积;卷积神经网络;视觉感知;特征融合21|5|0更新时间:2024-05-07
摘要:目的引入视觉信息流的整体和局部处理机制,提出了一种多路径卷积神经网络的轮廓感知新方法。方法利用高斯金字塔尺度分解获得低分辨率子图,用来表征视觉信息中的整体轮廓;通过2维高斯导函数模拟经典感受野的方向选择性,获得描述细节特征的边界响应子图;构建多路径卷积神经网络,利用具有稀疏编码特性的子网络(Sparse-Net)实现对整体轮廓的快速检测;利用具有冗余度增强编码特性的子网络(Redundancy-Net)实现对局部细节特征提取;对上述多路径卷积神经网络响应进行融合编码,以实现轮廓响应的整体感知和局部检测融合,获取轮廓的精细化感知结果。结果以美国伯克利大学计算机视觉组提供的数据集BSDS500图库为实验对象,在GTX1080Ti环境下本文Sparse-Net对整体轮廓的检测速度达到42幅/s,为HFL方法1.2幅/s的35倍;而Sparse-Net和Redundancy-Net融合后的检测指标数据集尺度上最优(ODS)、图片尺度上最优(OIS)、平均精度(AP)分别为0.806、0.824、0.846,优于HED(holistically-nested edge detection)方法和RCF(richer convolution features for edge detection)方法,结果表明本文方法能有效突出主体轮廓并抑制纹理背景。结论多路径卷积神经网络的轮廓感知应用,将有助于进一步理解视觉感知机制,并对减弱卷积神经网络的黑盒特性有着重要的意义。关键词:轮廓检测;空洞卷积;卷积神经网络;视觉感知;特征融合21|5|0更新时间:2024-05-07 -
 摘要:目的尽管基于深度神经网络的人脸检测器在检测精度上有了极大的提升,但其代价是必须依赖强大的计算资源。如何在CPU上取得较高的检测精度的同时达到实时的检测速度是一个巨大的挑战。针对非约束性条件下的快速鲁棒的人脸检测问题,提出一种基于轻量级神经网络的检测方法。方法受轻量级网络MobileNet的启发,本文算法采用通道分离的卷积方式进行特征提取,并结合Inception和残差连接的思想,构建若干特征提取模块,最终训练出一个简单高效的特征提取网络;在检测时,采用One-Stage的检测策略,在骨干网络的若干不同层级上使用卷积的同时进行目标区域的分类和定位;在进行目标区域精调时,需要先在对应的特征层上预设先验框,然后再使用边界框回归算法调整先验框的位置和大小,使之接近真实框的位置。为了减少先验框的数量以节省模型参数,本算法针对人脸目标框的特点设置先验框。结果基于TensorFlow深度学习库构建和训练本文的检测模型,在FDDB数据集上对其进行测试,并与若干经典算法对比了检测速度和精度。相较于多任务级联卷积网络(MTCNN)等典型的深度学习方法,本文算法在CPU上将检测速度提升到25帧/s,同时平均精度(mAP)保持在0.892,高于大多数传统算法。实验结果表明本文方法能实现在CPU上的实时、高精度检测。结论提出了一种基于轻量级网络模型的人脸检测方法,以简单高效的卷积模块为基础构建骨干网络,并在检测时针对人脸比例特征设置合理的先验框。在非约束性条件以及有限计算资源条件下,该方法不仅在精度上表现良好,而且具有较快的检测速度,是一种鲁棒的检测方法。关键词:计算机视觉;人脸检测;卷积神经网络;轻量级模型;One-Stage检测;先验框12|4|5更新时间:2024-05-07
摘要:目的尽管基于深度神经网络的人脸检测器在检测精度上有了极大的提升,但其代价是必须依赖强大的计算资源。如何在CPU上取得较高的检测精度的同时达到实时的检测速度是一个巨大的挑战。针对非约束性条件下的快速鲁棒的人脸检测问题,提出一种基于轻量级神经网络的检测方法。方法受轻量级网络MobileNet的启发,本文算法采用通道分离的卷积方式进行特征提取,并结合Inception和残差连接的思想,构建若干特征提取模块,最终训练出一个简单高效的特征提取网络;在检测时,采用One-Stage的检测策略,在骨干网络的若干不同层级上使用卷积的同时进行目标区域的分类和定位;在进行目标区域精调时,需要先在对应的特征层上预设先验框,然后再使用边界框回归算法调整先验框的位置和大小,使之接近真实框的位置。为了减少先验框的数量以节省模型参数,本算法针对人脸目标框的特点设置先验框。结果基于TensorFlow深度学习库构建和训练本文的检测模型,在FDDB数据集上对其进行测试,并与若干经典算法对比了检测速度和精度。相较于多任务级联卷积网络(MTCNN)等典型的深度学习方法,本文算法在CPU上将检测速度提升到25帧/s,同时平均精度(mAP)保持在0.892,高于大多数传统算法。实验结果表明本文方法能实现在CPU上的实时、高精度检测。结论提出了一种基于轻量级网络模型的人脸检测方法,以简单高效的卷积模块为基础构建骨干网络,并在检测时针对人脸比例特征设置合理的先验框。在非约束性条件以及有限计算资源条件下,该方法不仅在精度上表现良好,而且具有较快的检测速度,是一种鲁棒的检测方法。关键词:计算机视觉;人脸检测;卷积神经网络;轻量级模型;One-Stage检测;先验框12|4|5更新时间:2024-05-07 -
 摘要:目的线结构光视觉测量是一种利用可控光源和数字图像的主动视觉测量方法,光条中心提取是线结构光视觉测量的关键技术,直接影响到线结构光视觉测量的精度。传统灰度重心法只在图像的横向或纵向上计算光条的灰度重心,没有考虑光条的法线方向,精度较低。本文提出一种改进的光条中心提取算法,以期实现光条中心的精确提取。方法在分析线结构光的光条灰度特性基础上,基于传统的灰度重心法,提出一种改进的两步提取算法。基于图像差分法从原始图像中分离出有效的线结构光光条,采用传统灰度重心法对光条中心进行粗提取;在粗提取的光条中心点处通过自定义的方向模板确定光条的法线方向,以粗提取的光条中心点为中心,沿法线方向采用灰度重心法进行二次提取,获取线结构光光条的中心。结果本文采用CCD相机、镜头、线激光器及辅助机构搭建线结构光视觉系统,采用提出的算法对线激光器投影产生的直线型光条、非连续光条和弯曲光条的中心进行提取。通过光条中心提取实验获取的光条中心线的走向与光条的走向大致相同,符合预期的光条中心线。本文将Steger法作为评价标准,分别计算本文算法、传统灰度重心法与Steger法提取的光条中心的偏差,通过对比实验可知,本文算法提取的光条中心的偏差更小,并且程序运行时间比Steger法减少了3 s以上。结论本文研究线结构光的光条中心提取算法,对传统灰度重心法进行改进,能够实现直线型光条、非连续光条和弯曲光条等不同形状光条的亚像素级中心提取,并且在保证较少的程序运行时间的同时,能够提高传统灰度重心法的光条中心提取精度。关键词:线结构光;亚像素级;灰度重心法;光条中心提取算法;方向模板;法线方向13|4|5更新时间:2024-05-07
摘要:目的线结构光视觉测量是一种利用可控光源和数字图像的主动视觉测量方法,光条中心提取是线结构光视觉测量的关键技术,直接影响到线结构光视觉测量的精度。传统灰度重心法只在图像的横向或纵向上计算光条的灰度重心,没有考虑光条的法线方向,精度较低。本文提出一种改进的光条中心提取算法,以期实现光条中心的精确提取。方法在分析线结构光的光条灰度特性基础上,基于传统的灰度重心法,提出一种改进的两步提取算法。基于图像差分法从原始图像中分离出有效的线结构光光条,采用传统灰度重心法对光条中心进行粗提取;在粗提取的光条中心点处通过自定义的方向模板确定光条的法线方向,以粗提取的光条中心点为中心,沿法线方向采用灰度重心法进行二次提取,获取线结构光光条的中心。结果本文采用CCD相机、镜头、线激光器及辅助机构搭建线结构光视觉系统,采用提出的算法对线激光器投影产生的直线型光条、非连续光条和弯曲光条的中心进行提取。通过光条中心提取实验获取的光条中心线的走向与光条的走向大致相同,符合预期的光条中心线。本文将Steger法作为评价标准,分别计算本文算法、传统灰度重心法与Steger法提取的光条中心的偏差,通过对比实验可知,本文算法提取的光条中心的偏差更小,并且程序运行时间比Steger法减少了3 s以上。结论本文研究线结构光的光条中心提取算法,对传统灰度重心法进行改进,能够实现直线型光条、非连续光条和弯曲光条等不同形状光条的亚像素级中心提取,并且在保证较少的程序运行时间的同时,能够提高传统灰度重心法的光条中心提取精度。关键词:线结构光;亚像素级;灰度重心法;光条中心提取算法;方向模板;法线方向13|4|5更新时间:2024-05-07
图像分析和识别
-
 摘要:目的在布料仿真中,针对基于物理方法计算复杂、耗时长、实时性差的缺点,提出了一种融合随机森林模型的布料分层建模方法。方法采用基于物理的方法计算出各个质点的初始位置,连接各个质点形成最初始水平布料。然后通过使用随机森林模型的回归算法来推断质点在下一水平布料的位置,使用
摘要:目的在布料仿真中,针对基于物理方法计算复杂、耗时长、实时性差的缺点,提出了一种融合随机森林模型的布料分层建模方法。方法采用基于物理的方法计算出各个质点的初始位置,连接各个质点形成最初始水平布料。然后通过使用随机森林模型的回归算法来推断质点在下一水平布料的位置,使用$ \sqrt 3 $ 关键词:布料仿真;多精度布料;分层布料模拟;机器学习;随机森林11|4|1更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的几何光学四分量是指在太阳光照条件下传感器所能观测的4个光学分量,即光照植被、光照土壤、阴影植被和阴影土壤。四分量是构成遥感几何光学模型的重要内容。在近地表遥感应用中,相机俯视拍照是提取四分量的一个途径。准确快速地从图像数据中提取四分量对植被冠层结构参数反演和植被长势监测具有重要意义。方法植被与土壤二分量的识别是四分量提取的基础。目前大多数二分类算法在自然光照条件复杂时分类误差较大。本文基于卷积神经网络(CNN)和阈值法实现了多种二分类和四分量提取算法。阈值法中,使用SHAR-LABFVC(shadow-resistant algorithm:LABFVC)实现植被与土壤的二分类,并在此基础上应用二次阈值分割获取四分量,称为二次阈值法;基于CNN的方法中,采用U-Net架构,并使用RGB和RGBV数据进行训练得到U-Net和U-Net-V模型,前者完成二分类和四分量任务,后者只完成四分量提取实验。最后,对一种结合U-Net与阈值法的混合算法进行四分量提取实验。结果本文在18幅图像(1 800个子图)数据上进行了实验,结果表明,与目视解译得到的四分量真值相比较,U-Net-V和混合法精度最高,具有相近的均方根误差(RMSE)(0.06和0.07)和相关系数(0.95和0.94);二次阈值法与U-Net模型精度略低于上述两种算法,RMSE分别是0.08和0.09,相关系数均为0.88。在二分类实验中,U-Net的分类正确率是91%,SHAR-LABFVC为85%。结论通过对比实验表明,在二分类问题中,U-Net可以更好地应对复杂自然光照条件下的数字图像。在四分量提取实验中,混合法和U-Net-V的结果优于U-Net与二次阈值法,可以用于提取四分量。关键词:几何光学四分量;卷积神经网络;阈值法;冠层图像处理;图像语义分割14|4|1更新时间:2024-05-07
摘要:目的几何光学四分量是指在太阳光照条件下传感器所能观测的4个光学分量,即光照植被、光照土壤、阴影植被和阴影土壤。四分量是构成遥感几何光学模型的重要内容。在近地表遥感应用中,相机俯视拍照是提取四分量的一个途径。准确快速地从图像数据中提取四分量对植被冠层结构参数反演和植被长势监测具有重要意义。方法植被与土壤二分量的识别是四分量提取的基础。目前大多数二分类算法在自然光照条件复杂时分类误差较大。本文基于卷积神经网络(CNN)和阈值法实现了多种二分类和四分量提取算法。阈值法中,使用SHAR-LABFVC(shadow-resistant algorithm:LABFVC)实现植被与土壤的二分类,并在此基础上应用二次阈值分割获取四分量,称为二次阈值法;基于CNN的方法中,采用U-Net架构,并使用RGB和RGBV数据进行训练得到U-Net和U-Net-V模型,前者完成二分类和四分量任务,后者只完成四分量提取实验。最后,对一种结合U-Net与阈值法的混合算法进行四分量提取实验。结果本文在18幅图像(1 800个子图)数据上进行了实验,结果表明,与目视解译得到的四分量真值相比较,U-Net-V和混合法精度最高,具有相近的均方根误差(RMSE)(0.06和0.07)和相关系数(0.95和0.94);二次阈值法与U-Net模型精度略低于上述两种算法,RMSE分别是0.08和0.09,相关系数均为0.88。在二分类实验中,U-Net的分类正确率是91%,SHAR-LABFVC为85%。结论通过对比实验表明,在二分类问题中,U-Net可以更好地应对复杂自然光照条件下的数字图像。在四分量提取实验中,混合法和U-Net-V的结果优于U-Net与二次阈值法,可以用于提取四分量。关键词:几何光学四分量;卷积神经网络;阈值法;冠层图像处理;图像语义分割14|4|1更新时间:2024-05-07 -
 摘要:目的高光谱图像距具有较高的光谱分辨率,从而具备区分诊断性光谱特征地物的能力,但高光谱数据经常会受到如环境、设备等各种因素的干扰,导致数据污染,严重影响高光谱数据在应用中的精度和可信度。方法根据高光谱图像光谱维度特征值大小与所包含信息的关系,利用截断核范数最小化方法表示光谱低秩先验,从而有效抑制稀疏噪声;再利用高光谱图像的空间稀疏先验建立正则化模型,达到去除高密度噪声的目的;最终,结合上述两种模型的优势,构建截断核范数全变差正则化模型去除高斯噪声、稀疏噪声及其他混合噪声等。结果将本文与其他三种近期发表的主流去噪方法进行对比,模型平均峰信噪比提高3.20 dB,平均结构相似数值指标提高0.22,并可以应用到包含各种噪声、不同尺寸的图像,其模型平均峰信噪比提高1.33 dB。结论本文方法在光谱低秩中更加准确地表示了观测数据的先验特征,利用高光谱遥感数据的空间和低秩先验信息,能够对含有高密度噪声以及稀疏异常值的图像进行复原。关键词:高光谱遥感图像;图像复原;低秩先验;截断核范数;全变差;正则化方法13|6|5更新时间:2024-05-07
摘要:目的高光谱图像距具有较高的光谱分辨率,从而具备区分诊断性光谱特征地物的能力,但高光谱数据经常会受到如环境、设备等各种因素的干扰,导致数据污染,严重影响高光谱数据在应用中的精度和可信度。方法根据高光谱图像光谱维度特征值大小与所包含信息的关系,利用截断核范数最小化方法表示光谱低秩先验,从而有效抑制稀疏噪声;再利用高光谱图像的空间稀疏先验建立正则化模型,达到去除高密度噪声的目的;最终,结合上述两种模型的优势,构建截断核范数全变差正则化模型去除高斯噪声、稀疏噪声及其他混合噪声等。结果将本文与其他三种近期发表的主流去噪方法进行对比,模型平均峰信噪比提高3.20 dB,平均结构相似数值指标提高0.22,并可以应用到包含各种噪声、不同尺寸的图像,其模型平均峰信噪比提高1.33 dB。结论本文方法在光谱低秩中更加准确地表示了观测数据的先验特征,利用高光谱遥感数据的空间和低秩先验信息,能够对含有高密度噪声以及稀疏异常值的图像进行复原。关键词:高光谱遥感图像;图像复原;低秩先验;截断核范数;全变差;正则化方法13|6|5更新时间:2024-05-07 -
 摘要:目的近年来,随着我国遥感技术的快速发展,遥感数据呈现出大数据的特点,遥感数据的时效性增强,针对新环境下遥感算法编程语言众多,程序运行和部署环境需求多样,程序的集成和部署困难的问题,提出了一种遥感算法程序快速封装与Docker容器化系统集成架构。方法该系统架构主要包括:1)遥感算法程序的镜像自动化封装制作;2)镜像的分发管理,达到算法程序镜像的共享;3)遥感信息产品生产流程的容器化编排服务,将相关联的算法程序镜像串联,以满足特定遥感信息产品的生产;4)容器的调度运行,调用镜像,实现特定遥感产品的容器化运行。本文在上述容器化系统集成架构下,以Landsat5数据的NDVI、NDWI信息产品的生产作为容器化生产实例,并同物理机、KVM(kernel-based virtual machine)虚拟机在运行时间、内存占用量、部署效率等性能进行了对比。结果Docker容器虚拟化环境下的产品生产和物理机环境下在运行时间和内存占用量上几无差别,优于KVM虚拟机。Docker容器虚拟化环境和KVM虚拟机环境下在部署上能够节省大量时间,相比于物理机环境能够提高部署效率。结论容器化的系统集成方式能够有效解决遥感算法程序集成和部署困难的问题,有利于遥感算法程序的复用和流程的共享,提高系统集成效率,具备较强的遥感数据实时快速处理能力。关键词:Docker容器;算法集成;遥感产品生产;虚拟化;可复用性12|4|0更新时间:2024-05-07
摘要:目的近年来,随着我国遥感技术的快速发展,遥感数据呈现出大数据的特点,遥感数据的时效性增强,针对新环境下遥感算法编程语言众多,程序运行和部署环境需求多样,程序的集成和部署困难的问题,提出了一种遥感算法程序快速封装与Docker容器化系统集成架构。方法该系统架构主要包括:1)遥感算法程序的镜像自动化封装制作;2)镜像的分发管理,达到算法程序镜像的共享;3)遥感信息产品生产流程的容器化编排服务,将相关联的算法程序镜像串联,以满足特定遥感信息产品的生产;4)容器的调度运行,调用镜像,实现特定遥感产品的容器化运行。本文在上述容器化系统集成架构下,以Landsat5数据的NDVI、NDWI信息产品的生产作为容器化生产实例,并同物理机、KVM(kernel-based virtual machine)虚拟机在运行时间、内存占用量、部署效率等性能进行了对比。结果Docker容器虚拟化环境下的产品生产和物理机环境下在运行时间和内存占用量上几无差别,优于KVM虚拟机。Docker容器虚拟化环境和KVM虚拟机环境下在部署上能够节省大量时间,相比于物理机环境能够提高部署效率。结论容器化的系统集成方式能够有效解决遥感算法程序集成和部署困难的问题,有利于遥感算法程序的复用和流程的共享,提高系统集成效率,具备较强的遥感数据实时快速处理能力。关键词:Docker容器;算法集成;遥感产品生产;虚拟化;可复用性12|4|0更新时间:2024-05-07
遥感图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0