
最新刊期
2018 年 第 23 卷 第 9 期
-
 摘要:目的浮雕是雕塑艺术的一种,根据其空间结构和用途的不同分为高浮雕、浅浮雕和凹浮雕3类。随着数字化技术和3D打印技术的发展,数字化浮雕的生成技术已经成为近年来计算机图形学领域的研究热点之一,从3维模型生成浮雕以其真实自然的效果成为浮雕生成的主要方法之一。为了使即将进入该领域的学者尽快了解该方法的现状和发展趋势,本文对3种类型的浮雕生成技术进行了系统的综述。方法介绍了3种类型的浮雕生成技术,着重比较分析了基于3维网格模型的数字浅浮雕生成过程中的关键技术,存在问题及解决方案。针对复杂3维网格模型在生成数字凹浮雕过程中存在的部分细节信息丢失、特征线类型体现形式不完善、线条与形体间的过渡尚未解决、生成浮雕效果不自然等具体问题,提出了适用于3维复杂网格模型生成数字凹浮雕的研究方案。同时,从角色动画序列出发,对最优浮雕的生成技术进行了探讨,探讨结合信息熵理论计算选择最佳动作及观察视角的场景,还原艺术家的创作过程,为适用于面向3维打印的用户浮雕产品定制服务提供了可行的解决方案。结果基于3维模型的浮雕生成方法是生成数字浮雕的一种重要方法,如何通过压缩和细节保持相关算法得到效果自然的浮雕模型一直是研究者们研究的热点问题。结论虽然由3维模型生成数字浮雕是一种行之有效的方法,但是仍存在细节信息丢失、线条过渡不自然、特征线类型不完善等几个值得继续研究的问题,另外一个值得研究的问题就是如何智能地从3维动画序列生成浮雕。关键词:浅浮雕;凹浮雕;细节保持;非线性压缩;最佳视角;最佳姿态;3D打印13|19|2更新时间:2024-05-07
摘要:目的浮雕是雕塑艺术的一种,根据其空间结构和用途的不同分为高浮雕、浅浮雕和凹浮雕3类。随着数字化技术和3D打印技术的发展,数字化浮雕的生成技术已经成为近年来计算机图形学领域的研究热点之一,从3维模型生成浮雕以其真实自然的效果成为浮雕生成的主要方法之一。为了使即将进入该领域的学者尽快了解该方法的现状和发展趋势,本文对3种类型的浮雕生成技术进行了系统的综述。方法介绍了3种类型的浮雕生成技术,着重比较分析了基于3维网格模型的数字浅浮雕生成过程中的关键技术,存在问题及解决方案。针对复杂3维网格模型在生成数字凹浮雕过程中存在的部分细节信息丢失、特征线类型体现形式不完善、线条与形体间的过渡尚未解决、生成浮雕效果不自然等具体问题,提出了适用于3维复杂网格模型生成数字凹浮雕的研究方案。同时,从角色动画序列出发,对最优浮雕的生成技术进行了探讨,探讨结合信息熵理论计算选择最佳动作及观察视角的场景,还原艺术家的创作过程,为适用于面向3维打印的用户浮雕产品定制服务提供了可行的解决方案。结果基于3维模型的浮雕生成方法是生成数字浮雕的一种重要方法,如何通过压缩和细节保持相关算法得到效果自然的浮雕模型一直是研究者们研究的热点问题。结论虽然由3维模型生成数字浮雕是一种行之有效的方法,但是仍存在细节信息丢失、线条过渡不自然、特征线类型不完善等几个值得继续研究的问题,另外一个值得研究的问题就是如何智能地从3维动画序列生成浮雕。关键词:浅浮雕;凹浮雕;细节保持;非线性压缩;最佳视角;最佳姿态;3D打印13|19|2更新时间:2024-05-07
综述

-
 摘要:目的针对目前基于稀疏表示的超分辨率重建算法中对字典原子的选取效率低、图像重建效果欠佳的问题,本文提出了核方法与一种高效的字典原子相关度筛选方法相融合的图像超分辨重建算法,充分利用字典原子与图像的相关度,选用对重建的贡献最大的原子来提高重建的效率和效果。方法首先,通过预处理高分辨率图像得到高、低分辨率图像样本集,再用字典学习得到高、低分辨率字典对;然后,对字典原子进行非相关处理提高字典原子的表达能力;此后,再利用低分辨率字典,引入核方法和字典原子筛选方法进行稀疏表示,设置阈值筛选高相关原子,低相关度原子对重建贡献度低,在迭代过程中耗费计算量,所以舍去低相关原子,再对普通原子进行正则化处理后加入支撑集,处理后的字典原子对于重建具有很好的表达能力;最后,利用处理后的字典原子对低分辨率图求解稀疏表示问题得到稀疏表示系数,结合高分辨率字典重建出高分辨率图像。结果实验通过与其他学习算法对比,得到结构相似度(SSIM)、峰值信噪比(PSNR)以及重建时间的结果。实验结果表明:本文方法与对比方法相比,图像重建时间提高了22.2%;图像结构相似度提高了9.06%;峰值信噪比提高了2.30 dB。原有的基于字典学习的方法对于字典选取具有一定的盲目性,所选取的原子与重建图像相关度较低,使重建效果差,本文方法获得的字典原子可以减少稀疏表示过程的时耗,同时提高稀疏表示的精度。引入核方法,改善经典算法中对原子选取的低精度问题,经实验证明,本方法能有效提高重建算法性能。结论实验结果表明,图像的稀疏表示过程的重建时间明显减少,重建效果也有一定的提高,并且在训练样本较少的情况下同样有良好的重建效率和效果,适合在实际中使用。关键词:稀疏表示;超分辨率重建;核方法;原子相关度;非相关处理11|4|1更新时间:2024-05-07
摘要:目的针对目前基于稀疏表示的超分辨率重建算法中对字典原子的选取效率低、图像重建效果欠佳的问题,本文提出了核方法与一种高效的字典原子相关度筛选方法相融合的图像超分辨重建算法,充分利用字典原子与图像的相关度,选用对重建的贡献最大的原子来提高重建的效率和效果。方法首先,通过预处理高分辨率图像得到高、低分辨率图像样本集,再用字典学习得到高、低分辨率字典对;然后,对字典原子进行非相关处理提高字典原子的表达能力;此后,再利用低分辨率字典,引入核方法和字典原子筛选方法进行稀疏表示,设置阈值筛选高相关原子,低相关度原子对重建贡献度低,在迭代过程中耗费计算量,所以舍去低相关原子,再对普通原子进行正则化处理后加入支撑集,处理后的字典原子对于重建具有很好的表达能力;最后,利用处理后的字典原子对低分辨率图求解稀疏表示问题得到稀疏表示系数,结合高分辨率字典重建出高分辨率图像。结果实验通过与其他学习算法对比,得到结构相似度(SSIM)、峰值信噪比(PSNR)以及重建时间的结果。实验结果表明:本文方法与对比方法相比,图像重建时间提高了22.2%;图像结构相似度提高了9.06%;峰值信噪比提高了2.30 dB。原有的基于字典学习的方法对于字典选取具有一定的盲目性,所选取的原子与重建图像相关度较低,使重建效果差,本文方法获得的字典原子可以减少稀疏表示过程的时耗,同时提高稀疏表示的精度。引入核方法,改善经典算法中对原子选取的低精度问题,经实验证明,本方法能有效提高重建算法性能。结论实验结果表明,图像的稀疏表示过程的重建时间明显减少,重建效果也有一定的提高,并且在训练样本较少的情况下同样有良好的重建效率和效果,适合在实际中使用。关键词:稀疏表示;超分辨率重建;核方法;原子相关度;非相关处理11|4|1更新时间:2024-05-07 -
 摘要:目的目前在图像补全领域研究的重点和难点是补全具有复杂结构信息和丰富纹理信息的大破损区域的图像。传统的基于样本块的图像补全算法主要采用规则的模板块和匹配块来进行补全,补全过程中不能充分利用图像的结构或纹理的不规则信息,从而影响算法修复的精度和效率。针对这一问题,本研究提出一种基于不规则块的图像补全算法。方法在该算法中,首先利用结构稀疏度来区分图像的结构信息和纹理信息并基于结构稀疏度和置信度计算破损区域边界点的优先级,然后选择优先级最高的点构造规则模板块。对处于复杂结构区域的模板块,如果其邻域含有已知的结构信息,则膨胀该规则模板并利用其周围的结构信息来辅助构造不规则模板块。接下来,在图像完好区域内搜索与该模板块对应的匹配块,如果该匹配块的邻域包含有效的结构信息,则膨胀该匹配块并补充其周围的结构信息来完善该不规则匹配块。最后,利用该不规则匹配块补全破损区域。对于补全过程中块间接缝造成的视觉不连通问题,本研究利用图像的纹理信息来进行修饰。结果将本文算法与4种修复效果较好的算法(3种基于规则块的算法和1种基于局部敏感哈希的修复算法)进行对比,通过8组经典图像进行实例验证,采用客观评价指标峰值信噪比PSNR和主观视觉连通性进行评价,结果表明本文提出的算法峰值信噪比相较4种对比算法均有04 dB的提高,且在补全的精细度和视觉连通性方面有更佳的效果。结论本文算法在补全含有较复杂结构和丰富纹理的破损自然图像、壁画图像和目标物体移除上有较好的修复效果,普适性较强。关键词:图像补全;结构稀疏度;不规则块;接缝修饰;局部一致性;自适应18|38|0更新时间:2024-05-07
摘要:目的目前在图像补全领域研究的重点和难点是补全具有复杂结构信息和丰富纹理信息的大破损区域的图像。传统的基于样本块的图像补全算法主要采用规则的模板块和匹配块来进行补全,补全过程中不能充分利用图像的结构或纹理的不规则信息,从而影响算法修复的精度和效率。针对这一问题,本研究提出一种基于不规则块的图像补全算法。方法在该算法中,首先利用结构稀疏度来区分图像的结构信息和纹理信息并基于结构稀疏度和置信度计算破损区域边界点的优先级,然后选择优先级最高的点构造规则模板块。对处于复杂结构区域的模板块,如果其邻域含有已知的结构信息,则膨胀该规则模板并利用其周围的结构信息来辅助构造不规则模板块。接下来,在图像完好区域内搜索与该模板块对应的匹配块,如果该匹配块的邻域包含有效的结构信息,则膨胀该匹配块并补充其周围的结构信息来完善该不规则匹配块。最后,利用该不规则匹配块补全破损区域。对于补全过程中块间接缝造成的视觉不连通问题,本研究利用图像的纹理信息来进行修饰。结果将本文算法与4种修复效果较好的算法(3种基于规则块的算法和1种基于局部敏感哈希的修复算法)进行对比,通过8组经典图像进行实例验证,采用客观评价指标峰值信噪比PSNR和主观视觉连通性进行评价,结果表明本文提出的算法峰值信噪比相较4种对比算法均有04 dB的提高,且在补全的精细度和视觉连通性方面有更佳的效果。结论本文算法在补全含有较复杂结构和丰富纹理的破损自然图像、壁画图像和目标物体移除上有较好的修复效果,普适性较强。关键词:图像补全;结构稀疏度;不规则块;接缝修饰;局部一致性;自适应18|38|0更新时间:2024-05-07 -
 摘要:目的由于人脸图像蕴含着丰富的个人敏感信息,直接发布出来可能会造成个人的隐私泄露。为了保护人脸图像中的隐私信息,本文提出了一种基于傅里叶变换与差分隐私技术相结合的人脸图像发布方法FIP(facial image publication)。方法将人脸图像作为实数域2维矩阵,充分利用离散傅里叶变换技术压缩图像。为了有效均衡由拉普拉斯机制引起的噪音误差以及由傅里叶变换导致的重构误差,引入一种基于指数机制的傅里叶系数选择方法EMK(exponential mechanism-based
摘要:目的由于人脸图像蕴含着丰富的个人敏感信息,直接发布出来可能会造成个人的隐私泄露。为了保护人脸图像中的隐私信息,本文提出了一种基于傅里叶变换与差分隐私技术相结合的人脸图像发布方法FIP(facial image publication)。方法将人脸图像作为实数域2维矩阵,充分利用离散傅里叶变换技术压缩图像。为了有效均衡由拉普拉斯机制引起的噪音误差以及由傅里叶变换导致的重构误差,引入一种基于指数机制的傅里叶系数选择方法EMK(exponential mechanism-based$k$ $\varepsilon $ $k$ $\varepsilon $ 关键词:人脸图像处理;隐私保护;差分隐私;傅里叶变换76|110|2更新时间:2024-05-07
图像处理和编码
-
 摘要:目的特征降维是机器学习领域的热点研究问题。现有的低秩稀疏保持投影方法忽略了原始数据空间和降维后的低维空间之间的信息损失,且现有的方法不能有效处理少量有标签数据和大量无标签数据的情况,针对这两个问题,提出基于低秩稀疏图嵌入的半监督特征选择方法(LRSE)。方法LRSE方法包含两步:第1步是充分利用有标签数据和无标签数据分别学习其低秩稀疏表示,第2步是在目标函数中同时考虑数据降维前后的信息差异和降维过程中的结构信息保持,其中通过最小化信息损失函数使数据中有用的信息尽可能地保留下来,将包含数据全局结构和内部几何结构的低秩稀疏图嵌入在低维空间中使得原始数据空间中的结构信息保留下来,从而能选择出更有判别性的特征。结果将本文方法在6个公共数据集上进行测试,对降维后的数据采用KNN分类验证本文方法的分类准确率,并与其他现有的降维算法进行实验对比,本文方法分类准确率均有所提高,在其中的5个数据集上本文方法都有最高的分类准确率,其分类准确率分别在Wine数据集上比次高算法鲁棒非监督特征选择算法(RUFS)高11.19%,在Breast数据集上比次高算法RUFS高0.57%,在Orlraws10P数据集上比次高算法多聚类特征选择算法(MCFS)高1%,在Coil20数据集上比次高算法MCFS高1.07%,在数据集Orl64上比次高算法MCFS高2.5%。结论本文提出的基于低秩稀疏图嵌入的半监督特征选择算法使得降维后的数据能最大限度地保留原始数据包含的信息,且能有效处理少量有标签样本和大量无标签样本的情况。实验结果表明,本文方法比现有算法的分类效果更好,此外,由于本文方法基于所有的特征都在线性流形上的假设,所以本文方法只适用于线性流形上的数据。关键词:特征选择;半监督学习;低秩表示;稀疏表示;结构嵌入;图像分类11|4|3更新时间:2024-05-07
摘要:目的特征降维是机器学习领域的热点研究问题。现有的低秩稀疏保持投影方法忽略了原始数据空间和降维后的低维空间之间的信息损失,且现有的方法不能有效处理少量有标签数据和大量无标签数据的情况,针对这两个问题,提出基于低秩稀疏图嵌入的半监督特征选择方法(LRSE)。方法LRSE方法包含两步:第1步是充分利用有标签数据和无标签数据分别学习其低秩稀疏表示,第2步是在目标函数中同时考虑数据降维前后的信息差异和降维过程中的结构信息保持,其中通过最小化信息损失函数使数据中有用的信息尽可能地保留下来,将包含数据全局结构和内部几何结构的低秩稀疏图嵌入在低维空间中使得原始数据空间中的结构信息保留下来,从而能选择出更有判别性的特征。结果将本文方法在6个公共数据集上进行测试,对降维后的数据采用KNN分类验证本文方法的分类准确率,并与其他现有的降维算法进行实验对比,本文方法分类准确率均有所提高,在其中的5个数据集上本文方法都有最高的分类准确率,其分类准确率分别在Wine数据集上比次高算法鲁棒非监督特征选择算法(RUFS)高11.19%,在Breast数据集上比次高算法RUFS高0.57%,在Orlraws10P数据集上比次高算法多聚类特征选择算法(MCFS)高1%,在Coil20数据集上比次高算法MCFS高1.07%,在数据集Orl64上比次高算法MCFS高2.5%。结论本文提出的基于低秩稀疏图嵌入的半监督特征选择算法使得降维后的数据能最大限度地保留原始数据包含的信息,且能有效处理少量有标签样本和大量无标签样本的情况。实验结果表明,本文方法比现有算法的分类效果更好,此外,由于本文方法基于所有的特征都在线性流形上的假设,所以本文方法只适用于线性流形上的数据。关键词:特征选择;半监督学习;低秩表示;稀疏表示;结构嵌入;图像分类11|4|3更新时间:2024-05-07 -
 摘要:目的 基于阈值的分割方法能根据像素的信息将图像划分为同类的区域,其中常用的最大模糊相关分割方法,因能利用模糊相关度量划分的适当性,得到较好的分割结果,而广受关注。然而该算法存在划分数需预先确定,阈值的分割结果存在孤立噪声,无法对彩色图像实施分割的问题。为此,提出基于模糊相关图割的非监督层次化分割策略来解决该问题。方法 算法首先将图像划分为若干超像素,以提高层次化图像分割的效率;随后将快速模糊相关算法与图割结合,构成模糊相关图割2-划分算子,在确保分割效率的基础上,解决单一阈值分割存在孤立噪声的问题;最后设计了自顶向下层次化分割策略,利用构建的2-划分算子选择合适的区域及通道,迭代地对超像素实施层次化分割,直到算法收敛,划分数自动确定。结果 对Berkeley分割数据库上300幅图像进行了测试,结果表明算法能有效分割彩色图像,分割精度优于Ncut、JSEG方法,运行时间较这两种方法也提高了近20%。结论 本文算法为最大模糊相关算法在非监督彩色图像分割领域的应用提供指导依据,能用于目标检测和识别领域。关键词:彩色图像分割;非监督分割;超像素;模糊相关;图割21|5|2更新时间:2024-05-07
摘要:目的 基于阈值的分割方法能根据像素的信息将图像划分为同类的区域,其中常用的最大模糊相关分割方法,因能利用模糊相关度量划分的适当性,得到较好的分割结果,而广受关注。然而该算法存在划分数需预先确定,阈值的分割结果存在孤立噪声,无法对彩色图像实施分割的问题。为此,提出基于模糊相关图割的非监督层次化分割策略来解决该问题。方法 算法首先将图像划分为若干超像素,以提高层次化图像分割的效率;随后将快速模糊相关算法与图割结合,构成模糊相关图割2-划分算子,在确保分割效率的基础上,解决单一阈值分割存在孤立噪声的问题;最后设计了自顶向下层次化分割策略,利用构建的2-划分算子选择合适的区域及通道,迭代地对超像素实施层次化分割,直到算法收敛,划分数自动确定。结果 对Berkeley分割数据库上300幅图像进行了测试,结果表明算法能有效分割彩色图像,分割精度优于Ncut、JSEG方法,运行时间较这两种方法也提高了近20%。结论 本文算法为最大模糊相关算法在非监督彩色图像分割领域的应用提供指导依据,能用于目标检测和识别领域。关键词:彩色图像分割;非监督分割;超像素;模糊相关;图割21|5|2更新时间:2024-05-07 -
 摘要:目的 心血管内超声(IVUS)图像内膜和中—外膜(MA)轮廓勾画是冠脉粥样硬化和易损斑块定量评估的必要过程。由于存在斑点噪声、图像伪影和各类斑块,重要组织边界的自动分割是一个非常困难的任务。为此,提出一种用于检测20 MHz心电门控IVUS图像内膜和MA边界方法。方法 首先利用深度全卷积网络(DFCN)学习原始IVUS图像与所对应手动分割图像之间映射,预测出目标或者背景的概率图,实现医学图像语义分割。然后在此基础上,结合心血管先验形状信息,采用数学形态学闭、开操作,平滑内膜和MA边界,降低分割过程中错误分类像素或区域的影响。结果针对来自10位病人的IVUS图像及其标注信息所组成的435幅国际标准公开数据集,从线性回归、Bland-Altman分析和面积交并比(
摘要:目的 心血管内超声(IVUS)图像内膜和中—外膜(MA)轮廓勾画是冠脉粥样硬化和易损斑块定量评估的必要过程。由于存在斑点噪声、图像伪影和各类斑块,重要组织边界的自动分割是一个非常困难的任务。为此,提出一种用于检测20 MHz心电门控IVUS图像内膜和MA边界方法。方法 首先利用深度全卷积网络(DFCN)学习原始IVUS图像与所对应手动分割图像之间映射,预测出目标或者背景的概率图,实现医学图像语义分割。然后在此基础上,结合心血管先验形状信息,采用数学形态学闭、开操作,平滑内膜和MA边界,降低分割过程中错误分类像素或区域的影响。结果针对来自10位病人的IVUS图像及其标注信息所组成的435幅国际标准公开数据集,从线性回归、Bland-Altman分析和面积交并比($ JM$ $ PAD$ $ HD$ $AD $ $ AD$ $ HD$ $ JM$ $ PAD$ 关键词:医学图像分析;深度学习;深度全卷积网络;先验形状信息;心血管内超声;内膜检测;中-外膜检测11|4|2更新时间:2024-05-07 -
 摘要:目的 局部特征描述子在3维目标识别等任务中能够有效地克服噪声、不同点云分辨率、局部遮挡、点云散乱分布等因素的干扰,但是已有3维描述子难以在性能和效率之间取得平衡,为此提出LoVPE(局部多视点投影视图相关编码)特征描述子用于复杂场景中的3维目标识别。方法 首先构建局部参考坐标系,将世界坐标系下的局部表面变换至关键点局部参考坐标系下的局部表面;然后绕局部参考坐标系各坐标轴旋转
摘要:目的 局部特征描述子在3维目标识别等任务中能够有效地克服噪声、不同点云分辨率、局部遮挡、点云散乱分布等因素的干扰,但是已有3维描述子难以在性能和效率之间取得平衡,为此提出LoVPE(局部多视点投影视图相关编码)特征描述子用于复杂场景中的3维目标识别。方法 首先构建局部参考坐标系,将世界坐标系下的局部表面变换至关键点局部参考坐标系下的局部表面;然后绕局部参考坐标系各坐标轴旋转$K$ $N$ $N$ 关键词:3维局部特征描述子;局部参考坐标系;多视点投影;相关编码;3维目标识别13|6|1更新时间:2024-05-07 -
 摘要:目的 针对2维线性鉴别分析提取人脸特征向量稳定性较差、仅对行或列方向提取特征时容易丢失不同行或列间有助于鉴别分析的协方差信息、同时存在特征维数较高的问题,提出一种广义并行2维复判别分析的人脸识别方法。方法 首先对人脸图像进行广义并行2维线性判别分析处理,根据特征值贡献率动态选取特征向量组成正交投影矩阵,完成水平和垂直方向上的投影;其次将处理后得到的两类特征矩阵以复数的实部和虚部形式相加,对融合后的特征矩阵进行广义2维复判别分析处理得到复特征矩阵;然后以复特征矩阵的特征值大小来衡量特征矩阵分量的识别性能,对特征矩阵分量进行重新排序,选取最具鉴别力的分量形成最终表征人脸的特征;最后采用最大相似度分类器比较测试样本与训练样本特征的相似度,进行人脸图像特征的分类识别。结果 在Yale、ORL、FERET、CMU-PIE及LFW人脸数据库上进行实验测试,该方法的最优识别率分别为100%、100%、98.98%、99.76%及98.67%,特征维数在85~90之间,表明该方法对复杂条件下的人脸识别有较高的准确率和较低的空间占有率。结论 该方法能够有效克服2维线性鉴别分析提取特征稳定性差、特征空间中特征重叠、存储系数多、特征维数高的缺点,表现出较高鲁棒性和准确率及较低空间复杂度的特性。关键词:人脸识别;广义并行2维复判别分析;复特征矩阵;最大相似度分类12|5|1更新时间:2024-05-07
摘要:目的 针对2维线性鉴别分析提取人脸特征向量稳定性较差、仅对行或列方向提取特征时容易丢失不同行或列间有助于鉴别分析的协方差信息、同时存在特征维数较高的问题,提出一种广义并行2维复判别分析的人脸识别方法。方法 首先对人脸图像进行广义并行2维线性判别分析处理,根据特征值贡献率动态选取特征向量组成正交投影矩阵,完成水平和垂直方向上的投影;其次将处理后得到的两类特征矩阵以复数的实部和虚部形式相加,对融合后的特征矩阵进行广义2维复判别分析处理得到复特征矩阵;然后以复特征矩阵的特征值大小来衡量特征矩阵分量的识别性能,对特征矩阵分量进行重新排序,选取最具鉴别力的分量形成最终表征人脸的特征;最后采用最大相似度分类器比较测试样本与训练样本特征的相似度,进行人脸图像特征的分类识别。结果 在Yale、ORL、FERET、CMU-PIE及LFW人脸数据库上进行实验测试,该方法的最优识别率分别为100%、100%、98.98%、99.76%及98.67%,特征维数在85~90之间,表明该方法对复杂条件下的人脸识别有较高的准确率和较低的空间占有率。结论 该方法能够有效克服2维线性鉴别分析提取特征稳定性差、特征空间中特征重叠、存储系数多、特征维数高的缺点,表现出较高鲁棒性和准确率及较低空间复杂度的特性。关键词:人脸识别;广义并行2维复判别分析;复特征矩阵;最大相似度分类12|5|1更新时间:2024-05-07 -
 摘要:目的 针对城市实施的路灯杆编码项目,即获取路灯坐标并依次编号,传统的测量方法耗费大量人力物力,且作业周期长,虽然激光测量精度高,但成本也高。为此本文提出一种将基于深度学习的目标检测与全景量测结合自动获取路灯坐标的方法。方法通过Faster R-CNN(faster region convolutional neural network)训练检测模型,对全景图像中的路灯底座进行检测,同时输出检测框坐标,并与HOG(histogram of oriented gradient)特征结合SVM(support vector machine)的检测结果进行效果对比。再将检测框的对角线交点作为路灯脚点,采用核线匹配的方式找到两幅图像中一个或多个路灯相对应的同名像点并进行前方交会得到路灯的实际空间坐标,为路灯编码做好前期工作。结果 采用上述两种方法分别对100幅全景影像的路灯进行检测,结果显示Faster R-CNN具有明显优势,采用Faster R-CNN与全景量测结合自动获取路灯坐标。由于路灯底部到两成像中心的距离大小及3点构成的交会角大小对坐标量测精度具有较大影响,本文分别对距离约为7 m、11 m、18 m的点在交会角为0°180°的范围进行量测结果对比。经验证,交会角在30°150°时,距离越近,对量测精度的影响越小。基于上述规律,在自动量测的120个路灯坐标中筛选出交会角大于30°且小于150°,距离小于20 m的102个点进行精度验证,其空间坐标量测结果的误差最大不超过0.6 m,中误差小于0.3 m,满足路灯编码项目中路灯坐标精度在1 m以内的要求。结论 本文提出了一种自动获取路灯坐标的方法,将基于深度学习的目标检测应用于全景量测中,避免手动选取全景图像的同名像点进行双像量测,节省大量人力物力,具有一定的实践意义。本文方法适用于城市车流量较少的路段或时段,以免车辆遮挡造成过多干扰,对于路灯遮挡严重的街道全景,本文方法存在一定的局限性。关键词:Faster R-CNN;深度学习;路灯检测;全景;前方交会;核线约束13|4|3更新时间:2024-05-07
摘要:目的 针对城市实施的路灯杆编码项目,即获取路灯坐标并依次编号,传统的测量方法耗费大量人力物力,且作业周期长,虽然激光测量精度高,但成本也高。为此本文提出一种将基于深度学习的目标检测与全景量测结合自动获取路灯坐标的方法。方法通过Faster R-CNN(faster region convolutional neural network)训练检测模型,对全景图像中的路灯底座进行检测,同时输出检测框坐标,并与HOG(histogram of oriented gradient)特征结合SVM(support vector machine)的检测结果进行效果对比。再将检测框的对角线交点作为路灯脚点,采用核线匹配的方式找到两幅图像中一个或多个路灯相对应的同名像点并进行前方交会得到路灯的实际空间坐标,为路灯编码做好前期工作。结果 采用上述两种方法分别对100幅全景影像的路灯进行检测,结果显示Faster R-CNN具有明显优势,采用Faster R-CNN与全景量测结合自动获取路灯坐标。由于路灯底部到两成像中心的距离大小及3点构成的交会角大小对坐标量测精度具有较大影响,本文分别对距离约为7 m、11 m、18 m的点在交会角为0°180°的范围进行量测结果对比。经验证,交会角在30°150°时,距离越近,对量测精度的影响越小。基于上述规律,在自动量测的120个路灯坐标中筛选出交会角大于30°且小于150°,距离小于20 m的102个点进行精度验证,其空间坐标量测结果的误差最大不超过0.6 m,中误差小于0.3 m,满足路灯编码项目中路灯坐标精度在1 m以内的要求。结论 本文提出了一种自动获取路灯坐标的方法,将基于深度学习的目标检测应用于全景量测中,避免手动选取全景图像的同名像点进行双像量测,节省大量人力物力,具有一定的实践意义。本文方法适用于城市车流量较少的路段或时段,以免车辆遮挡造成过多干扰,对于路灯遮挡严重的街道全景,本文方法存在一定的局限性。关键词:Faster R-CNN;深度学习;路灯检测;全景;前方交会;核线约束13|4|3更新时间:2024-05-07
图像分析和识别
-
 摘要:目的2维转3维技术可以将现有的丰富2维图像资源快速有效地转为立体图像,但是现有方法只能对树木的整体进行深度估计,所生成的图像无法表现出树木的立体结构。为此,提出一种树木结构层次细化的立体树木图像构建方法。方法首先利用Lab颜色模型下的像素色差区别将2维树木图像的树干区域和树冠区域分割开来,并对树冠区域进行再分割;然后,在深度梯度假设思想基础上建立多种类型的深度模板,结合深度模板和树冠的区域信息为典型树木对象构建初始深度图,并通过基础深度梯度图组合的方式为非典型树木进行个性化深度构建;最后,根据应用场景对树木深度信息进行自适应调整与优化,将树木图像合成到背景图像中,并构建立体图像。结果对5组不同的树木图像及背景图像进行了立体树木图像的构建与合成。结果表明,不同形态的树木图像都能生成具有层次感的深度图并自适应地合成到立体背景图像中,构建树木图像深度图的时间与原始树木图像的尺寸成正比,而构建立体树木图像并合成到背景中所需时间在2~4 s之间。对立体图像质量的主观评价测试中,这些图像的评分均达到良好级别以上,部分立体图像达到了优秀级别。结论该方法充分利用了树木的形态结构特征,能同时适用于典型和非典型树木,所构建的立体树木图像质量较高,具有丰富的层次感,并具有舒适的立体观看效果。关键词:树木图像;立体图像;图像合成;深度模板;树木结构11|4|3更新时间:2024-05-07
摘要:目的2维转3维技术可以将现有的丰富2维图像资源快速有效地转为立体图像,但是现有方法只能对树木的整体进行深度估计,所生成的图像无法表现出树木的立体结构。为此,提出一种树木结构层次细化的立体树木图像构建方法。方法首先利用Lab颜色模型下的像素色差区别将2维树木图像的树干区域和树冠区域分割开来,并对树冠区域进行再分割;然后,在深度梯度假设思想基础上建立多种类型的深度模板,结合深度模板和树冠的区域信息为典型树木对象构建初始深度图,并通过基础深度梯度图组合的方式为非典型树木进行个性化深度构建;最后,根据应用场景对树木深度信息进行自适应调整与优化,将树木图像合成到背景图像中,并构建立体图像。结果对5组不同的树木图像及背景图像进行了立体树木图像的构建与合成。结果表明,不同形态的树木图像都能生成具有层次感的深度图并自适应地合成到立体背景图像中,构建树木图像深度图的时间与原始树木图像的尺寸成正比,而构建立体树木图像并合成到背景中所需时间在2~4 s之间。对立体图像质量的主观评价测试中,这些图像的评分均达到良好级别以上,部分立体图像达到了优秀级别。结论该方法充分利用了树木的形态结构特征,能同时适用于典型和非典型树木,所构建的立体树木图像质量较高,具有丰富的层次感,并具有舒适的立体观看效果。关键词:树木图像;立体图像;图像合成;深度模板;树木结构11|4|3更新时间:2024-05-07 -
 摘要:目的摄像机旋转扫描条件下的动目标检测研究中,传统的线性模型无法解决摄像机旋转扫描运动带来的图像间非线性变换问题,导致图像补偿不准确,在动目标检测时将引起较大误差,造成动目标虚假检测。为解决这一问题,提出了一种面阵摄像机旋转扫描条件下的图像补偿方法,其特点是能够同时实现背景运动补偿和图像非线性变换补偿,从而实现动目标的快速可靠检测。方法首先进行图像匹配,然后建立摄像机旋转扫描非线性模型,通过参数空间变换将其转化为线性求解问题,采用Hough变换实现该方程参数的快速鲁棒估计。解决摄像机旋转扫描条件下获取的图像间非线性变换问题,从而实现图像准确补偿。在此基础上,可以利用帧间差分等方法检测出运动目标。结果实验结果表明,在摄像机旋转扫描条件下,本文方法能够同时实现图像间的背景运动补偿和非线性变换补偿,可以去除大部分由于立体视差效应(parallax effects)产生的匹配错误。并且在实验中,本文方法处理速度可以达到50帧/s,满足实时性要求。结论在面阵摄像机旋转扫描的条件下,相比于传统的基于线性模型的图像补偿方法,本文方法能够快速、准确地在背景补偿的基础上同时解决图像间非线性变换问题,从而更好地提取出运动目标,具有一定的实用价值。关键词:旋转扫描;非线性变换;Hough变换;帧间差分;图像补偿13|4|0更新时间:2024-05-07
摘要:目的摄像机旋转扫描条件下的动目标检测研究中,传统的线性模型无法解决摄像机旋转扫描运动带来的图像间非线性变换问题,导致图像补偿不准确,在动目标检测时将引起较大误差,造成动目标虚假检测。为解决这一问题,提出了一种面阵摄像机旋转扫描条件下的图像补偿方法,其特点是能够同时实现背景运动补偿和图像非线性变换补偿,从而实现动目标的快速可靠检测。方法首先进行图像匹配,然后建立摄像机旋转扫描非线性模型,通过参数空间变换将其转化为线性求解问题,采用Hough变换实现该方程参数的快速鲁棒估计。解决摄像机旋转扫描条件下获取的图像间非线性变换问题,从而实现图像准确补偿。在此基础上,可以利用帧间差分等方法检测出运动目标。结果实验结果表明,在摄像机旋转扫描条件下,本文方法能够同时实现图像间的背景运动补偿和非线性变换补偿,可以去除大部分由于立体视差效应(parallax effects)产生的匹配错误。并且在实验中,本文方法处理速度可以达到50帧/s,满足实时性要求。结论在面阵摄像机旋转扫描的条件下,相比于传统的基于线性模型的图像补偿方法,本文方法能够快速、准确地在背景补偿的基础上同时解决图像间非线性变换问题,从而更好地提取出运动目标,具有一定的实用价值。关键词:旋转扫描;非线性变换;Hough变换;帧间差分;图像补偿13|4|0更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的现有刚体破碎仿真模拟中,基于物理受力分析的方法往往难以应用在对实时性要求较高的场景中;而基于非物理方法的破碎模拟,破碎效果大多缺乏多样性。为了使得破碎模拟同时满足实时性和破碎效果多样化,提出了一种多样化实时刚体破碎模拟方法。方法进行破碎模拟时首先由选定的种子点生成类型得到种子点集,采用Sweep Plane算法生成Voronoi图后基于Voronoi图信息对模型进行空间剖分;然后选择破碎时行为模拟方式,对物体破碎时所受外力进行模拟;最后对破碎时碰撞检测及碰撞后碎片的运动过程进行模拟并渲染显示。结果通过组合不同的种子点生成类型和破碎时行为模拟方式,得到了多样化的刚体破碎效果。对单个刚体进行破碎模拟时,碎片数目不超过200个时帧率可以达到75帧/s,满足实时性的需求;对多个可破碎目标同时存在的复杂场景,破碎仿真模拟的平均帧率可以达到50帧/s,同样满足实时性要求;与现有方法对比的结果也验证了本文方法在计算效率和破碎效果多样性两方面达到了较好的平衡。结论本文方法在满足实时性要求的同时,丰富了刚体破碎的效果,不同种子点生成类型和破碎时行为模拟方式的组合可以实现破碎效果多样性。关键词:计算机仿真;虚拟现实;刚体破碎模拟;Voronoi图;多样化破坏;碰撞效果28|7|1更新时间:2024-05-07
摘要:目的现有刚体破碎仿真模拟中,基于物理受力分析的方法往往难以应用在对实时性要求较高的场景中;而基于非物理方法的破碎模拟,破碎效果大多缺乏多样性。为了使得破碎模拟同时满足实时性和破碎效果多样化,提出了一种多样化实时刚体破碎模拟方法。方法进行破碎模拟时首先由选定的种子点生成类型得到种子点集,采用Sweep Plane算法生成Voronoi图后基于Voronoi图信息对模型进行空间剖分;然后选择破碎时行为模拟方式,对物体破碎时所受外力进行模拟;最后对破碎时碰撞检测及碰撞后碎片的运动过程进行模拟并渲染显示。结果通过组合不同的种子点生成类型和破碎时行为模拟方式,得到了多样化的刚体破碎效果。对单个刚体进行破碎模拟时,碎片数目不超过200个时帧率可以达到75帧/s,满足实时性的需求;对多个可破碎目标同时存在的复杂场景,破碎仿真模拟的平均帧率可以达到50帧/s,同样满足实时性要求;与现有方法对比的结果也验证了本文方法在计算效率和破碎效果多样性两方面达到了较好的平衡。结论本文方法在满足实时性要求的同时,丰富了刚体破碎的效果,不同种子点生成类型和破碎时行为模拟方式的组合可以实现破碎效果多样性。关键词:计算机仿真;虚拟现实;刚体破碎模拟;Voronoi图;多样化破坏;碰撞效果28|7|1更新时间:2024-05-07 -
 摘要:目的本文旨在构造一种含形状参数的Bézier曲线,要求该曲线定义在代数多项式空间上,其基函数的次数与相同数量控制顶点所需Bernstein基函数的次数相同,对基函数以及相应曲线的计算要尽可能简单,并且要给出常见设计要求下曲线中形状参数的选取方案。方法以三次Bézier曲线为初始研究对象,依据由可调控制顶点定义可调曲线的思想,在两个内控制顶点中引入参数,与Bernstein基函数作线性组合生成形状可调曲线,再将曲线表达式改写成固定控制顶点与含参数的调配函数的线性组合,从而得出三次Bernstein基函数的含参数扩展基,借助递推公式得出更高次的含参数扩展基,然后观察基函数表达式的规律,给出所有含参数扩展基统一的显示表达式,分析了扩展基的性质,并由之定义含参数的曲线,分析了曲线的性质,给出了曲线的几何作图法以及光滑拼接条件,以曲线拉伸能量、弯曲能量、扭曲能量近似最小为目标,推导了曲线中形状参数的计算公式,再通过曲线图和曲率图对比分析了不同能量目标所得曲线的差异。结果由于所给含参数的扩展基并未提升Bernstein基函数的次数,且具有统一的显示表达式,因此本文方法在赋予Bézier曲线形状调整能力的同时并未增加计算量,由于提供了可以直接使用的形状参数的计算公式,因此在使用该方法时,符合设计要求的形状参数的确定变得简单,数值实例直观显示了所给曲线造型方法以及曲线中形状参数选取方案的正确性与有效性,体现了本文方法较文献中类似方法的优越之处。结论所给含参数扩展基的构造方法以及形状参数的选取方法具有一般性,该方法可以推广至构造含形状参数的三角域Bézier曲面。关键词:曲线造型;Bezier曲线;形状参数;能量优化;参数选择32|115|2更新时间:2024-05-07
摘要:目的本文旨在构造一种含形状参数的Bézier曲线,要求该曲线定义在代数多项式空间上,其基函数的次数与相同数量控制顶点所需Bernstein基函数的次数相同,对基函数以及相应曲线的计算要尽可能简单,并且要给出常见设计要求下曲线中形状参数的选取方案。方法以三次Bézier曲线为初始研究对象,依据由可调控制顶点定义可调曲线的思想,在两个内控制顶点中引入参数,与Bernstein基函数作线性组合生成形状可调曲线,再将曲线表达式改写成固定控制顶点与含参数的调配函数的线性组合,从而得出三次Bernstein基函数的含参数扩展基,借助递推公式得出更高次的含参数扩展基,然后观察基函数表达式的规律,给出所有含参数扩展基统一的显示表达式,分析了扩展基的性质,并由之定义含参数的曲线,分析了曲线的性质,给出了曲线的几何作图法以及光滑拼接条件,以曲线拉伸能量、弯曲能量、扭曲能量近似最小为目标,推导了曲线中形状参数的计算公式,再通过曲线图和曲率图对比分析了不同能量目标所得曲线的差异。结果由于所给含参数的扩展基并未提升Bernstein基函数的次数,且具有统一的显示表达式,因此本文方法在赋予Bézier曲线形状调整能力的同时并未增加计算量,由于提供了可以直接使用的形状参数的计算公式,因此在使用该方法时,符合设计要求的形状参数的确定变得简单,数值实例直观显示了所给曲线造型方法以及曲线中形状参数选取方案的正确性与有效性,体现了本文方法较文献中类似方法的优越之处。结论所给含参数扩展基的构造方法以及形状参数的选取方法具有一般性,该方法可以推广至构造含形状参数的三角域Bézier曲面。关键词:曲线造型;Bezier曲线;形状参数;能量优化;参数选择32|115|2更新时间:2024-05-07
计算机图形学
-
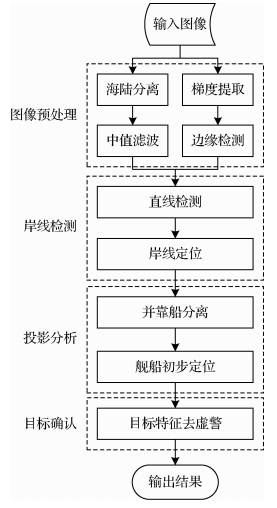 摘要:目的高分辨率遥感图像中,靠岸舰船检测有着广泛的应用前景,其主要难点在于舰船与港口陆地在空间上紧邻,在颜色和纹理特征上相似,舰船与港口陆地难以分割。针对这种情况,利用港口岸线平直的几何特点和靠岸舰船多为舷靠的停泊特点,提出一种基于投影分析的靠岸舰船检测方法。方法首先,对原始图像进行预处理,利用K-means聚类算法与区域生长算法相结合的方式得到海陆分割图像,利用Sobel算子与Otsu分割结合的方式获取边缘图像;然后,通过改进的Hough变换提取直线特征,结合港岸几何特性定位港口岸线;再将海陆分割后的二值图像向沿岸线和垂直岸线两个方向进行投影,根据沿岸线方向投影形态确定和分离并靠舰船,根据垂直岸线方向的投影形态定位舰船目标;最后,利用舰船尺寸、长宽比、最小外接矩形占空比特征去除虚警。结果在15个港口场景不同分辨率的遥感图像测试集上,本文方法整体检测率达到85.4%,虚警率达17.2%;限定分辨率范围在2~4 m的情形下,检测率提高到93.5%,虚警率降低至5.3%。结论本文方法简单有效,无需港口先验信息,适用于多尺度和多方向的靠岸舰船目标检测任务,对不同类型舰船形态差异具有鲁棒性,且能够分离并靠舰船。关键词:靠岸舰船检测;岸线检测;投影分析;高分辨率遥感图像;并靠船检测12|4|4更新时间:2024-05-07
摘要:目的高分辨率遥感图像中,靠岸舰船检测有着广泛的应用前景,其主要难点在于舰船与港口陆地在空间上紧邻,在颜色和纹理特征上相似,舰船与港口陆地难以分割。针对这种情况,利用港口岸线平直的几何特点和靠岸舰船多为舷靠的停泊特点,提出一种基于投影分析的靠岸舰船检测方法。方法首先,对原始图像进行预处理,利用K-means聚类算法与区域生长算法相结合的方式得到海陆分割图像,利用Sobel算子与Otsu分割结合的方式获取边缘图像;然后,通过改进的Hough变换提取直线特征,结合港岸几何特性定位港口岸线;再将海陆分割后的二值图像向沿岸线和垂直岸线两个方向进行投影,根据沿岸线方向投影形态确定和分离并靠舰船,根据垂直岸线方向的投影形态定位舰船目标;最后,利用舰船尺寸、长宽比、最小外接矩形占空比特征去除虚警。结果在15个港口场景不同分辨率的遥感图像测试集上,本文方法整体检测率达到85.4%,虚警率达17.2%;限定分辨率范围在2~4 m的情形下,检测率提高到93.5%,虚警率降低至5.3%。结论本文方法简单有效,无需港口先验信息,适用于多尺度和多方向的靠岸舰船目标检测任务,对不同类型舰船形态差异具有鲁棒性,且能够分离并靠舰船。关键词:靠岸舰船检测;岸线检测;投影分析;高分辨率遥感图像;并靠船检测12|4|4更新时间:2024-05-07
遥感图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0