
最新刊期
2018 年 第 23 卷 第 8 期
-
 摘要:目的随着军事侦察任务设备的发展,红外与可见光侦察技术成为军事装备中的主要侦察手段。研究视觉目标跟踪技术对提高任务设备的全天候目标侦察、目标跟踪、目标定位等战场情报获取能力具有重要意义。目前,对视觉目标跟踪技术的研究越来越深入,目标跟踪的方法和种类也越来越丰富。本文对目前应用较为广泛的4种视觉目标跟踪方法进行研究综述,为后续国内外研究者对目标跟踪相关理论及发展研究工作提供基础。方法通过对视觉目标跟踪技术难点问题进行分析,根据目标跟踪方法建模方式的不同,将视觉目标跟踪方法分为生成式模型方法与判别式模型方法。分别对生成式模型跟踪算法中的均值漂移目标跟踪方法和粒子滤波目标跟踪方法,判别式模型跟踪算法中的相关滤波目标跟踪方法和深度学习目标跟踪方法进行研究。首先分别对4种跟踪算法的基本原理进行介绍,然后针对4种跟踪算法基本原理的不足和对应目标跟踪中的难点问题进行分析,最后针对目标跟踪的难点问题,给出对应算法的主流改进方案。结果针对视觉目标跟踪相关技术研究进展,结合无人机侦察任务需求,对跟踪算法实际应用中存在的重点解决问题与相关目标跟踪的难点问题进行分析,给出目前的解决方案与不足,探讨研究未来无人机目标侦察跟踪技术的发展方向。结论视觉目标跟踪技术已经取得了显著的进展,在侦察任务中的应用越来越广泛。但目标跟踪技术仍然是非常具有挑战性的问题,目标跟踪中的相关理论有待进一步完善和改进,由于实际应用中的场景复杂,目标跟踪的难点问题的挑战性更大,因此容易导致跟踪效果不佳。针对不同的应用环境,结合具体不同军事装备的特点,研究相对精确和鲁棒并且满足实时性要求的视觉目标跟踪算法,对提升装备的全天候侦察目标信息获取能力具有重要意义。关键词:目标跟踪;均值漂移;粒子滤波;相关滤波;深度学习32|257|38更新时间:2024-08-15
摘要:目的随着军事侦察任务设备的发展,红外与可见光侦察技术成为军事装备中的主要侦察手段。研究视觉目标跟踪技术对提高任务设备的全天候目标侦察、目标跟踪、目标定位等战场情报获取能力具有重要意义。目前,对视觉目标跟踪技术的研究越来越深入,目标跟踪的方法和种类也越来越丰富。本文对目前应用较为广泛的4种视觉目标跟踪方法进行研究综述,为后续国内外研究者对目标跟踪相关理论及发展研究工作提供基础。方法通过对视觉目标跟踪技术难点问题进行分析,根据目标跟踪方法建模方式的不同,将视觉目标跟踪方法分为生成式模型方法与判别式模型方法。分别对生成式模型跟踪算法中的均值漂移目标跟踪方法和粒子滤波目标跟踪方法,判别式模型跟踪算法中的相关滤波目标跟踪方法和深度学习目标跟踪方法进行研究。首先分别对4种跟踪算法的基本原理进行介绍,然后针对4种跟踪算法基本原理的不足和对应目标跟踪中的难点问题进行分析,最后针对目标跟踪的难点问题,给出对应算法的主流改进方案。结果针对视觉目标跟踪相关技术研究进展,结合无人机侦察任务需求,对跟踪算法实际应用中存在的重点解决问题与相关目标跟踪的难点问题进行分析,给出目前的解决方案与不足,探讨研究未来无人机目标侦察跟踪技术的发展方向。结论视觉目标跟踪技术已经取得了显著的进展,在侦察任务中的应用越来越广泛。但目标跟踪技术仍然是非常具有挑战性的问题,目标跟踪中的相关理论有待进一步完善和改进,由于实际应用中的场景复杂,目标跟踪的难点问题的挑战性更大,因此容易导致跟踪效果不佳。针对不同的应用环境,结合具体不同军事装备的特点,研究相对精确和鲁棒并且满足实时性要求的视觉目标跟踪算法,对提升装备的全天候侦察目标信息获取能力具有重要意义。关键词:目标跟踪;均值漂移;粒子滤波;相关滤波;深度学习32|257|38更新时间:2024-08-15
综述

-
 摘要:目的传统误差扩散或恢复函数的多载体密图分存会对嵌密载体视觉质量造成较大影响,同时恢复函数需单独设计,只适用于二值或灰度图像,且通过简单Arnold置乱或异或加密仅能提供有限的安全性。针对此问题,提出结合EMD-cl嵌入的多载体密图分存方法。方法采用双哈希MD5和SHA-1值产生多组与密图属性和用户密钥有关的置乱参数,驱动2维双尺度矩形映射来改变载体像素对应关系,然后将置乱后载体同位置像素构成向量,按扩展约瑟夫遍历映射分配基向量,通过EMD-cl嵌入秘密像素,从而将密图分存到多张载体中。结果采用EMD-cl提高了嵌密载体视觉质量且不需额外设计恢复函数,可针对不同分辨率和灰度阶密图分存。所提方法载体像素位置和EMD-cl基向量都与密图MD5和SHA-1值以及用户密钥紧密绑定,仅有正确用户密钥和密图MD5和SHA-1值才能对密图恢复,并可通过第三方公信方托管的参与者分存信息MD5和SHA-1值使得所述策略具备认证能力。所提方法密钥空间为1.193 6×10118,可抵抗暴力破解。实验结果表明,结合EMD-cl,所提方法具有较好的嵌密载体视觉质量,NC趋近于1,对于EMD-3l,嵌密载体PSNR均接近50 dB;对于EMD-5l和EMD-7l,PSNR分别达到45 dB和42 dB,而传统方法,PSNR最好仅为42 dB。所提方法可分存不同分辨率和灰度阶密图,可对参与者密钥分存信息的真实性进行检验且对密图哈希和用户密钥极度敏感。结论所提方法具有较低复杂度,较高安全性和普适性及认证能力,在整体性能上优于传统误差扩散或恢复函数的多载体密图分存方法,适用于对嵌密载体视觉质量要求高和针对不同分辨率和灰度阶密图分存的安全场景中。关键词:全方向扩展;多载体;图像分存;2维双尺度矩形映射;约瑟夫遍历映射;哈希函数;误差扩散;恢复函数11|5|1更新时间:2024-08-15
摘要:目的传统误差扩散或恢复函数的多载体密图分存会对嵌密载体视觉质量造成较大影响,同时恢复函数需单独设计,只适用于二值或灰度图像,且通过简单Arnold置乱或异或加密仅能提供有限的安全性。针对此问题,提出结合EMD-cl嵌入的多载体密图分存方法。方法采用双哈希MD5和SHA-1值产生多组与密图属性和用户密钥有关的置乱参数,驱动2维双尺度矩形映射来改变载体像素对应关系,然后将置乱后载体同位置像素构成向量,按扩展约瑟夫遍历映射分配基向量,通过EMD-cl嵌入秘密像素,从而将密图分存到多张载体中。结果采用EMD-cl提高了嵌密载体视觉质量且不需额外设计恢复函数,可针对不同分辨率和灰度阶密图分存。所提方法载体像素位置和EMD-cl基向量都与密图MD5和SHA-1值以及用户密钥紧密绑定,仅有正确用户密钥和密图MD5和SHA-1值才能对密图恢复,并可通过第三方公信方托管的参与者分存信息MD5和SHA-1值使得所述策略具备认证能力。所提方法密钥空间为1.193 6×10118,可抵抗暴力破解。实验结果表明,结合EMD-cl,所提方法具有较好的嵌密载体视觉质量,NC趋近于1,对于EMD-3l,嵌密载体PSNR均接近50 dB;对于EMD-5l和EMD-7l,PSNR分别达到45 dB和42 dB,而传统方法,PSNR最好仅为42 dB。所提方法可分存不同分辨率和灰度阶密图,可对参与者密钥分存信息的真实性进行检验且对密图哈希和用户密钥极度敏感。结论所提方法具有较低复杂度,较高安全性和普适性及认证能力,在整体性能上优于传统误差扩散或恢复函数的多载体密图分存方法,适用于对嵌密载体视觉质量要求高和针对不同分辨率和灰度阶密图分存的安全场景中。关键词:全方向扩展;多载体;图像分存;2维双尺度矩形映射;约瑟夫遍历映射;哈希函数;误差扩散;恢复函数11|5|1更新时间:2024-08-15
图像处理和编码
-
 摘要:目的由于CV模型仅利用了图像的全局信息,其对灰度不均匀图像的分割效果不理想,同时在分割弱边缘和弱纹理图像时,优化易陷入局部最优从而导致分割效率低下,且对初始位置的选择较为敏感。针对这些问题,提出一种结合分数阶微分和图像局部信息的CV模型。方法首先将分数阶梯度信息融入图像的局部信息中,用来替代CV模型的整数阶全局信息,并建立自适应计算分数阶最佳阶次的数学模型,然后在模型中加入符号距离的约束项。结果一方面,用局部信息代替全局信息,可以在一定程度上解决CV模型对灰度不均匀图像分割效果不理想的问题。另一方面,将Grünwald-Letnikov分数阶梯度信息融合到局部信息中,当分数阶阶次0 < α < 1时,增加了图像灰度不均匀、弱边缘、弱纹理区域的梯度信息,从而增加了演化驱动力避免演化曲线陷入局部最优,有效地解决了图像因灰度变化不大导致演化曲线驱动力小的问题,在一定程度上解决了模型对初始轮廓位置选择和对噪声敏感的问题。同时为了解决人工选取最佳分数阶阶次费时费力的问题,根据图像的梯度模值和信息熵建立计算分数阶最佳阶次的数学模型,将此自适应分数阶模型应用到算法之中,以自适应确定最佳分数阶阶次。此外,为了避免模型的重新初始化,在模型中加入符号距离的约束项,从而提高了曲线的演化效率。结论理论分析和实验结果均表明,该算法能够较好地分割灰度不均匀、弱边缘和弱纹理区域的图像,并能根据图像特征自适应确定最佳分数阶阶次,提高了分割精度和分割效率,且对初始轮廓位置选择及噪声均具有一定的鲁棒性。关键词:图像分割;分数阶微分;局部信息;CV模型;自适应;灰度不均匀41|43|1更新时间:2024-08-15
摘要:目的由于CV模型仅利用了图像的全局信息,其对灰度不均匀图像的分割效果不理想,同时在分割弱边缘和弱纹理图像时,优化易陷入局部最优从而导致分割效率低下,且对初始位置的选择较为敏感。针对这些问题,提出一种结合分数阶微分和图像局部信息的CV模型。方法首先将分数阶梯度信息融入图像的局部信息中,用来替代CV模型的整数阶全局信息,并建立自适应计算分数阶最佳阶次的数学模型,然后在模型中加入符号距离的约束项。结果一方面,用局部信息代替全局信息,可以在一定程度上解决CV模型对灰度不均匀图像分割效果不理想的问题。另一方面,将Grünwald-Letnikov分数阶梯度信息融合到局部信息中,当分数阶阶次0 < α < 1时,增加了图像灰度不均匀、弱边缘、弱纹理区域的梯度信息,从而增加了演化驱动力避免演化曲线陷入局部最优,有效地解决了图像因灰度变化不大导致演化曲线驱动力小的问题,在一定程度上解决了模型对初始轮廓位置选择和对噪声敏感的问题。同时为了解决人工选取最佳分数阶阶次费时费力的问题,根据图像的梯度模值和信息熵建立计算分数阶最佳阶次的数学模型,将此自适应分数阶模型应用到算法之中,以自适应确定最佳分数阶阶次。此外,为了避免模型的重新初始化,在模型中加入符号距离的约束项,从而提高了曲线的演化效率。结论理论分析和实验结果均表明,该算法能够较好地分割灰度不均匀、弱边缘和弱纹理区域的图像,并能根据图像特征自适应确定最佳分数阶阶次,提高了分割精度和分割效率,且对初始轮廓位置选择及噪声均具有一定的鲁棒性。关键词:图像分割;分数阶微分;局部信息;CV模型;自适应;灰度不均匀41|43|1更新时间:2024-08-15 -
 摘要:目的相比静态表情图片,视频序列中蕴含更多的情感信息,视频序列中的具有明显表情的序列在特征提取与识别中具有关键作用,但是视频中同时存在的中性表情也可能会对模型参数的训练造成干扰,影响最终的判别。为了减少这种干扰带来的误差,本文对动态时间规整算法进行改进,提出一种滑动窗口动态时间规整算法(SWDTW)来自动选取视频中表情表现明显的图片序列;同时,为了解决人脸图像受环境光照因素影响较大和传统特征提取过程中存在过多人为干预的问题,构建一种基于深度卷积神经网络的人脸视频序列处理方法。方法首先截取表情视频中人脸正面帧,用梯度方向直方图特征计算代价矩阵,并在代价矩阵上增加滑动窗口机制,计算所有滑动窗口的平均距离;然后通过平均距离最小值选取全局最优表情序列;最后采用深度卷积神经网络对规整后的人脸表情图像序列进行无监督学习和面部表情分类,统计视频序列图像分类概率和,进而得出视频序列的表情类别。结果在CK+与MMI数据库上进行5次交叉实验,分别取得了92.54%和74.67%的平均识别率,与随机选取视频序列相比,分别提高了19.86%和22.24%;此外,与目前一些优秀的视频表情识别方法相比,也表现出了优越性。结论本文提出的SWDTW不仅有效地实现了表情序列的选取,而且增强了卷积神经网络在视频面部表情分类中的鲁棒性,提高了视频人脸表情分析的自适应性度和识别率。关键词:人脸表情识别;视频序列选取;滑动窗口动态时间规整;特征提取;卷积神经网络13|4|6更新时间:2024-08-15
摘要:目的相比静态表情图片,视频序列中蕴含更多的情感信息,视频序列中的具有明显表情的序列在特征提取与识别中具有关键作用,但是视频中同时存在的中性表情也可能会对模型参数的训练造成干扰,影响最终的判别。为了减少这种干扰带来的误差,本文对动态时间规整算法进行改进,提出一种滑动窗口动态时间规整算法(SWDTW)来自动选取视频中表情表现明显的图片序列;同时,为了解决人脸图像受环境光照因素影响较大和传统特征提取过程中存在过多人为干预的问题,构建一种基于深度卷积神经网络的人脸视频序列处理方法。方法首先截取表情视频中人脸正面帧,用梯度方向直方图特征计算代价矩阵,并在代价矩阵上增加滑动窗口机制,计算所有滑动窗口的平均距离;然后通过平均距离最小值选取全局最优表情序列;最后采用深度卷积神经网络对规整后的人脸表情图像序列进行无监督学习和面部表情分类,统计视频序列图像分类概率和,进而得出视频序列的表情类别。结果在CK+与MMI数据库上进行5次交叉实验,分别取得了92.54%和74.67%的平均识别率,与随机选取视频序列相比,分别提高了19.86%和22.24%;此外,与目前一些优秀的视频表情识别方法相比,也表现出了优越性。结论本文提出的SWDTW不仅有效地实现了表情序列的选取,而且增强了卷积神经网络在视频面部表情分类中的鲁棒性,提高了视频人脸表情分析的自适应性度和识别率。关键词:人脸表情识别;视频序列选取;滑动窗口动态时间规整;特征提取;卷积神经网络13|4|6更新时间:2024-08-15 -
 摘要:目的现实中采集到的人脸图像通常受到光照、遮挡等环境因素的影响,使得同一类的人脸图像具有不同程度的差异性,不同类的人脸图像又具有不同程度的相似性,这极大地影响了人脸识别的准确性。为了解决上述问题对人脸识别造成的影响,在低秩矩阵恢复理论的基础上提出了具有识别力的结构化低秩字典学习的人脸识别算法。方法该算法基于训练样本的标签信息将低秩正则化以及结构化稀疏同时引入到学习的具有识别力的字典上。在字典学习过程中,首先利用样本的重建误差约束样本与字典之间的关系;其次将Fisher准则应用到稀疏编码过程中,使其编码系数具有识别能力;由于训练样本中的噪声信息会影响字典的识别力,所以在低秩矩阵恢复理论的基础上将低秩正则化应用到字典学习过程中;接着,在字典学习过程中加入了结构化稀疏使其不丢失结构信息以保证对样本进行最优分类;最后再利用误差重构法对测试样本进行分类识别。结果本文算法在AR以及ORL人脸数据库上分别进行了实验仿真。在AR人脸数据库中,为了分析样本不同维数对实验结果造成的影响,选取了第一时期拍摄的每人6幅图像,包括1幅围巾遮挡,2幅墨镜遮挡以及3幅脸部表情变化以及光照变化(未被遮挡)的图像作为训练样本,同时选取相同组合的样本图像作为测试样本,无论哪种方法,图像的维度越高识别率越高。对比SRC(sparse representation based on classification)算法与DKSVD(discriminative K-means singular value decomposition)算法的识别率可知,DKSVD算法通过字典学习减缓了训练样本中的不确定因素对识别结果的影响;对比DLRD_SR(discriminative low-rank dictionary learning for sparse representation)算法与FDDL(Fisher discriminative dictionary learning)算法的识别率可知,当图像有遮挡等噪声信息存在时,字典低秩化可以提高至少5.8%的识别率;对比本文算法与DLRD_SR算法可知,在字典学习的过程中加入Fisher准则后识别率显著提高,同时理想稀疏值能保证对样本进行最优的分类。当样本图像的维度达到500维时人脸图像在有围巾、墨镜遮挡的情况下识别率可达到85.2%;其中墨镜和围巾的遮挡程度分别可以看成是人脸图像的20%和40%,为了验证本文算法在不同脸部表情变化、光照改变以及遮挡情况下的有效性,根据训练样本的具体图像组合情况进行实验。无论哪种样本图像组合,本文算法在有遮挡存在的样本识别中具有显著优势。在训练样本只包含脸部表情变化、光照变化以及墨镜遮挡图像的情况下,本文算法的识别率高于其他算法至少2.7%,在训练样本只包含脸部表情变化、光照变化以及围巾遮挡图像的情况下,本文算法的识别率高于其他算法至少3.6%,在训练样本包含脸部表情变化、光照变化、围巾遮挡以及墨镜遮挡图像的情况下,其识别率高于其他算法至少1.9%。在ORL人脸数据库中,人脸图像在无遮挡的情况下识别率达到95.2%,稍低于FDDL算法的识别率;在随机块遮挡程度达到20%时,相比较于SRC算法、DKSVD算法、FDDL算法以及DLRD_SR算法,本文算法的识别率最高;当随机块遮挡程度达到50%时,以上算法的识别率均不高,但本文算法的其识别率仍然最高。结论本文算法在人脸图像受到遮挡等因素的影响时具有一定的鲁棒性,实验结果表明该算法在人脸识别方面具有可行性。关键词:人脸识别;低秩正则化;标签信息;结构化稀疏;Fisher准则;字典学习12|4|1更新时间:2024-08-15
摘要:目的现实中采集到的人脸图像通常受到光照、遮挡等环境因素的影响,使得同一类的人脸图像具有不同程度的差异性,不同类的人脸图像又具有不同程度的相似性,这极大地影响了人脸识别的准确性。为了解决上述问题对人脸识别造成的影响,在低秩矩阵恢复理论的基础上提出了具有识别力的结构化低秩字典学习的人脸识别算法。方法该算法基于训练样本的标签信息将低秩正则化以及结构化稀疏同时引入到学习的具有识别力的字典上。在字典学习过程中,首先利用样本的重建误差约束样本与字典之间的关系;其次将Fisher准则应用到稀疏编码过程中,使其编码系数具有识别能力;由于训练样本中的噪声信息会影响字典的识别力,所以在低秩矩阵恢复理论的基础上将低秩正则化应用到字典学习过程中;接着,在字典学习过程中加入了结构化稀疏使其不丢失结构信息以保证对样本进行最优分类;最后再利用误差重构法对测试样本进行分类识别。结果本文算法在AR以及ORL人脸数据库上分别进行了实验仿真。在AR人脸数据库中,为了分析样本不同维数对实验结果造成的影响,选取了第一时期拍摄的每人6幅图像,包括1幅围巾遮挡,2幅墨镜遮挡以及3幅脸部表情变化以及光照变化(未被遮挡)的图像作为训练样本,同时选取相同组合的样本图像作为测试样本,无论哪种方法,图像的维度越高识别率越高。对比SRC(sparse representation based on classification)算法与DKSVD(discriminative K-means singular value decomposition)算法的识别率可知,DKSVD算法通过字典学习减缓了训练样本中的不确定因素对识别结果的影响;对比DLRD_SR(discriminative low-rank dictionary learning for sparse representation)算法与FDDL(Fisher discriminative dictionary learning)算法的识别率可知,当图像有遮挡等噪声信息存在时,字典低秩化可以提高至少5.8%的识别率;对比本文算法与DLRD_SR算法可知,在字典学习的过程中加入Fisher准则后识别率显著提高,同时理想稀疏值能保证对样本进行最优的分类。当样本图像的维度达到500维时人脸图像在有围巾、墨镜遮挡的情况下识别率可达到85.2%;其中墨镜和围巾的遮挡程度分别可以看成是人脸图像的20%和40%,为了验证本文算法在不同脸部表情变化、光照改变以及遮挡情况下的有效性,根据训练样本的具体图像组合情况进行实验。无论哪种样本图像组合,本文算法在有遮挡存在的样本识别中具有显著优势。在训练样本只包含脸部表情变化、光照变化以及墨镜遮挡图像的情况下,本文算法的识别率高于其他算法至少2.7%,在训练样本只包含脸部表情变化、光照变化以及围巾遮挡图像的情况下,本文算法的识别率高于其他算法至少3.6%,在训练样本包含脸部表情变化、光照变化、围巾遮挡以及墨镜遮挡图像的情况下,其识别率高于其他算法至少1.9%。在ORL人脸数据库中,人脸图像在无遮挡的情况下识别率达到95.2%,稍低于FDDL算法的识别率;在随机块遮挡程度达到20%时,相比较于SRC算法、DKSVD算法、FDDL算法以及DLRD_SR算法,本文算法的识别率最高;当随机块遮挡程度达到50%时,以上算法的识别率均不高,但本文算法的其识别率仍然最高。结论本文算法在人脸图像受到遮挡等因素的影响时具有一定的鲁棒性,实验结果表明该算法在人脸识别方面具有可行性。关键词:人脸识别;低秩正则化;标签信息;结构化稀疏;Fisher准则;字典学习12|4|1更新时间:2024-08-15 -
 摘要:目的3维人脸点云的局部遮挡是影响3维人脸识别精度的一个重要因素。为克服局部遮挡对3维人脸识别的影响,提出一种基于径向线和局部特征的3维人脸识别方法。方法首先为了充分利用径向线的邻域信息,提出用一组局部特征来表示径向线;其次对于点云稀疏引起的采样点不均匀,提出将部分相邻局部区域合并以减小采样不均匀的影响;然后,利用径向线的邻域信息构造代价函数,进而构造相应径向线间的相似向量。最后,利用相似向量来进行径向线匹配,从而完成3维人脸识别。结果在FRGC v2.0数据库上进行不同局部特征识别率的测试实验,选取的局部特征Rank-1识别率达到了95.2%,高于其他局部特征的识别率;在Bosphorus数据库上进行不同算法局部遮挡下的人脸识别实验,Rank-1识别率达到了最高的92.0%;进一步在Bosphorus数据库上进行不同算法的时间复杂度对比实验,耗费时间最短,为8.17 s。该算法在准确率和耗时方面均取得了最好的效果。结论基于径向线和局部特征的3维人脸方法能有效提取径向线周围的局部信息;局部特征的代价函数生成的相似向量有效减小了局部遮挡带来的影响。实验结果表明本文算法具有较高的精度和较短的耗时,同时对人脸的局部遮挡具有一定的鲁棒性。该算法适用于局部遮挡下的3维人脸识别,但是对于鼻尖部分被遮挡的人脸,无法进行识别。关键词:3维人脸识别;局部遮挡;局部特征;面部径向线;区域合并11|4|2更新时间:2024-08-15
摘要:目的3维人脸点云的局部遮挡是影响3维人脸识别精度的一个重要因素。为克服局部遮挡对3维人脸识别的影响,提出一种基于径向线和局部特征的3维人脸识别方法。方法首先为了充分利用径向线的邻域信息,提出用一组局部特征来表示径向线;其次对于点云稀疏引起的采样点不均匀,提出将部分相邻局部区域合并以减小采样不均匀的影响;然后,利用径向线的邻域信息构造代价函数,进而构造相应径向线间的相似向量。最后,利用相似向量来进行径向线匹配,从而完成3维人脸识别。结果在FRGC v2.0数据库上进行不同局部特征识别率的测试实验,选取的局部特征Rank-1识别率达到了95.2%,高于其他局部特征的识别率;在Bosphorus数据库上进行不同算法局部遮挡下的人脸识别实验,Rank-1识别率达到了最高的92.0%;进一步在Bosphorus数据库上进行不同算法的时间复杂度对比实验,耗费时间最短,为8.17 s。该算法在准确率和耗时方面均取得了最好的效果。结论基于径向线和局部特征的3维人脸方法能有效提取径向线周围的局部信息;局部特征的代价函数生成的相似向量有效减小了局部遮挡带来的影响。实验结果表明本文算法具有较高的精度和较短的耗时,同时对人脸的局部遮挡具有一定的鲁棒性。该算法适用于局部遮挡下的3维人脸识别,但是对于鼻尖部分被遮挡的人脸,无法进行识别。关键词:3维人脸识别;局部遮挡;局部特征;面部径向线;区域合并11|4|2更新时间:2024-08-15 -
 摘要:目的目前行人检测存在特征维度高、检测耗时的问题,行人图像易受到光照、背景、遮挡等影响,给实际行人检测造成了一定困难。为了提高检测准确性,减少检测耗时,针对以上问题,提出一种改进特征与GPU(graphic processing unit)加速的行人检测算法。方法首先,采用多尺度无缩放思想,通过canny算子对所有样本进行预处理,减少背景干扰与统一归格化的形变影响。然后,针对实际视频中的遮挡问题,把图像分成头部、左臂、上身、右臂、左腿、右腿6个区域。接着选取比LBP(local binary patterns)特征鲁棒性更好的SILTP(scale invariant local ternary pattern)特征作为纹理特征,在GPU空间中并行提取;同时,分别提取6个区域的HOG(histogram of oriented gradient)特征值,结合行人轮廓在6个区域上的梯度方向分布特性,对其进行加权。最后,将提取的全部特征输出到CPU(central processing unit),利用支持向量机(SVM)分类器实现行人检测。结果在INRIA、NICTA数据集上进行实验,INRIA数据集上检测率达到99.80%,NICTA数据集上检测率达到99.91%,并且INRIA数据集上检测时间加速比达到12.19,NICTA数据集上达到13.49,相对传统HOG、LBP算法,检测率、时间比实现提高。结论提出的改进HOG-SILTP特征与GPU加速的行人检测算法,能够有效表达行人信息,改善传统特征提取方式带来的耗时与形变影响,对环境变化、遮挡具有较强的鲁棒性。该算法在检测率、检测时间方面均有提高,能够实现有效、快速的行人检测,具有实际意义。关键词:行人检测;GPU加速;SILTP特征;HOG特征;支持向量机(SVM)分类器13|5|2更新时间:2024-08-15
摘要:目的目前行人检测存在特征维度高、检测耗时的问题,行人图像易受到光照、背景、遮挡等影响,给实际行人检测造成了一定困难。为了提高检测准确性,减少检测耗时,针对以上问题,提出一种改进特征与GPU(graphic processing unit)加速的行人检测算法。方法首先,采用多尺度无缩放思想,通过canny算子对所有样本进行预处理,减少背景干扰与统一归格化的形变影响。然后,针对实际视频中的遮挡问题,把图像分成头部、左臂、上身、右臂、左腿、右腿6个区域。接着选取比LBP(local binary patterns)特征鲁棒性更好的SILTP(scale invariant local ternary pattern)特征作为纹理特征,在GPU空间中并行提取;同时,分别提取6个区域的HOG(histogram of oriented gradient)特征值,结合行人轮廓在6个区域上的梯度方向分布特性,对其进行加权。最后,将提取的全部特征输出到CPU(central processing unit),利用支持向量机(SVM)分类器实现行人检测。结果在INRIA、NICTA数据集上进行实验,INRIA数据集上检测率达到99.80%,NICTA数据集上检测率达到99.91%,并且INRIA数据集上检测时间加速比达到12.19,NICTA数据集上达到13.49,相对传统HOG、LBP算法,检测率、时间比实现提高。结论提出的改进HOG-SILTP特征与GPU加速的行人检测算法,能够有效表达行人信息,改善传统特征提取方式带来的耗时与形变影响,对环境变化、遮挡具有较强的鲁棒性。该算法在检测率、检测时间方面均有提高,能够实现有效、快速的行人检测,具有实际意义。关键词:行人检测;GPU加速;SILTP特征;HOG特征;支持向量机(SVM)分类器13|5|2更新时间:2024-08-15 -
 摘要:目的人群数量和密度估计在视频监控、智能交通和公共安全等领域有着极其重要的应用价值。现有技术对人群数量大,复杂环境下人群密度的估计仍存在较大的改进空间。因此,针对密度大、分布不均匀、遮挡严重的人群密度视觉检测,提出一种基于多层次特征融合网络的人群密度估计方法,用来解决人群密度估计难的问题。方法首先,利用多层次特征融合网络进行人群特征的提取、融合、生成人群密度图;然后,对人群密度图进行积分计算求出对应人群的数量;最后,通过还原密度图上人群空间位置信息并结合估算出的人群数量,对人群拥挤程度做出量化判断。结果在Mall数据集上本文方法平均绝对误差(MAE)降至2.35,在ShanghaiTech数据集上MAE分别降至20.73和104.86,与现有的方法进行对比估计精度得到较大提升,尤其是在环境复杂、人数较多的场景下提升效果明显。结论本文提出的多层次特征融合的人群密度估计方法能有效地对不同尺度的特征进行提取,具有受场景约束小,人群数量估计精度高,人群拥挤程度评估简单可靠等优点,实验的对比结果验证了本文方法的有效性。关键词:人群密度估计;拥挤程度评估;层次特征融合;卷积神经网络;深度学习;智能视频分析12|5|1更新时间:2024-08-15
摘要:目的人群数量和密度估计在视频监控、智能交通和公共安全等领域有着极其重要的应用价值。现有技术对人群数量大,复杂环境下人群密度的估计仍存在较大的改进空间。因此,针对密度大、分布不均匀、遮挡严重的人群密度视觉检测,提出一种基于多层次特征融合网络的人群密度估计方法,用来解决人群密度估计难的问题。方法首先,利用多层次特征融合网络进行人群特征的提取、融合、生成人群密度图;然后,对人群密度图进行积分计算求出对应人群的数量;最后,通过还原密度图上人群空间位置信息并结合估算出的人群数量,对人群拥挤程度做出量化判断。结果在Mall数据集上本文方法平均绝对误差(MAE)降至2.35,在ShanghaiTech数据集上MAE分别降至20.73和104.86,与现有的方法进行对比估计精度得到较大提升,尤其是在环境复杂、人数较多的场景下提升效果明显。结论本文提出的多层次特征融合的人群密度估计方法能有效地对不同尺度的特征进行提取,具有受场景约束小,人群数量估计精度高,人群拥挤程度评估简单可靠等优点,实验的对比结果验证了本文方法的有效性。关键词:人群密度估计;拥挤程度评估;层次特征融合;卷积神经网络;深度学习;智能视频分析12|5|1更新时间:2024-08-15 -
 摘要:目的现有对艺术画进行分类的文献大多对整幅画作直接进行特征提取,但任何图像内容特征的可适应性都存在一定的局限性。画家画不同艺术目标的笔锋和艺术处理往往是不同的,如果不考虑每个笔锋所产生的条件而一味地分析笔锋的走向和力度分布等将会是很盲目的。为此提出一种基于艺术目标的中国画分类算法。方法首先,基于简单线性迭代聚类算法根据像素间颜色和位置的相差程度来生成超像素;其次,提出针对艺术目标的最大相似度区域合并算法交互式地进行艺术目标分割,将国画分割成一系列的艺术目标,如马、人物等,以提取画家用来表现艺术形式和抒发情感的相对稳定单元;然后利用深度卷积神经网络(O-CNN)来描述这些艺术目标的高级语义特征;最后,引入支持向量机对每幅中国画内的各种艺术目标的分类结果进行最后的融合与分类。结果本文针对艺术目标进行国画的学习和分类,实现了对样本库中10位画家中国画的识别,平均准确率为89%。实验结果表明,本文算法在平均查全率和查准率上优于现有的MHMM(The 2D multi-resolution hidden Markov model)和Fusion等方法。结论本文的成果可用于中国画的数字化分析、管理、理解和识别,为中国画传承和鉴赏提供有效的数字工具。关键词:艺术目标分割;中国画分类;卷积神经网络;融合算法;深度学习;超像素分割28|11|10更新时间:2024-08-15
摘要:目的现有对艺术画进行分类的文献大多对整幅画作直接进行特征提取,但任何图像内容特征的可适应性都存在一定的局限性。画家画不同艺术目标的笔锋和艺术处理往往是不同的,如果不考虑每个笔锋所产生的条件而一味地分析笔锋的走向和力度分布等将会是很盲目的。为此提出一种基于艺术目标的中国画分类算法。方法首先,基于简单线性迭代聚类算法根据像素间颜色和位置的相差程度来生成超像素;其次,提出针对艺术目标的最大相似度区域合并算法交互式地进行艺术目标分割,将国画分割成一系列的艺术目标,如马、人物等,以提取画家用来表现艺术形式和抒发情感的相对稳定单元;然后利用深度卷积神经网络(O-CNN)来描述这些艺术目标的高级语义特征;最后,引入支持向量机对每幅中国画内的各种艺术目标的分类结果进行最后的融合与分类。结果本文针对艺术目标进行国画的学习和分类,实现了对样本库中10位画家中国画的识别,平均准确率为89%。实验结果表明,本文算法在平均查全率和查准率上优于现有的MHMM(The 2D multi-resolution hidden Markov model)和Fusion等方法。结论本文的成果可用于中国画的数字化分析、管理、理解和识别,为中国画传承和鉴赏提供有效的数字工具。关键词:艺术目标分割;中国画分类;卷积神经网络;融合算法;深度学习;超像素分割28|11|10更新时间:2024-08-15 -
 摘要:目的手写文本行提取是文档图像处理中的重要基础步骤,对于无约束手写文本图像,文本行都会有不同程度的倾斜、弯曲、交叉、粘连等问题。利用传统的几何分割或聚类的方法往往无法保证文本行边缘的精确分割。针对这些问题提出一种基于文本行回归-聚类联合框架的手写文本行提取方法。方法首先,采用各向异性高斯滤波器组对图像进行多尺度、多方向分析,利用拖尾效应检测脊形结构提取文本行主体区域,并对其骨架化得到文本行回归模型。然后,以连通域为基本图像单元建立超像素表示,为实现超像素的聚类,建立了像素-超像素-文本行关联层级随机场模型,利用能量函数优化的方法实现超像素的聚类与所属文本行标注。在此基础上,检测出所有的行间粘连字符块,采用基于回归线的k-means聚类算法由回归模型引导粘连字符像素聚类,实现粘连字符分割与所属文本行标注。最后,利用文本行标签开关实现了文本行像素的操控显示与定向提取,而不再需要几何分割。结果在HIT-MW脱机手写中文文档数据集上进行文本行提取测试,检测率DR为99.83%,识别准确率RA为99.92%。结论实验表明,提出的文本行回归-聚类联合分析框架相比于传统的分段投影分析、最小生成树聚类、Seam Carving等方法提高了文本行边缘的可控性与分割精度。在高效手写文本行提取的同时,最大程度地避免了相邻文本行的干扰,具有较高的准确率和鲁棒性。关键词:手写文本行提取;超像素;图像分割;回归;聚类15|10|0更新时间:2024-08-15
摘要:目的手写文本行提取是文档图像处理中的重要基础步骤,对于无约束手写文本图像,文本行都会有不同程度的倾斜、弯曲、交叉、粘连等问题。利用传统的几何分割或聚类的方法往往无法保证文本行边缘的精确分割。针对这些问题提出一种基于文本行回归-聚类联合框架的手写文本行提取方法。方法首先,采用各向异性高斯滤波器组对图像进行多尺度、多方向分析,利用拖尾效应检测脊形结构提取文本行主体区域,并对其骨架化得到文本行回归模型。然后,以连通域为基本图像单元建立超像素表示,为实现超像素的聚类,建立了像素-超像素-文本行关联层级随机场模型,利用能量函数优化的方法实现超像素的聚类与所属文本行标注。在此基础上,检测出所有的行间粘连字符块,采用基于回归线的k-means聚类算法由回归模型引导粘连字符像素聚类,实现粘连字符分割与所属文本行标注。最后,利用文本行标签开关实现了文本行像素的操控显示与定向提取,而不再需要几何分割。结果在HIT-MW脱机手写中文文档数据集上进行文本行提取测试,检测率DR为99.83%,识别准确率RA为99.92%。结论实验表明,提出的文本行回归-聚类联合分析框架相比于传统的分段投影分析、最小生成树聚类、Seam Carving等方法提高了文本行边缘的可控性与分割精度。在高效手写文本行提取的同时,最大程度地避免了相邻文本行的干扰,具有较高的准确率和鲁棒性。关键词:手写文本行提取;超像素;图像分割;回归;聚类15|10|0更新时间:2024-08-15 -
 摘要:目的针对当前文物资源由传统的实体文物向虚拟展示和数字文物进行扩展的趋势,如何提供一种多模态的信息呈现方式就显得尤为重要。通过将力触觉技术引入3维文物展示领域,提出一种基于多模感知的3维文物交互式呈现的算法框架。在对文物的基本特征进行视、听、触觉多通道分析的基础上,依据用户与文物模型的接触状态对多通道信息进行计算和整合。方法在力触觉计算渲染方面,基于嵌入深度构建弹簧系统模拟轮廓形状的接触过程,引入动摩擦和静摩擦因数来反映表面摩擦力这一材质特征,通过法线贴图来实现文物表面纹理的触觉处理;针对交互的环境由2维平面拓展至立体空间,结合力触觉设备将操作时的行为和状态映射为虚拟环境中的操作代理,借助操作代理构建"旋转"和"选择-移动-释放"两种基本的操作范式来实现用户意图;最后,物理引擎的引入将物体的基本运动规律集成至虚拟场景,提升场景交互的真实感.结果使用Phantom Omni手控器搭建面向馆藏文物的多模感知实验系统,抽取志愿者对实验系统进行测评。实验结果表明:运用本文方法,用户可从视觉、听觉、触觉多个通道对数字文物的整体和细节信息进行感知,且交互的整体过程简单、自然、有效。结论本文提出的基于多模感知的数字文物交互式呈现方法,可有效实现对各类数字遗产特别是3维文物的多模重现,在保证较高实时性的同时拥有良好的可用性和情感体验效果。关键词:虚拟现实;触/力觉感知;数字文物;多模态;人机交互38|122|1更新时间:2024-08-15
摘要:目的针对当前文物资源由传统的实体文物向虚拟展示和数字文物进行扩展的趋势,如何提供一种多模态的信息呈现方式就显得尤为重要。通过将力触觉技术引入3维文物展示领域,提出一种基于多模感知的3维文物交互式呈现的算法框架。在对文物的基本特征进行视、听、触觉多通道分析的基础上,依据用户与文物模型的接触状态对多通道信息进行计算和整合。方法在力触觉计算渲染方面,基于嵌入深度构建弹簧系统模拟轮廓形状的接触过程,引入动摩擦和静摩擦因数来反映表面摩擦力这一材质特征,通过法线贴图来实现文物表面纹理的触觉处理;针对交互的环境由2维平面拓展至立体空间,结合力触觉设备将操作时的行为和状态映射为虚拟环境中的操作代理,借助操作代理构建"旋转"和"选择-移动-释放"两种基本的操作范式来实现用户意图;最后,物理引擎的引入将物体的基本运动规律集成至虚拟场景,提升场景交互的真实感.结果使用Phantom Omni手控器搭建面向馆藏文物的多模感知实验系统,抽取志愿者对实验系统进行测评。实验结果表明:运用本文方法,用户可从视觉、听觉、触觉多个通道对数字文物的整体和细节信息进行感知,且交互的整体过程简单、自然、有效。结论本文提出的基于多模感知的数字文物交互式呈现方法,可有效实现对各类数字遗产特别是3维文物的多模重现,在保证较高实时性的同时拥有良好的可用性和情感体验效果。关键词:虚拟现实;触/力觉感知;数字文物;多模态;人机交互38|122|1更新时间:2024-08-15 -
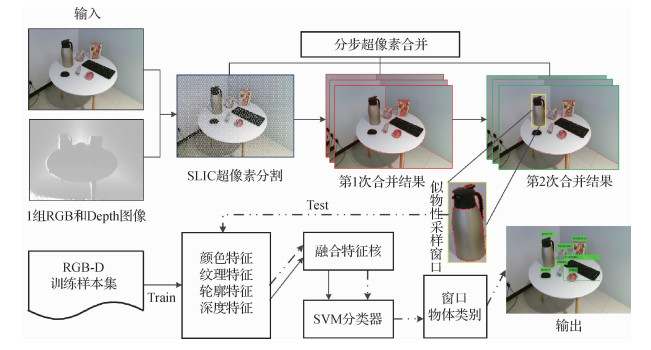 摘要:目的受光照变化、拍摄角度、物体数量和物体尺寸等因素的影响,室内场景下多目标检测容易出现准确性和实时性较低的问题。为解决此类问题,本文基于物体的彩色和深度图像组,提出了分步超像素聚合和多模态信息融合的目标识别检测方法。方法在似物性采样(object proposal)阶段,依据人眼对显著性物体观察时先注意其色彩后判断其空间深度信息的理论,首先对图像进行超像素分割,然后结合颜色信息和深度信息对分割后的像素块分步进行多阈值尺度自适应超像素聚合,得到具有颜色和空间一致性的似物性区域;在物体识别阶段,为实现物体不同信息的充分表达,利用多核学习方法融合所提取的物体颜色、纹理、轮廓、深度多模态特征,将特征融合核输入支持向量机多分类机制中进行学习和分类检测。结果实验在基于华盛顿大学标准RGB-D数据集和真实场景集上将本文方法与当前主流算法进行对比,得出本文方法整体的检测精度较当前主流算法提升4.7%,运行时间有了大幅度提升。其中分步超像素聚合方法在物体定位性能上优于当前主流似物性采样方法,并且在相同召回率下采样窗口数量约为其他算法的1/4;多信息融合在目标识别阶段优于单个特征和简单的颜色、深度特征融合方法。结论结果表明在基于多特征的目标检测过程中本文方法能够有效利用物体彩色和深度信息进行目标定位和识别,对提高物体检测精度和检测效率具有重要作用。关键词:3维目标检测;分步超像素聚合;多模态信息融合;深度图像;似物性采样;机器学习15|6|4更新时间:2024-08-15
摘要:目的受光照变化、拍摄角度、物体数量和物体尺寸等因素的影响,室内场景下多目标检测容易出现准确性和实时性较低的问题。为解决此类问题,本文基于物体的彩色和深度图像组,提出了分步超像素聚合和多模态信息融合的目标识别检测方法。方法在似物性采样(object proposal)阶段,依据人眼对显著性物体观察时先注意其色彩后判断其空间深度信息的理论,首先对图像进行超像素分割,然后结合颜色信息和深度信息对分割后的像素块分步进行多阈值尺度自适应超像素聚合,得到具有颜色和空间一致性的似物性区域;在物体识别阶段,为实现物体不同信息的充分表达,利用多核学习方法融合所提取的物体颜色、纹理、轮廓、深度多模态特征,将特征融合核输入支持向量机多分类机制中进行学习和分类检测。结果实验在基于华盛顿大学标准RGB-D数据集和真实场景集上将本文方法与当前主流算法进行对比,得出本文方法整体的检测精度较当前主流算法提升4.7%,运行时间有了大幅度提升。其中分步超像素聚合方法在物体定位性能上优于当前主流似物性采样方法,并且在相同召回率下采样窗口数量约为其他算法的1/4;多信息融合在目标识别阶段优于单个特征和简单的颜色、深度特征融合方法。结论结果表明在基于多特征的目标检测过程中本文方法能够有效利用物体彩色和深度信息进行目标定位和识别,对提高物体检测精度和检测效率具有重要作用。关键词:3维目标检测;分步超像素聚合;多模态信息融合;深度图像;似物性采样;机器学习15|6|4更新时间:2024-08-15
图像分析和识别
-
 摘要:目的形状的表示和匹配是计算机视觉和模式识别领域的重要问题。在基于区域的形状表示方法中出现了一批典型的方法,包括Hu不变矩方法(Hu不变矩)、角径向变换方法(ART方法)、通用傅里叶描述子方法(GFD方法)、拉东柱状图方法(HRT方法)和多尺度积分不变量方法(MSⅡ方法)等。由于这些方法出现的时间跨度长且在以往的对比研究中研究维度单一,因此需要对这些方法的综合性能做一个全面的比较分析和研究,为下一步的理论研究和实际应用提供方向和指导。方法采用3个基准形状库,包括简单几何图形形状库、MPEG-7形状库和汽车商标形状库,从3个维度,包括检索得分、检索稳定性和方法的计算复杂度,使用加权综合评估模型对典型的基于区域的形状表示方法进行比较分析,综合评估各种方法的综合性能指标。结果在综合性能上GFD方法具有最优的效果,其次是ART方法;由于HRT方法在匹配计算阶段具有较高的时间复杂度,在大规模形状库匹配的场景下性能会下降;Hu不变矩和MSⅡ方法的实验效果均不理想。通过比较研究还发现,将形状正交投影到正交基函数是提取形状视觉特征的有效方式。进一步猜想,将图像正交投影到正交基函数也是提取图像视觉特征的有效方式。因此,未来的研究中,寻找理想的正交基函数是提取形状乃至图像视觉特征的重要研究方向。结论在5种比较研究的方法中,GFD方法和ART方法在综合效果要好于HRT方法、Hu不变矩方法和MSⅡ方法,并且寻找理想的正交基函数是未来形状表示的重要研究方向。关键词:计算机视觉;模式识别;形状投影;形状描述符;形状匹配11|4|2更新时间:2024-08-15
摘要:目的形状的表示和匹配是计算机视觉和模式识别领域的重要问题。在基于区域的形状表示方法中出现了一批典型的方法,包括Hu不变矩方法(Hu不变矩)、角径向变换方法(ART方法)、通用傅里叶描述子方法(GFD方法)、拉东柱状图方法(HRT方法)和多尺度积分不变量方法(MSⅡ方法)等。由于这些方法出现的时间跨度长且在以往的对比研究中研究维度单一,因此需要对这些方法的综合性能做一个全面的比较分析和研究,为下一步的理论研究和实际应用提供方向和指导。方法采用3个基准形状库,包括简单几何图形形状库、MPEG-7形状库和汽车商标形状库,从3个维度,包括检索得分、检索稳定性和方法的计算复杂度,使用加权综合评估模型对典型的基于区域的形状表示方法进行比较分析,综合评估各种方法的综合性能指标。结果在综合性能上GFD方法具有最优的效果,其次是ART方法;由于HRT方法在匹配计算阶段具有较高的时间复杂度,在大规模形状库匹配的场景下性能会下降;Hu不变矩和MSⅡ方法的实验效果均不理想。通过比较研究还发现,将形状正交投影到正交基函数是提取形状视觉特征的有效方式。进一步猜想,将图像正交投影到正交基函数也是提取图像视觉特征的有效方式。因此,未来的研究中,寻找理想的正交基函数是提取形状乃至图像视觉特征的重要研究方向。结论在5种比较研究的方法中,GFD方法和ART方法在综合效果要好于HRT方法、Hu不变矩方法和MSⅡ方法,并且寻找理想的正交基函数是未来形状表示的重要研究方向。关键词:计算机视觉;模式识别;形状投影;形状描述符;形状匹配11|4|2更新时间:2024-08-15
图像理解和计算机视觉
-
 摘要:目的精确的肝脏分割是计算机辅助肝脏疾病诊断和手术规划的必要步骤,但由于肝脏解剖学的复杂性、邻近器官的低对比度和病态等原因,使得肝脏分割在医学图像处理领域仍然是具有挑战性的任务。针对腹部图像器官边界模糊及传统U-Net模型实现端到端的分割时精确度不高等问题,设计了一种基于改进的U-Net(IU-Net)和Morphsnakes算法的增强CT图像肝脏分割方法。方法首先根据CT图像头文件信息对原始数据进行预处理并构建数据集,然后使用构建好的数据集训练IU-Net,训练过程中使用自定义的Dice层评测图像分割结果的准确率,最后通过OpenCV和Morphsnakes对初始分割结果进行精细分割,最终实现增强CT图像中肝脏的精确分割。结果实验数据包括200组增强CT,160组用于训练,40组用于测试。本文算法分割准确率达到了94.8%,与U-Net、FCN-8s模型相比,具有更好的分割效果。结论本文算法可以准确分割增强CT图像中各种形状的肝脏,能够为临床诊断提供可靠依据。关键词:全卷积神经网络;肝脏分割;深度学习;主动轮廓;Morphsnakes14|4|10更新时间:2024-08-15
摘要:目的精确的肝脏分割是计算机辅助肝脏疾病诊断和手术规划的必要步骤,但由于肝脏解剖学的复杂性、邻近器官的低对比度和病态等原因,使得肝脏分割在医学图像处理领域仍然是具有挑战性的任务。针对腹部图像器官边界模糊及传统U-Net模型实现端到端的分割时精确度不高等问题,设计了一种基于改进的U-Net(IU-Net)和Morphsnakes算法的增强CT图像肝脏分割方法。方法首先根据CT图像头文件信息对原始数据进行预处理并构建数据集,然后使用构建好的数据集训练IU-Net,训练过程中使用自定义的Dice层评测图像分割结果的准确率,最后通过OpenCV和Morphsnakes对初始分割结果进行精细分割,最终实现增强CT图像中肝脏的精确分割。结果实验数据包括200组增强CT,160组用于训练,40组用于测试。本文算法分割准确率达到了94.8%,与U-Net、FCN-8s模型相比,具有更好的分割效果。结论本文算法可以准确分割增强CT图像中各种形状的肝脏,能够为临床诊断提供可靠依据。关键词:全卷积神经网络;肝脏分割;深度学习;主动轮廓;Morphsnakes14|4|10更新时间:2024-08-15
医学图像处理
-
 摘要:目的针对阴影在高分辨率遥感影像的特性,提出了一种多尺度分割和形态学运算相结合的阴影检测方法。方法基于面向对象思想,首先利用均值漂移法实现影像分割生成对象,并以对象为基本单元分别进行形态学膨胀和腐蚀运算,从而获得面向对象的阴影指数;然后对影像进行多尺度分割,生成阴影指数矢量;最后对阴影指数矢量和亮度均值分别指定高低阈值,进而获得阴影检测结果。结果选取高分二号和Google earth影像进行实验,采用误检率、漏检率和总错误率3个指标进行定量分析,并将实验结果与结合多特征法和形态学阴影指数法进行比较。在阴影检测定量精度分析中,相比于对比方法,本文方法的误检率偏高,但漏检率平均降低了7.31%;在建筑物阴影检测实验中,本文方法的漏检率同样下降了4.5个百分点;在多尺度效果融合分析中,本文方法在多组尺度组合下,各项精度指标均较理想;在阴影压盖地物实验中,3种方法的误检情况差异不大,但本文方法的漏检率得到较大改善,其下降程度平均达到了19.29%。结论本文提出的阴影检测方法具备一定的抗干扰能力,适用性强,可靠性高。关键词:高分辨率遥感影像;阴影检测;形态学运算;多尺度分割;阴影指数15|5|4更新时间:2024-08-15
摘要:目的针对阴影在高分辨率遥感影像的特性,提出了一种多尺度分割和形态学运算相结合的阴影检测方法。方法基于面向对象思想,首先利用均值漂移法实现影像分割生成对象,并以对象为基本单元分别进行形态学膨胀和腐蚀运算,从而获得面向对象的阴影指数;然后对影像进行多尺度分割,生成阴影指数矢量;最后对阴影指数矢量和亮度均值分别指定高低阈值,进而获得阴影检测结果。结果选取高分二号和Google earth影像进行实验,采用误检率、漏检率和总错误率3个指标进行定量分析,并将实验结果与结合多特征法和形态学阴影指数法进行比较。在阴影检测定量精度分析中,相比于对比方法,本文方法的误检率偏高,但漏检率平均降低了7.31%;在建筑物阴影检测实验中,本文方法的漏检率同样下降了4.5个百分点;在多尺度效果融合分析中,本文方法在多组尺度组合下,各项精度指标均较理想;在阴影压盖地物实验中,3种方法的误检情况差异不大,但本文方法的漏检率得到较大改善,其下降程度平均达到了19.29%。结论本文提出的阴影检测方法具备一定的抗干扰能力,适用性强,可靠性高。关键词:高分辨率遥感影像;阴影检测;形态学运算;多尺度分割;阴影指数15|5|4更新时间:2024-08-15
遥感图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0