
最新刊期
2018 年 第 23 卷 第 6 期
-
 摘要:目的数字视频区域篡改是指视频帧图像的某个关键区域被覆盖或被替换,经过图像编辑和修补之后,该关键区域的修改痕迹很难通过肉眼来分辨。视频图像的关键区域承载了视频序列的关键语义信息。如果该篡改操作属于恶意的伪造行为,将产生非常严重的影响和后果。因此,视频区域篡改的检测与定位研究具有重要的研究价值和应用前景。方法数字图像的复制粘贴篡改检测已经取得较大的研究进展,相关研究成果也很多。但是,数字视频区域篡改的检测与定位不能直接采用数字图像的复制—粘贴篡改取证算法。数字视频区域篡改检测与定位是数字视频被动取证研究领域中的一个新兴的研究方向,近年来越来越多的学者在该领域开展研究工作。目前,数字视频的区域篡改检测与定位研究还缺少完善的理论支撑和通用的检测与定位算法。在广泛调研最近几年的最新研究成果的基础上,对数字视频区域篡改的被动取证概念及重要性进行了介绍,将现有的数字视频区域篡改被动取证算法分为4类:基于噪声模式的算法、基于像素相关性的算法、基于视频内容特征的算法和基于抽象统计特征的算法。然后,对这些区域篡改检测与定位的算法进行对比分析,并介绍现有的视频区域篡改软件和算法,以及篡改检测算法的测试数据库。最后,对本研究领域存在的问题和挑战进行总结,并对未来的研究趋势进行展望。结果选取了20篇文献中的18种算法,分别介绍每种算法的算法原理,并对这些算法进行对比分析。大部分的算法都宣称可以检测并定位出篡改可疑区域,但是检测和定位的精度、计算复杂度都各有差异。其中,基于时空域的像素相关性分析的算法具有较好的检测和定位效果,并且支持运动背景视频中的运动目标删除篡改检测和定位。基于光流平滑性异常的算法和基于运动目标检测的算法都是基于公开的视频篡改测试库进行比较测试的,两种算法都具有较好的检测和定位效果。基于隐写分析特征提取的集成分类算法虽然只能实现时域上的篡改定位,不能实现更精细的空域篡改定位,但是该算法为基于机器学习的大规模视频篡改取证研究提供了新思路和可能的发展方向,具有较大的指导意义。结论由于视频编码压缩引入噪声,以及视频区域篡改软件工具和技术的改进,视频区域篡改检测和定位仍是一个极具挑战的课题。未来几年,基于视频内容特征和抽象统计特征的视频区域篡改检测和定位算法,有可能结合深度学习算法,得到进一步的研究和发展;相关的理论算法、系统模型和评价标准等研究成果将逐步完善。关键词:视频被动取证;篡改的检测与定位;像素相关性;视频内容特征;抽象统计特征29|114|3更新时间:2024-05-07
摘要:目的数字视频区域篡改是指视频帧图像的某个关键区域被覆盖或被替换,经过图像编辑和修补之后,该关键区域的修改痕迹很难通过肉眼来分辨。视频图像的关键区域承载了视频序列的关键语义信息。如果该篡改操作属于恶意的伪造行为,将产生非常严重的影响和后果。因此,视频区域篡改的检测与定位研究具有重要的研究价值和应用前景。方法数字图像的复制粘贴篡改检测已经取得较大的研究进展,相关研究成果也很多。但是,数字视频区域篡改的检测与定位不能直接采用数字图像的复制—粘贴篡改取证算法。数字视频区域篡改检测与定位是数字视频被动取证研究领域中的一个新兴的研究方向,近年来越来越多的学者在该领域开展研究工作。目前,数字视频的区域篡改检测与定位研究还缺少完善的理论支撑和通用的检测与定位算法。在广泛调研最近几年的最新研究成果的基础上,对数字视频区域篡改的被动取证概念及重要性进行了介绍,将现有的数字视频区域篡改被动取证算法分为4类:基于噪声模式的算法、基于像素相关性的算法、基于视频内容特征的算法和基于抽象统计特征的算法。然后,对这些区域篡改检测与定位的算法进行对比分析,并介绍现有的视频区域篡改软件和算法,以及篡改检测算法的测试数据库。最后,对本研究领域存在的问题和挑战进行总结,并对未来的研究趋势进行展望。结果选取了20篇文献中的18种算法,分别介绍每种算法的算法原理,并对这些算法进行对比分析。大部分的算法都宣称可以检测并定位出篡改可疑区域,但是检测和定位的精度、计算复杂度都各有差异。其中,基于时空域的像素相关性分析的算法具有较好的检测和定位效果,并且支持运动背景视频中的运动目标删除篡改检测和定位。基于光流平滑性异常的算法和基于运动目标检测的算法都是基于公开的视频篡改测试库进行比较测试的,两种算法都具有较好的检测和定位效果。基于隐写分析特征提取的集成分类算法虽然只能实现时域上的篡改定位,不能实现更精细的空域篡改定位,但是该算法为基于机器学习的大规模视频篡改取证研究提供了新思路和可能的发展方向,具有较大的指导意义。结论由于视频编码压缩引入噪声,以及视频区域篡改软件工具和技术的改进,视频区域篡改检测和定位仍是一个极具挑战的课题。未来几年,基于视频内容特征和抽象统计特征的视频区域篡改检测和定位算法,有可能结合深度学习算法,得到进一步的研究和发展;相关的理论算法、系统模型和评价标准等研究成果将逐步完善。关键词:视频被动取证;篡改的检测与定位;像素相关性;视频内容特征;抽象统计特征29|114|3更新时间:2024-05-07
综述

-
 摘要:目的现有的基于邻域嵌入的人脸超分辨率重建算法只利用了低分辨率图像流形空间的几何结构,而忽略了原始高分辨率图像的流形几何结构,不能很好的反映高低分辨率图像流形几何结构的关系。此外,其对同一幅图像中的不同图像块选取固定数目的最近邻域图像块,从而导致重建质量的下降。为了充分利用原始高分辨率图像空间的几何结构信息,提出基于联合局部约束和自适应邻域选择的邻域嵌入人脸超分辨率重建算法。方法该方法结合待重构图像与低分辨率图像样本库的相似性约束与初始高分辨图像与高分辨率图像样本库的相似性约束,形成约束低分辨率图像块的重构权重,并利用该重构权重估计出高分辨率的人脸图像,同时引入自适应邻域选择的方法。结果在CAS-PEAL-R1人脸库上的实验结果表明,相较于传统的基于邻域嵌入的人脸超分辨率重建方法,本文算法在PSNR和SSIM上分别提升了0.39 dB和0.02。相较于LSR重建方法,在PSNR和SSIM上分别提升了0.63 dB和0.01;相较于LcR重建方法,在PSNR和SSIM上分别提升了0.36 dB和0.003 2;相较于TRNR重建方法,在PSNR和SSIM上分别提升了0.33 dB和0.001 1。结论本文所提的重建方法在现有人脸数据库上进行实验,在主观视觉和客观评价指标上均取得了较好的结果,可进一步适用于现实监控视频中人脸图像的高分辨率重建。关键词:流形空间;联合局部约束;自适应邻域选择;邻域嵌入;人脸超分辨率重建11|4|2更新时间:2024-05-07
摘要:目的现有的基于邻域嵌入的人脸超分辨率重建算法只利用了低分辨率图像流形空间的几何结构,而忽略了原始高分辨率图像的流形几何结构,不能很好的反映高低分辨率图像流形几何结构的关系。此外,其对同一幅图像中的不同图像块选取固定数目的最近邻域图像块,从而导致重建质量的下降。为了充分利用原始高分辨率图像空间的几何结构信息,提出基于联合局部约束和自适应邻域选择的邻域嵌入人脸超分辨率重建算法。方法该方法结合待重构图像与低分辨率图像样本库的相似性约束与初始高分辨图像与高分辨率图像样本库的相似性约束,形成约束低分辨率图像块的重构权重,并利用该重构权重估计出高分辨率的人脸图像,同时引入自适应邻域选择的方法。结果在CAS-PEAL-R1人脸库上的实验结果表明,相较于传统的基于邻域嵌入的人脸超分辨率重建方法,本文算法在PSNR和SSIM上分别提升了0.39 dB和0.02。相较于LSR重建方法,在PSNR和SSIM上分别提升了0.63 dB和0.01;相较于LcR重建方法,在PSNR和SSIM上分别提升了0.36 dB和0.003 2;相较于TRNR重建方法,在PSNR和SSIM上分别提升了0.33 dB和0.001 1。结论本文所提的重建方法在现有人脸数据库上进行实验,在主观视觉和客观评价指标上均取得了较好的结果,可进一步适用于现实监控视频中人脸图像的高分辨率重建。关键词:流形空间;联合局部约束;自适应邻域选择;邻域嵌入;人脸超分辨率重建11|4|2更新时间:2024-05-07 -
 摘要:目的受成像距离、光照条件、动态模糊等因素影响,监控系统拍摄的车牌图像往往并不具备较高的可辨识度。为改善成像质量,提升对车牌的识别能力,提出一种基于亮度与梯度联合约束的车牌图像超分辨率重建方法。方法首先充分结合亮度约束和梯度约束的优势,实现对运动位移和模糊函数的精确估计;为抑制重建图像中的噪声与伪影,基于车牌图像的文字化特征,进一步确定了亮度与梯度联合约束的图像先验模型。结果为验证该方法的有效性,利用监控系统获得4组车牌图像,分别进行模拟和真实的超分辨率重建实验。在模拟实验中将联合约束图像先验重建结果与拉普拉斯、Huber-Markov(HMRF)以及总变分(TV)先验的处理结果进行对比,联合约束先验对车牌纹理信息的恢复效果优于其他3种常见图像先验;同时,在模拟和真实实验中,将本文算法与双三次插值、传统最大后验概率、非线性扩散正则化和自适应范数正则化方法的超分辨率重建结果进行比较,模拟实验的结果表明,在不添加噪声情况下,该算法峰值信噪比(PSNR)和结构相似性(SSIM)指标分别为35.326 dB和0.958,优于其他4种算法;该算法在真实实验中,能够有效增强车牌图像纹理信息,获得较优的视觉效果,通过对重建车牌图像的字符识别精度比较,本文算法重建结果的识别精度远高于其他3种算法,平均字符差距为1.3。结论模拟和真实图像序列的实验结果证明,基于亮度—梯度联合约束的超分辨率重建方法,能够降低运动和模糊等参数的估计误差,有效减少图像中存在的模糊和噪声,提高车牌的识别精度。该算法广泛适用于因光照变化、相对运动等因素影响下的低质量车牌图像超分辨率重建。关键词:超分辨率重建;联合约束;最大后验概率;光流估计;模糊估计;图像先验16|4|6更新时间:2024-05-07
摘要:目的受成像距离、光照条件、动态模糊等因素影响,监控系统拍摄的车牌图像往往并不具备较高的可辨识度。为改善成像质量,提升对车牌的识别能力,提出一种基于亮度与梯度联合约束的车牌图像超分辨率重建方法。方法首先充分结合亮度约束和梯度约束的优势,实现对运动位移和模糊函数的精确估计;为抑制重建图像中的噪声与伪影,基于车牌图像的文字化特征,进一步确定了亮度与梯度联合约束的图像先验模型。结果为验证该方法的有效性,利用监控系统获得4组车牌图像,分别进行模拟和真实的超分辨率重建实验。在模拟实验中将联合约束图像先验重建结果与拉普拉斯、Huber-Markov(HMRF)以及总变分(TV)先验的处理结果进行对比,联合约束先验对车牌纹理信息的恢复效果优于其他3种常见图像先验;同时,在模拟和真实实验中,将本文算法与双三次插值、传统最大后验概率、非线性扩散正则化和自适应范数正则化方法的超分辨率重建结果进行比较,模拟实验的结果表明,在不添加噪声情况下,该算法峰值信噪比(PSNR)和结构相似性(SSIM)指标分别为35.326 dB和0.958,优于其他4种算法;该算法在真实实验中,能够有效增强车牌图像纹理信息,获得较优的视觉效果,通过对重建车牌图像的字符识别精度比较,本文算法重建结果的识别精度远高于其他3种算法,平均字符差距为1.3。结论模拟和真实图像序列的实验结果证明,基于亮度—梯度联合约束的超分辨率重建方法,能够降低运动和模糊等参数的估计误差,有效减少图像中存在的模糊和噪声,提高车牌的识别精度。该算法广泛适用于因光照变化、相对运动等因素影响下的低质量车牌图像超分辨率重建。关键词:超分辨率重建;联合约束;最大后验概率;光流估计;模糊估计;图像先验16|4|6更新时间:2024-05-07 -
 摘要:目的针对基于位平面信息量分布的选择性加密算法安全性不高、像素置换加密算法不能很好抵抗统计攻击问题,提出一种基于位级同步置乱扩散和像素级环形扩散的图像加密算法(BSPDPAD算法),提高图像加密效率和安全性。方法BSPDPAD算法首先通过分段线性混沌映射产生两组混沌序列,其中一组混沌序列对图像进行随机分块,另一组混沌序列分解到位平面构成位级密钥流;然后,将各像素块分解到位平面,利用位级密钥流同步置乱扩散高位平面、置乱低位平面,实现位平面上块内置乱扩散及块间扩散;最后,再次迭代分段线性混沌映射产生新的密钥流,利用该密钥流对经过位级加密的中间密文图像进行横向顺序扩散和纵向逆序扩散,完成图像加密。结果灰度图像及彩色图像上的计算机仿真实验与性能分析表明:BSPDPAD算法密钥空间大于2100,信息熵接近于8,密文图像直方图趋近于均匀分布;与其他加密算法相比,BSPDPAD算法密文图像相邻像素相关性系数绝对值减小约12数量级,像素变化率和归一化平均强度明显提高,说明BSPDPAD算法在密钥、明文敏感性、抵抗多种攻击能力等性能上优于其他加密算法,且算法扩散效果好,仅一轮加密就能获得较理想的加密效果。结论将位级选择性加密与像素级环形扩散相结合的BSPDPAD算法可有效抵抗各种攻击,安全性高,适合各种类型的灰度及彩色图像加密,潜在应用价值大。关键词:位级;同步置乱扩散;环形扩散;分块;图像加密61|299|6更新时间:2024-05-07
摘要:目的针对基于位平面信息量分布的选择性加密算法安全性不高、像素置换加密算法不能很好抵抗统计攻击问题,提出一种基于位级同步置乱扩散和像素级环形扩散的图像加密算法(BSPDPAD算法),提高图像加密效率和安全性。方法BSPDPAD算法首先通过分段线性混沌映射产生两组混沌序列,其中一组混沌序列对图像进行随机分块,另一组混沌序列分解到位平面构成位级密钥流;然后,将各像素块分解到位平面,利用位级密钥流同步置乱扩散高位平面、置乱低位平面,实现位平面上块内置乱扩散及块间扩散;最后,再次迭代分段线性混沌映射产生新的密钥流,利用该密钥流对经过位级加密的中间密文图像进行横向顺序扩散和纵向逆序扩散,完成图像加密。结果灰度图像及彩色图像上的计算机仿真实验与性能分析表明:BSPDPAD算法密钥空间大于2100,信息熵接近于8,密文图像直方图趋近于均匀分布;与其他加密算法相比,BSPDPAD算法密文图像相邻像素相关性系数绝对值减小约12数量级,像素变化率和归一化平均强度明显提高,说明BSPDPAD算法在密钥、明文敏感性、抵抗多种攻击能力等性能上优于其他加密算法,且算法扩散效果好,仅一轮加密就能获得较理想的加密效果。结论将位级选择性加密与像素级环形扩散相结合的BSPDPAD算法可有效抵抗各种攻击,安全性高,适合各种类型的灰度及彩色图像加密,潜在应用价值大。关键词:位级;同步置乱扩散;环形扩散;分块;图像加密61|299|6更新时间:2024-05-07
图像处理和编码
-
 摘要:目的由于行人图像分辨率差异、光照差异、行人姿态差异以及摄像机视角和成像质量差异等原因,导致同一行人在不同监控视频中的外观区别很大,给行人再识别带来了巨大挑战。为提高行人再识别的准确率,针对以上问题,提出一种基于多特征融合与交替方向乘子法的行人再识别算法。方法首先利用图像增强算法对所有行人图像进行处理,减少因光照变化产生的影响,然后把处理后的图像进行非均匀分割,同时使用特定区域均值法提取行人图像的HSV和LAB颜色特征以及SILTP(scale invariant local ternary pattern)纹理特征和HOG(histogram of oriented gradient)特征,融合多种特征得到行人图像对的整体与局部相似度度量函数并结合产生相似度函数,最后使用交替方向乘子优化算法更新出最优的测度矩阵实现行人再识别。结果在VIPeR、CUHK01、CUHK03和GRID这4个数据集上进行实验,其中VIPeR、CUHK01和GRID 3个数据集Rank1(排名第1的搜索结果即为待查询人的比率)分别达到51.5%、48.7%和21.4%,CUHK03手动裁剪和检测器检测数据集Rank1分别达到62.40%和55.05%,识别率有了显著提高,具有实际应用价值。结论提出的多特征融合与交替方向乘子优化算法,能够很好地描述行人特征,迭代更新出来的测度矩阵能够很好地表达行人之间的距离信息,较大幅度地提高了识别率。该方法适用于大多数应用场景下的行人再识别。尤其是针对复杂场景下静态图像行人再识别问题,在存在局部遮挡、光照差异和姿态差异的情况下也能保持较高的识别正确率。关键词:行人再识别;多特征融合;非均匀分割;特定区域均值法;HOG特征;交替方向乘子法11|4|6更新时间:2024-05-07
摘要:目的由于行人图像分辨率差异、光照差异、行人姿态差异以及摄像机视角和成像质量差异等原因,导致同一行人在不同监控视频中的外观区别很大,给行人再识别带来了巨大挑战。为提高行人再识别的准确率,针对以上问题,提出一种基于多特征融合与交替方向乘子法的行人再识别算法。方法首先利用图像增强算法对所有行人图像进行处理,减少因光照变化产生的影响,然后把处理后的图像进行非均匀分割,同时使用特定区域均值法提取行人图像的HSV和LAB颜色特征以及SILTP(scale invariant local ternary pattern)纹理特征和HOG(histogram of oriented gradient)特征,融合多种特征得到行人图像对的整体与局部相似度度量函数并结合产生相似度函数,最后使用交替方向乘子优化算法更新出最优的测度矩阵实现行人再识别。结果在VIPeR、CUHK01、CUHK03和GRID这4个数据集上进行实验,其中VIPeR、CUHK01和GRID 3个数据集Rank1(排名第1的搜索结果即为待查询人的比率)分别达到51.5%、48.7%和21.4%,CUHK03手动裁剪和检测器检测数据集Rank1分别达到62.40%和55.05%,识别率有了显著提高,具有实际应用价值。结论提出的多特征融合与交替方向乘子优化算法,能够很好地描述行人特征,迭代更新出来的测度矩阵能够很好地表达行人之间的距离信息,较大幅度地提高了识别率。该方法适用于大多数应用场景下的行人再识别。尤其是针对复杂场景下静态图像行人再识别问题,在存在局部遮挡、光照差异和姿态差异的情况下也能保持较高的识别正确率。关键词:行人再识别;多特征融合;非均匀分割;特定区域均值法;HOG特征;交替方向乘子法11|4|6更新时间:2024-05-07 -
 摘要:目的细粒度车型识别旨在通过任意角度及场景下的车辆外观图像识别出其生产厂家、品牌型号、年款等信息,在智慧交通、安防等领域具有重要意义。针对该问题,目前主流方法已由手工特征提取向卷积神经网络为代表的深度学习方法过渡。但该类方法仍存在弊端,首先是识别时须指定车辆的具体位置,其次是无法充分利用细粒度目标识别其视觉差异主要集中在关键的目标局部的特点。为解决这些问题,提出基于区域建议网络的细粒度识别方法,并成功应用于车型识别。方法区域建议网络是一种全卷积神经网络,该方法首先通过卷积神经网络提取图像深层卷积特征,然后在卷积特征上滑窗产生区域候选,之后将区域候选的特征经分类层及回归层得到其为目标的概率及目标的位置,最后将这些区域候选通过目标检测网络获取其具体类别及目标的精确位置,并通过非极大值抑制算法得到最终识别结果。结果该方法在斯坦福BMW-10数据集的识别准确率为76.38%,在斯坦福Cars-196数据集识别准确率为91.48%,不仅大幅领先于传统手工特征方法,也取得了与目前最优的方法相当的识别性能。该方法同时在真实自然场景中取得了优异的识别效果。结论区域建议网络不仅为目标检测提供了目标的具体位置,而且提供了具有区分度的局部区域,为细粒度目标识别提供了一种新的思路。该方法克服了传统目标识别对于目标位置的依赖,并且能够实现一图多车等复杂场景下的车型细粒度识别,具有更好的鲁棒性及实用性。关键词:深度学习;卷积神经网络;车型识别;细粒度分类;图像分类16|4|3更新时间:2024-05-07
摘要:目的细粒度车型识别旨在通过任意角度及场景下的车辆外观图像识别出其生产厂家、品牌型号、年款等信息,在智慧交通、安防等领域具有重要意义。针对该问题,目前主流方法已由手工特征提取向卷积神经网络为代表的深度学习方法过渡。但该类方法仍存在弊端,首先是识别时须指定车辆的具体位置,其次是无法充分利用细粒度目标识别其视觉差异主要集中在关键的目标局部的特点。为解决这些问题,提出基于区域建议网络的细粒度识别方法,并成功应用于车型识别。方法区域建议网络是一种全卷积神经网络,该方法首先通过卷积神经网络提取图像深层卷积特征,然后在卷积特征上滑窗产生区域候选,之后将区域候选的特征经分类层及回归层得到其为目标的概率及目标的位置,最后将这些区域候选通过目标检测网络获取其具体类别及目标的精确位置,并通过非极大值抑制算法得到最终识别结果。结果该方法在斯坦福BMW-10数据集的识别准确率为76.38%,在斯坦福Cars-196数据集识别准确率为91.48%,不仅大幅领先于传统手工特征方法,也取得了与目前最优的方法相当的识别性能。该方法同时在真实自然场景中取得了优异的识别效果。结论区域建议网络不仅为目标检测提供了目标的具体位置,而且提供了具有区分度的局部区域,为细粒度目标识别提供了一种新的思路。该方法克服了传统目标识别对于目标位置的依赖,并且能够实现一图多车等复杂场景下的车型细粒度识别,具有更好的鲁棒性及实用性。关键词:深度学习;卷积神经网络;车型识别;细粒度分类;图像分类16|4|3更新时间:2024-05-07 -
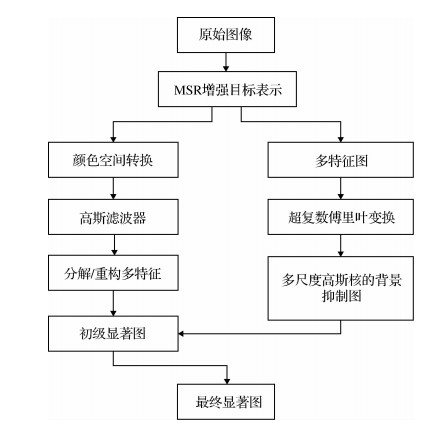 摘要:目的针对显著性目标检测方法生成显著图时存在背景杂乱、检测区域不准确的问题,提出基于复合域的显著性目标检测方法。方法首先,在空间域用多尺度视网膜增强算法对原图像进行初步处理;然后,在初步处理过的图像上建立无向图并提取节点特征,重构超复数傅里叶变换到频域上得到平滑振幅谱、相位谱和欧拉谱,通过多尺度高斯核的平滑,得到背景抑制图;同时,利用小波变换在小波域上的具有多层级特性对图像提取多特征,并计算出多特征的显著性图;最后,利用提出的自适应阈值选择法将背景抑制图与多特征的显著性图进行融合,选择得到最终的显著图。结果对标准测试数据集MSRA10K和THUR15K中的图像进行显著性目标检测实验,同目前较流行的6种显著性目标检测方法对比,结果表明上述问题通过本文方法得到了很好地解决,即使在背景复杂的情况下,本文算法的准确率、召回率均高于对比算法,在MSRA10K数据集中,平均绝对误差(MAE)值为0.106,在THUR15K数据集中,平均绝对误差(MAE)值降低至0.068,平均结构性指标S-measure值为0.844 9。结论基于复合域的显著性目标检测方法,融合多个域的优势,在抑制杂乱的背景的同时提高了准确率,适用于自然景物、生物、建筑以及交通工具等显著性目标图像的检测。关键词:显著性目标检测;多尺度视网膜增强算法;超复数傅里叶变换;小波变换;自适应阈值选择法21|13|1更新时间:2024-05-07
摘要:目的针对显著性目标检测方法生成显著图时存在背景杂乱、检测区域不准确的问题,提出基于复合域的显著性目标检测方法。方法首先,在空间域用多尺度视网膜增强算法对原图像进行初步处理;然后,在初步处理过的图像上建立无向图并提取节点特征,重构超复数傅里叶变换到频域上得到平滑振幅谱、相位谱和欧拉谱,通过多尺度高斯核的平滑,得到背景抑制图;同时,利用小波变换在小波域上的具有多层级特性对图像提取多特征,并计算出多特征的显著性图;最后,利用提出的自适应阈值选择法将背景抑制图与多特征的显著性图进行融合,选择得到最终的显著图。结果对标准测试数据集MSRA10K和THUR15K中的图像进行显著性目标检测实验,同目前较流行的6种显著性目标检测方法对比,结果表明上述问题通过本文方法得到了很好地解决,即使在背景复杂的情况下,本文算法的准确率、召回率均高于对比算法,在MSRA10K数据集中,平均绝对误差(MAE)值为0.106,在THUR15K数据集中,平均绝对误差(MAE)值降低至0.068,平均结构性指标S-measure值为0.844 9。结论基于复合域的显著性目标检测方法,融合多个域的优势,在抑制杂乱的背景的同时提高了准确率,适用于自然景物、生物、建筑以及交通工具等显著性目标图像的检测。关键词:显著性目标检测;多尺度视网膜增强算法;超复数傅里叶变换;小波变换;自适应阈值选择法21|13|1更新时间:2024-05-07 -
 摘要:目的现有的基于马尔可夫链的显著目标检测方法是使用简单线性迭代聚类(SLIC)分割获得超像素块构造图的节点,再将四边界进行复制获得吸收节点,但是SLIC分割结果的好坏直接影响到后续结果,另外,很大一部分图像的显著目标会占据1~2个边界,特别是对于人像、雕塑等,如果直接使用四边界作为待复制的节点,必然影响最终效果。针对以上存在的缺陷,本文提出一种背景吸收的马尔可夫显著目标检测方法。方法首先通过差异化筛选去除差异较大的边界,选择剩余3条边界上的节点进行复制作为马尔可夫链的吸收节点,通过计算转移节点的吸收时间获得初始的显著图,从初始显著图中选择背景可能性较大的节点进行复制作为吸收节点,再进行一次重吸收计算获得显著图,并对多层显著图进行融合获得最终的显著图。结果在ASD、DUT-OMRON和SED 3个公开数据库上,对比实验验证本文方法,与目前12种主流算法相比,在PR曲线、F值和直观上均有明显的提高,3个数据库计算出的F值分别为0.903、0.544 7、0.775 6,验证了算法的有效性。结论本文针对使用图像边界的超像素块复制作为吸收节点和SLIC分割技术的缺陷,提出了一种基于背景吸收马尔可夫显著目标检测模型,实验表明,本文的方法适用于自底向上的图像显著目标检测,特别是适用于存在人像或雕塑等目标的图像,并且可以应用于图像检索、目标识别、图像分割和图像压缩等多个领域。关键词:目标检测,SLIC分割;显著性检测;马尔可夫链;吸收节点;多层图12|4|0更新时间:2024-05-07
摘要:目的现有的基于马尔可夫链的显著目标检测方法是使用简单线性迭代聚类(SLIC)分割获得超像素块构造图的节点,再将四边界进行复制获得吸收节点,但是SLIC分割结果的好坏直接影响到后续结果,另外,很大一部分图像的显著目标会占据1~2个边界,特别是对于人像、雕塑等,如果直接使用四边界作为待复制的节点,必然影响最终效果。针对以上存在的缺陷,本文提出一种背景吸收的马尔可夫显著目标检测方法。方法首先通过差异化筛选去除差异较大的边界,选择剩余3条边界上的节点进行复制作为马尔可夫链的吸收节点,通过计算转移节点的吸收时间获得初始的显著图,从初始显著图中选择背景可能性较大的节点进行复制作为吸收节点,再进行一次重吸收计算获得显著图,并对多层显著图进行融合获得最终的显著图。结果在ASD、DUT-OMRON和SED 3个公开数据库上,对比实验验证本文方法,与目前12种主流算法相比,在PR曲线、F值和直观上均有明显的提高,3个数据库计算出的F值分别为0.903、0.544 7、0.775 6,验证了算法的有效性。结论本文针对使用图像边界的超像素块复制作为吸收节点和SLIC分割技术的缺陷,提出了一种基于背景吸收马尔可夫显著目标检测模型,实验表明,本文的方法适用于自底向上的图像显著目标检测,特别是适用于存在人像或雕塑等目标的图像,并且可以应用于图像检索、目标识别、图像分割和图像压缩等多个领域。关键词:目标检测,SLIC分割;显著性检测;马尔可夫链;吸收节点;多层图12|4|0更新时间:2024-05-07
图像分析和识别
-
 摘要:目的RGB-D相机的外参数可以被用来将相机坐标系下的点云转换到世界坐标系的点云,可以应用在3维场景重建、3维测量、机器人、目标检测等领域。一般的标定方法利用标定物(比如棋盘)对RGB-D彩色相机的外参标定,但并未利用深度信息,故很难简化标定过程,因此,若充分利用深度信息,则极大地简化外参标定的流程。基于彩色图的标定方法,其标定的对象是深度传感器,然而,RGB-D相机大部分则应用基于深度传感器,而基于深度信息的标定方法则可以直接标定深度传感器的姿势。方法首先将深度图转化为相机坐标系下的3维点云,利用MELSAC方法自动检测3维点云中的平面,根据地平面与世界坐标系的约束关系,遍历并筛选平面,直至得到地平面,利用地平面与相机坐标系的空间关系,最终计算出相机的外参数,即相机坐标系内的点与世界坐标系内的点的转换矩阵。结果实验以棋盘的外参标定方法为基准,处理从PrimeSense相机所采集的RGB-D视频流,结果表明,外参标定平均侧倾角误差为-1.14°,平均俯仰角误差为4.57°,平均相机高度误差为3.96 cm。结论该方法通过自动检测地平面,准确估计出相机的外参数,具有很强的自动化,此外,算法具有较高地并行性,进行并行优化后,具有实时性,可应用于自动估计机器人姿势。关键词:RGB-D相机;自动标定;3维点云;平面检测;深度图14|4|1更新时间:2024-05-07
摘要:目的RGB-D相机的外参数可以被用来将相机坐标系下的点云转换到世界坐标系的点云,可以应用在3维场景重建、3维测量、机器人、目标检测等领域。一般的标定方法利用标定物(比如棋盘)对RGB-D彩色相机的外参标定,但并未利用深度信息,故很难简化标定过程,因此,若充分利用深度信息,则极大地简化外参标定的流程。基于彩色图的标定方法,其标定的对象是深度传感器,然而,RGB-D相机大部分则应用基于深度传感器,而基于深度信息的标定方法则可以直接标定深度传感器的姿势。方法首先将深度图转化为相机坐标系下的3维点云,利用MELSAC方法自动检测3维点云中的平面,根据地平面与世界坐标系的约束关系,遍历并筛选平面,直至得到地平面,利用地平面与相机坐标系的空间关系,最终计算出相机的外参数,即相机坐标系内的点与世界坐标系内的点的转换矩阵。结果实验以棋盘的外参标定方法为基准,处理从PrimeSense相机所采集的RGB-D视频流,结果表明,外参标定平均侧倾角误差为-1.14°,平均俯仰角误差为4.57°,平均相机高度误差为3.96 cm。结论该方法通过自动检测地平面,准确估计出相机的外参数,具有很强的自动化,此外,算法具有较高地并行性,进行并行优化后,具有实时性,可应用于自动估计机器人姿势。关键词:RGB-D相机;自动标定;3维点云;平面检测;深度图14|4|1更新时间:2024-05-07 -
 摘要:目的在微小飞行器系统中,如何实时获取场景信息是实现自主避障及导航的关键问题。本文提出了一种融合中心平均Census特征与绝对误差(AD)特征、基于纹理优化的半全局立体匹配算法(ADCC-TSGM),并利用统一计算设备架构(CUDA)进行并行加速。方法使用沿极线方向的一维差分计算纹理信息,使用中心平均Census特征及AD特征进行代价计算,通过纹理优化的SGM算法聚合代价并获得初始视差图;然后,通过左右一致性检验检查剔除粗略视差图中的不稳定点和遮挡点,使用线性插值和中值滤波对视差图中的空洞进行填充;最后,利用GPU特性,对立体匹配中的代价计算、半全局匹配(SGM)计算、视差计算等步骤使用共享内存、单指令多数据流(SIMD)及混合流水线进行优化以提高运行速度。结果在Quarter Video Graphics Array(QVGA)分辨率的middlebury双目图像测试集中,本文提出的ADCC-TSGM算法总坏点率较Semi-Global Block Matching(SGBM)算法降低36.1%,较SGM算法降低28.3%;平均错误率较SGBM算法降低44.5%,较SGM算法降低49.9%。GPU加速实验基于NVIDIA Jetson TK1嵌入式计算平台,在双目匹配性能不变的情况下,通过使用CUDA并行加速,可获得117倍以上加速比,即使相较于已进行SIMD及多核并行优化的SGBM,运行时间也减少了85%。在QVGA分辨率下,GPU加速后的运行帧率可达31.8帧/s。结论本文算法及其CUDA加速可为嵌入式平台提供一种实时获取高质量深度信息的有效途径,可作为微小飞行器、小型机器人等设备进行环境感知、视觉定位、地图构建的基础步骤。关键词:双目视觉;census特征;半全局匹配;CUDA加速;并行计算15|4|6更新时间:2024-05-07
摘要:目的在微小飞行器系统中,如何实时获取场景信息是实现自主避障及导航的关键问题。本文提出了一种融合中心平均Census特征与绝对误差(AD)特征、基于纹理优化的半全局立体匹配算法(ADCC-TSGM),并利用统一计算设备架构(CUDA)进行并行加速。方法使用沿极线方向的一维差分计算纹理信息,使用中心平均Census特征及AD特征进行代价计算,通过纹理优化的SGM算法聚合代价并获得初始视差图;然后,通过左右一致性检验检查剔除粗略视差图中的不稳定点和遮挡点,使用线性插值和中值滤波对视差图中的空洞进行填充;最后,利用GPU特性,对立体匹配中的代价计算、半全局匹配(SGM)计算、视差计算等步骤使用共享内存、单指令多数据流(SIMD)及混合流水线进行优化以提高运行速度。结果在Quarter Video Graphics Array(QVGA)分辨率的middlebury双目图像测试集中,本文提出的ADCC-TSGM算法总坏点率较Semi-Global Block Matching(SGBM)算法降低36.1%,较SGM算法降低28.3%;平均错误率较SGBM算法降低44.5%,较SGM算法降低49.9%。GPU加速实验基于NVIDIA Jetson TK1嵌入式计算平台,在双目匹配性能不变的情况下,通过使用CUDA并行加速,可获得117倍以上加速比,即使相较于已进行SIMD及多核并行优化的SGBM,运行时间也减少了85%。在QVGA分辨率下,GPU加速后的运行帧率可达31.8帧/s。结论本文算法及其CUDA加速可为嵌入式平台提供一种实时获取高质量深度信息的有效途径,可作为微小飞行器、小型机器人等设备进行环境感知、视觉定位、地图构建的基础步骤。关键词:双目视觉;census特征;半全局匹配;CUDA加速;并行计算15|4|6更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的针对已有的3维模型分割方法人为设定过多参数的问题,提出了一种基于拓扑持续性和热亲和度矩阵的3维模型分割方法,只需给定分割部件数即可自动完成分割。方法首先通过拓扑持续性处理3维模型的热核签名,选取生存期最长的几个特征点作为模型被分割部件的显著特征点,对于模型躯干等无法通过生长周期选取特征点的部件,则选取热核签名的最小值所对应的顶点作为显著特征点,从而获得模型的初始聚类中心;然后使用不同的扩散时间所对应的热亲和度矩阵进行k-means聚类,并根据聚类中心的偏移距离等参数筛选聚类结果,从而获得3维模型的分割结果。结果选取人体模型进行分割实验,并与其他方法进行对比分析。结果表明,所提出的热亲和度的计算时间明显优于常用的测地距离和幂指数核;相比基于拓扑持续性和基于测地距离的聚类,本文方法可以正确分割模型的各个部件并获得恰当的分割边界。此外,本文方法针对姿态不同的同一非刚体3维模型可以取得一致性的分割结果,而且对模型表面噪声具有较好的鲁棒性。结论和已有方法相比,本文的基于拓扑持续性和热亲和度矩阵的3维模型分割方法可以在给定分割部件的前提下自动选定聚类中心并获得恰当的分割边界,并广泛适用于常见动物模型的分割。关键词:3维模型;分割;拓扑持续性;热亲和度矩阵;k-均值聚类;热核签名19|6|2更新时间:2024-05-07
摘要:目的针对已有的3维模型分割方法人为设定过多参数的问题,提出了一种基于拓扑持续性和热亲和度矩阵的3维模型分割方法,只需给定分割部件数即可自动完成分割。方法首先通过拓扑持续性处理3维模型的热核签名,选取生存期最长的几个特征点作为模型被分割部件的显著特征点,对于模型躯干等无法通过生长周期选取特征点的部件,则选取热核签名的最小值所对应的顶点作为显著特征点,从而获得模型的初始聚类中心;然后使用不同的扩散时间所对应的热亲和度矩阵进行k-means聚类,并根据聚类中心的偏移距离等参数筛选聚类结果,从而获得3维模型的分割结果。结果选取人体模型进行分割实验,并与其他方法进行对比分析。结果表明,所提出的热亲和度的计算时间明显优于常用的测地距离和幂指数核;相比基于拓扑持续性和基于测地距离的聚类,本文方法可以正确分割模型的各个部件并获得恰当的分割边界。此外,本文方法针对姿态不同的同一非刚体3维模型可以取得一致性的分割结果,而且对模型表面噪声具有较好的鲁棒性。结论和已有方法相比,本文的基于拓扑持续性和热亲和度矩阵的3维模型分割方法可以在给定分割部件的前提下自动选定聚类中心并获得恰当的分割边界,并广泛适用于常见动物模型的分割。关键词:3维模型;分割;拓扑持续性;热亲和度矩阵;k-均值聚类;热核签名19|6|2更新时间:2024-05-07 -
 摘要:目的虽然Ball曲线具有很好的几何特性,但当控制顶点保持不变时,曲线的形状却无法进行调整,这无疑限制了其在几何造型中的应用。为了使得任意次Ball曲线在控制顶点保持不变的情形下具有形状可调性,提出了一种构造带参数的同次Ball曲线的简单方法。方法首先通过将传统三次Ball基的定义区间由[0,1]扩展为[0,α],构造了一种带参数α的三次Ball基,并称之为三次α-Ball基;然后基于三次α-Ball基定义了相应的三次α-Ball曲线,并讨论了三次α-Ball曲线的拼接、参数对曲线的影响以及参数的3种选取方案;最后借助传统高次Ball基的递推性构造了任意次α-Ball基及其对应的α-Ball曲线,并给出了任意次α-Ball基与α-Ball曲线的性质。结果实例表明,所构造的α-Ball曲线是传统Ball曲线的同次扩展,不仅保留了传统Ball曲线的性质,而且还由于带有参数α使得曲线具有更好的表现能力。利用所给出的3种参数选取方案可构造出满足相应要求的α-Ball曲线。结论所提出的α-Ball曲线克服了传统Ball曲线在形状调整方面的不足,是一种构造形状可调的任意次Ball曲线的有效方法。关键词:Ball基;Ball曲线;任意次;同次扩展;形状调整;参数选取17|70|2更新时间:2024-05-07
摘要:目的虽然Ball曲线具有很好的几何特性,但当控制顶点保持不变时,曲线的形状却无法进行调整,这无疑限制了其在几何造型中的应用。为了使得任意次Ball曲线在控制顶点保持不变的情形下具有形状可调性,提出了一种构造带参数的同次Ball曲线的简单方法。方法首先通过将传统三次Ball基的定义区间由[0,1]扩展为[0,α],构造了一种带参数α的三次Ball基,并称之为三次α-Ball基;然后基于三次α-Ball基定义了相应的三次α-Ball曲线,并讨论了三次α-Ball曲线的拼接、参数对曲线的影响以及参数的3种选取方案;最后借助传统高次Ball基的递推性构造了任意次α-Ball基及其对应的α-Ball曲线,并给出了任意次α-Ball基与α-Ball曲线的性质。结果实例表明,所构造的α-Ball曲线是传统Ball曲线的同次扩展,不仅保留了传统Ball曲线的性质,而且还由于带有参数α使得曲线具有更好的表现能力。利用所给出的3种参数选取方案可构造出满足相应要求的α-Ball曲线。结论所提出的α-Ball曲线克服了传统Ball曲线在形状调整方面的不足,是一种构造形状可调的任意次Ball曲线的有效方法。关键词:Ball基;Ball曲线;任意次;同次扩展;形状调整;参数选取17|70|2更新时间:2024-05-07
计算机图形学
-
 摘要:目的准确的解缠绕相位是两点或三点Dixon技术等在磁共振临床应用的前提和关键,然而当相位图像中存在严重噪声、快速相位变换或不连通区域时,当前许多已经提出的相位解缠绕算法将会失败。为此本文提出一种基于相位分区和局部多项式曲面拟合的相位解缠绕新方法,该新方法在相位图像存在严重噪声、快速相位变换或不连通区域的情况下仍可以稳定可靠的工作。方法首先将获得的相位图像分成连通块,块内相位都在给定的相位区间内,把像素个数小于给定阈值的块归类为残余像素。然后利用局域增长的局部多项式曲面拟合方法依次进行块与块之间相位解缠绕和残余像素相位解缠绕。最后使用仿真与真实磁共振Dixon数据来评价提出方法,并与PRELUDE(phase region expanding labeler for unwrapping discrete estimates)方法进行了比较。结果在不同信噪比、快速相位变换或存在不连通区域的仿真实验中,即使当数据中存在信噪比为0.5、相邻相位变换大于π弧度或不连通区域时,提出方法的平均错误率不大于0.51%。对于100层真实的磁共振膝关节和踝关节水与脂肪分离图像,提出方法生成结果中发生明显解缠绕错误及水与脂肪互换的比率为6.00%,而PRELUDE却为42.00%。结论本文提出了一种磁共振相位解缠绕算法,利用相位分区方法,可靠的实现相位图像分块;利用局部多项式曲面拟合方法,准确的实现相位解缠绕。提出方法能够更加鲁棒的实现相位解缠绕,这将有益于相位相关的磁共振临床的应用,如两点和三点Dixon水脂分离技术、磁敏感加权成像和人脑相位成像等。关键词:磁共振成像;相位解缠绕;相位分区;局部多项式曲面拟合;水与脂肪分离12|5|1更新时间:2024-05-07
摘要:目的准确的解缠绕相位是两点或三点Dixon技术等在磁共振临床应用的前提和关键,然而当相位图像中存在严重噪声、快速相位变换或不连通区域时,当前许多已经提出的相位解缠绕算法将会失败。为此本文提出一种基于相位分区和局部多项式曲面拟合的相位解缠绕新方法,该新方法在相位图像存在严重噪声、快速相位变换或不连通区域的情况下仍可以稳定可靠的工作。方法首先将获得的相位图像分成连通块,块内相位都在给定的相位区间内,把像素个数小于给定阈值的块归类为残余像素。然后利用局域增长的局部多项式曲面拟合方法依次进行块与块之间相位解缠绕和残余像素相位解缠绕。最后使用仿真与真实磁共振Dixon数据来评价提出方法,并与PRELUDE(phase region expanding labeler for unwrapping discrete estimates)方法进行了比较。结果在不同信噪比、快速相位变换或存在不连通区域的仿真实验中,即使当数据中存在信噪比为0.5、相邻相位变换大于π弧度或不连通区域时,提出方法的平均错误率不大于0.51%。对于100层真实的磁共振膝关节和踝关节水与脂肪分离图像,提出方法生成结果中发生明显解缠绕错误及水与脂肪互换的比率为6.00%,而PRELUDE却为42.00%。结论本文提出了一种磁共振相位解缠绕算法,利用相位分区方法,可靠的实现相位图像分块;利用局部多项式曲面拟合方法,准确的实现相位解缠绕。提出方法能够更加鲁棒的实现相位解缠绕,这将有益于相位相关的磁共振临床的应用,如两点和三点Dixon水脂分离技术、磁敏感加权成像和人脑相位成像等。关键词:磁共振成像;相位解缠绕;相位分区;局部多项式曲面拟合;水与脂肪分离12|5|1更新时间:2024-05-07 -
 摘要:目的生物医学文献中的图像经常是包含多种模式的复合图像,自动标注其类别,将有助于提高图像检索的性能,辅助医学研究或教学。方法融合图像内容和说明文本两种模态的信息,分别搭建基于深度卷积神经网络的多标签分类模型。视觉分类模型借用自然图像和单标签的生物医学简单图像,实现异质迁移学习和同质迁移学习,捕获通用领域的一般特征和生物医学领域的专有特征,而文本分类模型利用生物医学简单图像的说明文本,实现同质迁移学习。然后,采用分段式融合策略,结合两种模态模型输出的结果,识别多标签医学图像的相关模式。结果本文提出的跨模态多标签分类算法,在ImageCLEF2016生物医学图像多标签分类任务数据集上展开实验。基于图像内容的混合迁移学习方法,比仅采用异质迁移学习的方法,具有更低的汉明损失和更高的宏平均F1值。文本分类模型引入同质迁移学习后,能够明显提高标签的分类性能。最后,融合两种模态的多标签分类模型,获得与评测任务最佳成绩相近的汉明损失,而宏平均F1值从0.320上升到0.488,提高了约52.5%。结论实验结果表明,跨模态生物医学图像多标签分类算法,融合图像内容和说明文本,引入同质和异质数据进行迁移学习,缓解生物医学图像领域标注数据规模小且标签分布不均衡的问题,能够更有效地识别复合医学图像中的模式信息,进而提高图像检索性能。关键词:多标签分类;卷积神经网络;迁移学习;生物医学图像;深度学习25|81|6更新时间:2024-05-07
摘要:目的生物医学文献中的图像经常是包含多种模式的复合图像,自动标注其类别,将有助于提高图像检索的性能,辅助医学研究或教学。方法融合图像内容和说明文本两种模态的信息,分别搭建基于深度卷积神经网络的多标签分类模型。视觉分类模型借用自然图像和单标签的生物医学简单图像,实现异质迁移学习和同质迁移学习,捕获通用领域的一般特征和生物医学领域的专有特征,而文本分类模型利用生物医学简单图像的说明文本,实现同质迁移学习。然后,采用分段式融合策略,结合两种模态模型输出的结果,识别多标签医学图像的相关模式。结果本文提出的跨模态多标签分类算法,在ImageCLEF2016生物医学图像多标签分类任务数据集上展开实验。基于图像内容的混合迁移学习方法,比仅采用异质迁移学习的方法,具有更低的汉明损失和更高的宏平均F1值。文本分类模型引入同质迁移学习后,能够明显提高标签的分类性能。最后,融合两种模态的多标签分类模型,获得与评测任务最佳成绩相近的汉明损失,而宏平均F1值从0.320上升到0.488,提高了约52.5%。结论实验结果表明,跨模态生物医学图像多标签分类算法,融合图像内容和说明文本,引入同质和异质数据进行迁移学习,缓解生物医学图像领域标注数据规模小且标签分布不均衡的问题,能够更有效地识别复合医学图像中的模式信息,进而提高图像检索性能。关键词:多标签分类;卷积神经网络;迁移学习;生物医学图像;深度学习25|81|6更新时间:2024-05-07
医学图像处理
-
 摘要:目的针对用于SAR(synthetic aperture radar)目标识别的深度卷积神经网络模型结构的优化设计难题,在分析卷积核宽度对分类性能影响基础上,设计了一种适用于SAR目标识别的深度卷积神经网络结构。方法首先基于二维随机卷积特征和具有单个隐层的神经网络模型-超限学习机分析了卷积核宽度对SAR图像目标分类性能的影响;然后,基于上述分析结果,在实现空间特征提取的卷积层中采用多个具有不同宽度的卷积核提取目标的多尺度局部特征,设计了一种适用于SAR图像目标识别的深度模型结构;最后,在对MSTAR(moving and stationary target acquisition and recognition)数据集中的训练样本进行样本扩充基础上,设定了深度模型训练的超参数,进行了深度模型参数训练与分类性能验证。结果实验结果表明,对于具有较强相干斑噪声的SAR图像而言,采用宽度更大的卷积核能够提取目标的局部特征,提出的模型因能从输入图像提取目标的多尺度局部特征,对于10类目标的分类结果(包含非变形目标和变形目标两种情况)接近或优于已知文献的最优分类结果,目标总体分类精度分别达到了98.39%和97.69%,验证了提出模型结构的有效性。结论对于SAR图像目标识别,由于与可见光图像具有不同的成像机理,应采用更大的卷积核来提取目标的空间特征用于分类,通过对深度模型进行优化设计能够提高SAR图像目标识别的精度。关键词:SAR目标识别;深度卷积神经网络;结构设计;随机权重;超限学习机12|4|3更新时间:2024-05-07
摘要:目的针对用于SAR(synthetic aperture radar)目标识别的深度卷积神经网络模型结构的优化设计难题,在分析卷积核宽度对分类性能影响基础上,设计了一种适用于SAR目标识别的深度卷积神经网络结构。方法首先基于二维随机卷积特征和具有单个隐层的神经网络模型-超限学习机分析了卷积核宽度对SAR图像目标分类性能的影响;然后,基于上述分析结果,在实现空间特征提取的卷积层中采用多个具有不同宽度的卷积核提取目标的多尺度局部特征,设计了一种适用于SAR图像目标识别的深度模型结构;最后,在对MSTAR(moving and stationary target acquisition and recognition)数据集中的训练样本进行样本扩充基础上,设定了深度模型训练的超参数,进行了深度模型参数训练与分类性能验证。结果实验结果表明,对于具有较强相干斑噪声的SAR图像而言,采用宽度更大的卷积核能够提取目标的局部特征,提出的模型因能从输入图像提取目标的多尺度局部特征,对于10类目标的分类结果(包含非变形目标和变形目标两种情况)接近或优于已知文献的最优分类结果,目标总体分类精度分别达到了98.39%和97.69%,验证了提出模型结构的有效性。结论对于SAR图像目标识别,由于与可见光图像具有不同的成像机理,应采用更大的卷积核来提取目标的空间特征用于分类,通过对深度模型进行优化设计能够提高SAR图像目标识别的精度。关键词:SAR目标识别;深度卷积神经网络;结构设计;随机权重;超限学习机12|4|3更新时间:2024-05-07
遥感图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0