
最新刊期
2018 年 第 23 卷 第 3 期
-
 摘要:目的视频烟雾检测具有响应速度快、不易受环境因素影响、适用面广、成本低等优势,为及早预警火灾提供有力保障。近年涌现大量视频检测方法,尽管检测率有所提升,但仍受到高误报率和高漏报率的困扰。为了全面反映视频烟雾检测的研究现状和最新进展,本文重点针对2014年至2017年国内外公开发表的主要文献,进行全面的梳理和分析。方法该工作建立在广泛文献调研的基础上,立足于视频烟雾检测的基本框架,围绕视频图像预处理、疑似烟区提取、烟雾特征描述、烟雾分类识别等处理阶段,系统地对最新文献进行分析和总结。此外,对区别于传统框架的深度学习检测方法亦进行了相关归纳。结果重点依据烟雾运动特征和烟雾静态特征这两类,对疑似烟区提取方法进行梳理;从统计量特征、变换域特征和局部模式特征3个方面对烟雾特征描述方法进行梳理,并从颜色、形状等七个角度进行总结;从基于规则和基于学习这两个视角,梳理烟雾识别和决策方法;最后,对于基于深度学习的方法单独进行了阐述。文献通过系统地梳理,凝练出视频烟雾检测近几年取得的进展和尚存在的不足,并对视频烟雾检测发展前景进行展望。结论针对视频烟雾检测的研究一直备受青睐,越来越多性能优秀的检测算法不断涌现。通过对现有研究进行全面梳理和系统分析,期望视频烟雾检测能取得更大的进展并更好地应用于工业领域,为火灾预警提供更有力的保障。关键词:视频烟雾检测;烟雾识别;特征提取;运动特征;静态特征;局部特征15|20|19更新时间:2024-05-07
摘要:目的视频烟雾检测具有响应速度快、不易受环境因素影响、适用面广、成本低等优势,为及早预警火灾提供有力保障。近年涌现大量视频检测方法,尽管检测率有所提升,但仍受到高误报率和高漏报率的困扰。为了全面反映视频烟雾检测的研究现状和最新进展,本文重点针对2014年至2017年国内外公开发表的主要文献,进行全面的梳理和分析。方法该工作建立在广泛文献调研的基础上,立足于视频烟雾检测的基本框架,围绕视频图像预处理、疑似烟区提取、烟雾特征描述、烟雾分类识别等处理阶段,系统地对最新文献进行分析和总结。此外,对区别于传统框架的深度学习检测方法亦进行了相关归纳。结果重点依据烟雾运动特征和烟雾静态特征这两类,对疑似烟区提取方法进行梳理;从统计量特征、变换域特征和局部模式特征3个方面对烟雾特征描述方法进行梳理,并从颜色、形状等七个角度进行总结;从基于规则和基于学习这两个视角,梳理烟雾识别和决策方法;最后,对于基于深度学习的方法单独进行了阐述。文献通过系统地梳理,凝练出视频烟雾检测近几年取得的进展和尚存在的不足,并对视频烟雾检测发展前景进行展望。结论针对视频烟雾检测的研究一直备受青睐,越来越多性能优秀的检测算法不断涌现。通过对现有研究进行全面梳理和系统分析,期望视频烟雾检测能取得更大的进展并更好地应用于工业领域,为火灾预警提供更有力的保障。关键词:视频烟雾检测;烟雾识别;特征提取;运动特征;静态特征;局部特征15|20|19更新时间:2024-05-07
综述

-
 摘要:目的针对图像拼接中大视差图像难以配准的问题,提出一种显性子平面自动配准算法。方法假设大视差图像包含多个显性子平面且每个平面内所含特征点密集分布。对该假设进行了验证性实验。所提算法以特征点分布为依据,通过聚类算法实现子平面分割,进而对子平面进行局部配准。首先,使用层次聚类算法对已匹配的特征点聚类,通过一种本文设计的拼接误差确定分组数目,并以各组特征点的聚类中心为新的聚类中心对重叠区域再聚类,分割出目标图像的显性子平面。然后,求解每个显性子平面的投影参数,并采用就近原则分配非重叠区域的单应性矩阵。结果采用公共数据集对本文算法进行测试,并与Auto-Stitching、微软Image Composite Editor两种软件及全局投影拼接方法(Baseline)、尽可能投影算法(APAP)进行对比,采用均方根误差作为配准精度的客观评判标准。实验结果表明,该算法在拼接大视差图像时,能有效地配准局部区域,解决软件和传统方法由误配准引起的鬼影、错位等问题。其均方根误差比Baseline方法平均减小55%左右。与APAP算法相比,均方根误差平均相差10%左右,但可视化配准效果相同且无需调节复杂参数,可实现自动配准。结论提出的显性子平面自动配准算法,通过分割图像所含子平面进而实现局部配准。该方法具有较高的配准精度,在大视差图像配准方面,优于部分软件及算法,可应用于图像拼接中大视差图像的自动配准。关键词:图像拼接;图像配准;大视差图像;聚类;显性子平面30|32|4更新时间:2024-05-07
摘要:目的针对图像拼接中大视差图像难以配准的问题,提出一种显性子平面自动配准算法。方法假设大视差图像包含多个显性子平面且每个平面内所含特征点密集分布。对该假设进行了验证性实验。所提算法以特征点分布为依据,通过聚类算法实现子平面分割,进而对子平面进行局部配准。首先,使用层次聚类算法对已匹配的特征点聚类,通过一种本文设计的拼接误差确定分组数目,并以各组特征点的聚类中心为新的聚类中心对重叠区域再聚类,分割出目标图像的显性子平面。然后,求解每个显性子平面的投影参数,并采用就近原则分配非重叠区域的单应性矩阵。结果采用公共数据集对本文算法进行测试,并与Auto-Stitching、微软Image Composite Editor两种软件及全局投影拼接方法(Baseline)、尽可能投影算法(APAP)进行对比,采用均方根误差作为配准精度的客观评判标准。实验结果表明,该算法在拼接大视差图像时,能有效地配准局部区域,解决软件和传统方法由误配准引起的鬼影、错位等问题。其均方根误差比Baseline方法平均减小55%左右。与APAP算法相比,均方根误差平均相差10%左右,但可视化配准效果相同且无需调节复杂参数,可实现自动配准。结论提出的显性子平面自动配准算法,通过分割图像所含子平面进而实现局部配准。该方法具有较高的配准精度,在大视差图像配准方面,优于部分软件及算法,可应用于图像拼接中大视差图像的自动配准。关键词:图像拼接;图像配准;大视差图像;聚类;显性子平面30|32|4更新时间:2024-05-07 -
 摘要:目的针对2维图像重建(或修复)的准确性和效率问题,以传递函数为核心并提出相关重建算法。方法在图像局部纹理稳定场模型的基础上,针对每一个缺损像素点,考虑其周围已知区域的像素点都对它进行能量传递,且在重建过程中首先将能量传递到最近邻域内,由此构造传递函数并引入标量场的二阶泰勒展开来完成,最终依据最近邻域内的能量值,以插值完成重建。结果采用重新构造的传递函数并结合不同的插值方法分别对缺损的几何图形、灰度图像及彩色图像进行重建,结果与图像场方向导数的局部区域重建算法、典型的CDD(curvature driven diffusion)、BSCB(Bertalmio Sapiro Caselles Ballester)、TV(total variation)重建算法相比,重建准确率分别提高了6%、10%、15%、13%,峰值信噪比(PSNR)分别提高了2 dB、1 dB、3 dB、2.5 dB,并且图像缺损边缘及纹理细节的重建更加清晰。结论对2维图像重建的传递函数的研究及所提出的相关重建算法,对于不同类型图像不同程度的缺损,以保持较好的整体视觉效果和重建效率为前提,较大地提高了重建准确性和PSNR,尤其在图像缺损区域边缘及纹理细节的重建上表现出色。关键词:2维图像重建;稳定场;传递函数;最近邻域;二阶泰勒展开12|4|1更新时间:2024-05-07
摘要:目的针对2维图像重建(或修复)的准确性和效率问题,以传递函数为核心并提出相关重建算法。方法在图像局部纹理稳定场模型的基础上,针对每一个缺损像素点,考虑其周围已知区域的像素点都对它进行能量传递,且在重建过程中首先将能量传递到最近邻域内,由此构造传递函数并引入标量场的二阶泰勒展开来完成,最终依据最近邻域内的能量值,以插值完成重建。结果采用重新构造的传递函数并结合不同的插值方法分别对缺损的几何图形、灰度图像及彩色图像进行重建,结果与图像场方向导数的局部区域重建算法、典型的CDD(curvature driven diffusion)、BSCB(Bertalmio Sapiro Caselles Ballester)、TV(total variation)重建算法相比,重建准确率分别提高了6%、10%、15%、13%,峰值信噪比(PSNR)分别提高了2 dB、1 dB、3 dB、2.5 dB,并且图像缺损边缘及纹理细节的重建更加清晰。结论对2维图像重建的传递函数的研究及所提出的相关重建算法,对于不同类型图像不同程度的缺损,以保持较好的整体视觉效果和重建效率为前提,较大地提高了重建准确性和PSNR,尤其在图像缺损区域边缘及纹理细节的重建上表现出色。关键词:2维图像重建;稳定场;传递函数;最近邻域;二阶泰勒展开12|4|1更新时间:2024-05-07 -
 摘要:目的针对当前大多数数字图像加密算法多采用单一的混沌系统,且置乱方法基本只采用像素行列互换、Arnold变换、Baker变换、序列排序构造替换表等几类,提出一种新的整合神经网络置乱图像的动态自反馈混沌系统图像加密算法。方法该算法通过1维Logistic混沌、chebyshev混沌和自定义m(
摘要:目的针对当前大多数数字图像加密算法多采用单一的混沌系统,且置乱方法基本只采用像素行列互换、Arnold变换、Baker变换、序列排序构造替换表等几类,提出一种新的整合神经网络置乱图像的动态自反馈混沌系统图像加密算法。方法该算法通过1维Logistic混沌、chebyshev混沌和自定义m($x$ 关键词:动态自反馈混沌系统;神经网络;随机性;双重置乱;图像加密11|4|1更新时间:2024-05-07
图像处理和编码
-
 摘要:目的近年来,3DTV(3-dimension television)与VR(virtual reality)技术迅速发展,但3D内容的短缺却成为该类技术发展的瓶颈。为快速提供更多的3D内容,需将现有的2D视频转换为3D视频。深度估计是2D转3D技术的关键,为满足转换过程中实时性较高的要求,本文提出基于相对高度深度线索方法的硬件实现方案。方法首先对灰度图进行Sobel边缘检测得到边缘图,然后对其进行线性追踪以及深度赋值完成深度估计得到深度图。在硬件实现方案中,Sobel边缘检测采用五级流水设计以及并行线轨迹计算方式,充分利用硬件设计的并行性,以提高系统的处理效率;在深度估计中通过等效处理简化“能量函数”的方式将算法中大量的乘法、除法以及指数运算简化成加法、减法和比较运算,以减小硬件资源开销;同时方案设计中巧妙借助SDRAM(synchronous dynamic random access memory)突发特性完成行列转换,节省系统硬件资源。结果最后完成了算法的FPGA(field programmable gate array)实现,并选取了2幅图像进行深度信息提取。将本文方法的软硬件处理效果与基于运动估计的深度图提取方法进行对比,结果表明本文算法相较于运动估计方法对图像深度图提取效果更好,同时硬件处理可以实现对2D图像的深度信息提取,且具有和软件处理一致的效果。在100 MHz的时钟频率下,估算帧率可达33.18帧/s。结论本文提出的硬件实现方案可以完成对单幅图像的深度信息提取且估算帧率远大于3DTV等3维视频应用中实时要求的24帧/s,具有很好的实时性和可移植性,为后期的视频信息处理奠定了基础。关键词:相对高度深度线索;Sobel;线性追踪;五级流水;深度图11|4|1更新时间:2024-05-07
摘要:目的近年来,3DTV(3-dimension television)与VR(virtual reality)技术迅速发展,但3D内容的短缺却成为该类技术发展的瓶颈。为快速提供更多的3D内容,需将现有的2D视频转换为3D视频。深度估计是2D转3D技术的关键,为满足转换过程中实时性较高的要求,本文提出基于相对高度深度线索方法的硬件实现方案。方法首先对灰度图进行Sobel边缘检测得到边缘图,然后对其进行线性追踪以及深度赋值完成深度估计得到深度图。在硬件实现方案中,Sobel边缘检测采用五级流水设计以及并行线轨迹计算方式,充分利用硬件设计的并行性,以提高系统的处理效率;在深度估计中通过等效处理简化“能量函数”的方式将算法中大量的乘法、除法以及指数运算简化成加法、减法和比较运算,以减小硬件资源开销;同时方案设计中巧妙借助SDRAM(synchronous dynamic random access memory)突发特性完成行列转换,节省系统硬件资源。结果最后完成了算法的FPGA(field programmable gate array)实现,并选取了2幅图像进行深度信息提取。将本文方法的软硬件处理效果与基于运动估计的深度图提取方法进行对比,结果表明本文算法相较于运动估计方法对图像深度图提取效果更好,同时硬件处理可以实现对2D图像的深度信息提取,且具有和软件处理一致的效果。在100 MHz的时钟频率下,估算帧率可达33.18帧/s。结论本文提出的硬件实现方案可以完成对单幅图像的深度信息提取且估算帧率远大于3DTV等3维视频应用中实时要求的24帧/s,具有很好的实时性和可移植性,为后期的视频信息处理奠定了基础。关键词:相对高度深度线索;Sobel;线性追踪;五级流水;深度图11|4|1更新时间:2024-05-07 -
 摘要:目的传统的单目视觉SLAM(simultaneous localization and mapping)跟踪失败后需要相机重新回到丢失的位置才能重定位并恢复建图,这极大限制了单目SLAM的应用场景。为解决这一问题,提出一种基于视觉惯性传感器融合的地图恢复融合算法。方法当系统跟踪失败,仅由惯性传感器提供相机位姿,通过对系统重新初始化并结合惯性传感器提供的丢失部分的相机位姿将丢失前的地图融合到当前的地图中;为解决视觉跟踪丢失期间由惯性测量计算导致的相机位姿误差,提出了一种以关键帧之间的共视关系为依据的跳跃式的匹配搜索策略,快速获得匹配地图点,再通过非线性优化求解匹配点之间的运动估计,进行误差补偿,获得更加准确的相机位姿,并删减融合后重复的点云;最后建立前后两个地图中关键帧之间与地图点之间的联系,用于联合优化后续的跟踪建图过程中相机位姿和地图点位置。结果利用Euroc数据集及其他数据进行地图精度和地图完整性实验,在精度方面,将本文算法得到的轨迹与ground truth和未丢失情况下得到的轨迹进行对比,结果表明,在SLAM系统跟踪失败的情况下,此方法能有效解决系统无法继续跟踪建图的问题,其精度可达厘米级别。在30 m2的室内环境中,仅有9 cm的误差,而在300 m2工厂环境中误差仅有7 cm。在完整性方面,在相机运动较剧烈的情况下,恢复地图的完整性优于ORB_SLAM的重定位算法,通过本文算法得到的地图关键帧数量比ORB_SLAM多30%。结论本文提出的算法在单目视觉SLAM系统跟踪失败之后,仍然能够继续跟踪建图,不会丢失相机轨迹。此外,无需相机回到丢失之前的场景中,只需相机观察到部分丢失前场景,即可恢复融合所有地图。本文算法不仅保证了恢复地图的精度,还保证了建图的完整性。与传统的重定位方法相比,本文算法在系统建图较少时跟踪失败的情况下效果更好。关键词:同时定位与建图;惯性测量单位;重定位;地图融合;坐标转换11|4|2更新时间:2024-05-07
摘要:目的传统的单目视觉SLAM(simultaneous localization and mapping)跟踪失败后需要相机重新回到丢失的位置才能重定位并恢复建图,这极大限制了单目SLAM的应用场景。为解决这一问题,提出一种基于视觉惯性传感器融合的地图恢复融合算法。方法当系统跟踪失败,仅由惯性传感器提供相机位姿,通过对系统重新初始化并结合惯性传感器提供的丢失部分的相机位姿将丢失前的地图融合到当前的地图中;为解决视觉跟踪丢失期间由惯性测量计算导致的相机位姿误差,提出了一种以关键帧之间的共视关系为依据的跳跃式的匹配搜索策略,快速获得匹配地图点,再通过非线性优化求解匹配点之间的运动估计,进行误差补偿,获得更加准确的相机位姿,并删减融合后重复的点云;最后建立前后两个地图中关键帧之间与地图点之间的联系,用于联合优化后续的跟踪建图过程中相机位姿和地图点位置。结果利用Euroc数据集及其他数据进行地图精度和地图完整性实验,在精度方面,将本文算法得到的轨迹与ground truth和未丢失情况下得到的轨迹进行对比,结果表明,在SLAM系统跟踪失败的情况下,此方法能有效解决系统无法继续跟踪建图的问题,其精度可达厘米级别。在30 m2的室内环境中,仅有9 cm的误差,而在300 m2工厂环境中误差仅有7 cm。在完整性方面,在相机运动较剧烈的情况下,恢复地图的完整性优于ORB_SLAM的重定位算法,通过本文算法得到的地图关键帧数量比ORB_SLAM多30%。结论本文提出的算法在单目视觉SLAM系统跟踪失败之后,仍然能够继续跟踪建图,不会丢失相机轨迹。此外,无需相机回到丢失之前的场景中,只需相机观察到部分丢失前场景,即可恢复融合所有地图。本文算法不仅保证了恢复地图的精度,还保证了建图的完整性。与传统的重定位方法相比,本文算法在系统建图较少时跟踪失败的情况下效果更好。关键词:同时定位与建图;惯性测量单位;重定位;地图融合;坐标转换11|4|2更新时间:2024-05-07 -
 摘要:目的针对目标在跟踪过程中出现剧烈形变,特别是剧烈尺度变化的而导致跟踪失败情况,提出融合图像显著性与特征点匹配的目标跟踪算法。方法首先利用改进的BRISK(binary robust invariant scalable keypoints)特征点检测算法,对视频序列中的初始帧提取特征点,确定跟踪算法中的目标模板和目标模板特征点集合;接着对当前帧进行特征点检测,并与目标模板特征点集合利用FLANN(fast approximate nearest neighbor search library)方法进行匹配得到匹配特征点子集;然后融合匹配特征点和光流特征点确定可靠特征点集;再后基于可靠特征点集和目标模板特征点集计算单应性变换矩阵粗确定目标跟踪框,继而基于LC(local contrast)图像显著性精确定目标跟踪框;最后融合图像显著性和可靠特征点自适应确定目标跟踪框。当连续三帧目标发生剧烈形变时,更新目标模板和目标模板特征点集。结果为了验证算法性能,在OTB2013数据集中挑选出具有形变特性的8个视频序列,共2214帧图像作为实验数据集。在重合度实验中,本文算法能够达到0.567 1的平均重合度,优于当前先进的跟踪算法;在重合度成功率实验中,本文算法也比当前先进的跟踪算法具有更好的跟踪效果。最后利用Vega Prime仿真了无人机快速抵近飞行下目标出现剧烈形变的航拍视频序列,序列中目标的最大形变量超过14,帧间最大形变量达到1.72,实验表明本文算法在该视频序列上具有更好的跟踪效果。本文算法具有较好的实时性,平均帧率48.6帧/s。结论本文算法能够实时准确的跟踪剧烈形变的目标,特别是剧烈尺度变化的目标。关键词:目标跟踪;形变;尺度变化;图像显著性;特征点匹配11|4|3更新时间:2024-05-07
摘要:目的针对目标在跟踪过程中出现剧烈形变,特别是剧烈尺度变化的而导致跟踪失败情况,提出融合图像显著性与特征点匹配的目标跟踪算法。方法首先利用改进的BRISK(binary robust invariant scalable keypoints)特征点检测算法,对视频序列中的初始帧提取特征点,确定跟踪算法中的目标模板和目标模板特征点集合;接着对当前帧进行特征点检测,并与目标模板特征点集合利用FLANN(fast approximate nearest neighbor search library)方法进行匹配得到匹配特征点子集;然后融合匹配特征点和光流特征点确定可靠特征点集;再后基于可靠特征点集和目标模板特征点集计算单应性变换矩阵粗确定目标跟踪框,继而基于LC(local contrast)图像显著性精确定目标跟踪框;最后融合图像显著性和可靠特征点自适应确定目标跟踪框。当连续三帧目标发生剧烈形变时,更新目标模板和目标模板特征点集。结果为了验证算法性能,在OTB2013数据集中挑选出具有形变特性的8个视频序列,共2214帧图像作为实验数据集。在重合度实验中,本文算法能够达到0.567 1的平均重合度,优于当前先进的跟踪算法;在重合度成功率实验中,本文算法也比当前先进的跟踪算法具有更好的跟踪效果。最后利用Vega Prime仿真了无人机快速抵近飞行下目标出现剧烈形变的航拍视频序列,序列中目标的最大形变量超过14,帧间最大形变量达到1.72,实验表明本文算法在该视频序列上具有更好的跟踪效果。本文算法具有较好的实时性,平均帧率48.6帧/s。结论本文算法能够实时准确的跟踪剧烈形变的目标,特别是剧烈尺度变化的目标。关键词:目标跟踪;形变;尺度变化;图像显著性;特征点匹配11|4|3更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的从真实环境中采集到的人脸图片通常伴随遮挡、光照和表情变化等因素,对识别结果产生干扰。在许多特殊环境下,训练样本的采集数量也无法得到保证,容易产生训练样本远小于测试样本的不利条件。基于以上情况,如何排除复杂的环境变化和较少的训练样本等多重因素对识别效果的影响逐渐成为了人脸识别方向需要攻克的难题。方法以低秩矩阵分解为基础,分别使用非凸秩近似范数和核范数进行两次低秩矩阵分解,以达到去除遮挡干扰的目的。首先通过非凸稳健主成分分析分解得到去除了光照、遮挡等变化的低秩字典。为消除不同人脸类的五官等共通部分的影响,加快算法收敛效率,将得到的低秩字典用作初始化,进行基于核范数的第二次秩近似分解,以获得去除了类间不相关判别性的低秩字典用于分类。最后针对训练样本较少和遮挡样本占比过大等问题,选用同一数据库中不用做训练和测试的辅助数据作为辅助字典模拟可能出现的遮挡、光照等影响,通过最小化稀疏表示重构误差进行分类识别。结果选用AR库和CK+库分别进行实验。在AR库的实验中,通过调整训练图片中遮挡、光照和表情变化的样本比例来检测算法性能。其中,在遮挡图片占比分别为1/7和3/7的训练集中,无遮挡图片由无干扰和光照表情干扰图片联合组成。在遮挡图片占比为2/7的训练集中,无遮挡图片全由光照表情变化图片组成。实验结果表明,在多种实验情况下均获得较高识别率。其中根据不同遮挡比例,分别获得97.75%、92%、95.25%和97.75%、90%、95.25%等识别率。与同类算法对比提高3%~5%。选用的外部数据从10类人脸至40类依次增加,获得的识别结果为96.75%~98%,与同类算法相比提高了2%~3%。在CK+表情库中,选用同伦算法配合分类求解,获得的识别结果为95.25%。结论本文提出了一种在克服复杂环境变化和训练样本不足两个方面具有高效性和鲁棒性的人脸识别算法,实验结果表明,本文算法在不同数据库中都具有高效性,未来的研究方向包括将算法应用于联立人脸和表情识别,模拟更为复杂的噪声状况,以期达到更为优异的结果。关键词:人脸识别;低秩分解;字典学习;结构不相关11|4|4更新时间:2024-05-07
摘要:目的从真实环境中采集到的人脸图片通常伴随遮挡、光照和表情变化等因素,对识别结果产生干扰。在许多特殊环境下,训练样本的采集数量也无法得到保证,容易产生训练样本远小于测试样本的不利条件。基于以上情况,如何排除复杂的环境变化和较少的训练样本等多重因素对识别效果的影响逐渐成为了人脸识别方向需要攻克的难题。方法以低秩矩阵分解为基础,分别使用非凸秩近似范数和核范数进行两次低秩矩阵分解,以达到去除遮挡干扰的目的。首先通过非凸稳健主成分分析分解得到去除了光照、遮挡等变化的低秩字典。为消除不同人脸类的五官等共通部分的影响,加快算法收敛效率,将得到的低秩字典用作初始化,进行基于核范数的第二次秩近似分解,以获得去除了类间不相关判别性的低秩字典用于分类。最后针对训练样本较少和遮挡样本占比过大等问题,选用同一数据库中不用做训练和测试的辅助数据作为辅助字典模拟可能出现的遮挡、光照等影响,通过最小化稀疏表示重构误差进行分类识别。结果选用AR库和CK+库分别进行实验。在AR库的实验中,通过调整训练图片中遮挡、光照和表情变化的样本比例来检测算法性能。其中,在遮挡图片占比分别为1/7和3/7的训练集中,无遮挡图片由无干扰和光照表情干扰图片联合组成。在遮挡图片占比为2/7的训练集中,无遮挡图片全由光照表情变化图片组成。实验结果表明,在多种实验情况下均获得较高识别率。其中根据不同遮挡比例,分别获得97.75%、92%、95.25%和97.75%、90%、95.25%等识别率。与同类算法对比提高3%~5%。选用的外部数据从10类人脸至40类依次增加,获得的识别结果为96.75%~98%,与同类算法相比提高了2%~3%。在CK+表情库中,选用同伦算法配合分类求解,获得的识别结果为95.25%。结论本文提出了一种在克服复杂环境变化和训练样本不足两个方面具有高效性和鲁棒性的人脸识别算法,实验结果表明,本文算法在不同数据库中都具有高效性,未来的研究方向包括将算法应用于联立人脸和表情识别,模拟更为复杂的噪声状况,以期达到更为优异的结果。关键词:人脸识别;低秩分解;字典学习;结构不相关11|4|4更新时间:2024-05-07 -
 摘要:目的多字体的汉字识别在中文自动处理及智能输入等方面具有广阔的应用前景,是模式识别领域的一个重要课题。近年来,随着深度学习新技术的出现,基于深度卷积神经网络的汉字识别在方法和性能上得到了突破性的进展。然而现有方法存在样本需求量大、训练时间长、调参难度大等问题,针对大类别的汉字识别很难达到最佳效果。方法针对无遮挡的印刷及手写体汉字图像,提出了一种端对端的深度卷积神经网络模型。不考虑附加层,该网络主要由3个卷积层、2个池化层、1个全连接层和一个Softmax回归层组成。为解决样本量不足的问题,提出了综合运用波纹扭曲、平移、旋转、缩放的数据扩增方法。为了解决深度神经网络参数调整难度大、训练时间长的问题,提出了对样本进行批标准化以及采用多种优化方法相结合精调网络等策略。结果实验采用该深度模型对国标一级3 755类汉字进行识别,最终识别准确率达到98.336%。同时通过多组对比实验,验证了所提出的各种方法对改善模型最终效果的贡献。其中使用数据扩增、使用混合优化方法和使用批标准化后模型对测试样本的识别率分别提高了8.0%、0.3%和1.4%。结论与其他文献中利用手工提取特征结合卷积神经网络的方法相比,减少了人工提取特征的工作量;与经典卷积神经网络相比,该网络特征提取能力更强,识别率更高,训练时间更短。关键词:汉字识别;卷积神经网络;深度学习;数据扩增;批标准化17|7|6更新时间:2024-05-07
摘要:目的多字体的汉字识别在中文自动处理及智能输入等方面具有广阔的应用前景,是模式识别领域的一个重要课题。近年来,随着深度学习新技术的出现,基于深度卷积神经网络的汉字识别在方法和性能上得到了突破性的进展。然而现有方法存在样本需求量大、训练时间长、调参难度大等问题,针对大类别的汉字识别很难达到最佳效果。方法针对无遮挡的印刷及手写体汉字图像,提出了一种端对端的深度卷积神经网络模型。不考虑附加层,该网络主要由3个卷积层、2个池化层、1个全连接层和一个Softmax回归层组成。为解决样本量不足的问题,提出了综合运用波纹扭曲、平移、旋转、缩放的数据扩增方法。为了解决深度神经网络参数调整难度大、训练时间长的问题,提出了对样本进行批标准化以及采用多种优化方法相结合精调网络等策略。结果实验采用该深度模型对国标一级3 755类汉字进行识别,最终识别准确率达到98.336%。同时通过多组对比实验,验证了所提出的各种方法对改善模型最终效果的贡献。其中使用数据扩增、使用混合优化方法和使用批标准化后模型对测试样本的识别率分别提高了8.0%、0.3%和1.4%。结论与其他文献中利用手工提取特征结合卷积神经网络的方法相比,减少了人工提取特征的工作量;与经典卷积神经网络相比,该网络特征提取能力更强,识别率更高,训练时间更短。关键词:汉字识别;卷积神经网络;深度学习;数据扩增;批标准化17|7|6更新时间:2024-05-07 -
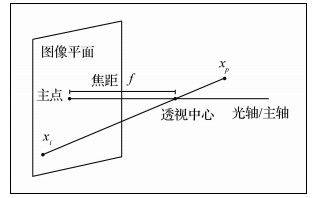 摘要:目的在列车运行安全性评价中,轮轨冲角是一关键性指标。列车运行过程中车体存在强烈振动,而且在基于应变片及传感器的冲角接触测量方法中存在许多弊端,例如丢失,损坏等问题,但冲角作为轮轨接触安全状态评价中的重要参数,对列车运行稳定性评价方面具有重要意义。为了避免接触测量方法中测量传感部件易损坏,丢失以及冲角值小等原因导致轮轨冲角检测难度大等问题,提出了一种新的轮轨冲角的图像检测方法。方法首先,将CCD传感器安装在转向架上构成视觉检测系统;其次,根据相机物像空间几何成像模型建立车轮运动中轮缘角度与图像中椭圆短轴变化关系,实现对3维空间中轮缘位置和角度信息的采样与记录,并证明了轮缘几何特性与车轮偏转角度之间单一映射关系,将轮轨冲角φ的检测转化为椭圆短轴长度特征的检测,缩减了检测难度,增加了可行性;最后,给出冲角仿真结果。结果实验结果表明,该方法测得的冲角值与使用仪器检测的冲角数值平均误差为0.024°,最大误差0.084°,单帧图像检测时间大约400 ms,通过仿真得出冲角的范围在0.75°内,且随机车速度的增大而增大,冲角在径向机构未锁定时小于锁定状态。结论该方法检测速度较快且准确性较高,具有一定的工程应用价值,能为后续列车运行的稳定性和安全性评价奠定了一定的基础。关键词:蛇形运动;轮轨冲角;椭圆检测;安全性评价11|4|0更新时间:2024-05-07
摘要:目的在列车运行安全性评价中,轮轨冲角是一关键性指标。列车运行过程中车体存在强烈振动,而且在基于应变片及传感器的冲角接触测量方法中存在许多弊端,例如丢失,损坏等问题,但冲角作为轮轨接触安全状态评价中的重要参数,对列车运行稳定性评价方面具有重要意义。为了避免接触测量方法中测量传感部件易损坏,丢失以及冲角值小等原因导致轮轨冲角检测难度大等问题,提出了一种新的轮轨冲角的图像检测方法。方法首先,将CCD传感器安装在转向架上构成视觉检测系统;其次,根据相机物像空间几何成像模型建立车轮运动中轮缘角度与图像中椭圆短轴变化关系,实现对3维空间中轮缘位置和角度信息的采样与记录,并证明了轮缘几何特性与车轮偏转角度之间单一映射关系,将轮轨冲角φ的检测转化为椭圆短轴长度特征的检测,缩减了检测难度,增加了可行性;最后,给出冲角仿真结果。结果实验结果表明,该方法测得的冲角值与使用仪器检测的冲角数值平均误差为0.024°,最大误差0.084°,单帧图像检测时间大约400 ms,通过仿真得出冲角的范围在0.75°内,且随机车速度的增大而增大,冲角在径向机构未锁定时小于锁定状态。结论该方法检测速度较快且准确性较高,具有一定的工程应用价值,能为后续列车运行的稳定性和安全性评价奠定了一定的基础。关键词:蛇形运动;轮轨冲角;椭圆检测;安全性评价11|4|0更新时间:2024-05-07 -
 摘要:目的图像分割是计算机视觉、数字图像处理等应用领域首要解决的关键问题。针对现有的单幅图像物体分割算法广泛存在的过分割和过合并现象,提出基于图像T型节点线索的图像物体分割算法。方法首先,利用L0梯度最小化方法平滑目标图像,剔除细小纹理的干扰;其次,基于Graph-based分割算法对平滑后图像进行适度分割,得到粗糙分割结果;最后,借助于图像中广泛存在的T型节点线索对初始分割块进行区域合并得到最终优化分割结果。结果将本文算法分别与Grabcut算法及Graph-based算法在不同场景类型下进行了实验与对比。实验结果显示,Grabcut算法需要人工定位边界且一次只能分割单个物体,Graph-based算法综合类内相似度和类间差异性,可以有效保持图像边界,但无法有效控制分割块数量,且分割结果对阈值参数过分依赖,极易导致过分割和过合并现象。本文方法在降低过分割和过合并现象、边界定位精确性和分割准确率方面获得明显改进,几组不同类型的图片分割准确率平均值达到91.16%,明显由于其他算法。处理图像尺寸800×600像素的图像平均耗时3.5 s,较之其他算法略有增加。结论与各种算法对比结果表明,该算法可有效解决过分割和过合并问题,对比实验结果验证了该方法的有效性,能够取得具有一定语义的图像物体分割结果。关键词:图像分割;T型节点;L0梯度最小化;graph-based算法;分割评价12|5|1更新时间:2024-05-07
摘要:目的图像分割是计算机视觉、数字图像处理等应用领域首要解决的关键问题。针对现有的单幅图像物体分割算法广泛存在的过分割和过合并现象,提出基于图像T型节点线索的图像物体分割算法。方法首先,利用L0梯度最小化方法平滑目标图像,剔除细小纹理的干扰;其次,基于Graph-based分割算法对平滑后图像进行适度分割,得到粗糙分割结果;最后,借助于图像中广泛存在的T型节点线索对初始分割块进行区域合并得到最终优化分割结果。结果将本文算法分别与Grabcut算法及Graph-based算法在不同场景类型下进行了实验与对比。实验结果显示,Grabcut算法需要人工定位边界且一次只能分割单个物体,Graph-based算法综合类内相似度和类间差异性,可以有效保持图像边界,但无法有效控制分割块数量,且分割结果对阈值参数过分依赖,极易导致过分割和过合并现象。本文方法在降低过分割和过合并现象、边界定位精确性和分割准确率方面获得明显改进,几组不同类型的图片分割准确率平均值达到91.16%,明显由于其他算法。处理图像尺寸800×600像素的图像平均耗时3.5 s,较之其他算法略有增加。结论与各种算法对比结果表明,该算法可有效解决过分割和过合并问题,对比实验结果验证了该方法的有效性,能够取得具有一定语义的图像物体分割结果。关键词:图像分割;T型节点;L0梯度最小化;graph-based算法;分割评价12|5|1更新时间:2024-05-07 -
 摘要:目的医学图像分割结果可帮助医生进行预测、诊断及制定治疗方案。医学图像在采集过程中受多种因素影响,同一组织往往具有不同灰度,且伴有强噪声。现有的针对医学图像的分割方法,对图像的灰度分布描述不够充分,不足以为精确的分割图像信息,且抗噪性较差。为实现医学图像的精确分割,提出一种多描述子的活动轮廓(MDAC)模型。方法首先,引入图像的熵,结合图像的局部均值和方差共同描述图像的灰度分布。其次,在贝叶斯框架下,引入灰度偏移因子,建立活动轮廓模型的能量泛函。最后,利用梯度下降流法得到水平集演化公式,演化的最后在完成分割的同时实现偏移场的矫正。结果利用合成图像和心脏、血管和脑等医学图像进行了仿真实验。利用MDAC模型对加噪的灰度不均图像进行分割,结果显示,在完成精确分割的同时实现了纠偏。通过对比分割前后图像的灰度直方图,纠偏图像只包含对应两相的两个峰,且界限更加清晰;与经典分割算法进行对比,MDAC在视觉效果和定量分析中,分割效果最好,比LIC的分割精度提高了30%多。结论实验结果表明,利用均值、方差和局部熵共同描述图像灰度分布,保证了算法的精度。局部熵的引入,在保证算法精度的同时,提高了算法的抗噪性。能泛中嵌入偏移因子,保证算法精确分割的同时实现偏移场纠正,进一步提高分割精度。关键词:医学图像分割;活动轮廓模型;局部熵;灰度不均匀;偏移场13|5|6更新时间:2024-05-07
摘要:目的医学图像分割结果可帮助医生进行预测、诊断及制定治疗方案。医学图像在采集过程中受多种因素影响,同一组织往往具有不同灰度,且伴有强噪声。现有的针对医学图像的分割方法,对图像的灰度分布描述不够充分,不足以为精确的分割图像信息,且抗噪性较差。为实现医学图像的精确分割,提出一种多描述子的活动轮廓(MDAC)模型。方法首先,引入图像的熵,结合图像的局部均值和方差共同描述图像的灰度分布。其次,在贝叶斯框架下,引入灰度偏移因子,建立活动轮廓模型的能量泛函。最后,利用梯度下降流法得到水平集演化公式,演化的最后在完成分割的同时实现偏移场的矫正。结果利用合成图像和心脏、血管和脑等医学图像进行了仿真实验。利用MDAC模型对加噪的灰度不均图像进行分割,结果显示,在完成精确分割的同时实现了纠偏。通过对比分割前后图像的灰度直方图,纠偏图像只包含对应两相的两个峰,且界限更加清晰;与经典分割算法进行对比,MDAC在视觉效果和定量分析中,分割效果最好,比LIC的分割精度提高了30%多。结论实验结果表明,利用均值、方差和局部熵共同描述图像灰度分布,保证了算法的精度。局部熵的引入,在保证算法精度的同时,提高了算法的抗噪性。能泛中嵌入偏移因子,保证算法精确分割的同时实现偏移场纠正,进一步提高分割精度。关键词:医学图像分割;活动轮廓模型;局部熵;灰度不均匀;偏移场13|5|6更新时间:2024-05-07 -
 摘要:目的在眼底图像分析中,准确的黄斑中心定位对于糖尿病性视网膜病变的计算机辅助诊断系统具有重要的意义。然而,由于光照不均匀、计算量大及病变的干扰给黄斑中心定位带来了巨大的挑战。因此,为了实现更为准确且高效的黄斑中心检测,提出一种基于血管投影和数学形态学的黄斑中心检测方法。方法首先,基于数学形态学,提出一种自动的血管检测方法。其次,利用视盘区域的血管分布实现视盘中心的自动定位。再次,根据视盘和黄斑的解剖学结构先验信息,提取感兴趣区域。最后,在感兴趣区域内,通过数学形态学和特征提取定位黄斑中心。结果本文提出的方法在两个标准的糖尿病视网膜病变数据库DIARETDB0和DIARETDB1上分别取得了96.92%和96.63%的成功率,且总成功率达到96.35%。此外,平均的执行时间分别为8.236 s和8.912 s。结论实验结果表明,本文方法能快速和准确地定位黄斑中心且其性能明显地优于现有的黄斑中心检测方法。关键词:计算机辅助诊断;视网膜眼底图像;视盘;黄斑中心;数学形态学;投影13|4|1更新时间:2024-05-07
摘要:目的在眼底图像分析中,准确的黄斑中心定位对于糖尿病性视网膜病变的计算机辅助诊断系统具有重要的意义。然而,由于光照不均匀、计算量大及病变的干扰给黄斑中心定位带来了巨大的挑战。因此,为了实现更为准确且高效的黄斑中心检测,提出一种基于血管投影和数学形态学的黄斑中心检测方法。方法首先,基于数学形态学,提出一种自动的血管检测方法。其次,利用视盘区域的血管分布实现视盘中心的自动定位。再次,根据视盘和黄斑的解剖学结构先验信息,提取感兴趣区域。最后,在感兴趣区域内,通过数学形态学和特征提取定位黄斑中心。结果本文提出的方法在两个标准的糖尿病视网膜病变数据库DIARETDB0和DIARETDB1上分别取得了96.92%和96.63%的成功率,且总成功率达到96.35%。此外,平均的执行时间分别为8.236 s和8.912 s。结论实验结果表明,本文方法能快速和准确地定位黄斑中心且其性能明显地优于现有的黄斑中心检测方法。关键词:计算机辅助诊断;视网膜眼底图像;视盘;黄斑中心;数学形态学;投影13|4|1更新时间:2024-05-07 -
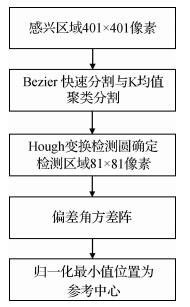 摘要:目的热带气旋(TC)是生成于热带或副热带洋面上的强烈天气系统。在TC的监测分析和预报工作中,准确地确定其中心实时地理位置至关重要。此外,TC的精确位置也是TC强度估计的重要参数。对此,提出一种利用偏差角方差定位TC中心的方法。方法首先,从红外卫星云图中截取热带气旋主体云系区域,并分别利用Bezier直方图和K均值聚类方法分割得到主体云系二值图像和红外亮温变化剧烈位置二值图像。其中,主体云系二值图像可将TC的主体云系从卫星红外云图中分割提取出来,用割提取出来的图像进行定位可以剔除掉外散环流的小云块对定位结果的影响;而红外亮温变化剧烈位置二值图像则可分别将TC中心密闭云区,螺旋云带和外散环流的边缘及梯度较大区域分割出来,这些区域是最后TC中心定位的主要依据。将上述两幅二值图像相与得到气旋主体云系红外亮温变化剧烈位置的二值图像,这一步剔除了TC的外散环流,而得到的二值图像便可分别将TC中心密闭云区和螺旋云带的边缘及梯度较大的区域分割出来。然后,对得到的气旋主体云系红外亮温变化剧烈位置二值图像进行Hough变换检测以减小气旋中心的搜索范围。最后,以检测区域内每个像素点为参考中心计算得到偏差角矩阵,并计算偏差角矩阵的方差填入对应检测区域内作为参考中心像素点的位置得到方差矩阵,将方差矩阵中值最小的位置作为气旋中心。因为TC除了少数特别强的时候大多数可以用圆形描述,而绝大多数时候TC要用螺旋线描述,但是具体是几度螺旋线来描述合适很难确定,本文用偏差角的方差就可以衡量这些云带、边缘的偏离状况是否集中,方差越小就表示偏离状况越集中。结果运用该方法对400幅无眼TC红外图像和197幅有眼TC红外图像进行中心定位,分别与中国气象局(CMA)、日本气象厅(JMA)和美国台风预警中心(JTWC)的主观定位结果进行比较并取平均偏差,本文方法对有眼TC定位平均偏差约为27 km,无眼TC平均偏差约为45 km。具体到分别与CMA、JMA和JTWC的比较,对于有眼TC定位偏差分别为26.82 km,26.05 km和27.84 km,无眼TC定位偏差为45.84 km,44.84 km和47.15 km。结论就结果而言,本文方法定位与CMA、JMA的偏差比较接近,与JTWC的偏差较大。就西北太平洋的TC而言,CMA和JMA的定位精度较高,JTWC精度稍低,这是与认知相符合,并且也证明了本文方法具有较高的可信度。此外,本文方法为TC定位提供了新的参考依据。关键词:偏差角方差;Bezier直方图分割;K均值聚类分割;Hough变换11|4|3更新时间:2024-05-07
摘要:目的热带气旋(TC)是生成于热带或副热带洋面上的强烈天气系统。在TC的监测分析和预报工作中,准确地确定其中心实时地理位置至关重要。此外,TC的精确位置也是TC强度估计的重要参数。对此,提出一种利用偏差角方差定位TC中心的方法。方法首先,从红外卫星云图中截取热带气旋主体云系区域,并分别利用Bezier直方图和K均值聚类方法分割得到主体云系二值图像和红外亮温变化剧烈位置二值图像。其中,主体云系二值图像可将TC的主体云系从卫星红外云图中分割提取出来,用割提取出来的图像进行定位可以剔除掉外散环流的小云块对定位结果的影响;而红外亮温变化剧烈位置二值图像则可分别将TC中心密闭云区,螺旋云带和外散环流的边缘及梯度较大区域分割出来,这些区域是最后TC中心定位的主要依据。将上述两幅二值图像相与得到气旋主体云系红外亮温变化剧烈位置的二值图像,这一步剔除了TC的外散环流,而得到的二值图像便可分别将TC中心密闭云区和螺旋云带的边缘及梯度较大的区域分割出来。然后,对得到的气旋主体云系红外亮温变化剧烈位置二值图像进行Hough变换检测以减小气旋中心的搜索范围。最后,以检测区域内每个像素点为参考中心计算得到偏差角矩阵,并计算偏差角矩阵的方差填入对应检测区域内作为参考中心像素点的位置得到方差矩阵,将方差矩阵中值最小的位置作为气旋中心。因为TC除了少数特别强的时候大多数可以用圆形描述,而绝大多数时候TC要用螺旋线描述,但是具体是几度螺旋线来描述合适很难确定,本文用偏差角的方差就可以衡量这些云带、边缘的偏离状况是否集中,方差越小就表示偏离状况越集中。结果运用该方法对400幅无眼TC红外图像和197幅有眼TC红外图像进行中心定位,分别与中国气象局(CMA)、日本气象厅(JMA)和美国台风预警中心(JTWC)的主观定位结果进行比较并取平均偏差,本文方法对有眼TC定位平均偏差约为27 km,无眼TC平均偏差约为45 km。具体到分别与CMA、JMA和JTWC的比较,对于有眼TC定位偏差分别为26.82 km,26.05 km和27.84 km,无眼TC定位偏差为45.84 km,44.84 km和47.15 km。结论就结果而言,本文方法定位与CMA、JMA的偏差比较接近,与JTWC的偏差较大。就西北太平洋的TC而言,CMA和JMA的定位精度较高,JTWC精度稍低,这是与认知相符合,并且也证明了本文方法具有较高的可信度。此外,本文方法为TC定位提供了新的参考依据。关键词:偏差角方差;Bezier直方图分割;K均值聚类分割;Hough变换11|4|3更新时间:2024-05-07 -
 摘要:目的红外数字TDI(time delay integration)先经过信号的模拟数字转换,再进行时间延迟累加,曝光方式比较灵活,能够提高探测系统灵敏度以及探测目标信噪比,在航空航天遥感应用领域具有广泛的应用,红外数字TDI通常采用扫描方式成像,既具有扫描成像的特点,其本身又是一个小面阵,在信息获取上具有扫描和凝视双重特性,在信息处理端,成像非均匀性是限制其成像质量的关键因素,降低输出图像的非均匀性,对开展目标探测、识别等研究和应用具有重要意义。方法通过分析成像系统的每个部分,建立成像输入输出模型,并讨论模型中各个参数对成像非均匀性的影响,指出优化系统非均匀性的途径;对图像非均匀性校正分为盲元补偿和有效像元的非均匀性校正,对盲元进行邻域像素替代和邻域像素平均的交替迭代补偿提高了盲元的补偿率,对有效像元分析了所有像元的响应特性,选择了曲线拟合的目标校正曲线对系统灰度输出与输入能量之间的非线性进行校正,并引入校正因子对非扫描方向上的非均匀性进一步校正。结果使用上海技术物理研究所研制的640×8中波红外数字TDI探测器进行了黑体定标验证,结果表明,在特定温度下的黑体成像经过校正后的非均匀性由19.44%下降到4.01%,外场实验获得的红外TDI图像上的横条纹明显减少和弱化。结论通过分析对目标场景成像从光信号到电信号的整个链路,得到影响成像非均匀性的具体参数,对红外数字TDI成像系统设计具有一定参考意义;使用本文方法对红外数字TDI成像进行了盲元补偿和非均匀性校正,成像非均匀性显著下降,验证了该方法的有效性。关键词:红外;成像;模型;盲元;非均匀校正26|5|1更新时间:2024-05-07
摘要:目的红外数字TDI(time delay integration)先经过信号的模拟数字转换,再进行时间延迟累加,曝光方式比较灵活,能够提高探测系统灵敏度以及探测目标信噪比,在航空航天遥感应用领域具有广泛的应用,红外数字TDI通常采用扫描方式成像,既具有扫描成像的特点,其本身又是一个小面阵,在信息获取上具有扫描和凝视双重特性,在信息处理端,成像非均匀性是限制其成像质量的关键因素,降低输出图像的非均匀性,对开展目标探测、识别等研究和应用具有重要意义。方法通过分析成像系统的每个部分,建立成像输入输出模型,并讨论模型中各个参数对成像非均匀性的影响,指出优化系统非均匀性的途径;对图像非均匀性校正分为盲元补偿和有效像元的非均匀性校正,对盲元进行邻域像素替代和邻域像素平均的交替迭代补偿提高了盲元的补偿率,对有效像元分析了所有像元的响应特性,选择了曲线拟合的目标校正曲线对系统灰度输出与输入能量之间的非线性进行校正,并引入校正因子对非扫描方向上的非均匀性进一步校正。结果使用上海技术物理研究所研制的640×8中波红外数字TDI探测器进行了黑体定标验证,结果表明,在特定温度下的黑体成像经过校正后的非均匀性由19.44%下降到4.01%,外场实验获得的红外TDI图像上的横条纹明显减少和弱化。结论通过分析对目标场景成像从光信号到电信号的整个链路,得到影响成像非均匀性的具体参数,对红外数字TDI成像系统设计具有一定参考意义;使用本文方法对红外数字TDI成像进行了盲元补偿和非均匀性校正,成像非均匀性显著下降,验证了该方法的有效性。关键词:红外;成像;模型;盲元;非均匀校正26|5|1更新时间:2024-05-07
CACIS 2017学术会议专栏
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0