
最新刊期
2018 年 第 23 卷 第 1 期
-
 摘要:目的像素置换作为一种可逆信息隐藏方式具有良好的抗灰度直方图隐写分析能力,但嵌入容量偏小一直是其缺陷。针对这一问题,提出了一种基于像素置换的自适应可逆信息隐藏算法。方法首先,与传统2×2像素块结构相比构造了尺寸更小的像素对结构,使得载体图像可以被更稠密地分割,为嵌入容量的提升提供了基数条件。其次,提出适用于该新像素结构的可嵌像素对(EPP)筛选条件,避免嵌入过程引起图像质量大幅下降。之后,根据EPP的灰度趋势差异对其进行自适应预编码,提高Huffman编码压缩比,进一步提升算法嵌入容量。最终,通过像素置换嵌入信息。结果与2×2像素块结构的非自适应图像隐写算法相比,在同样保证灰度直方图稳定性的情况下该算法的PSNR提高了32%左右,嵌入容量提高了95%以上。其中自适应性对嵌入容量提升的贡献极大。结论本文算法同时具有抗灰度直方图隐写分析能力与高嵌入容量性的可逆信息隐藏。算法构造了更高效的可嵌单位,并且针对不同载体图像的特点对其可嵌区域进行差异化编码。实验结果表明,本文算法在具有更好的不可见性的同时,嵌入容量得到大幅提升。关键词:可逆信息隐藏;像素置换;自适应;压缩编码;可嵌像素对;灰度直方图13|19|3更新时间:2024-05-07
摘要:目的像素置换作为一种可逆信息隐藏方式具有良好的抗灰度直方图隐写分析能力,但嵌入容量偏小一直是其缺陷。针对这一问题,提出了一种基于像素置换的自适应可逆信息隐藏算法。方法首先,与传统2×2像素块结构相比构造了尺寸更小的像素对结构,使得载体图像可以被更稠密地分割,为嵌入容量的提升提供了基数条件。其次,提出适用于该新像素结构的可嵌像素对(EPP)筛选条件,避免嵌入过程引起图像质量大幅下降。之后,根据EPP的灰度趋势差异对其进行自适应预编码,提高Huffman编码压缩比,进一步提升算法嵌入容量。最终,通过像素置换嵌入信息。结果与2×2像素块结构的非自适应图像隐写算法相比,在同样保证灰度直方图稳定性的情况下该算法的PSNR提高了32%左右,嵌入容量提高了95%以上。其中自适应性对嵌入容量提升的贡献极大。结论本文算法同时具有抗灰度直方图隐写分析能力与高嵌入容量性的可逆信息隐藏。算法构造了更高效的可嵌单位,并且针对不同载体图像的特点对其可嵌区域进行差异化编码。实验结果表明,本文算法在具有更好的不可见性的同时,嵌入容量得到大幅提升。关键词:可逆信息隐藏;像素置换;自适应;压缩编码;可嵌像素对;灰度直方图13|19|3更新时间:2024-05-07 -
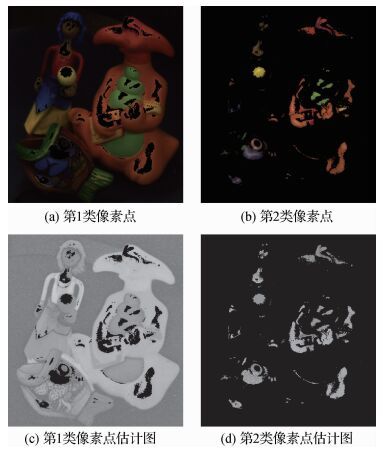 摘要:目的由于非均匀光照条件下,物体表面通常出现块状的强反射区域,传统的去高光方法在还原图像时容易造成颜色失真或者边缘的丢失。针对这些缺点,提出一种改进的基于双边滤波的去高光方法。方法首先通过双色反射模型变换得到镜面反射分量与最大漫反射色度之间的转换关系,然后利用阈值将图像的像素点分为两类,将仅含漫反射分量的像素点与含有镜面反射分量的像素点分离开来,对两类像素点的最大漫反射色度分别做估计,接着以估计的最大漫反射色度的相似度作为双边滤波器的值域,同时以图像的最大色度图作为双边滤波的引导图保边去噪,进而达到去除镜面反射分量的目的。结果以经典的高光图像作为处理对象,对含有镜面反射和仅含漫反射的像素点分别做最大漫反射色度估计,再以该估计图作为双边滤波的引导图,不仅能去除镜面反射分量还能有效的保留图像的边缘信息,最大程度的还原图像细节颜色,并且解决了原始算法处理结果中R、G、B三通道相似的像素点所出现的颜色退化问题。用改进的双边滤波去高光算法对50幅含高光的图像做处理,并将该算法与Yang方法和Shen方法分别作对比,结果图的峰值信噪比(PSNR)也分别平均提高4.17%和8.40%,所提算法的处理效果更符合人眼视觉,图像质量更好。结论实验结果表明针对含镜面反射的图像,本文方法能够更有效去除图像的多区域局部高光,完成对图像的复原,可为室内外光照不匀情况下所采集图像的复原提供有效理论基础。关键词:双色反射模型;镜面反射分量;漫反射色度估计;值域;双边滤波85|51|5更新时间:2024-05-07
摘要:目的由于非均匀光照条件下,物体表面通常出现块状的强反射区域,传统的去高光方法在还原图像时容易造成颜色失真或者边缘的丢失。针对这些缺点,提出一种改进的基于双边滤波的去高光方法。方法首先通过双色反射模型变换得到镜面反射分量与最大漫反射色度之间的转换关系,然后利用阈值将图像的像素点分为两类,将仅含漫反射分量的像素点与含有镜面反射分量的像素点分离开来,对两类像素点的最大漫反射色度分别做估计,接着以估计的最大漫反射色度的相似度作为双边滤波器的值域,同时以图像的最大色度图作为双边滤波的引导图保边去噪,进而达到去除镜面反射分量的目的。结果以经典的高光图像作为处理对象,对含有镜面反射和仅含漫反射的像素点分别做最大漫反射色度估计,再以该估计图作为双边滤波的引导图,不仅能去除镜面反射分量还能有效的保留图像的边缘信息,最大程度的还原图像细节颜色,并且解决了原始算法处理结果中R、G、B三通道相似的像素点所出现的颜色退化问题。用改进的双边滤波去高光算法对50幅含高光的图像做处理,并将该算法与Yang方法和Shen方法分别作对比,结果图的峰值信噪比(PSNR)也分别平均提高4.17%和8.40%,所提算法的处理效果更符合人眼视觉,图像质量更好。结论实验结果表明针对含镜面反射的图像,本文方法能够更有效去除图像的多区域局部高光,完成对图像的复原,可为室内外光照不匀情况下所采集图像的复原提供有效理论基础。关键词:双色反射模型;镜面反射分量;漫反射色度估计;值域;双边滤波85|51|5更新时间:2024-05-07 -
 摘要:目的多视点纹理加深度视频(MVD)格式逐渐成为立体视频的主流表现形式之一。新一代高效率立体视频编码(3D-HEVC)继承了HEVC的编码结构并引入一些新的编码技术,导致深度图帧内编码过程具有较高的计算复杂度。针对这一问题,提出了一种深度图帧内编码快速算法。方法本文算法利用深度图的特征分别对CU分割过程和粗略模式选择(RMD)过程进行优化。首先在四叉树编码结构上,利用基于纹理元的图像分析方法计算编码单元的梯度矩阵,若梯度矩阵中的梯度值之和小于给定的阈值,则终止该CU的分割进程。同时,对大尺寸的PU和小尺寸的PU分别利用纹理特征与粗略模式选择过程中Planar和DC进行低复杂度率失真计算后的最小率失真代价,跳过RMD中角度模式的检查过程。结果实验结果表明,与原始算法相比,本文算法平均节省40.64%的深度图编码时间,而合成视点的平均比特率仅仅增加了0.17%。本文算法不仅能对平坦的CU跳过不必要的深度决策过程,而且有效地减少了RMD中需要遍历的模式数目,提高了编码器的效率。结论该算法对CU分割进程和粗略模式选择过程都进行优化,在合成视点的视频质量几乎不变的前提下,有效降低了深度图的帧内编码复杂度。关键词:3维高效率立体视频编码(3D-HEVC);计算复杂度;深度图;帧内编码;编码单元;梯度矩阵15|4|1更新时间:2024-05-07
摘要:目的多视点纹理加深度视频(MVD)格式逐渐成为立体视频的主流表现形式之一。新一代高效率立体视频编码(3D-HEVC)继承了HEVC的编码结构并引入一些新的编码技术,导致深度图帧内编码过程具有较高的计算复杂度。针对这一问题,提出了一种深度图帧内编码快速算法。方法本文算法利用深度图的特征分别对CU分割过程和粗略模式选择(RMD)过程进行优化。首先在四叉树编码结构上,利用基于纹理元的图像分析方法计算编码单元的梯度矩阵,若梯度矩阵中的梯度值之和小于给定的阈值,则终止该CU的分割进程。同时,对大尺寸的PU和小尺寸的PU分别利用纹理特征与粗略模式选择过程中Planar和DC进行低复杂度率失真计算后的最小率失真代价,跳过RMD中角度模式的检查过程。结果实验结果表明,与原始算法相比,本文算法平均节省40.64%的深度图编码时间,而合成视点的平均比特率仅仅增加了0.17%。本文算法不仅能对平坦的CU跳过不必要的深度决策过程,而且有效地减少了RMD中需要遍历的模式数目,提高了编码器的效率。结论该算法对CU分割进程和粗略模式选择过程都进行优化,在合成视点的视频质量几乎不变的前提下,有效降低了深度图的帧内编码复杂度。关键词:3维高效率立体视频编码(3D-HEVC);计算复杂度;深度图;帧内编码;编码单元;梯度矩阵15|4|1更新时间:2024-05-07
图像处理和编码

-
 摘要:目的虹膜是位于人眼表面黑色瞳孔和白色巩膜之间的圆环形区域,有着丰富的纹理信息。虹膜纹理具有高度的区分性和稳定性。人种分类是解决虹膜识别在大规模数据库上应用难题的主要方法之一。现有的虹膜图像人种分类方法主要采用手工设计的特征,而且针对亚洲人和非亚洲人的基本人种分类,无法很好地解决亚种族分类问题。为此提出一种基于虹膜纹理深度特征和Fisher向量的人种分类方法。方法首先用CNN(convolutional neural network)对归一化后的虹膜纹理图像提取深度特征向量,作为底层特征;然后使用高斯混合模型提取Fisher向量作为最终的虹膜特征表达;最后用支持向量机分类得到最终结果。结果本文方法在亚洲人和非亚洲人的数据集上采用non-person-disjoint的方式取得99.93%的准确率,采用person-disjoint的方式取得91.94%的准确率;在汉族人和藏族人的数据集上采用non-person-disjoint的方式取得99.69%的准确率,采用person-disjoint的方式取得82.25%的准确率。结论本文通过数据驱动的方式从训练数据中学习到更适合人种分类的特征,可以很好地实现对基本人种以及亚种族人种的分类,提高了人种分类的精度。同时也首次证明了用虹膜图像进行亚种族分类的可行性,对人种分类理论进行了进一步地丰富和完善。关键词:人种分类;Fisher向量;高斯混合模型;特征表达;深度学习15|4|2更新时间:2024-05-07
摘要:目的虹膜是位于人眼表面黑色瞳孔和白色巩膜之间的圆环形区域,有着丰富的纹理信息。虹膜纹理具有高度的区分性和稳定性。人种分类是解决虹膜识别在大规模数据库上应用难题的主要方法之一。现有的虹膜图像人种分类方法主要采用手工设计的特征,而且针对亚洲人和非亚洲人的基本人种分类,无法很好地解决亚种族分类问题。为此提出一种基于虹膜纹理深度特征和Fisher向量的人种分类方法。方法首先用CNN(convolutional neural network)对归一化后的虹膜纹理图像提取深度特征向量,作为底层特征;然后使用高斯混合模型提取Fisher向量作为最终的虹膜特征表达;最后用支持向量机分类得到最终结果。结果本文方法在亚洲人和非亚洲人的数据集上采用non-person-disjoint的方式取得99.93%的准确率,采用person-disjoint的方式取得91.94%的准确率;在汉族人和藏族人的数据集上采用non-person-disjoint的方式取得99.69%的准确率,采用person-disjoint的方式取得82.25%的准确率。结论本文通过数据驱动的方式从训练数据中学习到更适合人种分类的特征,可以很好地实现对基本人种以及亚种族人种的分类,提高了人种分类的精度。同时也首次证明了用虹膜图像进行亚种族分类的可行性,对人种分类理论进行了进一步地丰富和完善。关键词:人种分类;Fisher向量;高斯混合模型;特征表达;深度学习15|4|2更新时间:2024-05-07
图像分析和识别
-
 摘要:目的形状的描述、匹配、相似性判定和检索是计算机视觉和图像识别的基本问题,也是一个开问题。在目前公开的方法中,除了只能应用于简单形状的几何复变换和基于边界的傅里叶描述子外,其他的方法均不能由构建的形状特征描述符重建原形状,因此不能保证所建立的形状特征能客观地描述原形状。本文提出了形状的圆内距离变换,该方法所建立的描述符可用于形状匹配、相似性度量和形状检索。该方法是可逆的,也就是可以从形状描述符重建原形状。方法形状的圆内距离变换通过在形状的最小外接圆内旋转和切分形状,求出形状相邻切分点之间的距离,并由此构建形状的特征矩阵。对于任意相似的形状,从理论上证明了形状的圆内距离变换具有缩放、旋转和位移不变性。结果对发生了形变、扭曲和仿射变换的形状,采用圆内距离变换方法进行了形状的相似性度量、检索和重建实验,结果表明,形状的圆内距离变换可以准确地描述形状、度量形状的相似性、检索形状并重建原形状。在形状的相似性度量上,形状的圆内距离变换能给出与人类视觉一致的结果,并且当两个形状相似时,还能计算出它们的尺度缩放和角度旋转。通过与经典的方法,包括形状上下文方法、傅里叶描述子方法、拉东柱状图方法,针对典型的MPEG-7形状库进行对比实验,发现形状的圆内距离变换在形状检索的综合得分上相比这些经典方法提高了近20%。结论形状的圆内距离变换在形状的描述、相似性判定和检索上是有效和可逆的,具有广泛的可适用性且优于本文比较的其他经典方法。关键词:形状;形状描述;相似性判定;形状匹配;形状检索11|4|2更新时间:2024-05-07
摘要:目的形状的描述、匹配、相似性判定和检索是计算机视觉和图像识别的基本问题,也是一个开问题。在目前公开的方法中,除了只能应用于简单形状的几何复变换和基于边界的傅里叶描述子外,其他的方法均不能由构建的形状特征描述符重建原形状,因此不能保证所建立的形状特征能客观地描述原形状。本文提出了形状的圆内距离变换,该方法所建立的描述符可用于形状匹配、相似性度量和形状检索。该方法是可逆的,也就是可以从形状描述符重建原形状。方法形状的圆内距离变换通过在形状的最小外接圆内旋转和切分形状,求出形状相邻切分点之间的距离,并由此构建形状的特征矩阵。对于任意相似的形状,从理论上证明了形状的圆内距离变换具有缩放、旋转和位移不变性。结果对发生了形变、扭曲和仿射变换的形状,采用圆内距离变换方法进行了形状的相似性度量、检索和重建实验,结果表明,形状的圆内距离变换可以准确地描述形状、度量形状的相似性、检索形状并重建原形状。在形状的相似性度量上,形状的圆内距离变换能给出与人类视觉一致的结果,并且当两个形状相似时,还能计算出它们的尺度缩放和角度旋转。通过与经典的方法,包括形状上下文方法、傅里叶描述子方法、拉东柱状图方法,针对典型的MPEG-7形状库进行对比实验,发现形状的圆内距离变换在形状检索的综合得分上相比这些经典方法提高了近20%。结论形状的圆内距离变换在形状的描述、相似性判定和检索上是有效和可逆的,具有广泛的可适用性且优于本文比较的其他经典方法。关键词:形状;形状描述;相似性判定;形状匹配;形状检索11|4|2更新时间:2024-05-07 -
 摘要:目的局部线性嵌入(LLE)算法是机器学习、数据挖掘等领域中的一种经典的流形学习算法。为克服LLE算法难以有效处理噪声、大曲率和稀疏采样数据等问题,提出一种改进重构权值的局部线性嵌入算法(IRWLLE)。方法采用测地线距离来描述结构,重新构造和定义LLE中的重构权值,即在某样本的邻域内,将测地距离与欧氏距离之比定义为结构权值;将测地距离与中值测地距离之比定义为距离权值,再将结构权值与距离权值的乘积作为重构权值,从而将流形的结构和距离两种信息进行有机的结合。结果对经典的人工数据Swiss roll、S-curve和Helix进行实验,在数据中加入噪声干扰,同时采用稀疏采样的方式来生成数据集,并与原始LLE算法和Hessian局部线性嵌入(HLLE)算法进行比较。实验结果表明,IRWLLE算法对比于LLE算法和HLLE算法,能够更好地保持流形的近邻关系,对流形的展开更加完好。尤其是对于加入噪声的大曲率数据集Helix,IRWLLE展现出极强的鲁棒性。对ORL和Yale人脸数据库进行人脸识别实验,采用最近邻分类器进行识别,将IRWLLE算法的识别结果与LLE算法进行对比。对于ORL数据集,IRWLLE算法识别率为90%,原LLE算法的识别率为85.5%;对于Yale数据集,IRWLLE算法识别率为88%,原LLE算法的识别率为75%,可见IRWLLE在人脸识别率上也有很大提高。结论本文提出的IRWLLE算法对比于原LLE算法,不仅将流形距离信息引入到重构权值中,而且还将结构信息加入其中,有效减少了噪声和流形外数据点的干扰,所以对于噪声数据具有更强的鲁棒性,能够更好地处理稀疏采样数据和大曲率数据,在人脸识别率上也有较大提升。关键词:流形学习;局部线性嵌入算法;重构权值;降维;鲁棒性11|4|2更新时间:2024-05-07
摘要:目的局部线性嵌入(LLE)算法是机器学习、数据挖掘等领域中的一种经典的流形学习算法。为克服LLE算法难以有效处理噪声、大曲率和稀疏采样数据等问题,提出一种改进重构权值的局部线性嵌入算法(IRWLLE)。方法采用测地线距离来描述结构,重新构造和定义LLE中的重构权值,即在某样本的邻域内,将测地距离与欧氏距离之比定义为结构权值;将测地距离与中值测地距离之比定义为距离权值,再将结构权值与距离权值的乘积作为重构权值,从而将流形的结构和距离两种信息进行有机的结合。结果对经典的人工数据Swiss roll、S-curve和Helix进行实验,在数据中加入噪声干扰,同时采用稀疏采样的方式来生成数据集,并与原始LLE算法和Hessian局部线性嵌入(HLLE)算法进行比较。实验结果表明,IRWLLE算法对比于LLE算法和HLLE算法,能够更好地保持流形的近邻关系,对流形的展开更加完好。尤其是对于加入噪声的大曲率数据集Helix,IRWLLE展现出极强的鲁棒性。对ORL和Yale人脸数据库进行人脸识别实验,采用最近邻分类器进行识别,将IRWLLE算法的识别结果与LLE算法进行对比。对于ORL数据集,IRWLLE算法识别率为90%,原LLE算法的识别率为85.5%;对于Yale数据集,IRWLLE算法识别率为88%,原LLE算法的识别率为75%,可见IRWLLE在人脸识别率上也有很大提高。结论本文提出的IRWLLE算法对比于原LLE算法,不仅将流形距离信息引入到重构权值中,而且还将结构信息加入其中,有效减少了噪声和流形外数据点的干扰,所以对于噪声数据具有更强的鲁棒性,能够更好地处理稀疏采样数据和大曲率数据,在人脸识别率上也有较大提升。关键词:流形学习;局部线性嵌入算法;重构权值;降维;鲁棒性11|4|2更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的高质量四边形网格生成是计算机辅助设计、等几何分析与图形学领域中一个富有挑战性的重要问题。针对这一问题,提出一种基于边界简化与多目标优化的高质量四边形网格生成新框架。方法首先针对亏格非零的平面区域,提出一种将多连通区域转化为单连通区域的方法,可生成高质量的插入边界;其次,提出"可简化角度"和"可简化面积比率"两个阈值概念,从顶点夹角和顶点三角形面积入手,将给定的多边形边界简化为粗糙多边形;然后对边界简化得到的粗糙多边形进行子域分解,并确定每个子域内的网格顶点连接信息;最后提出四边形网格的均匀性和正交性度量目标函数,并通过多目标非线性优化技术确定网格内部顶点的几何位置。结果在同样的离散边界下,本文方法与现有方法所生成的四边网格相比,所生成的四边网格顶点和单元总数目较少,网格单元质量基本类似,计算时间成本大致相同,但奇异点数目可减少70% 80%,衡量网格单元质量的比例雅克比值等相关指标均有所提高。结论本文所提出的四边形网格生成方法能够有效减少网格中的奇异点数目,并可生成具有良好光滑性、均匀性和正交性的高质量四边形网格,非常适用于工程分析和动画仿真。关键词:四边形网格生成;边界简化;子域分解;多目标优化;等几何分析11|5|1更新时间:2024-05-07
摘要:目的高质量四边形网格生成是计算机辅助设计、等几何分析与图形学领域中一个富有挑战性的重要问题。针对这一问题,提出一种基于边界简化与多目标优化的高质量四边形网格生成新框架。方法首先针对亏格非零的平面区域,提出一种将多连通区域转化为单连通区域的方法,可生成高质量的插入边界;其次,提出"可简化角度"和"可简化面积比率"两个阈值概念,从顶点夹角和顶点三角形面积入手,将给定的多边形边界简化为粗糙多边形;然后对边界简化得到的粗糙多边形进行子域分解,并确定每个子域内的网格顶点连接信息;最后提出四边形网格的均匀性和正交性度量目标函数,并通过多目标非线性优化技术确定网格内部顶点的几何位置。结果在同样的离散边界下,本文方法与现有方法所生成的四边网格相比,所生成的四边网格顶点和单元总数目较少,网格单元质量基本类似,计算时间成本大致相同,但奇异点数目可减少70% 80%,衡量网格单元质量的比例雅克比值等相关指标均有所提高。结论本文所提出的四边形网格生成方法能够有效减少网格中的奇异点数目,并可生成具有良好光滑性、均匀性和正交性的高质量四边形网格,非常适用于工程分析和动画仿真。关键词:四边形网格生成;边界简化;子域分解;多目标优化;等几何分析11|5|1更新时间:2024-05-07
计算机图形学
-
 摘要:目的海马体积很小,对比度极低,传统标记融合方法选用手工设计的特征模型,难以提取出适应性好、判别性强的特征。近年来,深度学习方法取得了极大成功,基于深度网络的方法已应用于医学图像分割中,但海马结构复杂,子区较多且体积差别较大,特别是CA2和CA3子区体积极小,常见的深度网络无法准确分割海马子区。为了解决这些问题,提出一种结合多尺度输入和串行处理神经网络的海马子区分割方法。方法针对海马中体积差距较大的子区,设计两种不同的网络,结合多种尺度图像块信息,为小子区建立类别数量均衡的训练集,避免网络被极端化训练,最后,采用串行标记的方式对海马子区进行分割。结果在Tail,SUB和PHG子区上的准确率达到了0.865,0.81,0.773,较现有的多图谱子区分割方法有较大提高,并且将体积较小子区CA2,CA3上的准确率分别提高了6%和9%。结论该算法将基于卷积神经网络的分类方法引入到标记融合阶段,根据海马子区特殊的灰度及结构特点,设计两种针对性网络,实验证明,该算法能提取出适应性好、判别性强的特征,提高了分割准确率。关键词:海马子区分割;多尺度;卷积神经网络;串行分割;多图谱11|4|3更新时间:2024-05-07
摘要:目的海马体积很小,对比度极低,传统标记融合方法选用手工设计的特征模型,难以提取出适应性好、判别性强的特征。近年来,深度学习方法取得了极大成功,基于深度网络的方法已应用于医学图像分割中,但海马结构复杂,子区较多且体积差别较大,特别是CA2和CA3子区体积极小,常见的深度网络无法准确分割海马子区。为了解决这些问题,提出一种结合多尺度输入和串行处理神经网络的海马子区分割方法。方法针对海马中体积差距较大的子区,设计两种不同的网络,结合多种尺度图像块信息,为小子区建立类别数量均衡的训练集,避免网络被极端化训练,最后,采用串行标记的方式对海马子区进行分割。结果在Tail,SUB和PHG子区上的准确率达到了0.865,0.81,0.773,较现有的多图谱子区分割方法有较大提高,并且将体积较小子区CA2,CA3上的准确率分别提高了6%和9%。结论该算法将基于卷积神经网络的分类方法引入到标记融合阶段,根据海马子区特殊的灰度及结构特点,设计两种针对性网络,实验证明,该算法能提取出适应性好、判别性强的特征,提高了分割准确率。关键词:海马子区分割;多尺度;卷积神经网络;串行分割;多图谱11|4|3更新时间:2024-05-07 -
 摘要:目的从3维牙颌模型上分割出单颗牙齿是计算机辅助正畸系统的重要步骤。由于3维测量分辨率和网格重建精度的有限性,三角网格牙颌模型上牙龈和牙缝边界往往融合在一起,使得单颗牙齿的自动分割变得极为困难。传统方法容易导致分割线断裂、分支干扰等问题,且手工交互较多,为此提出一种新颖的基于路径规划技术的单颗牙齿自动分割方法。方法为避免在探测边界时牙龈和牙缝相互干扰,采用牙龈路径和牙缝路径分开规划策略。首先基于离散曲率分析和一种双重路径规划法搜索牙龈分割路径,并基于搜索到的牙龈路径利用图像形态学和B样条拟合技术构建牙弓曲线;然后综合牙龈路径和牙弓曲线的形态特征探测牙龈路径上的牙缝凹点以划界每颗牙齿的牙龈边界轮廓,并通过匹配和搜索牙龈边界轮廓上颊舌侧凹点间的最优路径确定齿间牙缝边界路径;最后细化整个路径以获取每颗牙齿精确的封闭分割轮廓。结果对不同畸形程度的患者牙颌模型进行分割实验,结果表明,本文方法对于严重畸形的牙齿能够产生正确的分割结果,而且简单快速,整个分割过程基本能够控制在20 s以内。和现有方法相比,本文方法具有较少的人工干预和参数调整,除了在个别牙齿边界较为模糊的位置需要手动调整外,大部分情况都是自动的。结论提出的路径规划方法具有强大的抗干扰能力,能够有效克服牙缝牙沟等分支干扰以及分割线断裂等问题,最大程度地减少人工干预,适用于各类畸形牙患者模型的牙齿分割。关键词:牙齿分割;路径规划;离散曲率;B样条拟合;口腔正畸;3维牙颌模型14|4|4更新时间:2024-05-07
摘要:目的从3维牙颌模型上分割出单颗牙齿是计算机辅助正畸系统的重要步骤。由于3维测量分辨率和网格重建精度的有限性,三角网格牙颌模型上牙龈和牙缝边界往往融合在一起,使得单颗牙齿的自动分割变得极为困难。传统方法容易导致分割线断裂、分支干扰等问题,且手工交互较多,为此提出一种新颖的基于路径规划技术的单颗牙齿自动分割方法。方法为避免在探测边界时牙龈和牙缝相互干扰,采用牙龈路径和牙缝路径分开规划策略。首先基于离散曲率分析和一种双重路径规划法搜索牙龈分割路径,并基于搜索到的牙龈路径利用图像形态学和B样条拟合技术构建牙弓曲线;然后综合牙龈路径和牙弓曲线的形态特征探测牙龈路径上的牙缝凹点以划界每颗牙齿的牙龈边界轮廓,并通过匹配和搜索牙龈边界轮廓上颊舌侧凹点间的最优路径确定齿间牙缝边界路径;最后细化整个路径以获取每颗牙齿精确的封闭分割轮廓。结果对不同畸形程度的患者牙颌模型进行分割实验,结果表明,本文方法对于严重畸形的牙齿能够产生正确的分割结果,而且简单快速,整个分割过程基本能够控制在20 s以内。和现有方法相比,本文方法具有较少的人工干预和参数调整,除了在个别牙齿边界较为模糊的位置需要手动调整外,大部分情况都是自动的。结论提出的路径规划方法具有强大的抗干扰能力,能够有效克服牙缝牙沟等分支干扰以及分割线断裂等问题,最大程度地减少人工干预,适用于各类畸形牙患者模型的牙齿分割。关键词:牙齿分割;路径规划;离散曲率;B样条拟合;口腔正畸;3维牙颌模型14|4|4更新时间:2024-05-07
医学图像处理
-
 摘要:目的高光谱图像包含了丰富的空间、光谱和辐射信息,能够用于精细的地物分类,但是要达到较高的分类精度,需要解决高维数据与有限样本之间存在矛盾的问题,并且降低因噪声和混合像元引起的同物异谱的影响。为有效解决上述问题,提出结合超像元和子空间投影支持向量机的高光谱图像分类方法。方法首先采用简单线性迭代聚类算法将高光谱图像分割成许多无重叠的同质性区域,将每一个区域作为一个超像元,以超像元作为图像分类的最小单元,利用子空间投影算法对超像元构成的图像进行降维处理,在低维特征空间中执行支持向量机分类。本文高光谱图像空谱综合分类模型,对几何特征空间下的超像元分割与光谱特征空间下的子空间投影支持向量机(SVMsub),采用分割后进行特征融合的处理方式,将像元级别转换为面向对象的超像元级别,实现高光谱图像空谱综合分类。结果在AVIRIS(airbone visible/infrared imaging spectrometer)获取的Indian Pines数据和Reflective ROSIS(optics system spectrographic imaging system)传感器获取的University of Pavia数据实验中,子空间投影算法比对应的非子空间投影算法的分类精度高,特别是在样本数较少的情况下,分类效果提升明显;利用马尔可夫随机场或超像元融合空间信息的算法比对应的没有融合空间信息的算法的分类精度高;在两组数据均使用少于1%的训练样本情况下,同时融合了超像元和子空间投影的支持向量机算法在两组实验中分类精度均为最高,整体分类精度高出其他相关算法4%左右。结论利用超像元处理可以有效融合空间信息,降低同物异谱对分类结果的不利影响;采用子空间投影能够将高光谱数据变换到低维空间中,实现有限训练样本条件下的高精度分类;结合超像元和子空间投影支持向量机的算法能够得到较高的高光谱图像分类精度。关键词:高光谱图像;图像分类;子空间投影;超像元;支持向量机13|4|12更新时间:2024-05-07
摘要:目的高光谱图像包含了丰富的空间、光谱和辐射信息,能够用于精细的地物分类,但是要达到较高的分类精度,需要解决高维数据与有限样本之间存在矛盾的问题,并且降低因噪声和混合像元引起的同物异谱的影响。为有效解决上述问题,提出结合超像元和子空间投影支持向量机的高光谱图像分类方法。方法首先采用简单线性迭代聚类算法将高光谱图像分割成许多无重叠的同质性区域,将每一个区域作为一个超像元,以超像元作为图像分类的最小单元,利用子空间投影算法对超像元构成的图像进行降维处理,在低维特征空间中执行支持向量机分类。本文高光谱图像空谱综合分类模型,对几何特征空间下的超像元分割与光谱特征空间下的子空间投影支持向量机(SVMsub),采用分割后进行特征融合的处理方式,将像元级别转换为面向对象的超像元级别,实现高光谱图像空谱综合分类。结果在AVIRIS(airbone visible/infrared imaging spectrometer)获取的Indian Pines数据和Reflective ROSIS(optics system spectrographic imaging system)传感器获取的University of Pavia数据实验中,子空间投影算法比对应的非子空间投影算法的分类精度高,特别是在样本数较少的情况下,分类效果提升明显;利用马尔可夫随机场或超像元融合空间信息的算法比对应的没有融合空间信息的算法的分类精度高;在两组数据均使用少于1%的训练样本情况下,同时融合了超像元和子空间投影的支持向量机算法在两组实验中分类精度均为最高,整体分类精度高出其他相关算法4%左右。结论利用超像元处理可以有效融合空间信息,降低同物异谱对分类结果的不利影响;采用子空间投影能够将高光谱数据变换到低维空间中,实现有限训练样本条件下的高精度分类;结合超像元和子空间投影支持向量机的算法能够得到较高的高光谱图像分类精度。关键词:高光谱图像;图像分类;子空间投影;超像元;支持向量机13|4|12更新时间:2024-05-07
遥感图像处理
-
 摘要:目的基于普通个人计算机快速渲染大规模计算机辅助设计(CAD)模型仍然是个挑战。针对由少量基本对象按一定规律排布而成的大规模CAD模型——重复结构CAD模型,提出一种快速渲染方法,能够在个人计算机上的快速渲染大规模重复结构CAD模型。方法该方法首先利用重复结构CAD模型的层次结构特征,结合现代GPU的Render-To-Texture的功能进行快速视锥裁剪,节约视锥裁剪时间;然后利用重复结构CAD模型中对象按规律布置的特点,仅对少量基本对象进行面片化,其他对象的面片模型在渲染时根据对象排布规律由基本对象的面片模型实时变换生成,解决大规模CAD模型内存需求过多的问题。结果基于超级蒙卡核模拟软件系统SuperMC,使用典型重复结构模型——HM(hoogenboom-martin)、ADS(accelerator driven sub-critical system)、DCA(deuterium critical assembly)全堆芯CAD模型进行测试,HM、ADS、DCA模型分别由1 114 384,113 952和20 808个实体组成。测试结果表明,裁剪算法能大幅减少待渲染对象数量,渲染速度明显提高,且模型规模越大,本文方法优势越明显,在远视角的情况下提升效果最为突出,能提升3倍左右;结论针对任意大规模CAD模型的快速渲染仍然是一个挑战,但本文针对重复结构CAD模型的特点,针对性地提出一套专用渲染策略,在个人计算机上实现大规模重复结构CAD模型的快速渲染。使用多个典型重复结构模型——反应堆全堆芯模型进行测试,测试结果表明了本文方法的有效性。关键词:大规模CAD模型快速渲染;重复结构;视锥裁剪;渲染到纹理15|6|1更新时间:2024-05-07
摘要:目的基于普通个人计算机快速渲染大规模计算机辅助设计(CAD)模型仍然是个挑战。针对由少量基本对象按一定规律排布而成的大规模CAD模型——重复结构CAD模型,提出一种快速渲染方法,能够在个人计算机上的快速渲染大规模重复结构CAD模型。方法该方法首先利用重复结构CAD模型的层次结构特征,结合现代GPU的Render-To-Texture的功能进行快速视锥裁剪,节约视锥裁剪时间;然后利用重复结构CAD模型中对象按规律布置的特点,仅对少量基本对象进行面片化,其他对象的面片模型在渲染时根据对象排布规律由基本对象的面片模型实时变换生成,解决大规模CAD模型内存需求过多的问题。结果基于超级蒙卡核模拟软件系统SuperMC,使用典型重复结构模型——HM(hoogenboom-martin)、ADS(accelerator driven sub-critical system)、DCA(deuterium critical assembly)全堆芯CAD模型进行测试,HM、ADS、DCA模型分别由1 114 384,113 952和20 808个实体组成。测试结果表明,裁剪算法能大幅减少待渲染对象数量,渲染速度明显提高,且模型规模越大,本文方法优势越明显,在远视角的情况下提升效果最为突出,能提升3倍左右;结论针对任意大规模CAD模型的快速渲染仍然是一个挑战,但本文针对重复结构CAD模型的特点,针对性地提出一套专用渲染策略,在个人计算机上实现大规模重复结构CAD模型的快速渲染。使用多个典型重复结构模型——反应堆全堆芯模型进行测试,测试结果表明了本文方法的有效性。关键词:大规模CAD模型快速渲染;重复结构;视锥裁剪;渲染到纹理15|6|1更新时间:2024-05-07 -
 摘要:目的针对基于学习的图像超分辨率重建算法中存在边缘信息丢失、易产生视觉伪影等问题,提出一种基于边缘增强的深层网络模型用于图像的超分辨率重建。方法本文算法首先利用预处理网络提取输入低分辨率图像的低级特征,然后将其分别输入到两路网络,其中一路网络通过卷积层级联的卷积网络得到高级特征,另一路网络通过卷积网络和与卷积网络成镜像结构的反卷积网络的级联实现图像边缘的重建。最后,利用支路连接将两路网络的结果进行融合,并将其结果通过一个卷积层从而得到最终重建的具有边缘增强效果的高分辨率图像。结果以峰值信噪比(PSNR)和结构相似度(SSIM)作为评价指标来评价算法性能,在Set5、Set14和B100等常用测试集上放大3倍情况下进行实验,并且PSNR/SSIM指标分别取得了33.24 dB/0.9156、30.60 dB/0.852 1和28.45 dB/0.787 3的结果,相比其他方法有很大提升。结论定量与定性的实验结果表明,基于边缘增强的深层网络的图像超分辨重建算法所重建的高分辨率图像不仅在重建图像边缘信息方面有较好的改善,同时也在客观评价和主观视觉上都有很大提高。关键词:超分辨率重建;卷积神经网络;反卷积;去池化;边缘增强11|4|3更新时间:2024-05-07
摘要:目的针对基于学习的图像超分辨率重建算法中存在边缘信息丢失、易产生视觉伪影等问题,提出一种基于边缘增强的深层网络模型用于图像的超分辨率重建。方法本文算法首先利用预处理网络提取输入低分辨率图像的低级特征,然后将其分别输入到两路网络,其中一路网络通过卷积层级联的卷积网络得到高级特征,另一路网络通过卷积网络和与卷积网络成镜像结构的反卷积网络的级联实现图像边缘的重建。最后,利用支路连接将两路网络的结果进行融合,并将其结果通过一个卷积层从而得到最终重建的具有边缘增强效果的高分辨率图像。结果以峰值信噪比(PSNR)和结构相似度(SSIM)作为评价指标来评价算法性能,在Set5、Set14和B100等常用测试集上放大3倍情况下进行实验,并且PSNR/SSIM指标分别取得了33.24 dB/0.9156、30.60 dB/0.852 1和28.45 dB/0.787 3的结果,相比其他方法有很大提升。结论定量与定性的实验结果表明,基于边缘增强的深层网络的图像超分辨重建算法所重建的高分辨率图像不仅在重建图像边缘信息方面有较好的改善,同时也在客观评价和主观视觉上都有很大提高。关键词:超分辨率重建;卷积神经网络;反卷积;去池化;边缘增强11|4|3更新时间:2024-05-07 -
 摘要:目的现有栅格地图安全保护技术主要有:基于混沌理论的图像加密技术、数字图像置乱技术和图像信息隐藏技术,这些技术不适用于丢失容忍、解密简单、共享份图像顺序可交换、权限控制等应用场合。图像分存技术可应用于上述场合,其中基于视觉密码的图像分存技术秘密图像恢复时运算简单,仅利用人眼视觉系统或借助简单计算设备,便可以获得恢复图像的信息。但运用于彩色栅格地图分存的彩色视觉密码方案,存在像素扩展度较大、秘密图像颜色受限等问题。为解决该问题,基于异或运算给出了概率型彩色视觉密码方案定义,并构造了一种概率型(
摘要:目的现有栅格地图安全保护技术主要有:基于混沌理论的图像加密技术、数字图像置乱技术和图像信息隐藏技术,这些技术不适用于丢失容忍、解密简单、共享份图像顺序可交换、权限控制等应用场合。图像分存技术可应用于上述场合,其中基于视觉密码的图像分存技术秘密图像恢复时运算简单,仅利用人眼视觉系统或借助简单计算设备,便可以获得恢复图像的信息。但运用于彩色栅格地图分存的彩色视觉密码方案,存在像素扩展度较大、秘密图像颜色受限等问题。为解决该问题,基于异或运算给出了概率型彩色视觉密码方案定义,并构造了一种概率型($k,n$ $k,n$ $k,n$ $k,n$ $k,k$ $n$ $k,n$ 关键词:栅格地图分存;彩色视觉密码;概率型;异或运算;无像素扩展12|4|1更新时间:2024-05-07 -
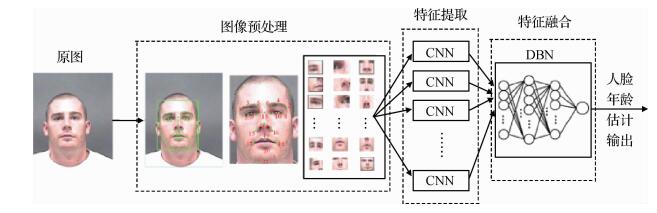 摘要:目的为了提高人脸图像年龄估计的精度,提出一种端对端可训练的深度神经网络模型来进行人脸年龄估计。方法该网络模型由多个卷积神经网络(CNN)和一个深度置信网络(DBN)堆叠而成,称为深度融合网络(DFN)。首先使用多个并联的CNN提取人脸图像多个区域的外观特征,将得到的特征进行串接输入一个DBN网络进行非线性融合。为了实现DFN的端到端的整体训练,提出一种逐网络迭代训练(INWT)的机制。为了降低过拟合效应,那些对应人脸局部图像的CNN经过多次迭代迁移学习实现面向人脸年龄估计任务的训练。完成对DFN中所有CNN和DBN的预训练后,再进行全网络端到端的整体精调。结果在两个人脸年龄图像库MORPH Ⅱ和FG-NET上对本文方法进行测试,实验结果显示基于DFN的人脸年龄估计方法能在两个人脸图像库中分别取得平均绝对误差(MAE)等于3.42和4.14的估计精度,与目前主流的年龄估计算法,如基于浅层学习的CA-SVR方法(两个数据库上取得的MAE分别等于5.88和4.75),基于深度学习的DeepRank+方法(MORPH Ⅱ数据库上取得的MAE为3.49)和Deep-CS-LBMFL方法(FG-NET数据库上取得的MAE为4.22)等相比,估计精确度明显提高。结论本文提出基于深度融合网络的人脸年龄估计方法与当前大部分基于深度神经网络的主流算法相比具有明显的优势。关键词:人脸年龄估计;深度融合网络;逐网络迭代训练;迁移学习13|4|2更新时间:2024-05-07
摘要:目的为了提高人脸图像年龄估计的精度,提出一种端对端可训练的深度神经网络模型来进行人脸年龄估计。方法该网络模型由多个卷积神经网络(CNN)和一个深度置信网络(DBN)堆叠而成,称为深度融合网络(DFN)。首先使用多个并联的CNN提取人脸图像多个区域的外观特征,将得到的特征进行串接输入一个DBN网络进行非线性融合。为了实现DFN的端到端的整体训练,提出一种逐网络迭代训练(INWT)的机制。为了降低过拟合效应,那些对应人脸局部图像的CNN经过多次迭代迁移学习实现面向人脸年龄估计任务的训练。完成对DFN中所有CNN和DBN的预训练后,再进行全网络端到端的整体精调。结果在两个人脸年龄图像库MORPH Ⅱ和FG-NET上对本文方法进行测试,实验结果显示基于DFN的人脸年龄估计方法能在两个人脸图像库中分别取得平均绝对误差(MAE)等于3.42和4.14的估计精度,与目前主流的年龄估计算法,如基于浅层学习的CA-SVR方法(两个数据库上取得的MAE分别等于5.88和4.75),基于深度学习的DeepRank+方法(MORPH Ⅱ数据库上取得的MAE为3.49)和Deep-CS-LBMFL方法(FG-NET数据库上取得的MAE为4.22)等相比,估计精确度明显提高。结论本文提出基于深度融合网络的人脸年龄估计方法与当前大部分基于深度神经网络的主流算法相比具有明显的优势。关键词:人脸年龄估计;深度融合网络;逐网络迭代训练;迁移学习13|4|2更新时间:2024-05-07 -
 摘要:目的呼吸率是呼吸疾病检测的敏感指标,基于视频的呼吸率检测方法因成本低、使用限制少等特点成为近年医疗健康领域的研究热点。针对现有方法在噪声抑制及夜间信号获取方面存在的问题,提出一种适用于昼夜环境且抗噪性能高的呼吸率视频检测方法。方法该方法只需使用夜视功能的摄像头即可实现昼夜呼吸率检测。首先,采用人脸检测确定人脸区域,并结合人体几何关系规范呼吸区域;然后,结合空间尺度及相位差异,采用基于相位的视频处理方法对呼吸区域进行时空相位处理,在突出呼吸区域的同时有效抑制了噪声干扰。采用最大似然法进行呼吸初估计,并结合初估计频率对原信号平滑滤波以优化波形;最后应用峰值检测完成呼吸率的二次估计。结果通过室内有无光源两种环境的实验可知,稳定光源下呼吸率平均误差为0.54次/min,无光源下平均误差为0.62次/min。本文方法与真实呼吸率有良好一致性,与传统呼吸率检测方法相比,鲁棒性更好。结论提出一种适用于昼夜环境的呼吸率视频检测方法。采用红外摄像机实现夜间视频采集,并通过胸部定位、基于相位的视频放大技术进行时空相位处理,在拓展空间分辨率的同时有效抑制噪声放大,提高呼吸检测的精度与鲁棒性。关键词:呼吸信号提取;胸部定位;视频运动放大;最大似然估计;呼吸率估计11|4|2更新时间:2024-05-07
摘要:目的呼吸率是呼吸疾病检测的敏感指标,基于视频的呼吸率检测方法因成本低、使用限制少等特点成为近年医疗健康领域的研究热点。针对现有方法在噪声抑制及夜间信号获取方面存在的问题,提出一种适用于昼夜环境且抗噪性能高的呼吸率视频检测方法。方法该方法只需使用夜视功能的摄像头即可实现昼夜呼吸率检测。首先,采用人脸检测确定人脸区域,并结合人体几何关系规范呼吸区域;然后,结合空间尺度及相位差异,采用基于相位的视频处理方法对呼吸区域进行时空相位处理,在突出呼吸区域的同时有效抑制了噪声干扰。采用最大似然法进行呼吸初估计,并结合初估计频率对原信号平滑滤波以优化波形;最后应用峰值检测完成呼吸率的二次估计。结果通过室内有无光源两种环境的实验可知,稳定光源下呼吸率平均误差为0.54次/min,无光源下平均误差为0.62次/min。本文方法与真实呼吸率有良好一致性,与传统呼吸率检测方法相比,鲁棒性更好。结论提出一种适用于昼夜环境的呼吸率视频检测方法。采用红外摄像机实现夜间视频采集,并通过胸部定位、基于相位的视频放大技术进行时空相位处理,在拓展空间分辨率的同时有效抑制噪声放大,提高呼吸检测的精度与鲁棒性。关键词:呼吸信号提取;胸部定位;视频运动放大;最大似然估计;呼吸率估计11|4|2更新时间:2024-05-07
CACIS2017学术会议专栏
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0