|
|
|
发布时间: 2022-09-16 |
多媒体分析与理解 |
|
|
|


|
收稿日期: 2021-12-30; 修回日期: 2022-06-13; 预印本日期: 2022-06-20
基金项目: 国家自然科学基金项目(62176195, 62036007, 61922066, 61876142)
作者简介:
辛经纬,1994年生,男,讲师,主要研究方向为机器学习和计算机视觉。E-mail: jwxin@xidian.edu.cn
魏子凯,男,硕士研究生,主要研究方向为底层视觉处理。E-mail:zkwei@stu.xidian.edu.cn 王楠楠,通信作者,男,教授,主要研究方向为计算机视觉、机器学习和模式识别。E-mail:nnwang@xidian.edu.cn 李洁,女,教授,主要研究方向为图像处理、模式识别和机器学习。E-mail:leejie@mail.xidian.edu.cn 高新波,男,教授,主要研究方向为多媒体分析、计算机视觉、模式识别、机器学习和无线通信。E-mail:gaoxb@cqupt.edu.cn *通信作者: 王楠楠 nnwang@xidian.edu.cn
中图法分类号: TP391
文献标识码: A
文章编号: 1006-8961(2022)09-2788-13
|
摘要
目的 人脸正面化重建是当前视觉领域的热点问题。现有方法对于模型的训练数据具有较高的需求,如精确的输入输出图像配准、完备的人脸先验信息等。但该类数据采集成本较高,可应用的数据集规模较小,直接将现有方法应用于真实的非受控场景中往往难以取得理想表现。针对上述问题,提出了一种无图像配准和先验信息依赖的任意视角人脸图像正面化重建方法。方法 首先提出了一种具有双输入路径的人脸编码网络,分别用于学习输入人脸的视觉表征信息以及人脸的语义表征信息,两者联合构造出更加完备的人脸表征模型。随后建立了一种多类别表征融合的解码网络,通过以视觉表征为基础、以语义表征为引导的方式对两种表征信息进行融合,融合后的信息经过图像解码即可得到最终的正面化人脸图像重建结果。结果 首先在Multi-PIE(multi-pose, illumination and expression)数据集上与8种较先进方法进行了性能评估。定量和定性的实验结果表明,所提方法在客观指标以及视觉质量方面均优于对比方法。此外,相较于当前性能先进的基于光流的特征翘曲模型(flow-based feature warping model,FFWM)方法,本文方法能够节省79%的参数量和42%的计算操作数。进一步基于CASIA-WebFace(Institute of Automation, Chinese Academy of Sciences—WebFace)数据集对所提出方法在真实非受控场景中的表现进行了评估,识别精度超过现有方法10%以上。结论 本文提出的双层级表征集成推理网络,能够挖掘并联合人脸图像的底层视觉特征以及高层语义特征,充分利用图像自身信息,不仅以更低的计算复杂度取得了更优的视觉质量和身份识别精度,而且在非受控的场景下同样展现出了出色的泛化性能。
关键词
人脸正面化重建; 任意姿态; 双编码路径; 视觉表征; 语义表征; 融合算法
Abstract
Objective The issue of uncontrolled-scenes-oriented human face recognition is challenged of series of uncontrollable factors like image perspective changes and face pose variations. Facial images reconstruction enables the interface between uncontrolled scenarios and matured recognition techniques. It aims to synthesize a standardized facial image derived from an arbitrary light and pose face image. The reconstructed facial image can be as a commonly used human face recognition method with no additional introduced inference. Beyond a pre-processing model of facial imaging contexts (e.g., recognition, semantic parsing, and animation generation, etc.), it has potentials in virtual and augmented reality like facial clipping, decoration and reconstruction. It is challenging to pursue 3D-rotation-derived predictable objects and the same of preserved identity for multi-view generations. Many classical tackling approaches have been proposed, which can be categorized into model-driven-based approaches, data-driven-based approaches, and a combination of both. Recent generative adversarial networks (GANs) have shown good results in multi-view generation. However, some high requirements of these methods have to be resolved in the training dataset, such as accurate input and output of image alignment and rich facial prior. We facilitate a novel facial reconstruction method beyond its image alignment and prior information. Method Our two-level representation integration inference network is composed of three aspects on a high-level facial semantic information encoder, a low-level facial visual information encoder, and an integrated multi-information decoder. The encoding process is concerned of the learning issue of richer identity representation information in terms of an arbitrary-posed facial image. The convolution weights of the pre-trained face recognition model is melted into our semantic encoder. The face recognition model is trained on a large-scale dataset, which enables the encoder to adapt complex face variations through facial prior knowledge. Benefiting from the face recognition model's ability for identity information, our semantic analysis could obtain accurate semantic representation information. We illustrate a visual encoder to complement the texture features in the network in terms of reconstructed facial texture information. Additionally, the receptive field of convolution neural networks has a significant impact on the nonlinear mapping capability. To obtain accurate prediction results and optimize the extraction of texture information further, a larger receptive field could meet the requirement for mapping process of multi-sources networks. The downsampling and dilated convolutions are integrated for feature extraction, i.e., each downsampling module in the network consists of a downsampling convolution and a dilated convolution. The dilated convolution can effectively increase the corresponding mapping range of each reconstructed pixel in the context of network layers and improve the receptive field of each layer of the network. The image reconstruction task is very sensitive to the low-level visual information of the image. If the coding-derived visual representation is combined with the semantic representation directly, the image reconstruction process of the model will be restricted of the visual representation and ignore the guiding function of the semantic representation. Therefore, the key to our multiple information integration process is first focused on the mapping relationship of the probability distribution of facial images in the feature space, and the following representation information of facial reconstruction is realized. To obtain the final analysis of facial reconstruction, the representation information is decoded at the end of the network. Result Our method is compared to 8 state-of-the-art facial methods on Multi-PIE(multi-pose, illumination and expression) dataset. The quantitative evaluation metric is Rank-1 recognition rates and the qualitative analysis is based on the visual effect of reconstructed images. The experiment results show that our model could get more optimized results. In addition, our method can save 79% of the number of parameters and 42% of the number of computational operations compared to the current state-of-the-art flow-based feature warping model(FFWM) method. To fully validate the effectiveness of the proposed method, we analyze the effects of dual coding paths, multiple information integration and the different loss functions on the model performance. To match the real uncontrolled scenarios, we evaluate the proposed method on the CASIA-WebFace(Institute of Automation, Chinese Academy of Sciences—WebFace) dataset. At the same time, we carry out quantitative and qualitative method compared to existing methods. Conclusion We develop a two-level representational integrated inference network, which integrate the low-level visual facial features and the high-level semantic features. It optimizes reconstructed results and higher recognition accuracy with lower computational complexity and shows its priority of generalization performance in uncontrolled scenes as well.
Key words
face frontalization; arbitrary pose; dual encoding path; visual representation; semantic representation; fusion algorithm
0 引言
在非受控场景下的人脸识别任务中,如何克服图像采集视角以及人脸姿态变化是一个关键问题。人脸正面化重建为解决这一问题提供了一种有效的方法,进而实现非受控场景与现有成熟识别技术的衔接。人脸正面化重建旨在从一张任意光照、任意姿态的人脸图像准确地合成出正常光照和姿态的正脸图像。重建的人脸图像可以直接用于一般的人脸识别处理,而不需要引入额外的推理操作。除了可以作为其他高层视觉任务(如人脸识别、人脸语义解析和人脸动画生成等)的前置任务(王欢等,2020;祝恺蔓等,2022;曹申豪等,2022),人脸重建技术也是一个独立的研究问题,存在如人脸编辑、配饰和重构等虚拟现实与增强现实中的潜在应用。
人脸正面化重建是一个具有挑战性的课题,因为计算机不仅需要推理出给定的人脸经过正面化旋转后的视图,同时还应该保持相同的身份。一般而言,解决该问题的经典方法主要包括基于模型驱动的方法(Blanz和Vetter,1999)、基于数据驱动的方法(Zhu等,2014;Yan等,2017),以及两者结合的方法(Zhu等,2016;Rezende等,2016)。近年来,Goodfellow等人(2014)提出的生成式对抗网络(generative adversarial network,GAN)在多人脸视图生成方面展现出了令人印象深刻的结果(Tran等,2017;Zhao等,2018a)。这些基于GAN的方法通常有一个标准的设计路径:一个编码器—解码器网络,之后是一个鉴别器网络。编码器(
人脸的先验信息对于人脸图像的重建过程具有积极的指导意义,并已在人脸正面化重建领域取得广泛应用。Hu等人(2018)提出了一种基于姿态引导的任意视角人脸重建算法(couple-agent pose-guided generative adversarial network,CAPG-GAN),该方法通过引入人脸地标性热图的先验信息来引导图像重建。Zhao等人(2018b)提出了一种基于3D辅助的人脸姿态不变模型(3D-aided deep pose-invariant model,3D-PIM),该模型通过人脸地标和3D先验引导模型从任意姿势中恢复真实的正面人脸视图。Wei等人(2020)提出了一种基于光流的特征翘曲模型(flow-based feature warping model,FFWM), 用于多视角人脸正面化重建,该模型能够有效利用人脸光流先验信息,从而在不一致光照下合成逼真且保持光照一致的正面人脸图像。虽然现有的方法在人脸正面化重建任务中已经展现出了令人满意的表现,但它们通常需要使用显式的先验知识作为约束或使用额外的计算处理操作。而在非受控环境下,显式的人脸先验信息获取成本较高,不足以支持现有模型的训练需求,而且额外的计算处理操作会消耗大量的计算资源,进一步限制了人脸正面化在现实中的应用。因此,本文专注于提供一种无先验依赖和低计算成本的方法来执行人脸正面化重建任务。
为了实现无人脸先验信息引入情况下高质量的人脸正面化图像重建,本文构造了一种双层级表征集成推理网络。该网络以人脸的身份特征和视觉特征为基础,无需引入额外的先验知识即可恢复正面化人脸图像。网络由两个编码器和一个解码器构成。在编码阶段,考虑到人脸的辨识度信息在图像质量感知及评估中的重要性,引入了预训练的人脸识别模型参与人脸特征的编码过程。该识别模型是在大规模数据集上预先训练的,对于人脸姿态及表情变化具有较强的鲁棒性。与之并列的另一个编码器则用于捕获人脸图像的色彩、纹理等底层视觉信息。该信息将用于图像重建的色彩、细节的渲染过程。在图像解码重建阶段中,该网络以像素级表征为基础、以语义级表征为引导的对两种表征信息进行融合,随后进行图像解码并得到最终的正面化人脸图像。图 1展示了本文方法的一些人脸正面化重建结果。


本文的主要贡献总结如下:
1) 构造了一种双层级表征集成推理网络。网络的编码过程同时结合了底层的基础视觉信息以及高层的语义表征信息,并充分挖掘利用了图像的自身信息。相较于现有方法,该网络能够在无额外先验信息引入的情况下取得较理想的图像重建表现。
2) 提出了一个多类别特征融合解码网络。该网络能够充分结合两种类别信息之间的对立性和互补性并用于图像的重建。得益于该融合模型机制及结构的合理性,与现有方法相比,本文方法能够以更低的计算复杂度取得更优的性能。
3) 大量实验验证了本文方法的有效性,并分析了不同的表征建模方式对于重建图像的影响。在最终的模型性能评估中,除了标准的Multi-PIE(multi-pose, illumination and expression)数据集之外,本文展开了在真实非受控场景中的实验评估。实验表明,本文方法无论在标准的评估数据集中还是真实非受控的场景中,均能取得当前最优的表现。特别地,与当前先进的方法FFWM(Wei等,2020)相比,本文方法节省了79%的参数数量和42%的运算操作数。
1 相关工作
人脸正面化重建是指从给定的非正面人脸图像中合成出其对应的正面的人脸视图。由于重建过程中的不确定性,该任务是一项非常具有挑战性的问题。传统的方法中,解决该问题的方式通常是通过对输入人脸图像的2维或3维的局部纹理进行翘曲(张剑等,2014;Hassner等,2015;Zhu等,2015)或统计建模(Sagonas等,2015)。Hassner等人(2015)构建了一种人脸的3维表征模型用于重建正面化的人脸图像。Zhu等人(2015)基于人脸3D形变统计模型(3D morphable model,3DMM)(Blanz和Vetter,1999)提供了一种具有高细节保真度的人脸姿态和表情的正则化方法。Sagonas等人(2015)构建了一个统计学模型,用于联合完成人脸正面化重建以及地标定位任务。这些方法在理想的受控场景中能够取得优秀的表现,但是对于面部非刚性变化的鲁棒性较低。在非受控的场景中,多样化人脸姿态会导致重建人脸图像的纹理细节严重丢失,模型性能急剧下降。
随着深度技术的发展和普及,Kan等人(2014)提出了一种叠加渐进式的自编码器,该模型通过特征编解码的方式,从网络提取的深度特征中进行人脸正面化重建。Yang等人(2015)采用了一个递归卷积编码器—解码器网络来合成离散的人脸3维视图。Yim等人(2015)引入了一个多任务学习模型来合成人脸正面化视图。此外,Cole等人(2017)首先通过人脸识别网络提取的特征中生成面部地标和纹理,随后将它们引入图像重构网络,合成具有中性表情的正面化人脸图像。
受益于GAN在图像重建任务中的优异表现,基于GAN的人脸正面化重建方法同样取得了显著的成就(Huang等,2017;Hu等,2018;Cao等,2018;Wei等,2020)。Yin等人(2017)将人脸的3维表征模型纳入了GAN框架中,为图像的重建过程提供形状和外观等先验信息。Huang等人(2017)同时结合面部的局部和全局信息用于正面化人脸图像的重建过程。Hu等人(2018)提出了基于姿态引导的任意视角人脸重建算法,该方法引入了人脸地标性热图来辅助多视角人脸正面化重建。Zhao等人(2018c)结合区域自适应策略,构建了一种姿态不变表征模型。Cao等人(2018)使用一种新的纹理翘曲方案实现了高质量的人脸正面化重建。Wei等人(2020)提出了一个新的基于光流的特征翘曲模型,可以在光照不一致的条件下合成出照片般逼真的正面人脸图像。Tu等人(2022)提出了一种人脸姿态归一化模块,通过感知输入人脸与参考人脸姿态间的差异引导人脸正面化重建。
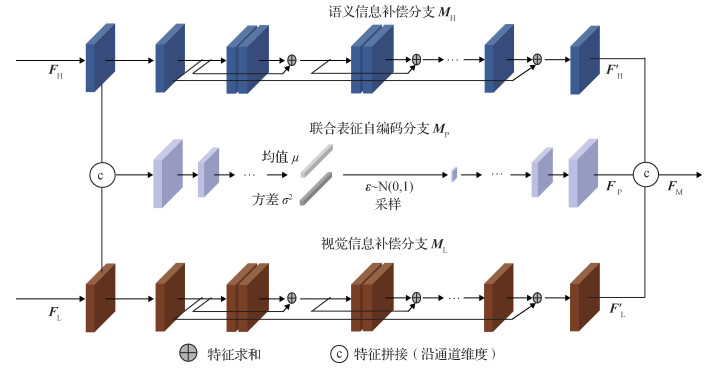
2 双层级表征集成推理网络
本文提出的基于双层级表征集成的人脸图像正面化重建框架如图 2所示,该架构实现了联合底层视觉特征与高层语义特征的正面化人脸视图求解。

2.1 模型基础框架
从图 2可以看出,双层级表征集成推理网络模型由3部分组成:面向底层特征的人脸视觉信息编码器、面向高层特征的人脸语义信息编码器以及多类别信息融合解码器。为了便于表达,设
| $ \boldsymbol{F}_{\mathrm{H}}=E_{\mathrm{H}}(\boldsymbol{x}), \boldsymbol{F}_{\mathrm{L}}=E_{\mathrm{L}}(\boldsymbol{x}) $ | (1) |
式中,
| $ \boldsymbol{F}_{\mathrm{M}}=M\left(\boldsymbol{F}_{\mathrm{H}}, \boldsymbol{F}_{\mathrm{L}}\right) $ | (2) |
式中,
| $ \hat{\boldsymbol{y}}=G\left(\boldsymbol{F}_{\mathrm{M}}\right) $ | (3) |
式中,
2.2 双路径的编码过程
双路径的编码过程包括高层的语义信息编码和底层视觉信息编码。首先,为了从具有任意姿态的人脸图像中学习到更加丰富的身份表征信息,将经过预训练的人脸识别模型的部分卷积权重共享到了语义信息编码器路径中。该人脸识别模型在大规模数据集上进行训练,能够适应复杂的人脸变化,通过隐含的人脸先验知识,为人脸的编码过程提供了对复杂人脸变化的适应能力。语义信息编码器借助人脸识别模型对于身份信息出色的建模能力获取到准确的语义表征信息。
假设预训练的人脸识别模型为
| $ E_{\mathrm{H}} \leftarrow R^{\mathrm{P}} $ | (4) |
式中,
面向重建人脸图像的纹理信息,本文提出了视觉编码器来补充网络中的纹理特征。一般而言,感受野的大小决定着网络映射过程的信息来源范围,更广泛的信息来源会促使映射过程更易于取得精准的预测结果。考虑到感受野对非线性映射能力的影响,该编码器采用了降采样卷积与空洞卷积相结合的特征提取过程,即网络中每个降采样的模块均由一个降采样卷积和一个空洞卷积组成,即
| $ f_{n+1}=D^r\left(f_n\right)=C_D^r\left(D\left(f_n\right)\right) $ | (5) |
式中,
| $ \boldsymbol{F}_{\mathrm{L}}=E_{\mathrm{L}}(\boldsymbol{x})=D_N^r\left(\cdots D_2^r\left(D_1^r\left(C_{\mathrm{in}}(\boldsymbol{x})\right)\right)\right) $ | (6) |
式中,
2.3 多类别信息融合解码过程
图像解码重建是图像重建任务的核心过程,本文方法的解码过程是从经过编码得到的高层的语义信息和底层视觉信息中进行图像的重建。因此如何对两者不同类别信息进行融合是该过程的重点。考虑到图像重建任务对于图像的底层视觉信息敏感的特点,若直接将编码得到的视觉表征和语义表征相结合,模型的图像重建过程会过分依赖于视觉表征而忽略语义表征的指导作用。因此多类别信息融合阶段的核心是求取人脸图像在特征空间中概率分布的映射关系,然后基于该分布重建出用于重建正面人脸图像的表征信息。本文方法的多类别信息融合解码过程如图 3所示。该融合过程首先构造了一个变分自编码器网络
| $ \mu, \sigma^2 \Leftarrow M_{\mathrm{P}, C}\left(\boldsymbol{F}_{\mathrm{H}}, \boldsymbol{F}_{\mathrm{L}}\right) $ | (7) |
式中,
| $ L_{\mathrm{KL}}=\frac{1}{2} \sum\limits_{i=1}^N\left(1+\log \left(\sigma_i^2\right)-\mu_i^2-\sigma_i^2\right) $ | (8) |
接着采用重参数化方法对获取的分布进行采样处理,并得到
| $ \boldsymbol{F}_{\mathrm{P}, E}=\mu+\boldsymbol{\varepsilon} \odot \sigma $ | (9) |
式中,
| $ \boldsymbol{F}_{\mathrm{P}}=M_{\mathrm{P}, D}\left(\boldsymbol{F}_{\mathrm{P}, E}\right) $ | (10) |
式中,
| $ \boldsymbol{F}_{\mathrm{H}}^{\prime}=M_{\mathrm{H}}\left(\boldsymbol{F}_{\mathrm{H}}\right), \boldsymbol{F}_{\mathrm{L}}^{\prime}=M_{\mathrm{L}}\left(\boldsymbol{F}_{\mathrm{L}}\right) $ | (11) |
式中,
| $ \hat{\boldsymbol{y}}=C_{\text {out }}\left(U_N^r\left(\cdots U_2^r\left(U_1^r\left(\operatorname{Cat}\left(\boldsymbol{F}_{\mathrm{H}}^{\prime}, \boldsymbol{F}_{\mathrm{L}}^{\prime}, \boldsymbol{F}_{\mathrm{P}}\right)\right)\right)\right)\right) $ | (12) |
式中,
2.4 模型损失函数
双层级表征集成推理模型以端到端方式训练,训练过程受到5个损失的协同监督,包括像素级损失、对抗损失、感知损失、身份保留损失以及KL散度损失。
1) 像素级损失。像素级损失对于图像重建任务十分重要,模型损失函数首先采用了像素级损失。对于给定的训练数据集
| $ L_{\text {pixel }}=\frac{1}{Q} \sum\limits_{i=1}^Q\left\|\boldsymbol{y}^{(i)}-\hat{y}^{(i)}\right\|_1 $ | (13) |
2) 对抗损失。面向于更加真实的人脸图像重建,模型训练的监督过程采用了对抗损失,引导重构的人脸图像具有与真实的人脸图像相同的特质。对抗损失定义为
| $ L_{\text {adv }}=E\left[\log D\left(\boldsymbol{y}^{(i)}\right)\right]-E\left[\log \left(1-D\left(\hat{\boldsymbol{y}}^{(i)}\right)\right)\right] $ | (14) |
式中,
3) 感知损失。像素级损失的使用易导致重建图像纹理平滑,通过引入感知损失能够有效缓解该问题。感知损失是在ImageNet上预先训练的VGG-19(Visual Geometry Group layer-19)网络的帮助下实现的。感知损失定义为
| $ {L_{\rm{p}}} = \left\| {\mathit{\boldsymbol{ \boldsymbol{\varPhi} }}\left({{\mathit{\boldsymbol{y}}^{(i)}}} \right) - \mathit{\boldsymbol{ \boldsymbol{\varPhi} }}\left({{{\mathit{\boldsymbol{\widehat y}}}^{(i)}}} \right)} \right\| $ | (15) |
式中,
4) 身份保留损失。为了维持正面人脸重建的过程中图像的身份一致性,模型训练的监督过程同样采用了身份保留损失。该损失通过一个预先训练的人脸识别网络来计算重建图像和参考图像之间的身份差异。身份保留损失定义为
| $ {L_{{\rm{id}}}} = \left\| {\mathit{\boldsymbol{ \boldsymbol{\varPsi} }}\left({{\mathit{\boldsymbol{y}}^{(i)}}} \right) - \mathit{\boldsymbol{ \boldsymbol{\varPsi} }}\left({{{\mathit{\boldsymbol{\widehat y}}}^{(i)}}} \right)} \right\| $ | (16) |
式中,
5) 模型总损失。最后,综合以上损失函数,可以得到模型训练的总损失函数为
| $ L=\lambda_1 L_{\text {pixel }}+\lambda_2 L_{\text {adv }}+\lambda_3 L_{\mathrm{p}}+\lambda_4 L_{\mathrm{id}}+\lambda_5 L_{\mathrm{KL}} $ | (17) |
式中,
3 实验
在实验阶段,除了在标准的Multi-PIE数据集(Gross等,2010)中进行评估外,还进一步地在非受控场景下获取的CASIA-WebFace(Institute of Automation, Chinese Academy of Sciences—WebFace)数据集(Yi等,2014)(人脸识别任务经典数据集)中进行了定性和定量的评估。首先介绍模型训练和测试数据集以及实现细节,接着进行一系列的消融研究以验证模型各个模块对性能的增益,最后通过定量的客观质量和定性的主观质量对所提出方法进行全面的性能评估。
3.1 实验设置
在人脸识别模型的预训练阶段,采用了MSCeleb-1M数据集(Guo等,2016)对人脸识别模型进行训练。需要说明的是,遵循与工作ArcFace(Deng等,2019)相一致的训练方式,对该数据集进行了精细化处理,处理后的数据集包含有85 K个身份以及对应的3.8 M幅图像。
首先使用经典的Multi-PIE数据集用于模型基础的性能评估,包括模型的训练和测试阶段。Multi-PIE数据集是受控场景下用于人脸合成和识别的最大的公共数据库。它包含4个部分,包含15个姿势和20个光照条件下337个身份的754 204幅图像。为了进行公平的比较,本文中训练和测试过程与现有工作(Tu等,2022;Wei等,2020;Yin等,2020;Zhao等,2018a;Hu等,2018;Huang等,2017)保持了相同的实验设置。
CASIA-WebFace数据集是非受控场景下常用于人脸识别的公共数据库。数据集包含了10 575个人的494 414幅图像。面向人脸正面化重建任务,本文首先对该数据集进行了模型输入及输出样本的划分。通过训练一个正面人脸识别模型对数据集中的正面/非正面人脸进行分类,其中非正面的人脸图像为输入图像,对应相同身份的正面人脸图像则为重建图像的参考图像。随后,数据集的10 575个身份中前9 000个身份划分为训练集,剩余的10 575个身份为测试集。数据集划分示例如图 4所示。

用于训练和测试的两个数据集图像统一调整到尺寸为128×128像素的标准视图。网络中降采样模块个数
3.2 双路径编码的有效性分析
在语义信息编码器的构建方面,分别采用了ResNet-18以及ResNet-50作为预训练的人脸识别模型。实验发现,基于两者所重建的人脸图像质量仅具有微弱差异。相较于ResNet-18,基于ResNet-50的平均Rank-1识别率仅领先0.02%。结合模型的计算复杂度与重建精度,最终确定采用ResNet-18作为预训练的人脸识别模型。
消融实验在维持网络其他部分不变的情况下,分别移除了编码阶段的视觉信息编码路径以及语义信息编码路径(两者在多类别信息融合模型中对应的补偿推理分支也进行了移除),得到了网络
表 1
模型组件分析:Multi-PIE数据集中Rank-1识别率
Table 1
Component analysis: Rank-1 recognition rates under the Multi-PIE dataset
| /% | |||||||||||||||||||||||||||||
| 模型 | 位姿度 | ||||||||||||||||||||||||||||
| ±15° | ±30° | ±45° | ±60° | ±75° | ±90° | ||||||||||||||||||||||||
| 100 | 100 | 99.67 | 98.50 | 97.17 | 92.17 | ||||||||||||||||||||||||
| 100 | 99.93 | 99.67 | 97.67 | 96.67 | 90.33 | ||||||||||||||||||||||||
| 99.17 | 98.67 | 95.50 | 85.83 | 80.67 | 67.67 | ||||||||||||||||||||||||
| 100 | 100 | 99.71 | 98.27 | 97.03 | 91.33 | ||||||||||||||||||||||||
| 本文 | 100 | 100 | 99.83 | 98.83 | 97.67 | 92.50 | |||||||||||||||||||||||
| 注:加粗字体表示各列最优结果。 | |||||||||||||||||||||||||||||
3.3 多类别信息融合模块的有效性分析
与3.2节设置相似,网络分别移除了联合表征自编码分支以及两个补偿推理分支得到了网络
3.4 各损失函数对模型性能的影响
为了进一步验证损失函数的有效性,全面地分析了各个损失函数对模型性能的影响,实验结果如表 2所示。消除身份保留损失对结果的影响最大,这说明了身份保留损失的重要性。
表 2
损失函数分析:Multi-PIE数据集中Rank-1识别率
Table 2
Loss function analysis: Rank-1 recognition rates under the Multi-PIE dataset
| /% | |||||||||||||||||||||||||||||
| 模型 | 位姿度 | ||||||||||||||||||||||||||||
| ±15° | ±30° | ±45° | ±60° | ±75° | ±90° | ||||||||||||||||||||||||
| w/o |
99.98 | 99.87 | 99.72 | 98.24 | 97.24 | 91.77 | |||||||||||||||||||||||
| w/o |
99.83 | 99.51 | 97.21 | 96.20 | 93.47 | 83.96 | |||||||||||||||||||||||
| w/o |
99.96 | 99.93 | 99.59 | 98.48 | 97.10 | 92.22 | |||||||||||||||||||||||
| w/o |
100 | 99.95 | 99.71 | 98.74 | 97.41 | 92.34 | |||||||||||||||||||||||
| 本文 | 100 | 100 | 99.83 | 98.83 | 97.67 | 92.50 | |||||||||||||||||||||||
| 注:加粗字体表示各列最优结果。 | |||||||||||||||||||||||||||||
3.5 客观质量评估
人脸识别的准确性通常用于定量评价不同方法的身份保持能力。人脸正面化的目的是将其应用到人脸识别模型中,以提高在大姿态跨度下重构人脸的识别准确性。因此,本文定量地比较了本文方法与其他方法重建人脸图像的识别精度。识别精度越高则代表模型重建结果的身份信息越准确。
首先在Multi-PIE数据集上进行正面化人脸重建性能评估。LightCNN-29用来作为基础的人脸识别模型,并将所提方法与当前较先进的方法,包括:TP-GAN(two-pathway generative adversarial network)(Huang等,2017)、CAPG-GAN(Hu等,2018)、PIM(pose-invariant model)(Zhao等,2018a)、3D-PIM(Zhao等,2018b)、DA-GAN(dual-attention generative adversarial network)(Yin等,2020)、FFWM(Wei等,2020)以及FFN-S(face frontalization sub-net-separate)(Tu等,2022)等进行了对比。实验结果如表 3所示,所有方法在姿态变化较小的情况下(±15°和±30°)均具有较高的识别精度,但所有方法的精度都随着位姿度的增加而降低,特别是在±75°和±90°。这是因为当位姿度增加时,会丢失更多的身份信息。与现有方法相比,本文方法在±15°、±30°、±45°和±75°时均取得了最优的人脸识别性能。特别是在±15°和±30°时达到了100%的识别率,并在所有姿态中取得了最优的平均识别率。
表 3
在Multi-PIE数据集中跨姿态重建人脸图像Rank-1识别率对比
Table 3
Rank-1 recognition rates across poses of the Multi-PIE dataset
| /% | |||||||||||||||||||||||||||||
| 方法 | 位姿度 | ||||||||||||||||||||||||||||
| ±15° | ±30° | ±45° | ±60° | ±75° | ±90° | 平均值 | |||||||||||||||||||||||
| Light-CNN(Wu等,2018) | 98.59 | 97.38 | 92.13 | 62.09 | 24.18 | 5.51 | 63.31 | ||||||||||||||||||||||
| TP-GAN(Huang等,2017) | 98.68 | 98.06 | 95.38 | 87.72 | 77.43 | 64.64 | 86.99 | ||||||||||||||||||||||
| CAPG-GAN(Hu等,2018) | 99.82 | 99.56 | 97.33 | 90.63 | 83.05 | 66.05 | 89.41 | ||||||||||||||||||||||
| PIM(Zhao等,2018a) | 99.30 | 99.00 | 98.50 | 98.10 | 95.00 | 86.50 | 96.07 | ||||||||||||||||||||||
| 3D-PIM(Zhao等,2018b) | 99.64 | 99.48 | 98.81 | 98.37 | 95.21 | 86.73 | 96.37 | ||||||||||||||||||||||
| DA-GAN(Yin等,2020) | 99.98 | 99.88 | 99.15 | 97.27 | 93.24 | 81.56 | 95.18 | ||||||||||||||||||||||
| FFWM(Wei等,2020) | 99.86 | 99.80 | 99.37 | 98.85 | 97.20 | 93.17 | 98.04 | ||||||||||||||||||||||
| FFN-S(Tu等,2022) | 99.83 | 99.82 | 98.05 | 91.81 | 85.31 | 70.20 | 90.84 | ||||||||||||||||||||||
| 本文 | 100 | 100 | 99.83 | 98.83 | 97.67 | 92.50 | 98.14 | ||||||||||||||||||||||
| 注:加粗数字为每列最优值,加下划线数字为每列次优值。 | |||||||||||||||||||||||||||||
实验进一步定性比较了不同方法的参数数量和计算复杂度。评估过程中各模型输入输出图像尺寸统一为128×128像素。实验结果如表 4中所示,本文方法在模型参数数量以及计算复杂度方面具有显著优势。其主要原因在于现有方法大多使用如面部地标热图等显式的先验知识作为约束,或使用额外的如流估计等复杂操作,导致网络存在高昂的存储和计算资源需求。与目前最先进的FFWM方法相比,本文方法不仅节省了79%的参数数量和42%的计算操作数,且展现出了更优的重建图像性能。
表 4
现有方法模型参数量和计算复杂度对比
Table 4
The number of parameters and computational complexity (FLOPs) of existing methods
| 方法 | 参数量/M | FLOPs/G |
| TP-GAN(Huang等,2017) | 138.31 | 251.81 |
| CAPG-GAN(Hu等,2018) | 44.00 | 27.50 |
| PIM(Zhao等,2018a) | 163.87 | 275.66 |
| DA-GAN(Yin等,2020) | 87.47 | 113.97 |
| FFWM(Wei等,2020) | 68.62 | 114.10 |
| 本文 | 14.11 | 65.35 |
| 注:加粗数字为每列最优值,加下划线数字为每列次优值。 | ||
3.6 主观质量评估
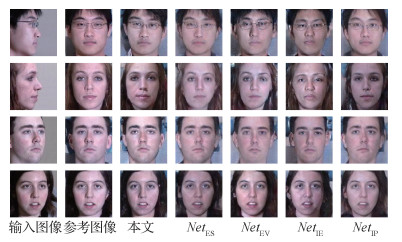
尽管现有的一些工作已经在大姿态上取得了较可以发现,本文方法重建的正面人脸图像能够具有为满意的视觉效果,但是人脸正面化重建过程中的身份信息丢失问题是难以避免的。因此相较于图像的视觉质量(细节纹理等逼真程度),视觉上身份的一致性更为重要。本文方法在Multi-PIE数据集上各种姿态中的表现如图 1所示,重建人脸图像具有稳健的身份一致性。
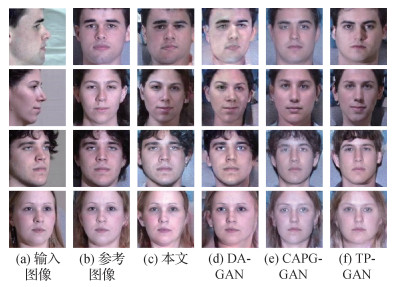
为了验证本文方法的先进性,进一步与现有工作进行了比较。考虑到现有方法对数据集处理方式的差异会影响到主观质量评估的公平性,实验选择了具有开源代码的DA-GAN(Yin等,2020)、CAPG-GAN(Hu等,2018)以及TP-GAN(Huang等,2017)等方法进行了定性比较。并在Multi-PIE训练集上进行了完备的训练。实验结果如图 6所示。图中展示了不同方法在不同姿态下的综合结果。通过对比可以发现,本文方法重建的正面人脸图像能够具有更加明确的身份特征以及视觉质量。
3.7 面向真实场景的质量评估
在CASIA-WebFace数据集上进行了面向真实非受控场景的性能评估。与3.6节设置相似,实验选择了DA-GAN(Yin等,2020)、CAPG-GAN(Hu等,2018)以及TP-GAN(Huang等,2017)等方法与本文方法进行定量和定性的比较,验证不同方法在真实非受控场景中的泛化能力。定量的结果如表 5所示,所提方法能够领先现有方法超过10%的识别精度。图 1展示了所提方法在CASIA-WebFace数据集上的视觉表现,在非受控环境下依然具有良好的正面化性能。图 7展示了所提方法与现有方法的主观质量对比结果。本文方法的重建图像质量具有显著的优越性,所保留的身份信息更加丰富。
表 5
与现有方法在CASIA-WebFace数据集上Rank-1识别率对比
Table 5
Rank-1 recognition rates comparison with existing methods on the CASIA-WebFace dataset
| TP-GAN | CAPG-GAN | DA-GAN | 本文 | |
| Rank-1/% | 61.2 | 68.1 | 67.3 | 79.9 |
| 注:加粗字体表示最优值。 | ||||

4 结论
可用数据集不足问题是当前人脸正面化重建技术发展的限制因素之一。本文提出了一种双层级表征集成推理网络,该网络通过联合输入图像的视觉信息以及表征信息获取更加完备的人脸表征方式,并以视觉表征为基础、以语义表征为引导对两种信息进行有效融合,实现了人脸正面化图像的高质量重建。该方法是一种无图像配准和人脸先验信息需求的人脸图像正面化重建方法,仅对常用的人脸识别数据集进行正面/非正面的粗划分后即可用于模型的训练,进而在真实场景中可实现任意姿态人脸图像的正面化重建。完备的定量和定性实验结果表明,本文方法不仅能够在基准数据集中取得最优表现,而且在真实非受控场景下的性能评估中也展现出了显著的优越性。
当前方法在大规模的人脸识别数据集中的训练过程仍有待进一步提升,包括更加完善的数据集划分的策略、损失函数的选择以及参数设置等。除了实验相关设置外,如何为人脸图像建立更加完备且便捷的表征建模方法将是后续研究的主要问题。
参考文献
-
Blanz V and Vetter T. 1999. A morphable model for the synthesis of 3D faces//Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques. Los Angeles, USA: ACM: 187-194 [DOI:10.1145/311535.311556]
-
Cao J, Hu Y B, Zhang H W, He R and Sun Z N. 2018. Learning a high fidelity pose invariant model for high-resolution face frontalization//Proceedings of the 32nd International Conference on Neural Information Processing Systems. Montréal, Canada: Curran Associates Inc. : 2872-2882
-
Cao S H, Liu X H, Mao X Q, Zou Q. 2022. A review of human face forgery and forgery-detection technologies. Journal of Image and Graphics, 27(4): 1023-1038 (曹申豪, 刘晓辉, 毛秀青, 邹勤. 2022. 人脸伪造及检测技术综述. 中国图象图形学报, 27(4): 1023-1038) [DOI:10.11834/jig.200466]
-
Cole F, Belanger D, Krishnan D, Sarna A, Mosseri I and Freeman W T. 2017. Synthesizing normalized faces from facial identity features//Proceedings of the 2nd International Conference on Learning Representations. Banff, Canada: IEEE: 3386-3395 [DOI:10.1109/CVPR.2017.361]
-
Deng J K, Guo J, Xue N N and Zafeiriou S. 2019. ArcFace: additive angular margin loss for deep face recognition//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE: 4685-4694 [DOI:10.1109/CVPR.2019.00482]
-
Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A and Bengio Y. 2014. Generative adversarial nets//Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press: 2672-2680
-
Gross R, Matthews I, Cohn J, Kanade T, Baker S. 2010. Multi-PIE. Image and Vision Computing, 28(5): 807-813 [DOI:10.1016/j.imavis.2009.08.002]
-
Guo Y D, Zhang L, Hu Y X, He X D and Gao J F. 2016. MS-Celeb-1M: a dataset and benchmark for large-scale face recognition//Proceedings of the 14th European Conference on Computer Vision. Amsterdam, the Netherlands: Springer: 87-102 [DOI:10.1007/978-3-319-46487-9_6]
-
Hassner T, Harel S, Paz E and Enbar R. 2015. Effective face frontalization in unconstrained images//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE: 4295-4304 [DOI:10.1109/CVPR.2015.7299058]
-
He K M, Zhang X Y, Ren S Q and Sun J. 2016. Deep residual learning for image recognition//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE: 770-778 [DOI:10.1109/CVPR.2016.90]
-
Hu Y B, Wu X, Yu B, He R and Sun Z N. 2018. Pose-guided photorealistic face rotation//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE: 8398-8406 [DOI:10.1109/CVPR.2018.00876]
-
Huang R, Zhang S, Li T Y and He R. 2017. Beyond face rotation: global and local perception GAN for photorealistic and identity preserving frontal view synthesis//Proceedings of 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE: 2458-2467 [DOI:10.1109/ICCV.2017.267]
-
Kan M N, Shan S G, Chang H and Chen X L. 2014. Stacked progressive auto-encoders (SPAE) for face recognition across poses//Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE: 1883-1890 [DOI:10.1109/CVPR.2014.243]
-
Kingma D P and Welling M. 2014. Auto-encoding variational Bayes [EB/OL]. [2021-05-01]. https://arxiv.org/pdf/1312.6114.pdf
-
Rezende D J, Eslami S M A, Mohamed S, Battaglia P, Jaderberg M and Heess N. 2016. Unsupervised learning of 3D structure from images//Proceedings of the 30th International Conference on Neural Information Processing Systems. Barcelona, Spain: Curran Associates Inc. : 5003-5011
-
Sagonas C, Panagakis Y, Zafeiriou S and Pantic M. 2015. Robust statistical face frontalization//Proceedings of 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE: 3871-3879 [DOI:10.1109/ICCV.2015.441]
-
Tran L, Yin X and Liu X M. 2017. Disentangled representation learning GAN for pose-invariant face recognition//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE: 1283-1292 [DOI:10.1109/CVPR.2017.141]
-
Tu X G, Zhao J, Liu Q K, Ai W J, Guo G D, Li Z F, Liu W, Feng J S. 2022. Joint face image restoration and frontalization for recognition. IEEE Transactions on Circuits and Systems for Video Technology, 32(3): 1285-1298 [DOI:10.1109/TCSVT.2021.3078517]
-
Wang H, Wu C D, Chi J N, Yu X S, Hu Q. 2020. Face super-resolution reconstruction based on multitask joint learning. Journal of Image and Graphics, 25(2): 229-240 (王欢, 吴成东, 迟剑宁, 于晓升, 胡倩. 2020. 联合多任务学习的人脸超分辨率重建. 中国图象图形学报, 25(2): 229-240) [DOI:10.11834/jig.190233]
-
Wei Y X, Liu M, Wang H L, Zhu R F, Hu G S and Zuo W M. 2020. Learning flow-based feature warping for face frontalization with illumination inconsistent supervision//Proceedings of the 16th European Conference on Computer Vision. Edinburghm, UK: Springer: 558-574 [DOI:10.1007/978-3-030-58610-2_33]
-
Wu X, He R, Sun Z N, Tan T N. 2018. A light CNN for deep face representation with noisy labels. IEEE Transactions on Information Forensics and Security, 13(11): 2884-2896 [DOI:10.1109/TIFS.2018.2833032]
-
Yan X C, Yang J M, Yumer E, Guo Y J and Lee H. 2017. Perspective transformer nets: learning single-view 3D object reconstruction without 3D supervision[EB/OL]. [2021-08-13]. https://arxiv.org/pdf/1612.00814.pdf
-
Yang J M, Reed S, Yang M H and Lee H. 2015. Weakly-supervised disentangling with recurrent transformations for 3D view synthesis//Proceedings of the 28th International Conference on Neural Information Processing Systems. Quebec, Canada: MIT Press: 1099-1107
-
Yi D, Lei Z, Liao S C and Li S Z. 2014. Learning face representation from scratch[EB/OL]. [2021-11-28]. https://arxiv.org/pdf/1411.7923.pdf
-
Yim J, Jung H, Yoo B, Choi C, Park D S and Kim J. 2015. Rotating your face using multi-task deep neural network//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE: 676-684 [DOI:10.1109/CVPR.2015.7298667]
-
Yin X, Yu X, Kihyuk S, Liu X M and Manmohan C. 2017. Towards large-pose face frontalization in the wild//Proceedings of 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE: 4010-4019 [DOI:10.1109/ICCV.2017.430]
-
Yin Y, Jiang S Y, Robinson J P and Fu Y. 2020. Synthesizing normalized faces from facial identity features//Proceedings of the 2nd International Conference on Learning Representations. Buenos Aires, Argentina: IEEE: 249-256 [DOI:10.1109/FG47880.2020.00004]
-
Zhang J, He H, Zhan X S, Xiao J. 2014. Three dimensional face reconstruction via feature adaptation and Laplace deformation. Journal of Image and Graphics, 19(9): 1349-1359 (张剑, 何骅, 詹小四, 肖俊. 2014. 结合特征适配与拉普拉斯形变的3维人脸重建. 中国图象图形学报, 19(9): 1349-1359) [DOI:10.11834/jig.20140912]
-
Zhao B, Wu X, Cheng Z Q, Liu H, Jie Z Q and Feng J S. 2018a. Multi-view image generation from a single-view//Proceedings of the 26th ACM International Conference on Multimedia. Seoul, Korea(South): ACM: 383-391 [DOI:10.1145/3240508.3240536]
-
Zhao J, Xiong L, Cheng Y, Cheng Y, Li J S, Zhou L, Xu Y, Karlekar J, Pranata S, Shen S M, Xing J L, Yan S H and Feng J S. 2018b. 3D-aided deep pose-invariant face recognition//Proceedings of the 27th International Joint Conference on Artificial Intelligence. Stockholm, Sweden: AAAI Press: 1184-1190 [DOI:10.24963/ijcai.2018/165]
-
Zhao J, Cheng Y, Xu Y, Xiong L, Li J S, Zhao F, Jayashree K, Pranata S, Shen S M, Xing J L, Yan S C and Feng J S. 2018c. Towards pose invariant face recognition in the wild//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE: 2207-2216 [DOI:10.1109/CVPR.2018.00235]
-
Zhu K M, Xu W B, Lu W, Zhao X F. 2022. Deepfake video detection with feature interaction amongst key frames. Journal of Image and Graphics, 27(1): 188-202 (祝恺蔓, 徐文博, 卢伟, 赵险峰. 2022. 多关键帧特征交互的人脸篡改视频检测. 中国图象图形学报, 27(1): 188-202) [DOI:10.11834/jig.210408]
-
Zhu X Y, Lei Z, Liu X M, Shi H L and Li S Z. 2016. Face alignment across large poses: a 3D solution//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE: 146-155 [DOI:10.1109/CVPR.2016.23]
-
Zhu X Y, Lei Z, Yan J J, Yi D and Li S Z. 2015. High-fidelity pose and expression normalization for face recognition in the wild//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE: 787-796 [DOI:10.1109/CVPR.2015.7298679]
-
Zhu Z Y, Luo P, Wang X G and Tang X O. 2014. Multi-view perceptron: a deep model for learning face identity and view representations//Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press: 217-225


