|
|
|
发布时间: 2022-09-16 |
多媒体分析与理解 |
|
|
|


|
收稿日期: 2022-01-05; 修回日期: 2022-06-01; 预印本日期: 2022-06-08
基金项目: 国家重点研发计划资助(2020YFB1406701);国家自然科学基金项目(62072147,62125201);浙江省自然科学基金项目(LR22F020001,LY22F020028)
作者简介:
余宙,1988年生,男,副教授,硕士生导师,主要研究方向为多模态数据分析与推理。E-mail: yuz@hdu.edu.cn
俞俊,通信作者,男,教授,博士生导师,主要研究方向为多媒体分析与检索。E-mail:yujun@hdu.edu.cn 朱俊杰,男,硕士研究生,主要研究方向为多媒体分析与视觉问答。E-mail: zhujj@hdu.edu.cn 匡振中,男,副教授,主要研究方向为多媒体隐私保护。E-mail: zzkuang@hdu.edu.cn *通信作者: 俞俊 yujun@hdu.edu.cn
中图法分类号: TP391.4
文献标识码: A
文章编号: 1006-8961(2022)09-2761-14
|
摘要
目的 现有视觉问答方法通常只关注图像中的视觉物体,忽略了对图像中关键文本内容的理解,从而限制了图像内容理解的深度和精度。鉴于图像中隐含的文本信息对理解图像的重要性,学者提出了针对图像中场景文本理解的“场景文本视觉问答”任务以量化模型对场景文字的理解能力,并构建相应的基准评测数据集TextVQA(text visual question answering)和ST-VQA(scene text visual question answering)。本文聚焦场景文本视觉问答任务,针对现有基于自注意力模型的方法存在过拟合风险导致的性能瓶颈问题,提出一种融合知识表征的多模态Transformer的场景文本视觉问答方法,有效提升了模型的稳健性和准确性。方法 对现有基线模型M4C(multimodal multi-copy mesh)进行改进,针对视觉对象间的“空间关联”和文本单词间的“语义关联”这两种互补的先验知识进行建模,并在此基础上设计了一种通用的知识表征增强注意力模块以实现对两种关系的统一编码表达,得到知识表征增强的KR-M4C(knowledge-representation-enhanced M4C)方法。结果 在TextVQA和ST-VQA两个场景文本视觉问答基准评测集上,将本文KR-M4C方法与最新方法进行比较。本文方法在TextVQA数据集中,相比于对比方法中最好的结果,在不增加额外训练数据的情况下,测试集准确率提升2.4%,在增加ST-VQA数据集作为训练数据的情况下,测试集准确率提升1.1%;在ST-VQA数据集中,相比于对比方法中最好的结果,测试集的平均归一化Levenshtein相似度提升5%。同时,在TextVQA数据集中进行对比实验以验证两种先验知识的有效性,结果表明提出的KR-M4C模型提高了预测答案的准确率。结论 本文提出的KR-M4C方法的性能在TextVQA和ST-VQA两个场景文本视觉问答基准评测集上均有显著提升,获得了在该任务上的最好结果。
关键词
场景文本视觉问答; 知识表征; 注意力机制; Transformer; 多模态融合
Abstract
Objective Deep neural networks technology promotes the research and development of computer vision and natural language processing intensively. Multiple applications like human face recognition, optical character recognition (OCR), and machine translation have been widely used. Recent development enable the machine learning to deal with more complex multimodal learning tasks that involve vision and language modalities, e.g., visual captioning, image-text retrieval, referring expression comprehension, and visual question answering (VQA). Given an arbitrary image and a natural language question, the VQA task is focused on an image-content-oriented and question-guided understanding of the fine-grained semantics and the following complex reasoning answer. The VQA task tends to be as the generalization of the rest of multimodal learning tasks. Thus, an effective VQA algorithms is a key step toward artificial general intelligence (AGI). Recent VQA have realized human-level performance on the commonly used benchmarks of VQA. However, most existing VQA methods are focused on visual objects of images only, while neglecting the recognition of textual content in the image. In many real-world scenarios, the image text can transmit essential information for scene understanding and reasoning, such as the number of a traffic sign or the brand awareness of a product. The ignorance of textual information is constraint of the applicability of the VQA methods in practice, especially for visually-impaired users. Due to the importance of the developing textual information for image interpretation, most researches intend to incorporate textual content into VQA for a scene text VQA task organizing. Specifically, the questions involve the textual contents in the scene text VQA task. The learned VQA model is required to establish unified associations among the question, visual object and the scene text. The reasoning is followed to generate a correct answer. To address the scene text VQA task, a model of multimodal multi-copy mesh(M4C) is faciliated based on the transformer architecture. Multimodal heterogeneous features are as input, a multimodal transformer is used to capture the interactions between input features, and the answers are predicted in an iterative manner. Despite of the strengths of M4C, it still has the two weaknesses as following: 1) the relative spatial relationship cannot be illustrated well between paired objects although each visual object and OCR object encode its absolute spatial location. It is challenged to achieve accurate spatial reasoning for M4C model; 2) the predicted words of answering are selected from either a dynamic OCR vocabulary or a fixed answer vocabulary. The semantic relationships are not explicitly considered in M4C between the multi-sources words. At the iterative answer prediction stage, it is challenged to understand the potential semantic associations between multiple sources derived words. Method To resolve the weaknesses of M4C mentioned above, we improve the reference of M4C model by introducing two added knowledge like the spatial relationship and semantic relationship, and a knowledge-representation-enhanced M4C (KR-M4C) approach is demonstrated to integrate the two types of knowledge representations simultaneously. Additionally, the spatial relationship knowledge encodes the relative spatial positions between each paired object (including the visual objects and OCR objects) in terms of their bounding box coordinates. The semantic relationship knowledge encodes the semantic similarity between the text words and the predicted answer words in accordance with the similarity calculated from their GloVe word embeddings. The two types of knowledge representation are encoded as unified knowledge representations. To match the knowledge representations adequately, the multi-head attention (MHA) module of M4C is modified to be a KRMHA module. By stacking the KRMHA modules in depth, the KR-M4C model performs spatial and semantic reasoning to improve the model performance over the reference M4C model. Result The KR-M4C approach is verified that our extended experiments are conducted on two benchmark datasets of text VQA(TextVQA) and scene text VQA(ST-VQA) based on same experimental settings. The demonstrated results are shown as below: 1) excluded of extra training data, KR-M4C obtains an accuracy improvement of 2.4% over existing optimization on the test set of TextVQA; 2) KR-M4C achieves an average normalized levenshtein similarity (ANLS) score of 0.555 on the test set of ST-VQA, which is 5% higher than theresult of SA-M4C. To verify the synergistic effect of two types of introduced knowledge further, comprehensive ablation studies are carried out on TextVQA, and the demonstrated results can support our hypothesis of those two types of knowledge are proactively and mutually to model performance. Finally, some visualized cases are provided to verify the effects of the two introduced knowledge representations. The spatial relationship knowledge improve the ability to localize key objects in the image, whilst the improved semantic relationship knowledge is perceived of the contextual words via the iterative answer decoding. Conclusion A novel KR-M4C method is introduced for the scene text VQA task. KR-M4C has its priority for the knowledge enhancement beyond the TextVQA and ST-VQA datasets.
Key words
scene text visual question answering; knowledge representation; attention mechanism; Transformer; multimodal fusion
0 引言
视觉问答(visual question answering,VQA)(Antol等,2015)是计算机视觉和自然语言处理的交叉方向的典型任务,也是近年来相关领域的研究热点。它以一幅图像和一个问题作为输入,旨在设计模型对多模态的输入进行信息融合与推理,最终以自然语言的形式输出问题的答案。图 1(a)展示了视觉问答任务的一个示例。模型对图像和问题细致的理解后进行推理,从而实现准确的答案预测,因此它是一项极具挑战性的任务。近年来,研究人员在视觉问答任务中取得了重大进展,在一些常用的视觉问答基准测试集上(Antol等,2015)取得了接近人类水平的准确率,但是这些方法大多忽视了对图像中“场景文本”这一重要信息的理解,从而限制了其对场景理解的深度。另外,视觉问答技术在现实生活中的一个典型应用场景是视障人群的辅助,而对于这些特殊人群来说,理解场景中的文字也是他们真正关心的痛点问题。


Singh等人(2019)和Biten等人(2019)提出将文本内容融入到视觉问答中,形成面向场景文本视觉问答任务,同时构建了TextVQA(text visual question answering)(Singh等,2019)和ST-VQA(scene text visual question answering)(Biten等,2019)两个基准数据集。图 1(b)展示了场景文本视觉问答任务的一个示例,该任务问题涉及图像中相关的场景文本,需要模型建立问题、视觉对象和场景文本之间的统一关联后开展推理以生成正确的答案。为了理解图像中的场景文本,场景文本视觉问答模型通常需要引入一个光学字符识别(optical character recognition,OCR)系统来检测并识别图像中的文本对象。基于抽取到的OCR对象,一些方法相继提出(Singh等,2019;Hu等,2020;Kant等,2020)。LoRRA(look read reason and answer)(Singh等,2019)方法在视觉问答模型的基础上,扩展了一个用于场景文本编码的OCR注意分支。M4C(multimodal multi-copy mesh)(Hu等,2020)方法通过多模态Transformer融合所有输入特征模态内和模态间的信息,并采用迭代解码生成答案。但是M4C中Transformer的自注意力层是完全连接的,将注意力分散到整体上下文中,而忽略了围绕特定对象或文本的局部上下文的重要性。
在场景文本视觉问答任务中,部分问题涉及推理对象间的相对空间关系。例如,图像右侧的标识牌上写了什么内容?或图像左边球员的球衣上写了什么数字?针对这类问题,SA-M4C(spatially aware M4C)(Kant等,2020)方法通过引入12种预先定义的空间关系(Yao等,2018)对视觉对象和OCR对象构建联系,获得了增强的相对空间关系知识,并将其融合到Transformer每个注意力层中,改进并提升了M4C方法的性能。但是人工构建的空间关系的空间量化策略不够精准,对于空间关联紧密的目标表达不够精准。
本文提出了一种融合知识表征的多模态Transformer的场景文本视觉问答方法KR-M4C(knowledge-representation-enhanced M4C),通过将“空间关联”和“语义关联”两种互补的先验知识进行统一建模后融入M4C模型框架,提升模型对复杂场景的理解能力。空间关联知识对视觉对象和OCR对象间的相对空间位置进行编码表征,有效对两两对象间细粒度的空间关系进行精准刻画。语义关联知识对OCR对象对应的单词和预测答案单词之间的语义相似性,对存在上下文语义关联的单词进行编码表征,提升答案生成过程模型的准确性和可靠性。为了评估提出的KR-M4C方法的有效性,分别在Text-VQA和ST-VQA两个公开数据集上进行实验。实验结果表明,相较于目前最好的方法,KR-M4C在两个数据集上均取得显著的性能提升。本文主要贡献如下:1)提出一种基于知识表征增强的多模态Transformer场景文本视觉问答模型KR-M4C,通过引入增强的知识,获得了更丰富的信息表示;2)建模了视觉对象间“空间关联”和单词间的“语义关联”这两种互补的先验知识,更准确地引导模型定位关键物体对象和文本对象;3)在TextVQA数据集和ST-VQA数据集上进行了充分的对比实验和消融实验。实验结果表明,KR-M4C与现有最好方法相比具有更出色的表现。
1 相关工作
多模态学习旨在设计模型对来自不同模态的信号(如视觉、听觉和语言等)进行信息关联,并在此基础上学习统一的语义表达。得益于深度学习的快速发展,多模态学习逐渐成为计算机视觉和自然语言处理领域的研究热点,提出了一系列重要的多模态学习任务。如视觉问答(Antol等,2015;Kim等,2018;Yu等,2019)、视觉定位(Yu等,2017a)、图文检索(Karpathy和Li,2015;Lee等,2018)和图像描述(Anderson等,2016;Veit等,2016)等。在这些任务中,视觉问答是一个典型且具有挑战性的任务。
VQA是多模态领域近年来的研究热点。VQA任务的核心在于如何进行图像和问题的多模态信息融合。Zhou等人(2015)和Antol等人(2015)使用的是特征拼接或对应元素相加的线性融合方法。而后,得益于双线性模型在细粒度识别领域取得的良好效果,Fukui等人(2016)、Kim等人(2017)、Ben-Younes等人(2017)和Yu等人(2017b)设计了不同的近似双线性池化模型用于多模态特征的细致语义融合。随着对注意力机制研究的深入,提出了深度共同注意力模型用于多模态融合和注意力学习。Yu等人(2019)将模块化的思想引入视觉问答中,设计两种注意力单元并进行模块化组合,构建深度模块化协同注意力网络,建模多模态数据间细粒度的交互关联。随着多模态预训练研究的兴起,研究人员不再聚焦于单一的视觉问答模型设计,而是将研究重心聚焦如何基于Transformer这种通用架构设计合适的预训练策略,在大规模数据集上进行预训练,并在得到的模型权重基础上利用VQA数据进行模型权重微调。Lu等人(2019)、Tan和Bansal(2019)、Chen等人(2020)和Cui等人(2021)提出了各种多模态预训练框架,并逐步刷新视觉问答任务基准评测集上的最好成绩。
场景文本视觉问答任务是一种特殊的视觉问答任务。相比一般视觉问答任务,场景文本视觉问答更侧重图像中的文本信息,不仅它的问题主要围绕图像中的文本信息,而且它的回答也需要使用图像中的文本信息。这要求模型对问题单词、图像的物体对象和图像的文本对象构建联系,并经过推理生成正确答案。由于该任务具有重要的研究和应用价值,研究人员提出了一系列的解决方案。LoRRA(Singh等,2019)扩展了面向传统视觉问答的Pythia(Jiang等,2018)方法,使用现有的OCR系统检测图像中的文本对象,额外增加了一个用于场景文本编码的OCR注意分支,通过对固定词汇表中的单词和OCR识别得到的单词进行推理,选择其中概率最大的单词作为答案。由于LoRRA没有构建丰富的OCR对象特征,因此无法充分理解OCR对象蕴含的信息。此外,其采用的浅层注意力融合模型无法进行深度推理。为解决该问题,Hu等人(2020)提出了M4C模型,该模型是该任务上的一个强有力的基线方法,它通过一个多模态Transformer(Antol等,2015)结构,将不同模态的特征嵌入到一个共同的语义空间中进行融合。在这个语义空间中,模态间和模态内的关联由自注意力模型自动学习得到。M4C将场景文本视觉问答作为一个序列生成任务,结合一个动态指针网络模块实现精准的答案生成。然而,M4C没有考虑到图像中对象之间的相对空间关系,因此在涉及相对空间关系的问题上表现不理想。为解决M4C模型存在的问题,SA-M4C(Kant等,2020)在M4C的基础上,通过12种空间关系(Yao等,2018)对物体对象和OCR文本对象构建联系,获得了增强的知识,进一步提升了准确率,但是预定义的空间关系建模方法对空间关系的表达粒度不够细致,对相近位置对象难以区分。
2 融合知识表征多模态Transformer
针对场景文本视觉问答任务,本文在M4C模型(Hu等,2020)基础上进行改进,通过对“空间关系”和“语义关系”两种互补先验知识进行联合建模,构建知识表征增强的M4C模型。
2.1 M4C模型概述
M4C模型以问题和图像两种模态的数据作为输入,在进行多模态数据统一表征后,输入一个多层Transformer网络对多模态信息深度融合,最后输入一个动态指针网络进行迭代式答案预测。
2.1.1 多模态数据统一表征
如图 2所示,M4C对问题和答案中的单词分别进行词向量表征,对图像分别提取视觉对象区域和OCR对象区域,并针对提取区域进行视觉对象表征和OCR对象表征。
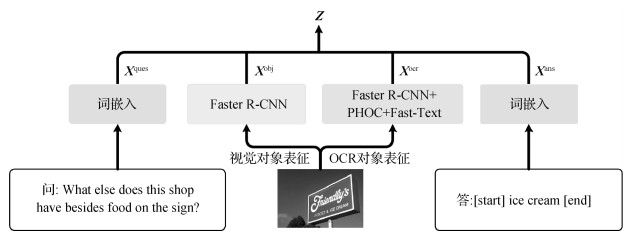
给定由至多
给定一幅图像,使用经过预训练的Faster R-CNN(region convolutional neural network)模型(Ren等,2015)从图像中提取至多
针对图像中的文本,首先使用外部OCR系统从图像中提取至多
对于由至多
将上述4组多模态特征
2.1.2 自回归答案预测
由于答案可能包含OCR单词与词汇表单词合并形成的短语,M4C引入结合动态指针网络的自回归答案预测模块,将在OCR单词和预先构建的答案词汇表中进行的自适应选择作为
令
| $ \mathit{\boldsymbol{y}}_{t, n}^{{\rm{ocr }}} = lin{e_d}{\left({z_t^{{\rm{ans }}}} \right)^{\rm{T}}}{\rm{ }}line{{\rm{ }}_d}\left({z_n^{{\rm{ocr }}}} \right) $ | (1) |
式中,
最后,将上述两个向量进行拼接得到预测向量,通过计算预测答案与正确答案的BCE(binary crossentropy)累计损失,实现对整个M4C模型的端到端优化。
2.2 KR-M4C模型的整体结构
得益于多层Transformer模型强大的建模表达能力,M4C模型可以学习得到不同模态特征之间的细粒度语义关联。但其存在两个弱点:1)尽管每个视觉对象和OCR对象中包含了其对应空间位置信息,然而这种空间位置特征与其他类型特征进行特征融合失去了明确的空间坐标含义,使得M4C模型难以准确理解对象间的空间关系;2)在进行答案预测时输出的单词需要从OCR对象单词和词汇表单词中进行选择,而这些不同来源的单词之间的语义关联在M4C中并未显式地建模,在进行答案预测过程中难以准确理解多来源单词之间的语义关联。
为了解决上述问题,本文在图像中的视觉对象和OCR对象之间提取空间关联知识表征,在OCR对象提取得到的单词和预测单词之间提取语义关联知识表征,并针对这两种关联知识表征,在M4C架构基础上提出一种知识表征增强的改进方法KR-M4C对知识进行编码表达。KR-M4C整体框架如图 3所示,视觉对象与OCR对象间的“空间关联”、OCR单词与预测答案单词间的“语义关联”有助于提升场景文本视觉问答的准确性。

1) 空间关联知识表征。场景文本视觉问答需要模型理解图像中视觉对象与OCR对象之间的空间关系,并在此基础上进行推理。如图 4所示,给定问题What’s the licence number of the car? 模型首先要检测到图像中的车牌对应的视觉对象,然后推断出号码与车牌之间的关系,判断只有车牌对象内的数字才是需要回答的车牌号。
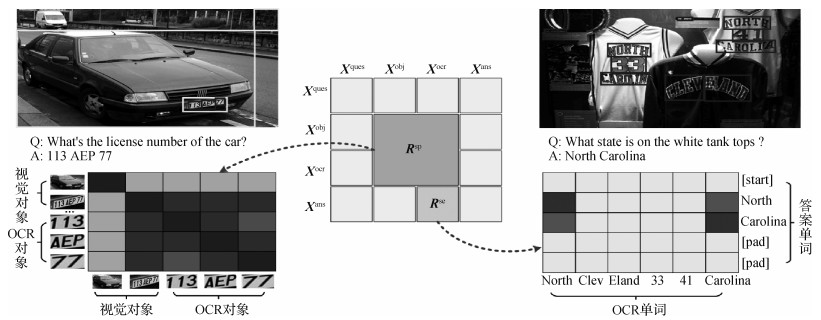
给定图像抽取得到的
| $ \boldsymbol{x}_{i, j}^{\mathrm{sp}}=\left[\log \frac{\left|x_i-x_j\right|}{w_i}, \log \frac{\left|y_i-y_j\right|}{h_i}, \log \frac{w_j}{w_i}, \log \frac{h_j}{h_i}\right] $ | (2) |
对于
| $ {\mathit{\boldsymbol{R}}^{{\rm{sp}}}} = {\rm{ }}relu \circ lin{e_1} \circ {\rm{ }}relu \circ lin{e_d}\left({{\mathit{\boldsymbol{X}}^{{\rm{sp}}}}} \right) $ | (3) |
式中,
2) 语义关联知识表征。部分问题也可能会涉及空间上不相邻的多个单词组合,如图 4所示的North和Carolina。如何去挖掘这些单词之间隐含的语义关系,这直接影响最后预测的精度。此外,由于答案中单词来源由OCR单词和固定词汇表两方面组成,并通过两个独立的分类器预测得到,因此需要模型学习理解两种不同来源单词之间的语义关联。
为解决上述问题,本文在OCR对象对应的单词与预测的答案输出单词之间构建语义关联知识,使用预训练的词向量表征之间的相似度计算单词之间的相对语义关系。具体而言,给定第
| $ \boldsymbol{x}_{i, j}^{\mathrm{se}}=f_{\text {cossim }}\left(\boldsymbol{e}_i, \boldsymbol{e}_j\right) $ | (4) |
给定
3) 知识表征增强自注意力模块。在原生M4C模型中,多模态融合得到的特征
| $ hea{d_j}(\mathit{\boldsymbol{Z}}) = SA\left({lin{e_{{d_h}}}(\mathit{\boldsymbol{Z}}), lin{e_{{d_h}}}(\mathit{\boldsymbol{Z}}), lin{e_{{d_h}}}(\mathit{\boldsymbol{Z}})} \right) $ | (5) |
| $ SA(\mathit{\boldsymbol{Q}}, \mathit{\boldsymbol{K}}, \mathit{\boldsymbol{V}}) = \mathit{softmax}\left({\mathit{\boldsymbol{Q}}{\mathit{\boldsymbol{K}}^{\rm{T}}}/\sqrt d } \right)\mathit{\boldsymbol{V}} $ | (6) |
式中,
受Hu等人(2018)提出的空间关系建模方法的启发,本文将其应用在KR-M4C模型中,将式(5)中的自注意力函数改写为知识先验引导的自注意力函数。具体地,将
| $ KRSA(\mathit{\boldsymbol{Q}}, \mathit{\boldsymbol{K}}, \mathit{\boldsymbol{V}}, \mathit{\boldsymbol{R}}) = \mathit{softmax}\left({\mathit{\boldsymbol{Q}}{\mathit{\boldsymbol{K}}^{\rm{T}}}/\sqrt d + \mathit{\boldsymbol{R}}} \right)\mathit{\boldsymbol{V}} $ | (7) |
式中,
| $ KRMHA(\mathit{\boldsymbol{Z}}) = lin{e_d}\left({\left[ {hea{d_1}(\mathit{\boldsymbol{Z}}), \cdots, hea{d_h}(\mathit{\boldsymbol{Z}})} \right]} \right) $ | (8) |
4) KR-M4C主干网络。通过将原生M4C模型中的MHA模块替换为知识表征增强的KRMHA模块,KR-M4C的主干模型为
| $ {\mathit{\boldsymbol{\widehat Z}}^l} = {\mathop{\rm norm}\nolimits} \left({KRMHA\left({{\mathit{\boldsymbol{Z}}^{l - 1}}} \right) + {\mathit{\boldsymbol{Z}}^{l - 1}}} \right), l = 1, \cdots, L $ | (9) |
| $ {\mathit{\boldsymbol{Z}}^l} = norm\left({FFN\left({{{\mathit{\boldsymbol{\widehat Z}}}^l}} \right) + {{\mathit{\boldsymbol{\widehat Z}}}^l}} \right), l = 1, \cdots, L $ | (10) |
式中,
3 实验
为验证本文KR-M4C的有效性,在场景文本视觉问答任务的TextVQA数据集和ST-VQA数据集上进行验证,并与现有的场景文本视觉问答模型的结果进行对比,对模型生成的样例进行分析。
3.1 实验设置
3.1.1 数据集
1) TextVQA数据集(Singh等,2019)收集了来自Open-Images v3(Kuznetsova等,2020)数据集的28 408幅自然场景图像,其中训练集21 953幅,验证集3 166幅,测试集3 289幅。对各幅图像提出了1~2个问题,共45 336个问题,其中训练集包含34 602个问题,验证集包含5 000个问题,测试集包含5 734个问题。各问题有10个人工标注的答案,通过10个答案的加权投票得分计算准确率。本文遵循先前的工作(Hu等,2020),在训练集的答案中收集前5 000个高频的单词构成固定词汇表。
2) ST-VQA数据集(Biten等,2019)包含MS COCO(Microsoft common objects in context)(Veit等,2016)、VizWiz(Gurari等,2018)、ICDAR(international conferenceon document analysisand recognition)(Karatzas等,2015)、ImageNet(Deng等,2009)、Visual Genome(Krishna等,2017)和IIIT-STR(IIIT scene text retrieval)(Mishra等,2013)这6个数据集共21 892幅自然场景图像,其中训练集和验证集包含18 921幅图像,测试集包含2 971幅图像。针对各幅图像,设计了1~3个问题,各问题提供1~2个人工标注的答案。该数据集涉及3项任务,本文遵循先前的工作(Hu等,2020),在任务3上验证模型的效果,原因是任务3与TextVQA数据集相似,官方不提供候选单词,需要通过外部OCR系统或固定词汇表得到候选单词。与TextVQA数据集不同,ST-VQA数据集推荐采用ANLS (average normalized levenshtein similarity)得分(Biten等,2019)作为官方评价指标,实现更为精准的答案一致性评估。在此基础上,实验时采用TextVQA数据集上使用的准确率指标作为补充。
3.1.2 实现细节
实验环境为装载了Nvidia Titan Xp GPU的工作站。使用PyTorch框架(Paszke等,2019)实现KR-M4C模型。遵循先前的工作(Kant等,2020),模型设计和训练的超参数如表 1所示。
表 1
KR-M4C模型超参数
Table 1
Hyperparameter choices for KR-M4C
| 超参数 | 值 |
| 问题词最大数量 |
20 |
| 物体对象最大数量 |
100 |
| OCR对象最大数量 |
50 |
| 最长答案长度 |
12 |
| 统一表征维度 |
768 |
| 注意力头个数 |
12 |
| 词汇表大小 |
5 000 |
| 优化器 | Adam |
| 批次大小 | 128 |
| 基础学习率 | 10-4 |
| 学习率衰减因子 | 0.1 |
| 学习率衰减轮数 | 14 000/19 000 |
| 迭代次数 | 24 000 |
3.2 消融实验
为了验证不同模型架构对KR-M4C的效果,在TextVQA数据集上进行消融实验。为公平对比,消融实验中的所有模型使用Microsoft OCR提取图像中的文本信息,并使用主干网络为ResNeXt-152的Faster R-CNN模型进行视觉特征表达(Xie等,2017)。实验结果如表 2所示。
表 2
TextVQA数据集上的消融实验
Table 2
Ablation experiments on the TextVQA dataset
| 行号 | 方法 | 模型层数(架构) | 验证集准确率/% |
| 1 | M4C(Hu等,2020) | 6(N) | 45.75 |
| 2 | SA-M4C(Kant等,2020) | 6(S) | 46.93 |
| 3 | KR-M4C | 6(K) | 48.42 |
| 4 | KR-M4C去除 |
6(K) | 46.90 |
| 5 | KR-M4C去除 |
6(K) | 47.06 |
| 6 | SA-M4C(Kant等,2020)* | 2(N)→4(S) | 46.70 |
| 7 | KR-M4C | 2(N)→4(K) | 47.91 |
| 8 | KR-M4C | 3(N)→3(K) | 47.04 |
| 9 | KR-M4C | 4(N)→2(K) | 47.18 |
| 10 | KR-M4C | 4(K) | 46.10 |
| 11 | KR-M4C | 8(K) | 48.34 |
| 12 | KR-M4C | 10(K) | 48.31 |
| 注:加粗字体表示最优结果,括号中的N表示标准的注意力结构,S表示SA-M4C中的空间感知注意力结构,K表示本文提出的知识表征增强的注意力结构。*表示基于原开源代码复现。 | |||
1) 不同类型知识的增强效果。以M4C模型架构为对照,验证不同类型知识引入后的增强效果。首先对比表 2第1、3行结果,发现在模型层数相同(均为6层)情况下,本文提出的KR-M4C方法显著优于M4C方法(Hu等,2020),证明了引入知识表征增强的有效性。其次对比第1、3、4、5行结果,发现仅建模空间关联知识
2) 不同模块组合的影响。在SA-M4C(Kant等,2020)中,将不同类型的注意力模块进行组合,如2个M4C中标准的自注意力(N)和4个SA-M4C中的空间感知注意力模块(S),可以提升模型的表达能力。因此,在表 2第3、8—11行的结果中,保持模型层数
3) 不同堆叠深度的影响。保持
3.3 与现有方法的对比实验
基于消融实验的结果,使用6(K)的最优架构在TextVQA数据集上与目前最好方法对比,包括LoRRA(Singh等,2019)、MM-GNN(multi-modal graph neural network)(Gao等,2020)、M4C(Hu等,2020)、SMA(structured multimodal attentions)(Gao等,2021)、CRN(cascade reasoning network)(Liu等,2020)、LaAPNet(localization-aware answer prediction network)(Han等,2020)和SA-M4C(Kant等,2020),结果如表 3所示。额外训练数据表示除Text-VQA数据集以外的数据,如ST-VQA数据集。
表 3
TextVQA数据集上与现有最好方法的对比结果
Table 3
Comparative results with existing state-of-the-art methods on TextVQA dataset
| 行号 | 方法 | 特征提取主干网络 | OCR系统 | 额外训练数据 | 验证集准确率/% | 测试集准确率/% |
| 1 | LoRRA(Singh等,2019) | ResNet | Rosetta-ml | - | 26.56 | 27.63 |
| 2 | MM-GNN(Gao等,2020) | ResNet | Rosetta-ml | - | 31.44 | 31.10 |
| 3 | M4C(Hu等,2020) | ResNet | Rosetta-en | - | 39.40 | 39.01 |
| 4 | SMA(Gao等,2021) | ResNet | Rosetta-en | - | 40.05 | 40.66 |
| 5 | CRN(Liu等,2020) | ResNet | Rosetta-en | - | 40.39 | 40.96 |
| 6 | LaAPNet(Han等,2020) | ResNet | Rosetta-en | - | 40.68 | 40.54 |
| 7 | KR-M4C(本文) | ResNet | Rosetta-en | - | 41.78 | 42.99 |
| 8 | M4C(Hu等,2020) | ResNet | Rosetta-en | ST-VQA | 40.55 | 40.46 |
| 9 | LaAPNet(Han等,2020) | ResNet | Rosetta-en | ST-VQA | 41.02 | 41.41 |
| 10 | KR-M4C(本文) | ResNet | Rosetta-en | ST-VQA | 42.78 | 43.51 |
| 11 | SA-M4C(Kant等,2020) | ResNeXt | Google OCR | - | 43.90 | - |
| 12 | SA-M4C(Kant等,2020)* | ResNeXt | Microsoft OCR | - | 46.70 | - |
| 13 | KR-M4C(本文) | ResNeXt | Microsoft OCR | - | 48.42 | - |
| 14 | SA-M4C(Kant等,2020)* | ResNeXt | Microsoft OCR | ST-VQA | 47.99 | 48.52 |
| 15 | KR-M4C(本文) | ResNeXt | Microsoft OCR | ST-VQA | 49.27 | 49.63 |
| 注:加粗字体为各不同对比条件的最优结果,“-”表示无实验数据,*表示基于原开源代码复现。 | ||||||
表 3展示了不同条件下(如特征提取主干网络、OCR系统和外部训练数据)的公平对比结果。特征提取主干网络包括基于Faster R-CNN的特征提取器与ResNet和ResNeXt两种主干网络的组合。OCR系统包括各方法采用的OCR系统。大部分方法沿用了M4C中的策略,使用Facebook提供的Rosetta-ml和Rosetta-en系统(Borisyuk等,2018),SA-M4C采用了识别性能更好的Google OCR系统。本文使用了总体效果更好的Microsoft OCR系统。从实验结果中可以得到如下结论:1)在使用Rosetta-en OCR系统、Faster R-CNN主干网络使用ResNet-101的条件下,KR-M4C在验证集和测试集上准确率为41.78%和42.99%(第7行),相比最好结果提升1.1%和2.5%;2)增加ST-VQA数据集作为额外训练数据,KR-M4C在验证集、测试集上准确率分别为42.78%和43.51%(第10行),均为同等条件下的最好结果;3)将OCR系统由Google OCR系统替换成效果更好的Microsoft OCR系统,在不增加额外数据的情况下,KR-M4C模型结果相较于同等条件下的SA-M4C模型,在验证集上准确率提升1.7%(第13行);4)增加ST-VQA数据集作为训练数据,KR-M4C模型在验证集和测试集上准确率最好,分别为49.27%和49.63%,比同等情况下的SA-M4C分别提升了1.3%和1.1%。
为进一步验证KR-M4C方法的有效性,在ST-VQA数据集上也进行了对比实验,结果如表 4所示。可以看出,KR-M4C方法比现有最好结果在验证集上的准确率提升了4.7%,在验证集和测试集上的ANLS指标均提升了5%。
表 4
ST-VQA数据集上的结果
Table 4
Comparative results on ST-VQA dataset
| 方法 | 验证集准确率/% | 验证集ANLS | 测试集ANLS |
| SAN+STR(Biten等,2019) | - | - | 0.135 |
| M4C(Hu等,2020) | 38.05 | 0.472 | 0.462 |
| SMA(Gao等,2021) | - | - | 0.466 |
| CRN(Liu等,2020) | - | - | 0.483 |
| LaAPNet(Han等,2020) | 39.74 | 0.497 | 0.485 |
| SA-M4C(Kant等,2020) | 42.23 | 0.512 | 0.504 |
| KR-M4C(本文) | 46.99 | 0.562 | 0.555 |
| 注:加粗字体表示各列最优结果,“-”表示无实验数据。 | |||
此外,为进一步分析M4C、SA-M4C和KR-M4C模型之间的差异,对算法的模型尺寸和复杂度进行对比,结果如表 5所示。可以看出:1)6(R)的KR-M4C相较6(N)的M4C和2(N)+ 4(S)的SA-M4C,模型参数量和FLOPs几乎没有增长,这是因为KR-M4C模型在式(6)中引入的模型参数和计算量相比Transformer主干网络几乎可以忽略;2)相比M4C和SA-M4C,KR-M4C在平均推理时间上用时分别增加48%和12%,增加的时间主要用于计算预测答案单词与OCR单词之间的余弦相似度。如何优化这部分计算过程以进一步提升方法的计算效率是未来拟开展的重要工作。
表 5
模型复杂性的对比结果
Table 5
Comparative results of model complexity
| 方法 | 网络参数量/M | FLOPs/G | 推理单幅图像平均耗时/ms |
| M4C(Hu等,2020) | 96.63 | 18.3 | 89 |
| SA-M4C(Kant等,2020) | 96.63 | 18.4 | 118 |
| KR-M4C(本文) | 96.65 | 18.4 | 132 |
3.4 典型样例分析
为了更好地理解KR-M4C的表现,本文挑选若干典型样例进行分析,相关结果如图 5所示。可以看出,1)KR-M4C相比M4C和SA-M4C获得了总体上更好的结果,体现了引入知识增强后模型对场景文本理解能力的提升。2)SA-M4C和KR-M4C在涉及相对空间关系时的表现相比M4C具有明显优势,可以准确回答“What is the first word on the top left of the boy’s t-shirt on the left?”这样需要复杂空间推理才能准确回答的任务。3)得益于KR-M4C建立的语义关联知识,模型可以发现预测答案与OCR单词间隐含的语义关联,因此在涉及多个单词的答案时表现比只考虑空间关联的SA-M4C方法表现更好。4)面对部分场景信息确实,需要“联想”能力才能理解的复杂场景时,所有方法均表现不佳。这反映了现有场景文本视觉问答框架的性能瓶颈,有待后续更深入的研究。

4 结论
本文提出一种融合知识表征的多模态Transformer的场景文本视觉问答方法,在基线方法M4C基础上引入“空间关联”和“语义关联”两种互补的先验知识,提出知识表征增强的KR-M4C模型,实现两种知识与多模态数据的统一建模表达。本文在TextVQA和ST-VQA两个常用的场景文本视觉问答数据集上进行实验验证,相比现有最好方法取得了明显的性能提升。本文提出的知识表征增强的多模态Transformer框架具有通用性,除了应用于场景文本视觉任务,也为其他相关多模态学习任务的方法改进提供了平台。
相比现有方法,本文提出的KR-M4C方法带来了显著的性能提升,但其性能受限于外部的OCR系统的识别能力。如何在模型中引入OCR识别模块,进行端到端的联合优化是未来一个有意义的研究方向。此外,现有方法的性能与人工标注的训练样本数量紧密相关。如何突破这种标注数据制约,利用天然的弱标注数据实现模型的预训练以支撑更大更深模型的有效训练,进一步提升模型的表达能力也是值得探索的重要方向。
参考文献
-
Almazán J, Gordo A, Fornés A, Valveny E. 2014. Word spotting and recognition with embedded attributes. IEEE Transactions on Pattern Analysis and Machine Intelligence, 36(12): 2552-2566 [DOI:10.1109/TPAMI.2014.2339814]
-
Anderson P, Fernando B, Johnson M and Gould S. 2016. SPICE: semantic propositional image caption evaluation//Proceedings of the 14th European Conference on Computer Vision. Amsterdam, the Netherlands: Springer: 382-398 [DOI:10.1007/978-3-319-46454-1_24]
-
Antol S, Agrawal A, Lu J S, Mitchell M, Batra D, Zitnick C L and Parikh D. 2015. VQA: visual question answering//Proceedings of 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE: 2425-2433 [DOI:10.1109/ICCV.2015.279]
-
Ben-Younes H, Cadene R, Cord M and Thome N. 2017. MUTAN: multimodal tucker fusion for visual question answering//Proceedings of 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE: 2612-2620 [DOI:10.1109/ICCV.2017.285]
-
Biten A F, Tito R, Mafla A, Gomez L, Rusiñol M, Jawahar C V, Valveny E and Karatzas D. 2019. Scene text visual question answering//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Seoul, Koera (South): IEEE: 4291-4301 [DOI:10.1109/ICCV.2019.00439]
-
Bojanowski P, Grave E, Joulin A, Mikolov T. 2017. Enriching word vectors with subword information. Transactions of the Association for Computational Linguistics, 5: 135-146 [DOI:10.1162/tacl_a_00051]
-
Borisyuk F, Gordo A and Sivakumar V. 2018. Rosetta: large scale system for text detection and recognition in images//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. London, UK: ACM: 71-79 [DOI:10.1145/3219819.3219861]
-
Chen Y C, Li L J, Yu L C, El Kholy A, Ahmed F, Gan Z, Cheng Y and Liu J J. 2020. UNITER: universal image-text representation learning//Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer: 104-120 [DOI:10.1007/978-3-030-58577-8_7]
-
Cui Y H, Yu Z, Wang C Q, Zhao Z Z, Zhang J, Wang M and Yu J. 2021. ROSITA: enhancing vision-and-language semantic alignments via cross-and intra-modal knowledge integration//Proceedings of the 29th ACM International Conference on Multimedia. Chengdu, China: ACM: 797-806 [DOI:10.1145/3474085.3475251]
-
Deng J, Dong W, Socher R, Li L J, Li K and Li F F. 2009. ImageNet: a large-scale hierarchical image database//Proceedings of 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami, USA: IEEE: 248-255.
-
Devlin J, Chang M W, Lee K and Toutanova K. 2019. BERT: pre-training of deep bidirectional transformers for language understanding//Proceedings of 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis, USA: Association for Computational Linguistics: 4171-4186 [DOI:10.18653/v1/N19-1423]
-
Fukui A, Park D H, Yang D, Rohrbach A, Darrell T and Rohrbach M. 2016. Multimodal compact bilinear pooling for visual question answering and visual grounding//Proceedings of 2016 Conference on Empirical Methods in Natural Language Processing. Austin, USA: Association for Computational Linguistics: 457-468 [DOI:10.18653/v1/D16-1044]
-
Gao C Y, Zhu Q, Wang P, Li H, Liu Y L, Van Den Hengel A and Wu Q. 2021. Structured multimodal attentions for textvqa [EB/OL]. [2021-11-26]. https://arxiv.org/pdf/2006.00753.pdf
-
Gao D F, Li K, Wang R P, Shan S G and Chen X L. 2020. Multi-modal graph neural network for joint reasoning on vision and scene text//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE: 12746-12756 [DOI:10.1109/CVPR42600.2020.01276]
-
Gurari D, Li Q, Stangl A J, Guo A H, Lin C, Grauman K, Luo J B and Bigham J P. 2018. VizWiz grand challenge: answering visual questions from blind people//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE: 3608-3617 [DOI:10.1109/CVPR.2018.00380]
-
Han W, Huang H T and Han T. 2020. Finding the evidence: localization-aware answer prediction for text visual question answering//Proceedings of the 28th International Conference on Computational Linguistics. Barcelona, Spain: International Committee on Computational Linguistics: 3118-3131 [DOI:10.18653/v1/2020.coling-main.278]
-
Hu H, Gu J Y, Zhang Z, Dai J F and Wei Y C. 2018. Relation networks for object detection//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE: 3588-3597 [DOI:10.1109/CVPR.2018.00378]
-
Hu R H, Singh A, Darrell T and Rohrbach M. 2020. Iterative answer prediction with pointer-augmented multimodal transformers for textVQA//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE: 9989-9999 [DOI:10.1109/CVPR42600.2020.01001]
-
Jiang Y, Natarajan V, Chen X L, Rohrbach M, Batra D and Parikh D. 2018. Pythia v0.1: the winning entry to the VQA challenge 2018 [EB/OL]. [2021-11-28]. https://arxiv.org/pdf/1807.09956.pdf
-
Kant Y, Batra D, Anderson P, Schwing A, Parikh D, Lu J S and Agrawal H. 2020. Spatially aware multimodal transformers for textVQA//Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer: 715-732 [DOI:10.1007/978-3-030-58545-7_41]
-
Karatzas D, Gomez-Bigorda L, Nicolaou A, Ghosh S, Bagdanov A, Iwamura M, Matas J, Neumann L, Chandrasekhar V R, Lu S J, Shafait F, Uchida S and Valveny E. 2015. ICDAR 2015 competition on robust reading//Proceedings of the 13th International Conference on Document Analysis and Recognition. Tunis, Tunisia: IEEE: 1156-1160 [DOI:10.1109/ICDAR.2015.7333942]
-
Karpathy A and Li F F. 2015. Deep visual-semantic alignments for generating image descriptions//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, USA: IEEE: 3128-3137 [DOI:10.1109/CVPR.2015.7298932]
-
Kim J H, Jun J and Zhang B T. 2018. Bilinear attention networks [EB/OL]. [2021-05-21]. https://arxiv.org/pdf/1805.07932.pdf
-
Kim J H, On K W, Lim W, Kim J, Ha J W and Zhang B T. 2017. Hadamard product for low-rank bilinear pooling//Proceedings of the 5th International Conference on Learning Representations. Toulon, France: OpenReview
-
Krishna R, Zhu Y K, Groth O, Johnson J, Hata K, Kravitz J, Chen S, Kalantidis Y, Li L J, Shamma D A, Bernstein M S, Li F F. 2017. Visual genome: connecting language and vision using crowdsourced dense image annotations. International Journal of Computer Vision, 123(1): 32-73 [DOI:10.1007/s11263-016-0981-7]
-
Kuznetsova A, Rom H, Alldrin N, Uijlings J, Krasin I, Pont-Tuset J, Kamali S, Popov S, Malloci M, Kolesnikov A, Duerig T, Ferrari V. 2020. The open images dataset v4. International Journal of Computer Vision, 128(7): 1956-1981 [DOI:10.1007/s11263-020-01316-z]
-
Lee K H, Chen X, Hua G, Hu H D and He X D. 2018. Stacked cross attention for image-text matching//Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer: 212-228 [DOI:10.1007/978-3-030-01225-0_13]
-
Liu F, Xu G H, Wu Q, Du Q, Jia W and Tan M K. 2020. Cascade reasoning network for text-based visual question answering//Proceedings of the 28th ACM International Conference on Multimedia. Seattle, USA: ACM: 4060-4069 [DOI:10.1145/3394171.3413924]
-
Lu J S, Batra D, Parikh D and Lee S. 2019. ViLBERT: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks [EB/OL]. [2021-08-06]. https://arxiv.org/pdf/1908.02265.pdf
-
Mishra A, Alahari K and Jawahar C V. 2013. Image retrieval using textual cues//Proceedings of 2013 IEEE International Conference on Computer Vision. Sydney, Australia: IEEE: 3040-3047 [DOI:10.1109/ICCV.2013.378]
-
Paszke A, Gross S, Massa F, Lerer A, Bradbury J, Chanan G, Killeen T, Lin Z M, Gimelshein N, Antiga L, Desmaison A, Köpf A, Yang E, DeVito Z, Raison M, Tejani A, Chilamkurthy S, Steiner B, Fang L, Bai J J and Chintala S. 2019. PyTorch: an imperative style, high-performance deep learning library//Proceedings of the 33rd International Conference on Neural Information Processing Systems. Vancouver, Canada: NIPS: 8026-8037
-
Pennington J, Socher R and Manning C D. 2014. GloVe: global vectors for word representation//Proceedings of 2014 conference on Empirical Methods in Natural Language Processing. Doha, Qatar: ACL: 1532-1543 [DOI:10.3115/v1/D14-1162]
-
Ren S Q, He K M, Girshick R and Sun J. 2015. Faster R-CNN: towards real-time object detection with region proposal networks//Proceedings of the 28th International Conference on Neural Information Processing Systems. Montreal, Canada: NIPS: 91-99
-
Singh A, Natarajan V, Shah M, Jiang Y, Chen X L, Batra D, Parikh D and Rohrbach M. 2019. Towards VQA models that can read//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE: 8317-8326 [DOI:10.1109/CVPR.2019.00851]
-
Tan H and Bansal M. 2019. LXMERT: learning cross-modality encoder representations from transformers//Proceedings of 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. Hong Kong, China: Association for Computational Linguistics: 5100-5111 [DOI:10.18653/v1/D19-1514]
-
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez A N, Kaiser L and Polosukhin I. 2017. Attention is all you need//Proceedings of the 31st International Conference on Neural Information Processing Systems. Long Beach, USA: NIPS: 6000-6010
-
Veit A, Matera T, Neumann L, Matas J and Belongie S. 2016. COCO-Text: dataset and benchmark for text detection and recognition in natural images [EB/OL]. [2021-01-26]. https://arxiv.org/pdf/1601.07140.pdf
-
Xie S N, Girshick R, Dollár P, Tu Z W and He K M. 2017. Aggregated residual transformations for deep neural networks//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE: 5987-5995 [DOI:10.1109/CVPR.2017.634]
-
Yao T, Pan Y W, Li Y H and Mei T. 2018. Exploring visual relationship for image captioning//Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer: 711-727 [DOI:10.1007/978-3-030-01264-9_42]
-
Yu L C, Tan H, Bansal M and Berg T L. 2017a. A joint speaker-listener-reinforcer model for referring expressions//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE: 3521-3529 [DOI:10.1109/CVPR.2017.375]
-
Yu Z, Yu J, Cui Y H, Tao D C and Tian Q. 2019. Deep modular co-attention networks for visual question answering//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE: 6274-6283 [DOI:10.1109/CVPR.2019.00644]
-
Yu Z, Yu J, Fan J P and Tao D C. 2017b. Multi-modal factorized bilinear pooling with co-attention learning for visual question answering//Proceedings of 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE: 1839-1848 [DOI:10.1109/ICCV.2017.202]
-
Zhou B L, Tian Y D, Sukhbaatar S, Szlam A and Fergus R. 2015. Simple baseline for visual question answering [EB/OL]. [2021-12-07]. https://arxiv.org/pdf/1512.02167.pdf


