|
|
|
发布时间: 2022-09-16 |
目标智能检测 |
|
|
|


|
收稿日期: 2022-02-16; 修回日期: 2022-04-22; 预印本日期: 2022-04-29
基金项目: 科技创新2030-“新一代人工智能”重大项目(2018AAA0100400);国家自然科学基金项目(U21B2013,61971277)
作者简介:
彭嘉淇,2001年生,男,本科生,主要研究方向为计算机视觉和机器学习。E-mail: stein_gate@sjtu.edu.cn
王涛,男,硕士研究生,主要研究方向为计算机视觉和机器学习。E-mail: wang_tao1111@sjtu.edu.cn 陈柯安,男,硕士研究生,主要研究方向为计算机视觉和机器学习。E-mail: ckadashuaige@sjtu.edu.cn 林巍峣,通信作者,男,教授,主要研究方向为计算机视觉、视觉监控、视频行为理解、视频及语义信息编码。E-mail: wylin@sjtu.edu.cn *通信作者: 林巍峣 wylin@sjtu.edu.cn
中图法分类号: TP391.4
文献标识码: A
文章编号: 1006-8961(2022)09-2749-12
|
摘要
目的 视频多目标跟踪(multiple object tracking,MOT)是计算机视觉中的一项重要任务,现有研究分别针对目标检测和目标关联部分进行改进,均忽视了多目标跟踪中的不一致问题。不一致问题主要包括3方面,即目标检测框中心与身份特征中心不一致、帧间目标响应不一致以及训练测试过程中相似度度量方式不一致。为了解决上述不一致问题,本文提出一种基于时空一致性的多目标跟踪方法,以提升跟踪的准确度。方法 从空间、时间以及特征维度对上述不一致性进行修正。对于目标检测框中心与身份特征中心不一致,针对每个目标检测框中心到特征中心之间的空间差异,在偏移后的位置上提取目标的ReID(re-identification)特征;对帧间响应不一致,使用空间相关计算相邻帧之间的运动偏移信息,基于该偏移信息对前一帧的目标响应进行变换后得到帧间一致性响应信息,然后对目标响应进行增强;对训练和测试过程中的相似度度量不一致,提出特征正交损失函数,在训练时考虑目标两两之间的相似关系。结果 在3个数据集上与现有方法进行比较。在MOT17、MOT20和Hieve数据集中,MOTA(multiple object tracking accuracy)值分别为71.2%、60.2%和36.1%,相比改进前的FairMOT算法分别提高了1.6%、3.2%和1.1%。与大多数其他现有方法对比,本文方法的MT(mostly tracked)比例更高,ML(mostly lost)比例更低,跟踪的整体性能更好。同时,在MOT17数据集中进行对比实验验证融合算法的有效性,结果表明提出的方法显著改善了多目标跟踪中的不一致问题。结论 本文提出的一致性跟踪方法,使特征在时间、空间以及训练测试中达成了更好的一致性,使多目标跟踪结果更加准确。
关键词
多目标跟踪(MOT); 一致性; 特征提取位置偏移; 特征正交损失; 帧间增强
Abstract
Objective Video-based multiple object tracking is one of the essential tasks in computer vision like automatic driving and intelligent video surveillance system. Most of the multiple object tracking methods tend to obtain object detection results first. The integrated strategies are used to link detection bounding boxes and form object trajectories. Current object detection contexts have been developing recently. But, the challenging inconsistency issues are required to be resolved in multiple object tracking, which affected the multi-objects tracking accuracy. The multi-objects tracking inconsistency can be classified into three types as mentioned below: 1) the inconsistency between the centers of the object bounding boxes and those object identity features. Many multiple object tracking methods are extracted the object re-identification(ReID) features at the object bounding boxes centers and these features are used to in associate with objects. However, those oriented ReID features are incapable to reflect the appearance of objects accurately due to the occlusion. The offsets are appeared between the best ReID feature extraction positions and bounding box centers. Current feature extraction strategy will lead to the spatial consistency problem. 2) The inconsistency of the object center response between consecutive frames. Some objects can be detected and tracked in the contexted frames due to the occlusion in videos. It causes consecutive frames loss and the inconsistency between the object-center-responsed heatmaps of two consecutive frames. 3) The inconsistency of the similarity assessment in the training process and testing process. Most of association step is considered as a classification problem and the cross entropy loss is used to train the model while the inter-object relations are ignored in the testing process. The feature cosine similarities of each pair of objects are used to associate them. To improve the accuracy of tracking, we facilitate a multiple object tracking method based on consistency optimization. Method These inconsistencies issues are validated based on spatial, temporal and featured scales. In view of the inconsistency between the centers of the object detection bounding boxes and the identity features, we predict the offsets from the centers of the detection bounding boxes to the feature centers for each object. To predict the best ReID feature extraction positions, we use the object centers and the offsets as well. We extract the ReID features of objects at those predicted positions and use these features to reflect objects. In view of the inconsistency of the response between frames, the spatial correlation module is used to calculate the offset information between adjacent frames. Based on the offset information, the object center response of the previous frame is transformed by deformable convolution to obtain the inter-frame consistency response information, which is enhanced to the current frame. To resolve the inconsistency of similarity measures in training and test process, we develop a feature orthogonal loss function, which considers the similarity relationship between the two objects during training. To detect and track objects, we integrate these three improved consistency results with FairMOT method. Result The performance of our method is compared to existing methods on three datasets. The comparative results are illustrated as following: 1) our multiple object tracking accuracy(MOTA) value is 71.2% on the MOT17 dataset, which is increased by 1.6% in comparison with the FairMOT method without consistency improvement; 2) the MOTA value is 60.2% on the MOT20 dataset, which is increased by 3.2%; 3) the MOTA value is 36.1% on the Hieve dataset, which is increased by 1.1%. At the same time, we conduct ablation studies on MOT17 dataset to verify the effectiveness of different components in our method, which shows that the proposed method improves the consistency in multiple objects tracking significantly. In ablation studies, we find that the identity switch numbers are decreased via the added ReID feature extraction position offsets and the feature orthogonal loss function. The model-based extraction position offsets can get the object appearance features at the right positions and the feature orthogonal loss function can learn the object appearance features in the right way. We also visualize the predicted ReID feature extraction positions and object bounding boxes centers, and the visualization results show that our predicted positions are closer to the object appearance features rather than the physical centers, which is feasible to the extraction position offsets. Conclusion Our multiple objects tracking method can achieve the spatio-temporal consistency of object features better in training and testing, which makes the model track objects more accurately.
Key words
multiple object tracking (MOT); consistency; feature extraction position offset; feature orthogonal loss; inter-frame enhancement
0 引言
多目标跟踪(multiple object tracking,MOT)任务的主要目标是对视频中多个感兴趣目标定位的同时,维持目标各自的身份识别号(identification,ID)并记录连续的运动轨迹。多目标跟踪在诸多领域都有广泛应用。例如,在自动驾驶中可以辅助车辆代替人员感知周围其他车辆和人员的运动情况,做出合理决策;在安防监控中可以辅助提取视频中可疑人员的身份和去向信息,节约人力。视频多目标跟踪场景的复杂性以及目标间的频繁遮挡,给准确的多目标跟踪带来挑战。现有多目标跟踪方法结果主要存在两类错误,即目标漏检和目标身份识别错误。目标漏检指某一帧目标没有检测到,导致轨迹中断。目标身份识别错误指同一目标在不同帧中识别为不同目标,导致身份跳变。在现有视频多目标跟踪方法中,通用做法为使用检测器获得单帧目标的检测框,然后利用前后帧同一目标相似度,在时序上对检测框进行跨帧关联,形成多个目标的轨迹。针对目标漏检和身份识别错误问题,现有方法基于基本框架采取了多种改进策略,从目标检测、目标关联以及两者联合的角度尝试解决。其中,一类方法关注于检测性能的改善,通过更加准确的检测器获得位置更加准确的目标检测框,作为目标关联步骤的输入。例如,DeepSORT(deep simple online and realtime tracking)(Wojke等,2017)使用比Faster R-CNN(region convolutional neural network)(Ren等,2015)效果更好的检测器POI(person of interest)(Yu等,2016)获得单帧检测结果,再进行目标间的关联。另一类方法关注于设计更加准确合理的目标关联机制。例如,使用图网络或复杂的全局匹配策略对目标进行更加准确的关联。其他研究则将目标检测和关联联合训练,增加匹配和关联之间的特征耦合关系,对两者的效果同时进行提升。例如,FairMOT(Zhang等,2020)采用无锚框的检测器CenterNet(Zhou等,2020)并增加一个ReID(re-identification)分支获取目标的外观特征,将外观特征与检测器特征联合训练。
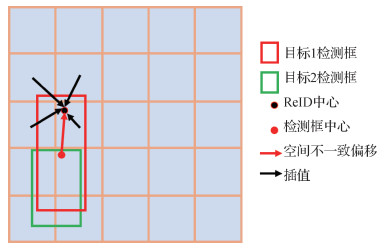
然而,尽管现有检测器尝试从目标检测、目标关联以及两者联合等多角度对多目标跟踪进行改进,特别是FairMOT,既使用了性能更强的检测器CenterNet,又将关联特征和检测部分进行联合训练,但是忽视了多目标跟踪中广泛存在的不一致性问题。这些不一致性体现在以下方面:1)空间不一致性。指ReID特征中心与目标检测框中心不一致。在将无锚框的检测器添加ReID特征分支进行跟踪的方法中,由于输出特征图上的每个位置代表一个潜在目标,因此在提取目标的ReID特征时,最直接的做法是根据目标的中心位置在ReID特征图的对应位置提取特征向量。由于目标中心位置由热图进行监督训练,而热图生成时使用的中心往往直接使用目标检测框的中心,从而出现目标特征与物理中心不一致问题。即在密集场景下目标检测框中心可能会落在周围其他目标对应的像素上,导致该处ReID特征包含大量不相干目标信息而不是对应目标信息,不能很好表示该目标外观特征。ReID特征提取的最佳中心与该目标检测框中心不一致,不能将两者混为一谈。如图 1(a)所示。2)时间不一致性。指相邻帧目标中心响应不一致。现有方法大多仅对单帧图像进行特征提取和检测,未使用邻帧的目标信息,出现目标中心响应时序不一致问题。即某些场景能够准确检测上一帧中的物体,但是到下一帧由于遮挡或模糊,物体无法检测,导致前后帧的物体召回情况不一致,使目标间无法一对一正确匹配。如图 1(b)所示。一致的目标响应是相邻帧均出现的同一目标均能检测到。3)特征相似度度量在训练与测试中不一致。如图 1(c)所示,现有方法在训练过程中往往将目标检测框进行分类,使用交叉熵损失函数对目标类别进行监督,同一轨迹的目标检测框分到同一类,每个目标是单独考虑的;但是在测试时,却需要在相邻帧目标特征上两两交互计算余弦相似度,根据相似度进行最优匹配。这两者之间存在巨大差异,导致测试与训练时模型机制不一致,使得性能下降。


为了解决现有多目标跟踪方法存在的不一致性问题,本文提出基于时空一致性的改进算法,并在FairMOT(Zhang等,2020)上验证。本文方法在抽取ReID特征时预测ReID中心与检测框中心的偏移,称为特征提取位置偏移,然后根据该偏移和检测框中心计算最佳ReID特征抽取中心,以此解决空间不一致问题,提升ReID特征对目标的表达能力。随后,在相邻帧之间计算运动偏移信息,根据偏移信息用上一帧的响应信息对下一帧的响应进行增强,解决时间不一致问题。最后,通过设计特征正交损失函数,在训练时考虑不同身份目标之间的相似度关系,在特征空间对不同目标特征进行正交约束,解决训练和测试中的相似度度量不一致问题。在MOT17和Hieve(Lin等,2021)数据集上进行验证,结果表明本文方法能够较好地解决这些不一致问题,对多目标跟踪的性能提升具有显著效果。
1 多目标跟踪方法
根据目标检测和目标关联的耦合程度,可以将现有多目标跟踪方法分为3类,即先检测后关联的方法、检测跟踪联合的方法和无关联的方法。
1.1 先检测后关联的方法
先检测后跟踪的方法使用独立的检测器对视频的每一帧图像进行目标检测,获取每一帧中的目标检测框,然后使用独立的关联模块对检测框依据外观、运动等相似度进行关联,连接成目标轨迹。SORT(simple online and realtime tracking)(Bewley等,2016)是此类方法中的经典,利用检测器Faster R-CNN(Ren等,2015)对每一帧进行检测,然后使用卡尔曼滤波预测目标在后一帧的位置,根据预测位置和实际检测框位置计算交并比作为轨迹与检测框之间的相似度,并进行二分图匹配,获得目标关联结果。DeepSORT(Wojke等,2017)在SORT上进行两方面改进,一是将Faster R-CNN替换成检测效果更好的检测器; 二是在目标相似度计算中引入使用深度网络提取的外观特征,提升了目标关联的准确度。DMAN(dual matching attention networks)(Zhu等,2018)在目标关联中的特征提取时使用空间注意力机制,使网络更加关注那些区分性较强区域的特征,使目标能够更准确地识别身份。GNMOT(graph networks for multiple object tracking)(Li等,2020)使用两路独立的图卷积网络对轨迹的外观特征和运动特征进行逐帧更新,利用得到的外观特征和运动特征计算融合相似度,用于后续的匹配过程。TubeTK(Pang等,2020)在多帧特征图上预测一个短的轨迹,利用短轨迹特征进行关联获得目标长轨迹。Ctracker(chained-tracker)(Peng等,2020)使用相邻两帧目标形成的目标对提取特征进行匹配关联。INAF-GNN(intra-frame relationship modeling and graph neural networks)(朱姝姝等,2022)使用图网络对帧内物体关系进行建模,使用自注意力机制整合局部特征和全局跟踪特征,实现更准确的关联。此外,获取更准确的ReID特征(如使用通道和空间注意力机制(Qin等,2021))以及孪生网络(高博,2021)对特征提取进行改进,也有助于增加关联的匹配准确度,从而提升跟踪效果。
1.2 检测跟踪联合的方法
先检测后关联的方法对目标检测和关联使用两个独立的网络进行。一方面特征提取等大量重复计算导致速度下降; 另一方面检测和关联分开学习使梯度无法共享,两者之间没有相互促进作用。因而一些方法尝试将目标检测和目标关联方法联合到一个网络中进行训练。如JDE(jointly learns the detector and embedding model)(Wang等,2020)使用标准的区域生成网络(region proposal network,RPN)作为检测器时,另外增加一路外观特征提取分支,在检测损失函数的基础上增加一个分类损失函数,基于目标的外观特征对目标的所属身份进行监督。FairMOT(Zhang等,2020)考虑到基于锚框的算法中,对目标进行外观特征提取时引入了大量无关的背景信息和其他目标的信息,因此使用无锚框的检测器, 外观特征则是在对应目标中心点进行提取,从而消除部分无关背景信息。此外,将分割等任务引入多目标跟踪(Yang等,2019)以及与检测关联联合学习也能有效提升多目标跟踪效果。
1.3 无关联的方法
由于目标关联准确性受相似度度量和关联策略的影响较大,因此有的方法将目标关联步骤省略,直接使用历史轨迹在当前帧预测位置。如Tracktor(Bergmann等,2019)利用Faster R-CNN中的二阶段网络,输入上一帧的目标检测框,一对一获得其在当前帧位置,省略了关联步骤。TrackFormer(Meinhardt等,2022)在基于Transformer的检测器DETR(detection transformer)(Carion等,2020)上进行修改,将上一帧目标作为新一帧的query,将当前帧图像的特征作为key,利用Transformer的编解码过程得到的这些key查询在新的一帧中的位置。TransCenter(Xu等,2022)在利用上一帧的目标中心提取查询特征后,在后一帧的图像特征上利用Transformer查询得到新的中心位置以及目标检测框的宽和高。
以上3类方法对多目标跟踪中的目标检测和目标关联进行了一系列改进,但对多目标跟踪中普遍存在的不一致性问题缺少足够的关注和改进。本文将基于FairMOT分别对目标关联特征与检测框中心不一致、训练测试相似度度量不一致以及目标中心响应时序不一致进行改进。
2 方法
2.1 方法整体框架
本文提出的时空一致性多目标跟踪方法结构如图 2所示,主要基于多目标跟踪方法FairMOT进行改进。
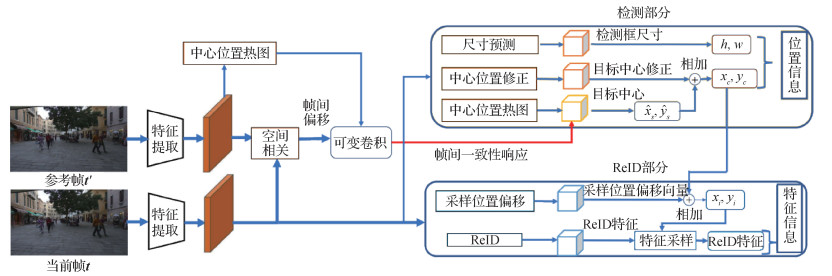
给定连续视频帧序列
目标检测包含heatmap、center offset和box size共3个分支。heatmap分支用于预测特征图上存在目标的概率,物体中心值预期为1,邻近值随着与目标中心的距离增大呈指数衰减。先对heatmap做非极大值抑制,找出一定量概率最大的位置,初步预测为目标的中心位置
目标关联包含ReID分支和extract offset分支两部分。ReID分支用于计算全局的ReID特征图,extract offset分支则预测目标ReID特征提取位置与目标检测框中心之间的偏移,目的是修正目标特征中心及检测框中心上的不一致性; extract offset分支得到的偏移和ReID分支以及检测部分得到的目标中心位置一起用于提取目标的ReID特征。关联时,使用当前帧目标与历史轨迹间的ReID特征相似度和基于卡尔曼滤波得到的轨迹预测位置与当前帧实际位置之间的距离相似度对目标和轨迹进行关联。
邻帧增强分支用于帧间一致性信息增强,修正相邻帧之间目标中心响应不一致的情况。本文方法根据相邻帧的特征图计算空间相关信息,预测两帧之间的偏移情况,然后使用可变形卷积基于偏移对上一帧的目标响应做时空对齐,得到与当前帧相关的响应信息,对当前帧的目标响应进行增强。
训练时,除了使用检测器中的损失函数,考虑到使用交叉熵损失进行分类训练与测试时目标关联步骤中的两两相似度计算过程不一致问题,本文将FairMOT中用于关联的交叉熵损失替换为特征正交损失,对训练集中的每个身份都学习一个模板特征向量,然后对目标和对应身份两两之间做损失计算,保持与测试时相似度计算的一致性。
2.2 基于ReID特征提取位置偏移的空间不一致修正
如图 3所示,由于目标的检测框中心可能落在其他目标上,直接采用FairMOT中从检测框中心抽取ReID特征的方式会使得该特征包含过多干扰信息,无法准确表征该目标。因此,基于目标的ReID中心与检测框中心之间存在的不一致情况,本文模型使用extract offset分支预测两者之间的偏移。在该分支中,对特征图上的每个位置,以该位置为默认中心的目标分别生成
具体实现时,假设检测分支得到的当前帧第
2.3 基于邻帧响应增强的时间不一致修正
为了充分利用邻帧间的一致性信息,首先将当前帧特征图与上一帧特征图进行邻帧相似度计算,得到大小为(
具体实现时,假设经过特征提取网络后得到当前帧特征图
2.4 基于特征正交损失的相似度不一致修正
一些多目标跟踪方法采用的交叉熵损失函数本质上是三元损失的简化,优化的目标是使正负样本差距
| $ L_{\text {identity }}=\sum\limits_i \max \left(0, \boldsymbol{f}^{\mathrm{T}} \boldsymbol{f}_i^{-}-\boldsymbol{f}^{\mathrm{T}} \boldsymbol{f}_i^{+}\right) $ | (1) |
平滑化该损失函数,可得
| $ \begin{gathered} L_{\text {identity }}=\log \left(1+\sum\limits_i \exp \left(\boldsymbol{f}^{\mathrm{T}} \boldsymbol{f}_i^{-}-\boldsymbol{f}^{\mathrm{T}} \boldsymbol{f}_i^{+}\right)\right)= \\ -\log \left(\frac{\exp \left(\boldsymbol{f}^{\mathrm{T}} \boldsymbol{f}_i^{+}\right)}{\exp \left(\boldsymbol{f}^{\mathrm{T}} \boldsymbol{f}_i^{+}\right)+\sum\limits_i \exp \left(\boldsymbol{f}^{\mathrm{T}} \boldsymbol{f}_i^{-}\right)}\right) \end{gathered} $ | (2) |
式中,
但是,在测试时采用余弦相似度度量前后帧目标的相似程度。目标训练和测试中计算相似度方式的不一致导致模型性能下降。因此本文提出在训练中采用与测试时相似度计算方式相近的特征正交损失,并为每个类别都设置一个可学习的类模板。为此,对训练集中的每个轨迹
| $ p=\sigma\left(\boldsymbol{f}^{i \mathrm{T}} \boldsymbol{M}^j\right)= \begin{cases}1 & i=j \\ 0 & i \neq j\end{cases} $ | (3) |
类似于二分类中的交叉熵损失,损失函数为
| $ L_{\text {identity }}= \begin{cases}-\log (p) & i=j \\ -\log (1-p) & i \neq j\end{cases} $ | (4) |
由于多目标跟踪中单帧中正样本只有一个,其余均为负样本。针对类别不均衡问题,对上述公式进行改进,得到最终的目标特征正交损失函数。具体为
| $ \begin{gathered} L_{\text {identity }}= \\ -\frac{1}{N} \sum\limits_i \sum\limits_j \begin{cases}(1-\sigma(p))^\gamma \log (\sigma(p)) & i=j \\ (\sigma(p))^\gamma \log (1-\sigma(p)) & i \neq j\end{cases} \end{gathered} $ | (5) |
式中,
3 实验
3.1 算法实现
算法基于FairMOT实现,在MS COCO(Microsoft common objects in context)数据集上预训练作为初始化并沿用FairMOT的训练方案。初始学习率设为0.000 1。在MOT17数据集和Hieve数据集上,图像均等比缩放至短边为608像素,batch size设置为4,总共训练30个周期,在20个周期后学习率下降为原来的0.1倍。
3.2 数据集与评价指标
实验主要在多目标跟踪数据集MOT17、MOT20和Hieve上进行,并与现有方法进行效果对比。
3.2.1 MOT17数据集
MOT17数据集是2017年MOT Challenge多目标检测跟踪方法公开的基准数据集,随后的MOT算法基本都会给出在MOT17上的性能表现。
MOT17主要标注目标为移动的行人,拥有丰富的场景画面、不同拍摄视角和相机运动,也包含不同天气状况的视频。MOT17数据集共14个视频序列,每个视频平均长度约800帧,其中7个为带有标注信息的训练集,其他7个为测试集,每个训练集提供SDP、DPM和Faster R-CNN共3种检测器的检测结果,标注超过1 300个目标,约300 000个检测框。
3.2.2 Hieve数据集
Hieve(Lin等,2021)数据集是2020年提出的以人为中心的复杂事件的数据集,包含人群的骨架、行为与跟踪标注。Hieve在YouTube收集了32个异常场景(如监狱)和异常事件(如打斗、地震)的视频序列,大多超过900帧,总长度33 min 18 s,分为19个训练集视频和13个测试集视频。在跟踪方面,Hieve中包含2 687个目标轨迹,平均轨迹长度大于480帧,2维检测框个数超过130万。
3.2.3 评测指标
在MOT任务中,通过检测框建立真实轨迹与预测轨迹之间的关系。使用目标交并比(intersection over union, IoU)作为相似性度量,阈值设定为0.5。当预测轨迹中的某一帧对应的检测框与真实轨迹中该帧对应的检测框之间的目标交并比>0.5时,则认为这一物体在该帧得到了准确跟踪。预测轨迹与真实轨迹之间的一一对应关系是由二分图最大匹配获得的,目标是使预测轨迹与真实轨迹间的IoU尽可能大。通过这种方式确定预测轨迹与真实轨迹间的一一对应关系后,再通过各种指标衡量跟踪的准确度。MOT任务中的评测指标主要包括整体评价指标MOTA(multiple object tracking accuracy)、准确率指标MOTP(multiple object tracking precision)、漏检指标FN(false negatives)、误检指标FP(false positives)、身份跳变指标IDs(identity switches)、80%帧跟踪正确轨迹比例MT(mostly tracked)和80%帧跟丢轨迹比例ML(mostly tracked)。其中,MOTA综合了FN、FP和IDs数据。
3.3 实验结果
3.3.1 各改进点的对比实验
1) 特征提取方式。在检测部分得到的目标检测框中心加上提取位置偏移预测分支得到的偏移后,可以得到ReID特征提取位置。由于得到的位置为浮点数,而ReID特征图上的位置均为整数,因此在提取时需要进行近似。实验分别对最近邻提取、置信度最高处提取、双线性插值提取和直接使用检测框中心位置提取进行对比。最近邻提取表示直接在与提取位置最近的整数位置提取特征位置。置信度提取表示在提取位置周围选取热图响应值最大的整数位置处的ReID特征作为目标ReID特征。双线性插值提取即第2节的提取方法。实验中损失函数均使用FairMOT中的原始交叉熵损失函数。实验结果如表 1所示。可以看出,使用双线性插值提取方式效果最佳,相比不采用特征提取位置偏移的方法,在MOTA上有0.7%的提升,同时ID切换次数也有非常明显的下降,说明通过提取位置偏移后提取的特征相比原来在检测框中心提取的特征能够更好地表征目标的外观信息。
表 1
偏移后不同特征提取方法对跟踪效果的影响
Table 1
The effect of different feature extraction method on tracking results
| 特征提取方式 | MOTA/% | MT | ML | IDs |
| 无偏移 | 69.6 | 945 | 462 | 4 572 |
| 最近邻 | 70.2 | 924 | 471 | 4 059 |
| 置信度最高 | 70.3 | 939 | 498 | 3 942 |
| 双线性插值 | 70.3 | 939 | 501 | 3 759 |
2) 帧间相关计算。在帧间信息增强时,帧间位置相似度的计算直接影响最终效果。因此实验中分别采用单点余弦相关和本文提出的空间相关方法进行相似度计算,并与不进行帧间增强的方法进行对比。其中,单点余弦相关直接使用当前帧与上一帧同一位置的特征向量进行余弦相似度计算,得到相似度矩阵。实验不进行ReID特征提取和损失函数修改。实验结果如表 2所示。可以看出,使用空间相关相似度计算进行帧间一致性响应增强带来的效果提升最大,相比不使用帧间增强在MOTA指标上提升0.9%,而直接使用单点余弦相关则几乎没有提升。主要原因是单点余弦相关只利用了对应位置的相似度信息,导致两帧位移信息估计不准,使历史响应信息经过可变卷积后与当前帧的响应没有得到良好对齐。而空间相关则提取了更多空间邻域的信息,使两帧之间的位移信息预测更加准确,有助于可变卷积准确提取帧间一致性响应信息。
表 2
帧间不同相关计算方式对跟踪效果的影响
Table 2
The effect of different relation calculation method between two frames
| 相关度计算 | MOTA/% | MT | ML | IDs |
| 无增强 | 69.6 | 40.1 | 19.6 | 4 572 |
| 单点余弦相关 | 69.6 | 40.4 | 18.7 | 7 179 |
| 空间相关 | 70.5 | 41.5 | 21.1 | 4 230 |
此外,对不同损失函数对跟踪效果的影响进行实验,将FairMOT中的交叉熵损失函数分别替换为focal loss和本文提出的特征交叉损失,实验结果如表 3所示。可以看出,focal loss相比交叉熵损失有0.6%的提升,但大幅低于本文提出的特征交叉损失。特征交叉损失能够取得最好效果,主要得益于训练时在损失函数计算中考虑了目标两两之间的相似度信息,与测试时的相似度度量机制比较一致,保证属于同一目标的特征相比不同目标间的特征更相似。
表 3
不同关联损失函数对跟踪效果的影响
Table 3
The effect of different feature extraction method on tracking results
| 损失函数 | MOTA/% | MT | ML | IDs |
| 交叉熵损失 | 69.6 | 40.1 | 19.2 | 4 572 |
| focal loss | 70.2 | 39.9 | 20.1 | 4 704 |
| 特征正交损失 | 70.6 | 42.3 | 18.0 | 7 488 |
为了验证本文提出的3种一致性改进对跟踪效果提升的作用以及它们之间的相互影响,将ReID特征位置偏移提取、特征正交损失和帧间一致性响应增强分别与基准方法FairMOT组合,进行跟踪效果对比实验。根据表 1—表 3的结果,实验使用双线性插值作为ReID特征提取方式,特征正交损失作为损失函数,空间相关作为帧间相似度计算方式。实验结果如表 4所示。本文方法最终得到的MOTA检测结果为71.2%,检测速度为15帧/s。
表 4
不同模块对跟踪效果的影响
Table 4
The effect of different components on tracking results
| ReID位置偏移提取 | 特征交叉损失 | 帧间一致性响应增强 | MOTA/% | IDs |
| - | - | - | 69.6 | 4 572 |
| √ | - | - | 70.3 | 3 759 |
| - | √ | - | 70.6 | 7 488 |
| - | - | √ | 70.5 | 4 230 |
| √ | √ | - | 70.9 | 7 275 |
| - | √ | √ | 70.8 | 7 461 |
| √ | √ | √ | 71.2 | 7 509 |
| 注:“√”表示使用该模块,“-”表示未使用该模块。 | ||||
从表 4可以看出,1)单独使用ReID位置偏移提取、特征正交损失函数和帧间一致性响应增强均能有效提升多目标跟踪的指标,叠加使用能够实现更好效果。2)相比不采用任何不一致消除策略的多目标跟踪方法,本文提出的一致性多目标跟踪方法的跟踪效果明显提升,MOTA指标从69.6%提升至71.2%,特别是在密集场景下,MOTA平均有3%的提升。如在MOT17-07拥挤的街道情形下,MOTA从52.7%提升至58.2%。3)空间一致性和帧间一致性改进均能有效降低目标的身份跳变次数。因为ReID特征偏移提取能够使目标获得更能代表自身外观的特征,而帧间一致性响应增强有助于召回更多的目标检测框供匹配,使匹配丢失情况减少。
3.3.2 与现有方法对比
为验证本文提出的一致性多目标跟踪方法的效果,与现有方法在MOT17数据集上进行对比,结果如表 5所示。可以看出,本文方法在MOTA指标上超过大部分现有方法。值得注意的是,尽管Center-Track等方法的IDs低于本文方法,但这些方法的MT较低,ML较高,其正确召回的目标框数量显著低于本文方法,导致IDs占据总匹配数的比例较大,因此匹配错误比例高于本文方法,这从较低的MOTA指标中亦可看出,说明它们的跟踪效果劣于本文方法。
表 5
本文方法与其他方法在MOT17数据集上的效果对比
Table 5
The tracking performance comparison between our method and other methods on MOT17 dataset
| 方法 | MOTA/% | MT | ML | IDs |
| CenterTrack(Zhou等,2020) | 67.8 | 34.6 | 24.6 | 3 039 |
| CTracker(Peng等,2020) | 66.6 | 32.2 | 24.2 | 5 529 |
| Tracktor(Bergmann等,2019) | 56.3 | 21.1 | 35.3 | 1 987 |
| FairMOT(Zhang等,2021) | 69.6 | 40.1 | 19.6 | 4 572 |
| TubeTK(Pang等,2020) | 63.0 | 31.2 | 19.9 | 4 137 |
| TransCenter(Xu等,2022) | 70.0 | 38.9 | 20.4 | 4 647 |
| Trades(Wu等,2021) | 69.1 | 36.4 | 21.5 | 3 555 |
| QuasiDense(Pang等,2021) | 68.7 | 40.6 | 21.9 | 3 378 |
| GSDT(Wang等,2021) | 66.2 | 40.8 | 18.3 | 3 318 |
| 本文 | 71.2 | 43.1 | 18.0 | 7 509 |
为了验证本文方法的通用性和泛化性能,在目标更加稠密的MOT20和Hieve数据集上进行对比实验。这两个数据集中目标数量更多更密集,目标遮挡情况更严重,因此由特征提取和目标丢失等带来的不一致现象也更加明显。实验结果如表 6和表 7所示。可以发现,本文方法在这两个数据集上均取得了超过大部分现有方法的跟踪效果,并且带来的相对提升比在MOT17数据集上更加明显,特别是在Hieve数据集上,本文方法在所有指标上均取得最好效果,在召回更多目标的同时,有效减少了目标间关联错误的次数,说明本文方法能够有效解决密集场景中的目标ReID特征提取、帧间响应以及相似度度量不一致问题,从而提升跟踪效果。
表 6
本文方法与其他方法在MOT20数据集上的效果对比
Table 6
The tracking performance comparison between our method and other methods on MOT20 dataset
| 方法 | MOTA/% | MT | ML | IDs |
| FairMOT(Zhang等,2021) | 57.0 | 43.2 | 9.3 | 4 419 |
| TransCenter(Xu等,2022) | 58.5 | 40.2 | 12.3 | 4 695 |
| Tracktor(Bergmann等,2019) | 52.6 | 24.3 | 22.0 | 4 374 |
| SORT(Bewley等,2016) | 42.7 | 13.8 | 21.7 | 4 470 |
| TransCenter(Xu等,2022) | 58.5 | 40.2 | 12.3 | 4 659 |
| MLT(Zhang等,2020) | 48.9 | 25.6 | 18.3 | 2 187 |
| 本文 | 60.2 | 46.0 | 8.7 | 7 637 |
表 7
本文方法与其他方法在Hieve数据集上的效果对比
Table 7
The tracking performance comparison between our method and other methods on Hieve dataset
| 方法 | MOTA/% | MT | ML | IDs |
| FairMOT(Zhang等,2021) | 35.0 | 16.3 | 44.2 | 2 312 |
| JDE(Wang等,2020) | 33.1 | 15.1 | 24.1 | 3 605 |
| Tracktor(Bergmann等,2019) | 35.6 | 11.3 | 43.8 | 4 019 |
| DeepSORT(Wojke等,2017) | 27.1 | 8.5 | 41.4 | 3 122 |
| 本文 | 36.1 | 17.1 | 50.5 | 1 783 |
3.3.3 可视化结果
图 4为本文方法在MOT17数据集上的一部分可视化效果。可以看出,尽管目标间存在比较严重的遮挡,但是由于本文提出的ReID特征位置偏移提取和特征交叉损失,使目标仍然能够获得较为准确的外观特征,得到正确匹配。而得益于帧间响应一致性信息的增强,对于部分遮挡目标也能够有效召回。

另外,将ReID特征提取位置偏移预测分支预测的偏移结果进行可视化,如图 5所示。其中,绿色点为目标检测框中心,红色点为预测的目标ReID特征提取位置。可以发现,本文模型预测的检测框中心位置加上偏移量后所处的位置大多落于目标自身的像素上,而不是落在遮挡目标上,该处提取的外观信息能够保留更多的当前目标信息,尽可能少地受到遮挡目标信息的干扰。

4 结论
现有多目标跟踪方法存在ReID特征中心与目标检测框中心的空间不一致、邻帧目标中心响应的时间不一致以及关联相似度度量的训练测试不一致问题。现有方法大多利用更准确的检测器或更复杂的目标关联策略对多目标跟踪进行改进,忽略了这些不一致问题,导致目标跟踪过程中频繁出现跟踪丢失、身份跳变等现象。针对这些不一致问题,本文提出了一致性多目标跟踪方法,在无锚框的目标检测和基于目标ReID特征的目标关联组成的多目标跟踪框架上,使用目标ReID特征中心偏移,在更能代表目标外观特征的位置提取ReID特征;使用帧间空间相关计算两帧的空间偏移,利用可变卷积对历史帧的目标响应进行变换,得到一致性响应信息增强到当前帧的目标热图上;在训练时为训练集中每个目标轨迹设定一个特征模板,计算检测目标与所有特征模板之间的相似度损失。通过这3方面的改进,解决了多目标跟踪中的一致性问题,在多个多目标跟踪数据集上取得了效果提升。
然而,在实验结果中也发现尽管采用了邻帧目标响应一致性信息进行增强,但是依然存在一些目标丢失或误检情况。原因在于只使用了前一帧的信息,没有使用更多历史信息对目标的响应进行增强。同时,目标的关联中尽管改进了空间上的不一致性,但是ReID特征仅由单帧特征获得,两帧同一目标的ReID特征也可能存在时间不一致。因此,下一步研究工作的重点有两方面。一是融合历史多帧的目标响应信息对当前帧目标的识别召回进行增强;二是在获取ReID特征时,使用历史目标的ReID特征对当前帧目标的ReID特征进行一致性监督学习或特征融合,实现ReID特征的时间一致性。
参考文献
-
Bergmann P, Meinhardt T and Leal-Taixé L. 2019. Tracking without bells and whistles//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Seoul, Korea (South): IEEE: 941-951 [DOI: 10.1109/iccv.2019.00103]
-
Bewley A, Ge Z Y, Ott L, Ramos F and Upcroft B. 2016. Simple online and realtime tracking//Proceedings of 2016 IEEE International Conference on Image Processing. Phoenix, USA: IEEE: 3464-3468 [DOI: 10.1109/ICIP.2016.7533003]
-
Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A and Zagoruyko S. 2020. End-to-end object detection with transformers//Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer: 213-229 [DOI: 10.1007/978-3-030-58452-8_13]
-
Gao B. 2021. Research on Multi-Target Tracking Algorithm Fusing Full Convolutional Twin Network and ReID. Qinhuangdao: Yanshan University (高博. 2021. 融合全卷积孪生网络和ReID网络的多目标跟踪算法研究. 秦皇岛: 燕山大学)
-
Li J H, Gao X and Jiang T T. 2020. Graph networks for multiple object tracking//Proceedings of 2020 IEEE Winter Conference on Applications of Computer Vision. Snowmass, USA: IEEE: 708-717 [DOI: 10.1109/wacv45572.2020.9093347]
-
Lin W Y, Liu H B, Liu S Z, Li Y X, Qian R, Wang T, Xu N, Xiong H K, Qi G J and Sebe N. 2021. Human in events: a large-scale benchmark for human-centric video analysis in complex events [EB/OL]. [2021-05-14]. https://arxiv.org/pdf/2005.04490.pdf
-
Meinhardt T, Kirillov A, Leal-Taixé L and Feichtenhofer C. 2022. TrackFormer: multi-object tracking with transformers [EB/OL]. [2022-04-29]. https://arxiv.org/pdf/2101.02702.pdf
-
Pang B, Li Y Z, Zhang Y F, Li M C and Lu C W. 2020. TubeTK: adopting tubes to track multi-object in a one-step training model//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE: 6307-6317 [DOI: 10.1109/cvpr42600.2020.00634]
-
Pang J M, Qiu L L, Li X, Chen H F, Li Q, Darrel T and Yu F. 2021. Quasi-Dense similarity learning for multiple object tracking//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, USA: IEEE: 164-173 [DOI: 10.1109/cvpr46437.2021.00023]
-
Peng J L, Wang C A, Wan F B, Wu Y, Wang Y B, Tai Y, Wang C J, Li J L, Huang F Y and Fu Y W. 2020. Chained-Tracker: chaining paired attentive regression results for end-to-end joint multiple-object detection and tracking//Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer: 145-161 [DOI: 10.1007/978-3-030-58548-8_9]
-
Qin J, Huang C and Xu J. 2021. End-to-End Multiple Object Tracking with Siamese Networks//Mantoro T, Lee M, Ayu M A, Wong K W, Hidayanto A N. eds. Neural Information Processing. ICONIP 2021. Communications in Computer and Information Science, vol 1517. Springer, Cham
-
Ren S Q, He K M, Girshick R, Sun J. 2015. Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(6): 1137-1149 [DOI:10.1109/TPAMI.2016.2577031]
-
Wang Y X, Kitani K and Weng X S. 2021. Joint object detection and multi-object tracking with graph neural networks//Proceedings of 2021 IEEE International Conference on Robotics and Automation. Xi′an, China: IEEE: 13708-13715 [DOI: 10.1109/icra48506.2021.9561110]
-
Wang Z D, Zheng L, Liu Y X, Li Y L and Wang S J. 2020. Towards real-time multi-object tracking//Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer: 107-122 [DOI: 10.1007/978-3-030-58621-8_7]
-
Wojke N, Bewley A and Paulus D. 2017. Simple online and realtime tracking with a deep association metric//Proceedings of 2017 IEEE International Conference on Image Processing. Beijing, China: IEEE: 3645-3649 [DOI: 10.1109/ICIP.2017.8296962]
-
Wu J L, Cao J L, Song L C, Wang Y, Yang M and Yuan J S. 2021. Track to detect and segment: an online multi-object tracker//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, USA: IEEE: 12347-12356 [DOI: 10.1109/cvpr46437.2021.01217]
-
Xu Y H, Ban Y T, Delorme G, Gan C, Rus D and Alameda-Pineda X. 2022. TransCenter: transformers with dense queries for multiple-object tracking [EB/OL]. [2022-04-28]. https://arxiv.org/pdf/2103.15145.pdf
-
Yang L, Fan Y and Xu N. 2019. Video instance segmentation//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Seoul, Korea (South): IEEE: 5187-5196 [DOI: 10.1109/ICCV.2019.00529]
-
Yu F W, Li W B, Li Q Q, Liu Y, Shi X H and Yan J J. 2016. POI: multiple object tracking with high performance detection and appearance feature//Proceedings of 2016 European Conference on Computer Vision. Amsterdam, the Netherlands: Springer: #9914 [DOI: 10.1007/978-3-319-48881-3_3]
-
Zhang Y, Sheng H, Wu Y B, Wang S, Ke W, Xiong Z. 2020. Multiplex labeling graph for near-online tracking in crowded scenes. IEEE Internet of Things Journal, 7(9): 7892-7902 [DOI:10.1109/jiot.2020.2996609]
-
Zhang Y F, Wang C Y, Wang X G, Zeng W J and Liu W Y. 2021. FairMOT: on the fairness of detection and re-identification in multiple object tracking [EB/OL]. [2021-10-19] https://arxiv.org/pdf/2004.01888.pdf
-
Zhou X Y, Koltun V and Krähenbühl P. 2020. Tracking objects as points//Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer: 474-490 [DOI: 10.1007/978-3-030-58548-8_28]
-
Zhu J, Yang H, Liu N, Kim M, Zhang W J and Yang M H. 2018. Online multi-object tracking with dual matching attention networks//Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer: 379-396 [DOI: 10.1007/978-3-030-01228-1_23]
-
Zhu S S, Wang H, Yan H. 2022. Multi-object tracking based on intra-frame relationship modeling and self-attention fusion mechanism. Control and Decision: 1-10 (朱姝姝, 王欢, 严慧. 2022. 基于帧内关系建模和自注意力融合的多目标跟踪方法. 控制与决策: 1-10) [DOI:10.13195/j.kzyjc.2021.1188]


