|
|
|
发布时间: 2022-09-16 |
多媒体智能安全 |
|
|
|


|
收稿日期: 2022-01-11; 修回日期: 2022-05-19; 预印本日期: 2022-05-26
基金项目: 国家自然科学基金项目(62076131)
作者简介:
杨少聪, 1996年生, 男, 硕士研究生, 主要研究方向为人脸深度伪造检测。E-mail: yangshaocong@njust.edu.cn
王健, 男, 博士研究生, 主要研究方向为人脸深度伪造检测。E-mail: wj92@njust.edu.cn 孙运莲, 通信作者, 女, 副教授, 主要研究方向为生物特征识别、模式识别、计算机视觉、人工智能。E-mail: yunlian.sun@njust.edu.cn 唐金辉, 男, 教授, 主要研究方向为多媒体分析与检索、社交媒体分析、计算机视觉、人工智能。E-mail: jinhuitang@njust.edu.cn *通信作者: 孙运莲 yunlian.sun@njust.edu.cn
中图法分类号: TP391.4
文献标识码: A
文章编号: 1006-8961(2022)09-2708-13
|
摘要
目的 随着深度伪造技术的快速发展, 人脸伪造图像越来越难以鉴别, 对人们的日常生活和社会稳定造成了潜在的安全威胁。尽管当前很多方法在域内测试中取得了令人满意的性能表现, 但在检测未知伪造类型时效果不佳。鉴于伪造人脸图像的伪造区域和非伪造区域具有不一致的源域特征, 提出一种基于多级特征全局一致性的人脸深度伪造检测方法。方法 使用人脸结构破除模块加强模型对局部细节和轻微异常信息的关注。采用多级特征融合模块使主干网络不同层级的特征进行交互学习, 充分挖掘每个层级特征蕴含的伪造信息。使用全局一致性模块引导模型更好地提取伪造区域的特征表示, 最终实现对人脸图像的精确分类。结果 在两个数据集上进行实验。在域内实验中, 本文方法的各项指标均优于目前先进的检测方法, 在高质量和低质量FaceForensics++数据集上, AUC (area under the curve)分别达到99.02%和90.06%。在泛化实验中, 本文的多项评价指标相比目前主流的伪造检测方法均占优。此外, 消融实验进一步验证了模型的每个模块的有效性。结论 本文方法可以较准确地对深度伪造人脸进行检测, 具有优越的泛化性能, 能够作为应对当前人脸伪造威胁的一种有效检测手段。
关键词
人脸伪造检测; 深度伪造; 多级特征学习; 全局一致性; 注意力机制
Abstract
Objective Human facial images interpretation is based on personal identity information like communication, access control and payment. However, advanced deep forgery technology causes faked facial information intensively. It is challenged to distinguish faked information from real ones. Most of the existing deep learning methods have weak generalization ability to unseen forgeries. Our method is focused on detecting the consistency of source features. The source features of deepfakes are inconsistent while source features are consistent in real images. Method First, a destructive module of facial structure is designed to reshuffle image patches. It allows our model to local details and abnormal regions. It restricts overfitting to face structure semantics, which are irrelevant to our deepfake detection task. Next, we extract the shallow, medium and deep features from the backbone network. We develop a multi-level feature fusion module to guide the fusion of features at different levels. Specifically, shallower leveled features can provide more detailed forged clues to the deeper level, while deeper features can suppress some irrelevant details in the features at the shallower level and extend the regional details of the abnormal region. The network can pay attention to the real or fake semantics better at all levels. In the backbone network, the shallow, medium and deep features are obtained via a channel attention module, and then merge them into a guided dual feature fusion module. It is accomplished based on the guided dual fusion of shallow features to deep features and the guided fusion of deep features to shallow features. The feature maps output are added together by the two fusion modules. In this way, we can mine forgery-related information better in each layer. Third, we extract a global feature vector from the fused features. To obtain a consistency map, we calculate the similarity between the global feature vector and each local feature vector (i.e., the feature vector at each local position). The inconsistent areas are highlighted in this map. We multiply the output of the multi-level feature fusion module by the consistency map. The obtained result is combined with the output of the backbone network to the classifier for the final binary classification. We use forged area labels to learn better and label the forged area of each face image in sequential: 1) to align the forged face image for its corresponding real face image and calculate the difference between their corresponding pixel values; 2) to generate a difference image of those spatial size are kept equivalent between real and fake face images; 3) to convert the difference image to a grayscale image through converting each pixel value to [0, 1] linearly, the difference image is binarized with a threshold of 0.1, resulting in the final forged area label. Our main contributions are shown as below: 1) to capture the inconsistent source features in forged images, a global consistency module is developed; 2) to make the network pay more attention to forged information and suppress irrelevant background details at the same time, a multi-level feature guided fusion module is facilitated; 3) to prevent our model from overfitting to face structure semantics, a destructive module of facial structure is designed to distinguish fake faces from real ones. Our method achieves good performance for the intra-dataset test and the cross-dataset test both. The test results show that we achieve highly competitive detection accuracy and generalization performance. During the experiment, we take 30 frames with equal spacing for each video in the training set, 100 frames for each video in the test set. For each image, we choose the largest detected sample and convert its size to 320×320 pixels. For experimental settings, we use Adam optimization with a learning rate of 0.000 2. The batch size is 16. Result Our method is compared to 8 latest methods on two datasets (including five forgery methods). In the FaceForensics++ (FF++) dataset, we obtain the best performance. On the FF++ (low-quality) dataset, the area under the curve(AUC) value is increased by 1.6% in comparison with the second best result. For the generalization experiment of four forgery methods in FF++, we achieve better result beyond the baseline. For the cross-dataset generalization experiment (trained on FF++ dataset and tested on Celeb-DF dataset), we achieve the best AUC on both datasets. In addition, the ablation experiments are carried out on FF++ dataset to verify the effectiveness of each module as well. Conclusion This method can detect deepfakes accurately and has good generalization performance. It has potential to deal with the threat of deep forgery.
Key words
face forgery detection; deep fakes; multi-level feature learning; global consistency; attention mechanism
0 引言
随着深度生成技术的不断完善, 伪造人脸技术逐渐成熟, 单凭人眼越来越难以鉴别人脸伪造图像。Deepfakes、Faceswap和Faceapp等人脸伪造技术已开源共享(网址https://github.com/iperov/Deep-FaceLab;https://github.com/MarekKowalski/FaceSwap;https://www.faceapp.com), 研究者可轻松获得, 并可随意篡改视频、图像中的人脸信息。这些伪造的媒体内容已深入人们的日常, 有些丰富了人们的生活, 但有些给人们的生活带来潜在威胁。例如, 如果针对公众人物使用伪造人脸技术发布虚假消息甚至行政命令, 将在社会中引发混乱, 造成恐慌。并且, 人脸包含丰富的个人身份信息, 在当今社会发挥着重要作用和价值。例如, 访问权限控制、案件举证和金融支付等。为了预防人脸伪造技术可能造成的负面影响, 有必要研究一种通用且鲁棒的人脸伪造检测技术。
早期很多工作(Afchar等, 2018;Cozzolino等, 2019;Nguyen等, 2019b)将伪造人脸检测任务定义为二分类问题, 直接使用深度神经网络对人脸进行分类。但是, 这些方法无法凸显伪造区域和非伪造区域的差异性, 并且无法实现伪造区域定位。为了解决这些问题, Nguyen等人(2019a)使用多任务学习方法检测伪造人脸图像, 可同时进行伪造人脸分类任务、图像重建任务和伪造区域定位任务, 多个任务间实现互相共享领域相关信息、互相促进学习。Dang等人(2020)提出一种基于注意力的方法实现伪造区域定位, 通过注意力机制引导模型更加关注伪造区域, 从而提高模型的检测性能。这些方法均尝试使用伪造区域的像素级标注引导模型关注伪造区域, 希望网络能更好地学习到伪造区域的内在表示, 虽然取得了不错的性能表现, 但是这些方法很容易过拟合, 尤其在跨域实验中性能表现不佳。近年来, 一些研究越来越关注模型在跨域实验中的表现, 并提出一些针对性的方法改善模型的泛化性能。Matern等人(2019)总结了伪造人脸图像中容易出现的多种视觉伪影, 并利用简单的分类器(如多层感知机等)对其进行捕捉。Liu等人(2020)认为伪造人脸的纹理和真实人脸的纹理存在较大差异, 因此利用深度神经网络提取全局纹理特征表示对伪造人脸图像进行检测。Qian等人(2020)发现在频域较RGB域更容易找到伪造痕迹, 尤其在高频和中频频段, 提出一种双流网络同时捕捉RGB域和频域信息, 实现人脸伪造检测。Masi等人(2020)提出一种用于提取高频信息和RGB域信息的双路模型, 设计了一种新的损失函数拉近真实人脸图像的特征距离, 扩大真实与伪造人脸图像特征之间的距离, 提升了模型的检测性能。Liu等人(2021)通过结合图像空间信息和图像相位谱捕获人脸伪造痕迹, 使用浅层网络获得更加清晰的纹理信息, 提高了模型的检测能力。以上方法主要通过学习伪造图像特性进行伪造检测, 取得了一定进展, 但存在以下不足:1)模型对训练集中出现的伪造图像容易过拟合, 对不可见伪造方法的检测效果不佳;2)大多数方法只提取图像整体特征, 没有着重关注伪造区域的细粒度特征;3)训练过程中网络模型对一些与任务无关的语义信息(例如人脸结构信息)过拟合, 削弱了模型对伪造信息的捕捉能力。
对于伪造人脸检测任务来说, 挖掘在人脸伪造过程中更加普遍的伪造痕迹对增强网络的泛化性至关重要。图 1展示了人脸伪造的普遍生成过程。首先用人脸检测器提取目标图像和源图像的人脸区域, 其次对两个人脸区域进行人脸关键点对齐, 然后使用相应的人脸生成技术对人脸信息进行伪造, 最后将伪造后的人脸区域合成到目标图像的背景中, 达成伪造人脸的目的(Li等, 2020a)。之前大多数伪造人脸检测方法更多的是利用图 1中人脸伪造阶段留下的痕迹辨别真伪, 然而不同的伪造方式会留下不同痕迹, 很难发掘共有的特性。
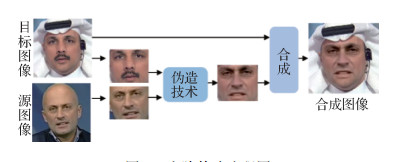

值得注意的是, 人脸伪造普遍会经历上述的合成阶段, 合成阶段往往需要两幅来源不同的图像, 而来源不同的图像具有不同的源域特征。例如不同的源相机特征(光响应不均匀性等(Lukas等, 2005))、不同的压缩方法以及一些特有的伪造痕迹(例如纹理不统一(Liu等, 2020)、生成对抗网络生成的图像会呈现棋盘效应(Yu等, 2019))。因此, 伪造的人脸图像将存在源域特征不一致的情况, 而真实人脸图像的源域特征具有全局一致性(Huh等, 2018;蒋小玉和刘春晓, 2021)。
基于上述内容, 本文提出一种基于多级特征全局一致性的方法检测人脸伪造。主要有以下贡献:1)设计一种全局一致性模块以捕捉伪造图像中普遍存在的不一致的源域特征;2)将多级特征融合模块用于引导模型更加关注伪造细节, 同时抑制无关的背景;3)使用人脸结构破除模块抑制模型对任务无关特征的拟合, 使模型倾向于学习更加鲁棒的特征;4)在FF++(FaceForensics++)和Celeb-DF数据集上分别进行域内测试和泛化性能测试, 测试结果显示本文方法取得了极具竞争力的域内性能和泛化性能。
1 本文方法
本文提出一种基于全局一致性的伪造人脸检测网络, 网络结构如图 2所示, 包括人脸结构破除模块、多级特征融合模块和全局一致性计算模块。
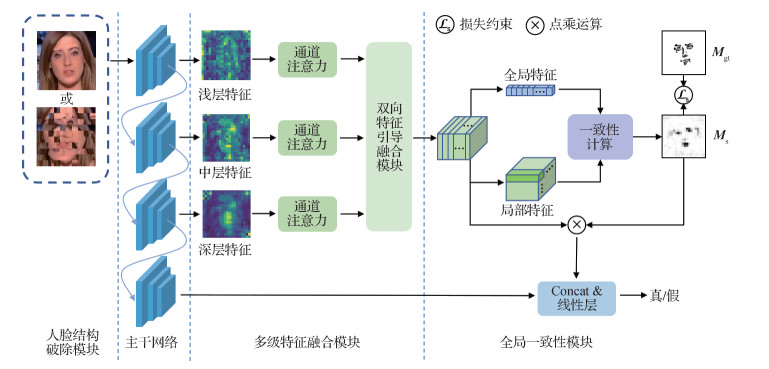
1.1 人脸结构破除模块
随着人脸伪造技术的逐渐成熟, 伪造痕迹越来越难以捕捉。一方面, 伪造人脸图像与真实人脸图像的全局结构信息几乎完全一致。例如眼睛、鼻子和嘴巴等五官在人脸区域中的位置几乎是恒定不变的。而这类冗余信息对模型的检测性能几乎没有帮助, 为了提升模型对关键的、细微的伪造痕迹的捕捉能力, 有必要采取一些策略, 使模型更加关注局部伪造细节并同时能够忽略全局结构冗余信息。另一方面, Das等人(2021)发现目前大多数人脸伪造检测数据集几乎都是对单张人脸进行有限的伪造操作。具体来说, 使用这类数据集时, 通常对同一个视频中的同一个人物取多帧人脸数据进行模型训练, 这显然会导致在训练过程中的过度采样。为解决以上冗余信息和过度采样问题, 本文引入一种人脸结构破除模块, 抑制模型对与目标任务无关的脸部特征的拟合, 使模型更加关注与目标任务高度相关的伪造痕迹。具体地, 人脸结构破除模块首先将人脸切分成

1.2 多级特征融合模块
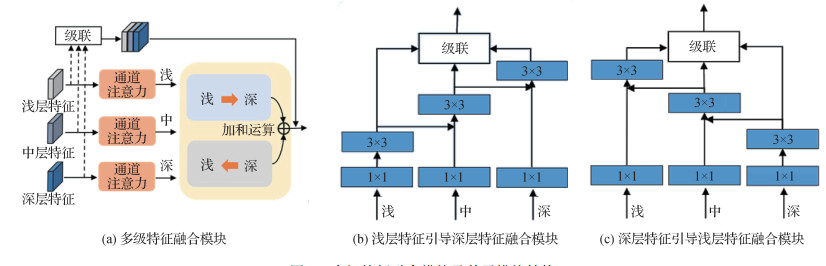
多数伪造人脸检测方法使用网络的深层特征直接进行分类, 尽管取得了不错的性能表现, 但是这些方法忽略了网络的浅层结构信息。近年来, 一些研究开始关注多级特征在人脸伪造检测任务中的重要作用。Chai等人(2020)提到浅层特征包含丰富的结构特征, 而这些结构特征能够揭露出细微的异常信息和不规则的纹理信息。Afchar等人(2018)使用中级特征检测伪造人脸, 中级特征相比较浅层特征具有更好的抗干扰能力, 相比较深层特征有更多的细节信息。因此, 为了挖掘更丰富、更鲁棒的特征表示, 本文方法结合浅、中和深多级特征来增强模型对伪造痕迹的捕捉。浅层特征提供更精细的结构信息给深层特征, 而深层特征能对浅层特征中一些与目标任务无关的细节信息进行抑制。不同层级的特征相互引导和优化, 从而增强特征的鲁棒性, 提升模型对各个层级伪造信息的捕捉能力。具体地, 如图 4(a)所示, 首先将主干网络的浅层、中层和深层特征分别输入通道注意力模块, 在通道维度上强化判别性信息的学习, 再将学习到的特征输入双向引导特征融合模块。双向引导特征融合模块实现了浅层到深层、深层到浅层的特征交互学习。同时, 本文方法将融合后的特征与之前的多级特征进行残差连接, 以防止梯度消失。
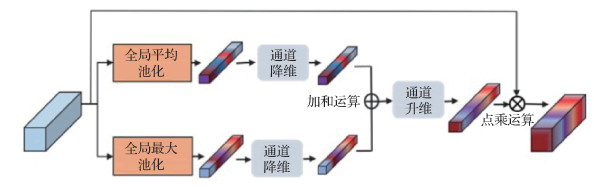
1.2.1 通道注意力模块
为了挖掘通道间的联系, 突出特征图中更具判别性的信息, 采用通道注意力模块对通道信息进行加权处理。全局平均池化(global average pooling, GAP)能够全面捕捉整体信息, 全局最大池化(global maximum pooling, GMP)可以捕获异常信息。受CBAM(convolutional block attention module)(Woo等, 2018)启发, 本文方法的通道注意力模块同时使用这两种池化操作, 实现通道维度上的软注意力加权操作。如图 5所示, 在通道注意力模块中, 输入特征
1.2.2 双向引导特征融合模块
为了提取鲁棒的特征表示、挖掘出轻微的伪造痕迹, 本文提出一种全新的双向引导特征融合模块, 实现多级特征交互学习。该模块主要由两个子模块构成, 一个子模块用于浅层特征引导深层特征学习, 另一个子模块用于深层特征引导浅层特征学习, 两个子模块实现了多级特征的交互学习, 这种特征交互学习期望能够增强模型的鲁棒性和泛化性。本文子模块的特征融合机制在Gao等人(2021)工作中已有类似应用, 他们的方法聚焦于不同尺度特征之间的信息融合, 而本文方法关注不同层级特征之间的引导学习, 并且提出双向引导融合机制, 实现了由浅层到深层、由深层到浅层的交互学习。
浅层特征引导深层特征融合模块如图 4(b)所示。其使用3×3卷积作为特征提取器, 每个层级的特征都有对应的特征提取器。浅、中和深层特征经过1×1卷积映射后, 较浅层的特征经过特征提取后, 与较深层的特征一起进入较深层对应的特征提取器。较深层特征在进行特征提取时, 能够同时得到具有更多细节的浅层信息的引导, 从而更好地挖掘伪造信息。然后对3种层级的特征在通道维度进行连接, 从而完成浅层特征对深层特征的引导学习。浅层特征引导深层特征融合模块在引导学习过程中, 只在相邻的层级之间传递引导信息, 因为相邻层级的信息跨度较小, 具有一定的连贯性和相似性, 能更好地进行不同层级间的信息引导。浅层特征引导深层特征融合模块可以表示为
| $\boldsymbol{Y}_i= \begin{cases}\boldsymbol{M}_i\left(\boldsymbol{X}_i\right) & i=1 \\ \boldsymbol{M}_i\left(\boldsymbol{X}_i+\boldsymbol{Y}_{i-1}\right) & 2 \leqslant i \leqslant 3\end{cases}$ | (1) |
式中,
深层特征引导浅层特征融合模块如图 4(c)所示。较深层的特征经过特征提取器后, 与较浅层的特征一起进入较浅层对应的特征提取器。较深层特征中的真伪相关的高级语义能够更好地引导较浅层特征的提取, 抑制无关的细节信息。然后对已经完成特征提取的3种层级特征在通道维度上进行连接。深层特征引导浅层特征融合模块是浅层特征引导深层特征融合模块的反向操作, 具体实现与式(1)类似。
1.3 全局一致性模块
全局一致性模块旨在计算局部特征与全局特征的相似性来获得更具判别性的特征表示。受到Hu等人(2018)工作的启发, 本文方法使用一个标量对每一个通道的全局信息进行有效代表, 继而得到一个能够有效代表全局信息的特征向量。Hu等人(2018)使用GAP获得代表通道全局信息的标量, 然而平均池化操作容易忽略细微的伪造痕迹, 不利于模型对轻微伪造痕迹的捕捉。因此, 对于每个通道, 本文使用一组独立的可学习参数
| $g_k=\sum\limits_{j=1}^H \sum\limits_{i=1}^W\left(Z_{k i j} \cdot X_{k i j}\right), k \in\{1, 2, \cdots, C\}$ | (2) |
式中,
| $\boldsymbol{o}=f_{\mathrm{GAP}}\left(\boldsymbol{X} \times\left|1-\boldsymbol{M}_{\mathrm{s}}\right|\right)$ | (1) |

1.4 损失函数
本文同时使用分类损失函数
| $L=L_{\mathrm{c}}+\lambda L_{\mathrm{s}}$ | (4) |
式中,
本文采用focal loss(Lin等, 2017)作为网络的分类损失, 即
| $L_{\mathrm{c}}=-\alpha y(1-p)^\gamma \log (p)- \\(1-\alpha)(1-y) p^\gamma \log (1-p)$ | (5) |
式中,
一致性损失函数
| $L_{\mathrm{s}}=\left\|\boldsymbol{M}_{\mathrm{s}}-\boldsymbol{M}_{\mathrm{gt}}\right\|_1$ | (6) |
式中,
| $\boldsymbol{M}_{\mathrm{gt}}=\left|1-\boldsymbol{M}_{\mathrm{f}}\right|$ | (7) |
2 实验结果与分析
2.1 数据集
为验证本文方法的有效性, 在两个公开可获得的伪造人脸数据集FF++(FaceForensics++)(Rössler等, 2019)和Celeb-DF(Li等, 2020b)上进行实验。FF++是广泛使用的大型伪造人脸数据集, 共5 000个视频, 包含1 000个真实视频和4 000个伪造视频。伪造视频由DF(Deepfakes)、NT(NeuraTextures)、F2F(Face2 Face)和FS(FaceSwap)等4种伪造方式生成, 每种伪造方式生成1 000个。另外, FF++数据集中共有3种压缩质量的视频, 分别为原始未压缩视频(raw videos, RAW)、经过轻微压缩的高质量视频(high-quality videos, HQ)和经过重度压缩的低质量视频(low-quality videos, LQ)。由于当前人脸伪造检测任务的一大问题是检测器面对压缩的视频或图像时性能出现明显下滑, 因此本文使用高质量和低质量的视频进行实验。
Celeb-DF数据集共6 529个视频, 包含890个真实视频和5 639个伪造视频。Celeb-DF数据集的伪造视频相比先前的数据集, 通过使用改进的人脸伪造方法减少了视觉伪影, 使生成的伪造视频更加难以鉴别。在人脸伪造检测任务中, Celeb-DF数据集广泛用于测试模型的泛化性能。
2.2 实验设置
2.2.1 数据预处理
本文方法使用Center Face(Xu等, 2020)人脸检测器提取视频中的人脸区域。对训练集中的每个视频等间距取30帧, 测试集中的每个视频等间距取100帧, 每帧图像取检测到的最大人脸作为训练数据, 然后将其尺寸调整到320×320像素。实验中, 使用水平翻转、高斯模糊、高斯噪声以及灰度化等常见的数据增强方法。此外, 因为每个原始视频对应4种伪造视频, 所以为了实现正负样本平衡, 本文按照FF++中的设置, 将训练集中的原始视频数量扩充到原来的4倍, 使原始视频与伪造视频的数量一致。
2.2.2 人脸伪造区域标注
为了获得像素级人脸伪造区域标注图, 首先将对齐的真实人脸图像与伪造图像进行差值计算, 并将差值图转换成灰度图。然后将灰度图的像素值映射到0~1之间, 用0.1作为阈值生成得到二值化图, 如图 3(c)所示。二值化图即需要的像素级人脸伪造区域的标注图
2.2.3 数据划分和参数设置
实验按FF++数据集和Celeb-DF数据集的原始划分设置, 将FF++数据集分为训练集、验证集和测试集;将Celeb-DF分为训练集和测试集。具体如表 1所示。其中FF++训练集、验证集和测试集分别占总体的72%、14%和14%。Celeb-DF训练集和测试集分别占总体的92%和8%。使用Xception作为模型主干网络, 使用ImageNet预训练的参数初始化主干网络, 使用Adam优化模型。设置学习率为0.000 2、batch size为32、人脸结构破除模块的
表 1
伪造人脸数据集划分
Table 1
Partitions of FF++ and Celeb-DF
| 类型 | FF++/个 | Celeb-DF/个 | ||||
| DF | F2F | FS | NT | 真实 | ||
| 训练集 | 720 | 720 | 720 | 720 | 720 | 6 011 |
| 验证集 | 140 | 140 | 140 | 140 | 140 | - |
| 测试集 | 140 | 140 | 140 | 140 | 140 | 518 |
| 合计 | 1 000 | 1 000 | 1 000 | 1 000 | 1 000 | 6 529 |
| 注:“-”表示无此类划分。 | ||||||
2.3 实验结果
为了全面验证提出方法的性能, 实验在FF++数据集上验证模型的域内性能, 在FF++子数据集和Celeb-DF数据集上验证模型的泛化性能。采用准确率(accurary, ACC)和曲线下面积(area under the curve, AUC)作为评估指标。与经典的和目前较新的LD-CNN(recasting residual-based local descriptors as convolutional neural networks)(Cozzolino等, 2017)、Xception-ELA(Xception with error level analysis)(Gunawan等, 2017)、MesoNet(Afchar等, 2018)、Xception(Rössler等, 2019)、Face X-ray(Li等, 2020a)、Two Branch (Masi等, 2020)、Multi-attentional(Zhao等, 2021)和SPSL(spatial-phase shallow learning)(Liu等, 2021)等方法进行对比。
2.3.1 域内实验结果
本文在FF++(HQ)与FF++(LQ)两种压缩质量的数据集上进行对比实验, 评估本文方法的域内性能。表 2展示了不同方法在FF++(HQ)和FF++(LQ)数据集同一视频压缩质量上进行训练和测试(即在FF++(HQ)上训练, 在FF++(HQ)上测试;在FF++(LQ)上训练, 在FF++(LQ)上测试)的实验结果。可以看出, 在HQ和LQ所有的视频压缩质量设置下, 本文方法的各项评价指标均优于所有对比方法。尤其在检测难度较高的FF++(LQ)数据集上, 本文方法的ACC和AUC分别为87.31%和90.06%, 与目前较先进的方法相比取得较大提升。与Multi-attentional(Zhao等, 2021)和SPSL(Liu等, 2021)相比, AUC分别提高了1.6%和7.24%, ACC提高了0.9%和5.74%。这主要得益于人脸结构破除模块、多级融合特征模块和全局一致性模块相互配合, 对伪造信息的充分挖掘。即便在伪造痕迹严重抹除的低质量数据上, 本文方法根据对局部源域信息和全局源域信息的一致性判断, 依然能够捕捉到轻微的伪造痕迹。值得注意的是, MesoNet(Afchar等, 2018)和Xception(Rössler等, 2019)都尝试使用不同的单一层级的特征检测伪造人脸, 而本文方法不仅同时关注浅层特征和深层特征, 还将两种特征进行相互引导融合, 可以更好地引导模型捕捉到轻微的伪造信息, 从而提升模型的性能。
表 2
FF++数据集上不同质量视频的分类结果
Table 2
Classification performance on FF++(HQ+LQ)
| /% | |||||||||||||||||||||||||||||
| 方法 | 低质量 | 高质量 | |||||||||||||||||||||||||||
| ACC | AUC | ACC | AUC | ||||||||||||||||||||||||||
| LD-CNN | 58.69 | - | 78.45 | - | |||||||||||||||||||||||||
| MesoNet* | 79.95 | 54.35 | 79.99 | 52.23 | |||||||||||||||||||||||||
| Face X-ray | - | 61.60 | - | 87.40 | |||||||||||||||||||||||||
| Xception-ELA* | 80.53 | 73.06 | 88.14 | 92.22 | |||||||||||||||||||||||||
| Two Branch | - | 86.59 | - | 98.70 | |||||||||||||||||||||||||
| Xception* | 86.04 | 87.78 | 95.71 | 98.74 | |||||||||||||||||||||||||
| Multi-attentional* | 86.41 | 88.46 | 96.14 | 98.90 | |||||||||||||||||||||||||
| SPSL | 81.57 | 82.82 | 91.50 | 95.32 | |||||||||||||||||||||||||
| 本文 | 87.31 | 90.06 | 96.63 | 99.02 | |||||||||||||||||||||||||
| 注:加粗字体表示各列最优结果, *表示使用官方代码在统一实验设置下重新训练, “-”表示原方法未提供该指标结果。 | |||||||||||||||||||||||||||||
为了更好地评估本文方法在不同伪造方式下的有效性, 本文在FF++(LQ)数据集上训练, 在FF++(LQ)数据集的DF、F2F、FS和NT伪造视频测试集上对多种方法进行测试, 实验结果如表 3所示。可以看出, 本文方法在大多数情况下都取得了最佳的检测性能, 尤其在众多方法检测能力均较弱的FS伪造数据测试集下, 本文方法的AUC达到94.13%, 相较先前的最佳方法Multi-attentional(Zhao等, 2021)提升了16.28%, 进一步说明了本文方法的优越性。
表 3
不同方法在FF++(LQ)数据集中的4种伪造数据测试集上的AUC结果
Table 3
Performance comparison (AUC) among different models on four sub-datasets corresponding to four forgery methods of the FF++ (LQ) test dataset
| /% | |||||||||||||||||||||||||||||
| 方法 | 训练集 | 测试集 | |||||||||||||||||||||||||||
| DF | F2F | FS | NT | 全部 | |||||||||||||||||||||||||
| MesoNet* | FF++ | 58.15 | 54.74 | 53.22 | 52.82 | 54.35 | |||||||||||||||||||||||
| Xception-ELA* | FF++ | 79.00 | 64.29 | 51.03 | 72.46 | 73.06 | |||||||||||||||||||||||
| Xception* | FF++ | 86.70 | 87.55 | 76.07 | 85.61 | 87.78 | |||||||||||||||||||||||
| Multi-attentional* | FF++ | 94.03 | 87.20 | 77.85 | 85.70 | 88.46 | |||||||||||||||||||||||
| 本文 | FF++ | 94.95 | 90.39 | 94.13 | 80.76 | 90.06 | |||||||||||||||||||||||
| 注:加粗字体为各列最优结果, *表示使用官方代码在统一实验设置下重新训练。 | |||||||||||||||||||||||||||||
2.3.2 跨域实验结果
为了进一步评估本文方法, 考虑实际伪造人脸检测任务的需求, 在不可见的伪造方法生成的数据集上测试, 进行了两种跨域实验。
1) 伪造技术泛化性实验。FF++数据集包含4种伪造的数据, 分别为DF、NT、F2F和FS。实验使用FF++(HQ)数据集中的1种伪造方式的数据进行训练, 在FF++(HQ)数据集的其他3种伪造方式生成的数据上进行泛化性能测试, 采用先进的检测器Xception作为对比方法, 结果如表 4所示。
表 4
FF++数据集上不同伪造方式的泛化性效果(AUC值)
Table 4
Generalization performance of different forgery methods on FF++
| /% | |||||||||||||||||||||||||||||
| 训练集 | 方法 | 测试集 | |||||||||||||||||||||||||||
| DF | F2F | FS | NT | ||||||||||||||||||||||||||
| DF | Xception | 99.9 | 67.69 | 42.84 | 69.59 | ||||||||||||||||||||||||
| 本文 | 99.9 | 72.26 | 52.66 | 71.22 | |||||||||||||||||||||||||
| F2F | Xception | 82.69 | 99.48 | 61.4 | 58.38 | ||||||||||||||||||||||||
| 本文 | 86.12 | 99.51 | 61.31 | 61.61 | |||||||||||||||||||||||||
| FS | Xception | 45.88 | 63.29 | 99.9 | 41.84 | ||||||||||||||||||||||||
| 本文 | 58.87 | 69.04 | 99.9 | 49.88 | |||||||||||||||||||||||||
| NT | Xception | 86.63 | 67.67 | 44.72 | 98.19 | ||||||||||||||||||||||||
| 本文 | 87.24 | 72.45 | 46.92 | 98.21 | |||||||||||||||||||||||||
| 注:加粗字体表示各组实验最优结果。 | |||||||||||||||||||||||||||||
从表 4可以看出, 伪造技术泛化性实验共12组, 本文方法除了在1组泛化实验(F2F训练, FS测试)中AUC略低于Xception 0.09%, 其余11组泛化实验的结果均高于甚至远高于Xception。Xception检测人脸伪造更多依赖高级语义信息实现二分类任务, 而本文通过深层语义和浅层结构信息的交互学习, 得到的特征更具判别性, 并且学习图像的全局一致性, 使得本文方法对轻微的、局部的伪造痕迹的检测更加鲁棒。因此, 本文方法在不可见伪造技术的泛化性实验中, 取得了良好的性能表现。
2) 数据集泛化性实验。实验按先前的工作设置(Li等, 2020b), 在FF++(DF)数据集上进行训练, 在Celeb-DF数据集上进行测试, 验证模型在交叉数据集上的泛化性能。与当前先进的Two-stream(Zhou等, 2017)、MesoNet(Afchar等, 2018)、Multi-task(Nguyen等, 2019a)、F3-net (Qian等, 2020)、Multi-attentional(Zhao等, 2021)、Two Branch(Masi等, 2020)、SPSL (Liu等, 2021)、Xception-raw、Xception-c23和Xception-c40等10种检测方法进行比较。其中, Xception-raw、Xception-c23和Xception-c40分别为Xception(Rössler等, 2019)在FF++(raw)、FF++(c23)和FF++(c40)上训练得到的模型。表 5呈现了不同方法在FF++(DF)上的域内测试的性能表现, 以及在Celeb-DF上得到的泛化测试结果。可以看出, 与当前最优方法相比, 本文方法在跨域实验中取得最佳性能表现的同时, 在域内的性能也高于目前其他方法。
表 5
在Celeb-DF上的跨域AUC结果
Table 5
Cross-dataset AUC evaluation on Celeb-DF
| /% | |||||||||||||||||||||||||||||
| 方法 | FF++(DF) | Celeb-DF | |||||||||||||||||||||||||||
| Two-stream | 70.10 | 53.80 | |||||||||||||||||||||||||||
| MesoNet* | 71.75 | 53.99 | |||||||||||||||||||||||||||
| Multi-task | 76.30 | 54.30 | |||||||||||||||||||||||||||
| Xception-raw* | 99.90 | 53.66 | |||||||||||||||||||||||||||
| Xception-c23* | 99.85 | 66.89 | |||||||||||||||||||||||||||
| Xception-c40* | 99.24 | 66.54 | |||||||||||||||||||||||||||
| F3-net | 98.10 | 65.17 | |||||||||||||||||||||||||||
| Multi-attentional* | 99.86 | 67.89 | |||||||||||||||||||||||||||
| Two Branch | 93.18 | 73.44 | |||||||||||||||||||||||||||
| SPSL | 96.91 | 76.88 | |||||||||||||||||||||||||||
| 本文 | 99.90 | 77.68 | |||||||||||||||||||||||||||
| 注:加粗字体表示各列最优结果, *表示使用官方代码在统一实验设置下重新训练。 | |||||||||||||||||||||||||||||
2.3.3 模型运行时间
实验对模型运行时间进行测试。在FF++(HQ)数据集上, 将本文方法与MesoNet(Afchar等, 2018)、Xception-ELA(Gunawan等, 2017)、Xception(Rössler等, 2019)和Multi-attentional(Zhao等, 2021)等方法比较训练和预测时间, 结果如表 6所示。可以发现, 本文方法的训练时间比基准网络Xception略慢, 但是比同样基于Xception的Multi-attentional方法快很多。同样, 本文方法的测试时间也介于Xception与Multi-attentional之间。综合而言, 本文方法在性能和运行速度上取得了良好平衡。
表 6
在FF++(HQ)数据集上的训练时间和预测时间
Table 6
Training and test time on FF++(HQ)
| 方法 | 训练时间/ (s/epoch) |
预测时间/ (ms/帧) |
| MesoNet* | 325.68 | 1.74 |
| Xception-ELA* | 2 153.70 | 3.60 |
| Xception* | 2 119.85 | 3.82 |
| Multi-attentional* | 7 064.67 | 5.79 |
| 本文 | 2 771.05 | 4.91 |
| 注:*表示使用官方代码在统一实验设置下重新训练。 | ||
2.3.4 消融实验
本文方法主要包括人脸结构破除模块、双向引导融合模块和全局一致性模块。为了测试各模块对模型的性能影响, 在FF++(LQ)数据集上进行消融实验, 结果如表 7所示。可以看出, 在仅使用全局一致性模块时, AUC提高了1.15%, 表明该模块能够对来源不同的特征进行有效区分, 从而达到更好的检测效果。在同时使用人脸结构破除模块和全局一致性模块时, 相对于只使用全局一致性模块, AUC提升了0.55%, 表明人脸结构破除模块使网络更关注真伪信息, 同时加强了对细节信息的捕捉, 因此最终性能有了一定提升。当3个模块同时使用时, 相对于不使用多级特征融合模块, AUC提高了0.57%, 由此可知, 使用多级特征相互引导, 充分发掘浅层、中层和深层中包含的伪造信息, 能够更好地引导模型关注到细微的伪造信息, 提高模型的检测能力和泛化性能。
表 7
在FF++(LQ) 数据集上的消融实验结果
Table 7
Ablation study results on FF++(LQ)
| /% | |||||||||||||||||||||||||||||
| 全局一致性 模块 |
人脸结构 破除模块 |
双向引导 融合模块 |
AUC | ||||||||||||||||||||||||||
| - | - | - | 87.79 | ||||||||||||||||||||||||||
| √ | - | - | 88.94 | ||||||||||||||||||||||||||
| √ | √ | - | 89.49 | ||||||||||||||||||||||||||
| √ | √ | √ | 90.06 | ||||||||||||||||||||||||||
| 注:加粗字体表示最优结果, “√”表示采用该模块, “-”表示不采用该模块。 | |||||||||||||||||||||||||||||
为了进一步说明人脸结构破除模块的有效性, 图 7展示了本文方法在使用该模块前后的分割对比图。可以看出, 当增加人脸结构破除模块时, 图 7(b)相较于图 7(c)关注到了更多局部区域的异常信息, 充分说明了人脸结构破除模块能够使模型更加关注伪造区域更本质的特性, 增强模型对局部伪造细节的挖掘, 从而提升模型对轻微伪造痕迹的检测能力。

2.3.5 可视化
为进一步证明本文方法的优越性, 图 8展示了本文方法在不同伪造图像上的伪造定位效果, 图 8(a)为输入图像, 包括original、DF、F2F、FS和NT;图 8(b)为输入图像对应的伪造区域标注

3 结论
针对现有人脸伪造检测方法泛化能力较弱的问题, 本文提出一种基于多级特征全局一致性的人脸伪造检测模型, 从3个方面进行改进:1)设计全局一致性模块, 用于捕获伪造人脸过程中更加普遍存在的源域不一致的信息;2)使用人脸结构破除模块抑制模型过度关注与目标任务无关的人脸结构信息, 加强模型对伪造信息的捕捉, 同时有助于模型对局部细微异常信息的检测;3)使用多级特征双向引导融合模块使不同层级的特征进行信息的交互学习, 浅层特征提供更加精细的结构信息给深层特征, 深层特征给浅层特征提供真伪的高级语义, 使浅层特征保留与任务相关的异常信号, 同时抑制浅层特征中的背景细节, 使网络能够更好地挖掘出源域特征用于一致性判断。通过上述改进, 本文方法实现了对伪造人脸的准确检测, 并具有良好的泛化性能。本文方法的优秀性能在FF++和Celeb-DF数据集上得到了验证, 且多项评价指标取得最佳性能。但是, 本文方法仍存在不足。生成人脸伪造区域标签的策略可以进一步优化, 使标签对伪造区域的描述更加准确, 对检测结果也有帮助。
参考文献
-
Afchar D, Nozick V, Yamagishi J and Echizen I. 2018. MesoNet: a compact facial video forgery detection network//Proceedings of 2018 IEEE International Workshop on Information Forensics and Security (WIFS). Hong Kong, China: IEEE: 1-7 [DOI: 10.1109/WIFS.2018.8630761]
-
Chai L, Bau D, Lim S N and Isola P. 2020. What makes fake images detectable? Understanding properties that generalize//Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer: 103-120 [DOI: 10.1007/978-3-030-58574-7_7]
-
Cozzolino D, Poggi G and Verdoliva L. 2017. Recasting residual-based local descriptors as convolutional neural networks: an application to image forgery detection//Proceedings of the 5th ACM Workshop on Information Hiding and Multimedia Security. Philadelphia, USA: ACM: 159-164 [DOI: 10.1145/3082031.3083247]
-
Cozzolino D, Thies J, Rössler A, Riess C, Nießner M and Verdoliva L. 2019. ForensicTransfer: weakly-supervised domain adaptation for forgery detection [EB/OL]. [2021-11-27]. https://arxiv.org/pdf/1812.02510.pdf
-
Dang H, Liu F, Stehouwer J, Liu X M and Jain A K. 2020. On the detection of digital face manipulation//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE: 5780-5789 [DOI: 10.1109/CVPR42600.2020.00582]
-
Das S, Seferbekov S, Datta A, Islam M S and Amin M R. 2021. Towards solving the DeepFake problem: an analysis on improving DeepFake detection using dynamic face augmentation//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW). Montreal, Canada: IEEE: 3769-3778 [DOI: 10.1109/ICCVW54120.2021.00421]
-
Gao S H, Cheng M M, Zhao K, Zhang X Y, Yang M H, Torr P. 2021. Res2Net: a new multi-scale backbone architecture. IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(2): 652-662 [DOI:10.1109/TPAMI.2019.2938758]
-
Gunawan T S, Hanafiah S A M, Kartiwi M, Ismail N, Za′bah N F, Nordin A N. 2017. Development of photo forensics algorithm by detecting photoshop manipulation using error level analysis. Indonesian Journal of Electrical Engineering and Computer Science, 7(1): 131-137 [DOI:10.11591/ijeecs.v7.i1.pp131-137]
-
Hu J, Shen L and Sun G. 2018. Squeeze-and-excitation networks//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE: 7132-7141 [DOI: 10.1109/CVPR.2018.00745]
-
Huh M, Liu A, Owens A and Efros A A. 2018. Fighting fake news: image splice detection via learned self-consistency//Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer: 106-124 [DOI: 10.1007/978-3-030-01252-6_7]
-
Jiang X Y, Liu C X. 2021. Edge and region inconsistency-guided image splicing tamper detection network. Journal of Image and Graphics, 26(10): 2411-2420 (蒋小玉, 刘春晓. 2021. 边缘与区域不一致性引导下的图像拼接篡改检测网络. 中国图象图形学报, 26(10): 2411-2420) [DOI:10.11834/jig.200298]
-
Li L Z, Bao J M, Zhang T, Yang H, Chen D, Wen F and Guo B N. 2020a. Face X-ray for more general face forgery detection//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE: 5000-5009 [DOI: 10.1109/CVPR42600.2020.00505]
-
Li Y Z, Yang X, Sun P, Qi H G and Lyu S. 2020b. Celeb-DF: a large-scale challenging dataset for deepfake forensics//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE: 3204-3213 [DOI: 10.1109/CVPR42600.2020.00327]
-
Lin T Y, Goyal P, Girshick R, He K M and Dollár P. 2017. Focal loss for dense object detection//Proceedings of 2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy: IEEE: 2999-3007 [DOI: 10.1109/ICCV.2017.324]
-
Liu H G, Li X D, Zhou W B, Chen Y F, He Y, Xue H, Zhang W M and Yu N H. 2021. Spatial-phase shallow learning: rethinking face forgery detection in frequency domain//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE: 772-781 [DOI: 10.1109/CVPR46437.2021.00083]
-
Liu Z Z, Qi X J and Torr P H S. 2020. Global texture enhancement for fake face detection in the wild//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE: 8057-8066 [DOI: 10.1109/CVPR42600.2020.00808]
-
Lukas J, Fridrich J and Goljan M. 2005. Determining digital image origin using sensor imperfections//Proceedings Volume 5685, Image and Video Communications and Processing 2005. San Jose, USA: SPIE: 249-260 [DOI: 10.1117/12.587105]
-
Masi I, Killekar A, Mascarenhas R M, Gurudatt S P and AbdAlmageed W. 2020. Two-branch recurrent network for isolating deepfakes in videos//Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer: 667-684 [DOI: 10.1007/978-3-030-58571-6_39]
-
Matern F, Riess C and Stamminger M. 2019. Exploiting visual artifacts to expose deepfakes and face manipulations//Proceedings of 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW). Waikoloa, USA: IEEE: 83-92 [DOI: 10.1109/WACVW.2019.00020]
-
Nguyen H H, Fang F M, Yamagishi J and Echizen I. 2019a. Multi-task learning for detecting and segmenting manipulated facial images and videos//Proceedings of the 10th IEEE International Conference on Biometrics Theory, Applications and Systems (BTAS). Tampa, USA: IEEE: 1-8 [DOI: 10.1109/BTAS46853.2019.9185974]
-
Nguyen H H, Yamagishi J and Echizen I. 2019b. Capsule-forensics: using capsule networks to detect forged images and videos//Proceedings of 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Brighton, UK: IEEE: 2307-2311 [DOI: 10.1109/ICASSP.2019.8682602]
-
Qian Y Y, Yin G J, Sheng L, Chen Z X and Shao J. 2020. Thinking in frequency: face forgery detection by mining frequency-aware clues//Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer: 86-103 [DOI: 10.1007/978-3-030-58610-2_6]
-
Rössler A, Cozzolino D, Verdoliva L, Riess C, Thies J and Niessner M. 2019. FaceForensics++: learning to detect manipulated facial images//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul. Korea (South): IEEE: 1-11 [DOI: 10.1109/ICCV.2019.00009]
-
Woo S, Park J, Lee J Y and Kweon I S. 2018. CBAM: convolutional block attention module//Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer: 3-19 [DOI: 10.1007/978-3-030-01234-2_1]
-
Xu Y Y, Yan W, Yang G K, Luo J L, Li T, He J N. 2020. CenterFace: joint face detection and alignment using face as point. Scientific Programming, 2020: 7845384 [DOI:10.1155/2020/7845384]
-
Yu N, Davis L and Fritz M. 2019. Attributing fake images to GANs: learning and analyzing GAN fingerprints//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South): IEEE: 7555-7565 [DOI: 10.1109/ICCV.2019.00765]
-
Zhao H Q, Wei T Y, Zhou W B, Zhang W M, Chen D D and Yu N H. 2021. Multi-attentional deepfake detection//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, USA: IEEE: 2185-2194 [DOI: 10.1109/CVPR46437.2021.00222]
-
Zhou P, Han X T, Morariu V I and Davis L S. 2017. Two-stream neural networks for tampered face detection//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Honolulu, USA: IEEE: 1831-1839 [DOI: 10.1109/CVPRW.2017.229]


