|
|
|
发布时间: 2022-09-16 |
多媒体智能安全 |
|
|
|


|
收稿日期: 2021-08-24; 修回日期: 2021-12-28; 预印本日期: 2022-01-04
基金项目: 安徽省重点研发计划资助(202004d07020011, 202104d07020001);教育部人文社会科学研究青年基金项目(19YJC870021);广东省类脑智能计算重点实验室开放课题(GBL202117);中央高校基本科研业务费专项资金资助(PA2021GDSK0073, PA2021GDSK0074, PA2022GDSK0037)
作者简介:
张国富, 1979年生, 男, 教授, 主要研究方向为人工智能及多媒体安全。E-mail: zgf@hfut.edu.cn
肖锐, 男, 硕士研究生, 主要研究方向为音频取证和软件工程。E-mail: 2019170915@mail.hfut.edu.cn 苏兆品, 通信作者, 女, 副教授, 主要研究方向为多媒体安全和机器学习。E-mail: szp@hfut.edu.cn 廉晨思, 女, 工程师, 主要研究方向为语音鉴真。E-mail: lchsi324@163.com 岳峰, 男, 副研究员, 主要研究方向为软件工程和多媒体安全。E-mail: yuefeng@hfut.edu.cn *通信作者: 苏兆品 szp@hfut.edu.cn
中图法分类号: TN912.3
文献标识码: A
文章编号: 1006-8961(2022)09-2697-11
|
摘要
目的 随着各种功能强大的音频编辑软件的流行, 使得不具备专业知识的普通用户也可以轻松随意地对数字音频文件进行编辑甚至是恶意篡改, 这给数字音频的鉴真带来了极大挑战。其中, copy-move篡改是将同一段音频中的部分区域复制粘贴到其他部分, 从而实现对音频的语义篡改。由于其篡改片段的特性与原始音频文件匹配度极高, 导致检测难度极大, 已成为音频取证领域的一个研究热点。然而, 现有研究大多基于语音端点检测技术, 只能检测出整个有声片段是否发生篡改, 而无法准确定位篡改的具体位置。为此, 本文提出一种基于多特征决策融合的音频copy-move篡改检测与定位方法。方法 首先利用基于谱熵法的语音端点检测技术将音频划分为若干静音段和有声段, 并基于能熵比方法进一步对有声段进行字节分割; 然后提取每个字节的基音频率特征、颜色自相关图特征和短时能量特征, 并利用动态时间规整距离计算任意两个字节在基音频率特征上的相似度, 采用余弦距离计算两个字节在颜色自相关图特征上的相似度, 利用短时能量和差值计算两个字节在短时能量特征上的相似度; 最后基于多特征决策融合准确定位篡改位置。结果 在相关数据集上的对比实验结果表明, 本文提出的多特征决策融合方法在精确率和召回率上均优于对比方法, 达到了90%以上。在检测的精确率上平均提升了约16%, 在召回率上平均提升了约26%。此外, 在定位的精准度上平均提升了约45%。而且, 在对数据集进行一些常规信号处理攻击后, 本文方法仍可以达到94%以上的检测准确率和召回率, 且在检测的精确率上平均提升了约16%, 在召回率上平均提升了约31%。结论 本文方法不仅具有更高的检测精确率、召回率和定位精准度, 而且对常规信号处理攻击也具有更好的鲁棒性。
关键词
音频取证; copy-move篡改; 检测与定位; 多特征决策融合; 基音频率; 颜色自相关图; 短时能量
Abstract
Objective Forensic-oriented digital audio technology has been intensively developing in terms of the growth of audio recordings. Digital audio recordings can be as the evidences for the legal disputes issue of civil litigation in common. However, the original semantic information of the audio recordings can be changed very easily by widely via several of digital audio editing software and their online tutorials. Consequently, audio forensics are challenged of the real or fake issue derived from tampered audio recording behavior. A copy-move forgery can distort the original recordings through audio clip. The source and the target segments in the copy-move forgery are both derived from the same audio recording compared to splicing and synthesized forgeries. Such attributes like amplitude, frequency, length, noise, tone, and even velocity can be well-matched between the forged segments and the recording, especially for the segments of very short duration for utterances. The requirement of blind audio tampering detection has promoted blind audio forensics via the copy-move forgery detection and localization on digital audio recordings. However, most of the existing methods divide the audio recording into very short multiple segments based on voice activity detection (VAD) related techniques. The accuracy of localization and forgery is challenged although the two similar segments can be identified within the recording. We facilitate multi-feature decision fusion method for detecting and localizing the audio copy-move forgeries. Method First, the audio recording is segmented into many voiced and unvoiced parts in terms of spectral-entropy-based VAD technology. Next, all the voiced segments are further split into syllables, each of which contains a Chinese character only according to the energy to spectral entropy ratio. Then, the pitch frequency, color auto-correlogram, and short-time energy features of each syllable are extracted respectively. The similarity of any two syllables on the pitch frequency features is calculated by the dynamic time warping distance. The similarity of the two syllables on the color auto-correlogram features is obtained by the cosine distance, and the similarity of the two syllables on the short-time energy features is generated by the difference of the short-time energy sum, respectively. Finally, audio forgeries are accurately localized on the basis of multi-feature decision fusion and the three similarities mentioned above. In detail, a copy-move forgery has occurred, and the approximate forgery locations are preliminarily determined for any two pending syllables if each similarity of the two syllables cannot meet the requirement of pre-specified threshold. After that, two new syllables are constructed through both of the two forged syllables by one frame. It is calculated by the three similarities of the new syllables compared to the threshold. If each similarity is still less than the threshold, the two syllables are extended by one frame again until one of the three similarities is beyond the corresponding threshold. The phase of two new syllables positions are based on forgery locations exaction only. Result A classical database is used to generate our copy-move forged dataset, which includes 500 authentic recordings and 500 forged recordings. The comparative analyses show that our proposed multi-feature decision fusion method has their potentials in terms of precision and recall of more than 97%. Specifically, the detection precision of the proposed method is improved by roughly 16 percentage points, the recall is improved by about 26 percentage points, and the localization accuracy is improved by more than 45% on average. Additionally, our detection precision and recall can reach more than 94% as well via common signal processing attacks like Gaussian noise addition, low-pass filtering, down-sampling, up-sampling, and MP3 format compression. Moreover, the detection precision is improved by about 16 percentage points, and the recall is improved by about 31 percentage points. Conclusion Our method not only has higher detection precision, recall, and localization accuracy, but also has better robustness against common signal processing attacks.
Key words
audio forensics; copy-move forgery; detection and localization; multi-feature decision fusion; pitch frequency; color auto-correlogram; short-time energy
0 引言
随着数字音频技术的发展, 社交软件如微信、QQ和米聊等均提供语音和实时语聊功能。这些语音功能不仅可用于日常交流, 还经常用于买卖、租赁和借贷等商业活动(杨鹏等, 2015)。当发生侵权纠纷时, 语音可作为证据在法庭上使用。但是, 根据2016年最高人民法院、最高人民检察院和公安部联合印发的《关于办理刑事案件收集提取和审查判断电子数据若干问题的规定》, 当电子数据系篡改、伪造或者无法确定真伪, 或者电子数据有增加、删除和修改等影响电子数据真实性的情形, 电子数据则不得作为定案的根据。因此, 音频真实性鉴别是音频能否作为法庭证据的一个基本前提, 是音频取证迫切需要解决的一个现实问题。
通常, 音频篡改操作包括对音频文件进行插入、删除、复制粘贴和拼接等, 以破坏、扭曲或者伪造新的语义, 达到断章取义、掩盖细节的目的。其中, copy-move篡改是指将部分语音片段复制并粘贴到同一音频文件中的其他位置, 以改变在原始音频文件中发生的事件或对话。这些操作可以通过各种功能强大的音频编辑软件轻松实现且很难发现。与其他音频篡改类型(如拼接和合成伪造)不同, 在copy-move篡改中, 音频源片段和目标片段都来自同一音频文件。因此, 许多基本的特性, 例如振幅、频率、长度、噪声、音调甚至速度, 都可以在伪造片段和音频文件之间很好地匹配, 尤其当伪造片段是持续时间很短的话语, 这大大增加了盲音频篡改检测的难度。因此, copy-move篡改检测是音频鉴真面临的一个极具挑战性的课题, 已成为音频取证领域中的一个研究热点。
1 相关工作
针对copy-move篡改检测, 当前主流的方法大都基于语音端点检测(voice activity detection, VAD)技术将音频文件划分成若干有声段和静音段, 然后通过计算所有有声段或字节之间的相似性来判断是否存在copy-move篡改。VAD旨在从复杂语音信号中区分有声片段和静音片段, 并确定每个有声片段的起始位置, 是语音检测、语音识别和语音增强等领域的一种重要技术。VAD通常包括特征提取和判决两个方面, 常用的特征参数有谱熵、短时能量和短时过零率等, 判别方法有单/双门限、统计模型和机器学习等。
Xiao等人(2014)利用快速卷积算法将完整的音频文件按时间跨度划分为固定等长的片段, 然后计算任意两个片段之间波形的相似程度。Wang等人(2017)计算每个有声段的离散余弦变换系数, 并采用奇异值分解算法得到奇异向量特征, 使用欧氏距离来衡量有声段的相似性。Imran等人(2017)通过局部二值模式编码提取每个有声段的特征, 然后将均方误差(mean square error, MSE)和能量比率结合使用计算相似性。Yan等人(2015)首先使用归一化低频能量比(normalized low frequency energy ratio, NLFER)方法区分静音段和有声段, 然后提取每个有声段的YAAPT(yet another algorithm for pitch tracking)特征(Kasi和Zahorian, 2002), 最后综合使用皮尔逊相关系数(Pearson correlation coefficients, PCC)和均方差值(average difference, AD)来衡量有声段的相似度。
为了提高算法的鲁棒性, Yan等人(2019)提取每个有声段的基音频率和共振峰(pitch and formant, PF)特征, 使用动态时间规整(dynamic time warping, DTW)距离计算任意有声段之间的相似度, 设计了一种PF-DTW检测方法。Mannepalli等人(2019)首先提取每个有声段的梅尔倒谱系数特征, 然后采用DTW算法来计算任意两个有声段的相似度。Li等人(2019)使用有限长单位冲激响应滤波器来计算基音频率序列之间的差异。Liu和Lu(2017)以及Huang等人(2019)首先提取每个有声段的离散傅里叶变换(discrete Fourier transform, DFT)特征, 然后根据特征点对有声段进行快速排序, 并采用PCC来计算每个有声段和其相邻的几个有声段之间的相似度, 提出一种DFT-PCC检测方法。KüÇükuǧurlu等人(2020)提取每个有声段的直方图特征, 并采用MSE计算任意两个局部二值模式(local binary pattern, LBP)特征直方图的相似性, 设计了一种LBP-MSE检测方法。
需要指出的是, 上述研究虽然能够发现音频文件存在copy-move篡改, 但往往很难准确定位到copy-move篡改的具体位置, 难以满足实际司法取证需求。例如, 在实际的音频鉴真中, 经常会出现对一个有声片段内的某一个字或几个字被复制粘贴。例如, 将“我没做”篡改成“我有做”。在这种情况下, 不仅需要确定是否发生了篡改, 还需要准确指出篡改的位置, 即哪个字是伪造的。已有研究大都只能检测出整个有声片段是否发生了copy-move篡改, 而很难准确指出哪个字是伪造的, 即很难准确给出伪造字节所在的位置。
基于上述背景, 本文在充分调研和总结分析已有工作的基础上, 首先利用VAD技术划分出音频文件中的每个字节, 从频域、空间域和时域角度分别提取一种特征。对于音频文件中的任意两个字节, 根据每个特征计算一个相似度, 然而基于多特征决策融合(multi-feature decision fusion, MFDF)准确定位copy-move篡改位置, 最后基于相关数据集(Wang和Zhang, 2015)对所提方法进行测试和验证。
2 基于MFDF的copy-move篡改检测与定位方法
本文所提的音频copy-move篡改检测与定位方法MFDF总体流程如图 1所示。首先利用VAD技术将音频分为静音段和有声段, 并进一步对有声段进行字节分割, 然后提取每个字节的基音频率特征、颜色自相关图特征和短时能量特征。对于音频文件中任意两个字节, 利用DTW距离计算其在基音频率特征上的相似度, 利用余弦距离计算其在颜色自相关图特征上的相似度, 利用短时能量和差值计算其在短时能量特征上的相似度, 然后基于多特征决策融合确定copy-move篡改的具体位置。
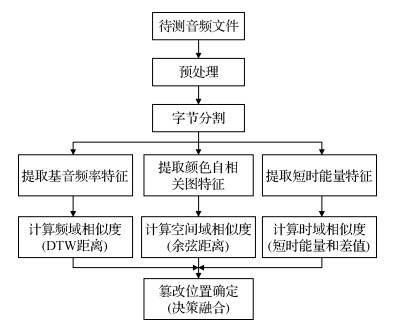

为了更加清晰地说明图 1所示的copy-move篡改检测与定位MFDF方法, 详细介绍框架中的一些关键步骤。
2.1 预处理
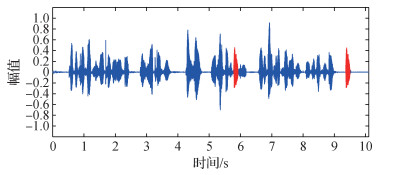
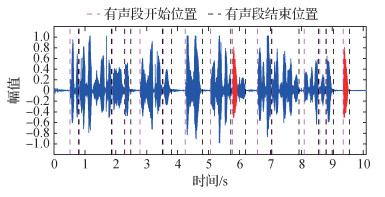
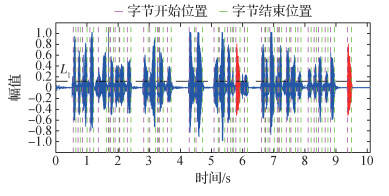
为了尽可能减少噪声和静音段的影响, 需要将待测音频文件进行音量标准化、分帧和加窗, 并利用基于谱熵法的VAD技术(Jin和Cheng, 2010)将音频划分为若干有声段和静音段。图 2为一段待检测的音频, 图 3是利用VAD分割的结果。可以看到, 预处理后, 可以把整个音频文件分割成许多的有声段和静音段, 从而为下一步的字节分割打下基础。
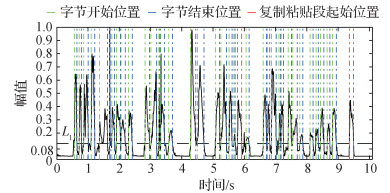
2.2 字节分割
为了提高copy-move篡改检测和定位的准确度, 本文基于能熵比方法(Wang和Tasi, 2008)进一步对划分出的有声段进行字节分割, 以实现每个字节包含一个完整的汉字。假设对音频信号分割后的有声段信号为
1) 首先对
| $E_c=\sum\limits_{q=0}^{G / 2} X_c(q) \overline{X_c}(q)$ | (1) |
| $H_c=-\sum\limits_{q=0}^{G / 2} \frac{X_c(q) \overline{X_c}(q)}{E_c} \log \frac{X_c(q) \overline{X_c}(q)}{E_c}$ | (2) |
式中,
2) 计算第
| $E E F_c=\sqrt{1+\left|E_c / H_c\right|}$ | (3) |
3) 将
经过上述处理后, 有声段信号
2.3 多特征提取与相似度计算
为了保证音频复制粘贴检测高准确率的同时, 进一步降低检测误检率, 本文从音频的频域、空间域和时域3个域出发分别提取基音频率、颜色自相关图特征和短时能量。在频域, 说话人声带振动频率即为基音频率, 作为音频频域具有代表性的特征能有效准确地体现说话人不同字节的差距。在空间域, 语谱图的出现对语音分析起到了十分关键的作用, 包含了丰富的语音信息。颜色自相关图不仅包含了颜色像素在同一幅图像中所占比例, 还包含了空间关系信息。在时域, 说话人语音都会携带能量, 短时能量作为经典的时域特征, 已广泛用于语音信号处理中。本文将这3种不同域的典型特征综合起来考虑, 以期全面感知音频信号的细微变化。
2.3.1 基音频率特征
基音频率是音频频域常用特征之一, 常用于识别发音源。对于分割得到的任一字节
1) 计算帧
| $R_{i_a}(v)=\sum\limits_{l=1}^{N-l} S_{i_a}(l) S_{i_a}(l+v)$ | (4) |
| $D_{i_a}(v)=\frac{1}{N} \sum\limits_{l=0}^{N-v-1}\left|S_{i_a}(l+v)-S_{i_a}(l)\right|$ | (i) |
式中,
2) 计算帧
| $Q_{i_a}(v)=\frac{R_{i_a}(v)}{D_{i_a}(v)}$ | (6) |
3) 在
按照上述步骤, 可以求得任一字节
| $d t w\left(f_{i_r}, f_{j_q}\right)=\operatorname{dist}\left(f_{i_r}, f_{j_q}\right)+\min \left[d t w\left(f_{i_{r-1}}, f_{j_q}\right)\right.\\ \left.d t w\left(f_{i_{r-1}}, f_{j_{q-1}}\right), d t w\left(f_{i_r}, f_{j_{q-1}}\right)\right]$ | (7) |
| $\operatorname{\mathit{dist}}\left(f_{i_r}, f_{j_q}\right)=\left|f_{i_r}-f_{j_q}\right|$ | (8) |
式中,
2.3.2 颜色自相关图特征
语谱图是一种以可视化形式反映语音信号频谱特性的方式, 可以观察语音不同频段的信号强度随时间的变化情况, 反映了音频的空间域特征。对于任一字节
1) 首先生成语音字节
2) 将语谱图
| $t\left(p_{U_1, V_1}, p_{U_2, V_2}\right)=\left|p_{U_1, V_1}-p_{U_2, V_2}\right|=\\ \quad \max \left\{\left|U_1-U_2\right|, \left|V_1-V_2\right|\right\}$ | (9) |
3) 假设
| $\delta_{\omega_r}=\operatorname{\mathit{Pr}}\left[t\left(p_{U_1, V_1}, p_{U_2, V_2}\right)=z\right]$ | (10) |
式中,
| $\cos _{i, j}=\frac{\sum\limits_{\tau=1}^{64} \delta_{i, \tau} \times \delta_{j, \tau}}{\sqrt{\sum\limits_{\tau=1}^{64} \delta_{i, \tau}^2} \times \sqrt{\sum\limits_{\tau=1}^{64} \delta_{j, \tau}^2}}$ | (11) |
2.3.3 短时能量特征
语音短时能量指的是一帧时间内的语音能量, 是语音信号典型的时域特征, 通常作为辅助的特征参数用于语音识别。对于任一字节
| $E_{i_a}=\sum\limits_{l=0}^{N-1} y^2(l)$ | (12) |
式中,
| $E_i=\sum\limits_{a=1}^{n_i} E_{i_a}$ | (13) |
基于此, 字节之间的相似性可采用短时能量和的差值进行度量。对任一两个字节
| $\Delta_{i, j}=E_i-E_j$ | (14) |
2.4 决策融合
为了提高copy-move篡改检测与定位的准确性, 本文基于多特征决策融合(谭等泰等, 2020)设计了一种MFDF方法, 主要步骤如下:
1) 对于一个待测音频文件, 根据第2.3.1、2.3.2和2.3.3节的方法计算音频中任意两个字节
2) 将计算出的特征相似度分别与其设定的阈值
3) 对于每一个copy-move字节对, 分别首尾各扩展一帧构成新的两个字节, 计算新的两个字节3个特征的相似度并继续与阈值进行比较。
4) 如果仍然同时满足
需要指出的是, 本文基于MFDF方法进行copy-move篡改判定, 所以在设置阈值时尽可能设置较低的阈值以确保低误检率。同时, 非copy-move字节要想满足MFDF的判定条件十分困难, 因为需要3个特征值相似度同时满足各自的阈值。因此, 本文可以将阈值稍微放大一点, 预留一定的判断缓冲空间, 而不会影响判定结果。此时, 只要两个字节其中某个特征值相似度大于所设置的阈值, 则直接判定为非copy-move字节对, 这样处理可以在一定程度上增加MFDF方法对常规信号处理攻击的抵抗能力。
3 实验结果与分析
为了验证本文MFDF方法的有效性, 与最新的DFT-PCC(Liu和Lu, 2017)、PF-DTW(Yan等, 2019)和LBP-MSE(KüÇükuǧurlu等, 2020)3种方法进行对比分析。
3.1 数据集与参数设置
本文基于清华大学的开源中文语料库(http://www.openslr.org/18)(Wang和Zhang, 2015)构建本文的copy-move音频数据集。本文数据集主要包括两部分:500条原始音频和500条copy-move篡改音频。500条原始音频直接从语料库中随机抽取。在copy-move篡改检测中, 复制粘贴的操作越多, 越容易被检测出来。因此, 为了衡量检测方法对细微篡改的灵敏度, 与已有工作一样(Liu和Lu, 2017;Yan等, 2019;KüÇükuǧurlu等, 2020), 采用Cool Edit Pro音频编辑软件构建500条copy-move篡改音频数据集, 对每一条原始音频随机挑选出一个完整字节复制粘贴到这条语音的其他位置。所有音频均为wav格式文件, 采样率为16 kHz, 量化位数为16 bits。需要指出的是, 本文方法以及对比方法均不是机器学习方法, 故可直接基于数据集进行检测, 不需要训练集。
采用实验法, 即结合已有工作并基于数据集通过大量测试获得结果相对较好的阈值, 这也是目前常用的确定参数的方法。其中, MFDF方法的相似度阈值为
所有方法的代码均基于MATLAB编写, 并在Intel(R) Core(TM) i7-7700 CPU @ 3.60 GHz、RAM 8.0 GB、Windows 7操作系统的个人PC上进行测试。
与对比方法(Liu和Lu, 2017;Yan等, 2019;KüÇükuǧurluurlu等, 2020)一样, 本文采用精确率(precision)和召回率(recall)作为copy-move篡改检测的评价指标, 分别计算为
| $p=\frac{T P}{T P+F P}$ | (15) |
| $r=\frac{T P}{T P+F N}$ | (16) |
式中,
采用绝对误差值来衡量不同方法在copy-move篡改定位上的精准度。
3.2 MFDF的有效性
以图 2所示的待测音频测试并分析本文MFDF方法在copy-move定位上的有效性。在图 2中, 红色部分即为copy-move篡改字节, 其真实位置为5.779~5.940 s和9.357~9.519 s。从图 5可以看出, 该copy-move篡改字节对分别位于第22个字节和第37个字节。
图 6—图 8分别给出了两两不同字节之间的相似度指标值(即DTW距离、余弦距离、短时能量和差值)的3维Mesh平面视角图。因为同一对字节之间的相似度一致, 例如字节1和7之间的相似度与字节7和1之间的相似度值相同, 所以只绘制了上半区域。其中, 图片下方的横线指的是设定的相似度阈值, 以观察有多少字节对之间的相似度在阈值以下。从图 6可以看出, 有7对字节的DTW距离小于阈值50, 分别为第2和第10字节、第2和第36字节、第4和第36字节、第6和第13字节、第10和第35字节、第15和第27字节、第22和第37字节。从图 7可以看出, 有28对字节的余弦距离小于阈值0.015, 和DTW结果重叠的只有2对字节:第15和第27字节、第22和第37字节。从图 8可以看出, 有13对字节的短时能量和差值小于阈值5, 和DTW结果、余弦距离重叠的只有1对字节:第22和第37字节。
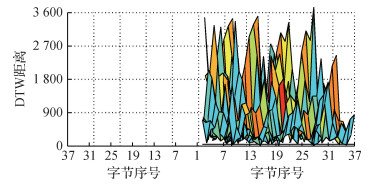
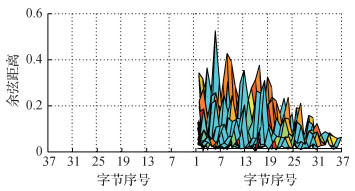
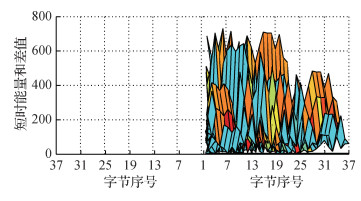
经过MFDF处理, 从频域、时域和空间域3个层面将可疑字节对从DTW的7对最终减少到1对, 进一步降低了误检率, 并初步确定出copy-move篡改位置在第22个字节和第37个字节, 分别位于5.782 5~5.917 5 s与9.362 5~9.497 5 s。进一步地, 分别对第22个字节和第37个字节前后进行逐帧扩展, 最终更加精确地定位copy-move篡改位置区域在5.780 0~5.920 0 s和9.360 0~9.500 0 s, 与该copy-move篡改的真实位置(5.779~5.940 s和9.357~9.519 s)已经非常接近。上述实验结果表明, 对于copy-move篡改, 基于MFDF要比单特征决策更加精准, 可显著降低误检率。
表 1给出了MFDF方法在全库上的消融实验。从表中可以看出, 当只利用单个特征进行篡改检测, 虽然未被检测出来的样本数很少, 但是检测的精确率很低, 误检率太高。当利用两个特征进行篡改检测, 精确率有所提升, 但误检率依然很高。当利用MFDF方法(利用3个特征)进行篡改检测, 不仅保持了较高的召回率, 而且获得了较高的精确率, 大大降低了误检率。
表 1
MFDF方法的全库消融实验结果
Table 1
Ablation experimental results of MFDF
| /% | |||||||||||||||||||||||||||||
| DTW距离 | 余弦距离 | 短时能量和差值 | 精确率 | 召回率 | |||||||||||||||||||||||||
| √ | - | - | 52.2 | 99.8 | |||||||||||||||||||||||||
| - | √ | - | 50.7 | 100.0 | |||||||||||||||||||||||||
| - | - | √ | 50.0 | 99.8 | |||||||||||||||||||||||||
| √ | √ | - | 75.2 | 99.6 | |||||||||||||||||||||||||
| √ | - | √ | 78.2 | 98.2 | |||||||||||||||||||||||||
| - | √ | √ | 75.9 | 98.0 | |||||||||||||||||||||||||
| √ | √ | √ | 97.1 | 97.0 | |||||||||||||||||||||||||
| 注:“√”表示消融实验选用的特征, “-”表示未选用, 加粗字体表示各列最优结果。 | |||||||||||||||||||||||||||||
3.3 与已有方法的对比
基于copy-move数据集中的1 000条音频文件, 对比分析MFDF、DFT-PCC(Liu和Lu, 2017)、PF-DTW(Yan等, 2019)和LBP-MSE(KüÇükuǧurlu等, 2020)的性能。
表 2给出了4种方法的检测结果。可以看出, 本文MFDF方法在精确率和召回率上均优于其他方法, 均达到了97%以上, 而其他3种方法均在90%以下。具体来说, 相比于PF-DTW、DFT-PCC和LBP-MSE, 精确率分别提升了约12%、11%和26%, 平均提升约16%;召回率分别提升了约26%、28%和33%, 平均提升约29%。上述实验结果表明, 本文MFDF方法对copy-move篡改具有更好的检测效果。
表 2
不同方法的copy-move篡改检测结果
Table 2
Experimental results of different methods to copy-move forgery detection
| /% | |||||||||||||||||||||||||||||
| 指标 | MFDF | PF-DTW | DFT-PCC | LBP-MSE | |||||||||||||||||||||||||
| 精确率 | 97.1 | 85.5 | 86.0 | 71.2 | |||||||||||||||||||||||||
| 召回率 | 97.0 | 70.8 | 68.8 | 64.4 | |||||||||||||||||||||||||
| 注:加粗字体表示各行最优结果。 | |||||||||||||||||||||||||||||
为了进一步对比4种方法定位的精准度, 从4种方法均检测正确的篡改音频中随机挑取了100条进行分析。首先根据MFDF的定位绝对误差值将这100条篡改音频按照升序进行排列, 并统计排序后对应音频序号在PF-DTW、DFT-PCC和LBP-MSE上的定位绝对误差值。其中, 由于PF-DTW和LBP-MSE采用相同的分段方法, 因此其定位绝对误差值相同。图 9给出了4种方法在100条篡改音频上的定位绝对误差值。从图中可以看出, 在100条音频中, MFDF在89条音频上的定位绝对误差值均小于等于其他方法。

表 3给出了4种方法在100条篡改音频上的定位平均绝对误差值。从表中可以看出, 相比于PF-DTW、LBP-MSE和DFT-PCC, MFDF的定位精准度分别提升约43%、43%和49%, 平均提升约45%。上述实验结果表明, 本文MFDF方法在copy-move篡改定位的精准度上要显著优于已有方法, 能够定位到更加精准的copy-move篡改区域。
表 3
不同方法的定位平均绝对误差值
Table 3
Average absolute error of different methods to copy-move forgery localization
| 指标 | MFDF | PF-DTW | DFT-PCC | LBP-MSE |
| 绝对误差值/s | 0.0154 | 0.027 | 0.030 4 | 0.027 |
| 注:加粗字体表示最优结果。 | ||||
3.4 鲁棒性分析
在实际的音频鉴真活动中, 音频篡改操作常常附加一些常规信号处理攻击(Su等, 2018), 以掩盖篡改的痕迹, 例如, 1)加噪:对音频添加30 dB的高斯白噪声;2)滤波:对音频进行中值滤波;3)上采样:对音频分别进行频率18 kHz的上采样;4)下采样:对音频分别进行14 kHz的下采样;5)MP3压缩:对音频进行MP3压缩, 比特率160 kbps, 采样率保持不变。
为了测试4种方法对上述常规信号处理攻击的鲁棒性, 对于1 000条音频, 依次采用一种信号处理进行攻击, 共产生5 000条攻击音频。表 4和表 5分别给出了4种方法在攻击音频数据集上的检测精确率和召回率。可以看出, 经过5种常规信号处理攻击后, 4种方法的精确率和召回率均有所下降, 但本文MFDF方法在精确率和召回率上依然优于对比方法, 且平均值达到了94%以上, 而其他3种方法均在85%以下。具体来说, 相比于PF-DTW、DFT-PCC和LBP-MSE, 平均精确率提升了约16%, 平均召回率提升了约31%。这是因为, 本文MFDF方法分别从频域、空间域和时域3个不同域提取最典型的特征, 可以在一定程度上保证单特征的检测准确率, 然后基于多特征决策融合可进一步提高检测和定位的精准度, 并有效降低误检率。上述实验结果表明, 本文MFDF方法具有很好的鲁棒性, 可以更好地适应一些常规信号处理攻击。
表 4
本文MFDF方法在信号处理攻击音频数据集上的检测精确率
Table 4
Detection precision of MFDF on the dataset attacked by common signal processing
| /% | |||||||||||||||||||||||||||||
| 攻击方式 | MFDF | PF-DTW | DFT-PCC | LBP-MSE | |||||||||||||||||||||||||
| 加噪 | 92.2 | 82.8 | 86.8 | 63.9 | |||||||||||||||||||||||||
| 滤波 | 93.6 | 81.6 | 82.3 | 68.7 | |||||||||||||||||||||||||
| 上采样 | 95.7 | 79.5 | 82.6 | 68.4 | |||||||||||||||||||||||||
| 下采样 | 95.0 | 81.1 | 86.6 | 65.7 | |||||||||||||||||||||||||
| MP3压缩 | 94.9 | 83.4 | 86.4 | 70.9 | |||||||||||||||||||||||||
| 平均值 | 94.3 | 81.7 | 84.9 | 67.5 | |||||||||||||||||||||||||
| 注:加粗字体表示各行最优结果。 | |||||||||||||||||||||||||||||
表 5
本文MFDF方法在信号处理攻击音频数据集上的检测召回率
Table 5
Detection recall of MFDF on the dataset attacked by common signal processing
| /% | |||||||||||||||||||||||||||||
| 攻击方式 | MFDF | PF-DTW | DFT-PCC | LBP-MSE | |||||||||||||||||||||||||
| 加噪 | 97.4 | 64.4 | 66.8 | 53.2 | |||||||||||||||||||||||||
| 滤波 | 96.0 | 67.2 | 68 | 58.4 | |||||||||||||||||||||||||
| 上采样 | 92.4 | 73.8 | 70.2 | 53.8 | |||||||||||||||||||||||||
| 下采样 | 91.4 | 62.6 | 64.4 | 52.8 | |||||||||||||||||||||||||
| MP3压缩 | 96.4 | 67.4 | 67.8 | 66.4 | |||||||||||||||||||||||||
| 平均值 | 94.7 | 67.1 | 67.4 | 56.9 | |||||||||||||||||||||||||
| 注:加粗字体表示各行最优结果。 | |||||||||||||||||||||||||||||
4 结论
音频真实性鉴别是音频能否作为法庭证据的一个重要前提, 是目前音频取证领域一个亟待解决的问题。其中, copy-move篡改将部分语音片段复制并粘贴到同一音频文件中的其他位置, 由于音频源片段和目标片段均来自同一音频文件, 给盲音频篡改检测带来了极大挑战。传统方法擅长检测周期较长的有声分段, 而在面向短复制片段时, 检测和定位精度均不够理想, 难以满足音频鉴真的实际需求。为此, 本文综合考虑音频信号的频域、空间域和时域特性, 提取音频信号的基音频率特征、颜色自相关图特征和短时能量特征, 并通过全库消融实验验证了多特征相较单特征有着更高的精准率和召回率, 误检率得到显著降低。提出一种多特征决策融合(MFDF)的copy-move篡改检测和定位方法。在清华大学开源中文语料库上的测试结果表明, 本文MFDF方法在检测的精确率和召回率上, 以及定位的精准度上均显著优于已有方法, 且对常规信号处理攻击具有很好的鲁棒性。不过, 本文只是针对音频copy-move篡改检测和定位研究的一个初步尝试, 在未来仍有许多工作需要深入研究。首先, 需要考虑引入更多的特征, 以期进一步提升MFDF的检测性能。其次, 还需要考虑一种更加通用的MFDF方法, 以便能够检测和定位各种音频篡改操作, 拓展MFDF检测方法的普适性。
致谢 本文对比方法DFT-PCC(Liu和Lu, 2017)和PF-DTW(Yan等, 2019)的源代码由中山大学计算机学院卢伟教授和深圳大学信息工程学院黄继武教授提供, 在此表示感谢。
参考文献
-
Huang J, Kumar S R, Mitra M, Zhu W J and Zabih R. 1997. Image indexing using color correlograms//Proceedings of 1997 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Juan, USA: IEEE: 762-768 [DOI: 10.1109/CVPR.1997.609412]
-
Huang X C, Liu Z H, Lu W, Liu H M, Xiang S J. 2019. Fast and effective copy-move detection of digital audio based on auto segment. International Journal of Digital Crime and Forensics, 11(2): 47-62 [DOI:10.4018/IJDCF.2019040104]
-
Imran M, Ali Z, Bakhsh S T, Akram S. 2017. Blind detection of copy-move forgery in digital audio forensics. IEEE Access, 5: 12843-12855 [DOI:10.1109/ACCESS.2017.2717842]
-
Jin L and Cheng J. 2010. An improved speech endpoint detection based on spectral subtraction and adaptive sub-band spectral entropy//Proceedings of 2010 International Conference on Intelligent Computation Technology and Automation. Changsha, China: IEEE: 591-594 [DOI: 10.1109/ICICTA.2010.309]
-
Kasi K and Zahorian S A. 2002. Yet another algorithm for pitch tracking//Proceedings of 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing. Orlando, USA: IEEE: I-361-I-364 [DOI: 10.1109/ICASSP.2002.5743729]
-
KüÇükuǧurlu B, Ustubioglu B and Ulutas G. 2020. Duplicated audio segment detection with local binary pattern//Proceedings of the 43rd International Conference on Telecommunications and Signal Processing. Milan, Italy: IEEE: 350-353 [DOI: 10.1109/TSP49548.2020.9163568]
-
Li C, Sun Y M, Meng X B and Tian L H. 2019. Homologous audio copy-move tampering detection method based on pitch//Proceedings of the 19th IEEE International Conference on Communication Technology. Xi'an, China: IEEE: 530-534 [DOI: 10.1109/ICCT46805.2019.8947002]
-
Liu Z H and Lu W. 2017. Fast copy-move detection of digital audio//Proceedings of the 2nd IEEE International Conference on Data Science in Cyberspace. Shenzhen, China: IEEE: 625-629 [DOI: 10.1109/DSC.2017.11]
-
Mannepalli K, Krishna P V, Krishna K V, Krishna K R. 2019. Copy and move detection in audio recordings using dynamic time warping algorithm. International Journal of Innovative Technology and Exploring Engineering, 9(2): 2244-2249 [DOI:10.35940/ijitee.b6678.129219]
-
Su Z P, Zhang G F, Yue F, Chang L J, Jiang J G, Yao X. 2018. SNR-constrained heuristics for optimizing the scaling parameter of robust audio watermarking. IEEE Transactions on Multimedia, 20(10): 2631-2644 [DOI:10.1109/TMM.2018.2812599]
-
Tan D T, Li S C, Chang W W, Li D L. 2020. Multi-feature fusion behavior recognition model. Journal of Image and Graphics, 25(12): 2541-2552 (谭等泰, 李世超, 常文文, 李登楼. 2020. 多特征融合的行为识别模型. 中国图象图形学报, 25(12): 2541-2552) [DOI:10.11834/jig.190637]
-
Wang D and Zhang X W. 2015. THCHS-30: a free Chinese speech corpus [EB/OL]. [2021-08-24]. https://arxiv.org/pdf/1512.01882.pdf
-
Wang F Y, Li C and Tian L H. 2017. An algorithm of detecting audio copy-move forgery based on DCT and SVD//Proceedings of the 17th International Conference on Communication Technology. Chengdu, China: IEEE: 1652-1657 [DOI: 10.1109/ICCT.2017.8359911]
-
Wang K C and Tasi Y H. 2008. Voice activity detection algorithm with low signal-to-noise ratios based on spectrum entropy//Proceedings of the 2nd International Symposium on Universal Communication. Osaka, Japan: IEEE: 423-428 [DOI: 10.1109/ISUC.2008.55]
-
Xiao J N, Jia Y Z, Fu E D, Huang Z, Li Y, Shi S P. 2014. Audio authenticity: duplicated audio segment detection in waveform audio file. Journal of Shanghai Jiaotong University (Science), 19(4): 392-397 [DOI:10.1007/s12204-014-1515-5]
-
Yan Q, Yang R and Huang J W. 2015. Copy-move detection of audio recording with pitch similarity//Proceedings of 2015 IEEE International Conference on Acoustics, Speech and Signal Processing. South Brisbane, Australia: IEEE: 1782-1786 [DOI: 10.1109/ICASSP.2015.7178277]
-
Yan Q, Yang R, Huang J W. 2019. Robust copy-move detection of speech recording using similarities of pitch and formant. IEEE Transactions on Information Forensics and Security, 14(9): 2331-2341 [DOI:10.1109/TIFS.2019.2895965]
-
Yang P, Xie L, Zhang Y N. 2015. Survey on unsupervised spoken term detection for low-resource languages. Journal of Image and Graphics, 20(2): 211-218 (杨鹏, 谢磊, 张艳宁. 2015. 低资源语言的无监督语音关键词检测技术综述. 中国图象图形学报, 20(2): 211-218) [DOI:10.11834/jig.20150207]
-
Zahorian S A, Hu H B. 2008. A spectral/temporal method for robust fundamental frequency tracking. The Journal of the Acoustical Society of America, 123(6): 4559-4571 [DOI:10.1121/1.2916590]


