|
|
|
发布时间: 2022-04-16 |
图像分析和识别 |
|
|
|


|
收稿日期: 2020-09-08; 修回日期: 2020-12-29; 预印本日期: 2021-01-05
基金项目: 浙江省自然科学基金项目(LY19F020017); 嘉兴市级公益性研究计划项目(2020AY10024)
作者简介:
贾可心,1991年生,女,硕士研究生,主要研究方向为智能信息处理、深度学习。E-mail: 276293454@qq.com
马正华,通信作者,男,教授,主要研究方向为嵌入式系统及应用。E-mail:mazh@cczu.edu.cn 朱蓉,女,教授,主要研究方向为智能信息处理、数据挖掘、机器学习。E-mail:zr@zjxu.edu.cn 李永刚,男,副教授,主要研究方向为计算机视觉、图像视频处理和模式识别。E-mail:lyg_gang@163.com *通信作者: 马正华 mazh@cczu.edu.cn
中图法分类号: TP391
文献标识码: A
文章编号: 1006-8961(2022)04-1161-15
|
摘要
目的 海面目标检测图像中的小目标数量居多,而基于深度学习的目标检测方法通常针对通用目标数据集设计检测模型,对图像中的小目标检测效果并不理想。使用一般目标检测模型检测海面目标图像的特征时,通常会出现小目标漏检情况,而一些特定的小目标检测模型对海面目标的检测效果还有待验证。为此,在标准的SSD(single shot multiBox detector)目标检测模型基础上,结合Xception深度可分卷积,提出一种轻量SSD模型用于海面目标检测。方法 在标准的SSD目标检测模型基础上,使用基于Xception网络的深度可分卷积特征提取网络替换VGG-16(Visual Geometry Group network-16)骨干网络,通过控制变量来对比不同网络的检测效果;在特征提取网络中的exit flow层和Conv1层引入轻量级注意力机制模块来提高检测精度,并与在其他层引入轻量级注意力机制模块的模型进行检测效果对比;使用注意力机制改进的轻量SSD目标检测模型和其他几种模型分别对海面目标检测数据集中的小目标和正常目标进行测试。结果 为证明本文模型的有效性,进行了多组对比实验。实验结果表明,模型轻量化导致特征表达能力降低,从而影响检测精度。相对于标准的SSD目标检测模型,本文模型在参数量降低16.26%、浮点运算量降低15.65%的情况下,浮标的平均检测精度提高了1.1%,漏检率减小了3%,平均精度均值(mean average precision,mAP)提高了0.51%,同时,保证了船的平均检测精度,并保证其漏检率不升高,在对数据集中的小目标进行测试时,本文模型也表现出较好的检测效果。结论 本文提出的海面小目标检测模型,能够在压缩模型的同时,保证模型的检测速度和检测精度,达到网络轻量化的效果,并且降低了小目标的漏检率,可以有效实现对海面小目标的检测。
关键词
深度学习; 目标检测; 注意力机制; 深度可分卷积; SSD; 海面小目标检测
Abstract
Objective Object detection on the sea surface plays a key role in the development and utilization of marine resources. The sea environment is complex and changeable, and there are many kinds of objects. Considering the factors such as safety and obstacle avoidance, the shooting process of sea surface object detection images will target on the amount of small and medium-sized objects in the image majority, which puts forward higher requirements for accurate detection of objects on the sea surface. Although some regular object detection methods with good detection results have been proposed, they still face the problems of low detection accuracy and slow detection speed. With the rapid development of deep learning theory, the feature extraction capability of deep learning model is gradually mature, and it is widely used in object detection technology. Compared with the original object detection methods, deep-learning-based object detection method has its priority in speed and accuracy. Deep-learning-based object detection method focuses on the construction of deeper network to improve the detection accuracy. The network model usually has the difficulties with too large parameters, which leads to the slow detection speed. Most of the good detection network can only run on high-performance graphics processor unit (GPU), which requires higher computing power equipment. It will also interfere the detection accuracy of the network if the model is compressed. In addition, the initial deep-learning-based object detection method is a detection model designed for the general object dataset. For the small object in the image, the detection effect is not very ideal. In terms of the characteristics of the sea object detection image, the general object detection model will miss the detection of small objects, and the detection effect of some small-targeted object detection models for sea objects needs to be verified. Method The original data of this demonstration is based on the marine obstacle detection dataset 2 (MODD 2), which is mainly composed of boats, buoys and other sea objects. Total 5 050 images of them are used in the illustrated data. To construct the sea surface object dataset, the boats and buoys are calibrated by calibration software called LabelImg, and processed in accordance with the format of visual object class 2007 (VOC2007) dataset. First, on the basis of standard single shot MultiBox detector (SSD) object detection model, Visual Geometry Group network-16 (VGG-16) backbone network is substituted via depth wise separable convolution feature extraction network based on Xception network. The detection effect of different network models is compared based on variables application, including VGG-16-based SSD network, Mobilenet-based SSD network and Xception-based SSD network. In the process of training, the size of the input image is scaled to the RGB image of 300 × 300 pixels. The following input images are normalized. The trained model is based on the Xception pre-trained model on common objects in context(COCO) dataset. Next, the SSD + Xception object detection model is used as lightweight SSD model based on Xception feature extraction network. The lightweight attention mechanism module is evolved into exit flow layer and Conv1 layer in feature extraction network to improve the detection accuracy, and the detection effect is compared with the model of lightweight attention mechanism module in other layers. The model parameters (params), floating-point operations per second (FLOPs) and the quantity of images can be processed via frames per second (FPS). Precision rate and miss rate are used to evaluate the model. The mean average precision (mAP) are used to evaluate the performance of the model. At last, the small object and normal object in the sea object detection dataset are tested via the lightweight SSD object detection model with improved attention mechanism and other models. Result In order to prove the effectiveness of this model, a quantity of comparative experiments are conducted. Firstly, the parameters and floating-point operation of each model are compared, and the reason of network lightweight is analyzed. The demonstrated illustration analyzed that the model can improve the memory reading and writing speed to achieve the network lightweight effect via Mul deduction and operations adding. But, the compression model will lead to the reduction of network feature expression ability, thus affecting the detection accuracy to a certain extent. The SSD object detection model with Mobilenet as feature extraction network is the lightest, but its detection accuracy is interfered at most, and the mAP is reduced by 2.28%. The SSD + Xception object detection model is opted as the lightweight SSD sea object detection model based on Xception feature extraction network. The model transforms a certain amount of Mul and Add operations only, which reduces the parameter amount by 19.01% and the floating-point operation amount by 18.40%. It garantees the feature expression ability of the model, and maintains the amount of images processed per second based on cutting parameters and floating-point operations. The quantity is basically unchanged, and the detection accuracy is reduced less, which achieves the effect of lightening the network under the condition of a certain detection accuracy. In order to improve the detection accuracy of the lightweight SSD sea object detection model, a lightweight attention mechanism module is issued in the lower layer of the model to focus on some significant or interesting information, which facilitates the illustration of the feature semantic information of small objects. In comparison of the standard SSD target detection model, the analyses demonstrate that the average accuracy of the buoy is increased by 1.1%, the miss detection rate is reduced by 3%, and the mAP is increased by 0.51%, the parameters are reduced by 16.26% and the floating-point operation is reduced by 15.65%. Simultaneously, the average detection accuracy of the boat is guaranteed, and the miss detection error is not generated more. The illustrated model also shows qualified detection effect based on small objects in the dataset verification. Conclusion For the small object detection in the sea image, this small object detection model can identify the detection speed of the model and guarantee the detection accuracy of the model, and achieve the effect of network lightweight. Moreover, this model reduces the rate of missing detection of small objects to realize the detection of small sea objects effectively as well.
Key words
deep learning; object detection; attention mechanism; depthwise separable convolution; single shot multiBox detector (SSD); small object detection on the sea surface
0 引言
中国拥有广阔的水域面积和大量海洋资源,随着对海洋开发需求的不断增长,无论对海洋资源勘探、无人艇避障还是目标攻击等应用,海面目标检测都是重要的研究课题(Zhao等,2014)。然而,海面复杂多变的环境和种类繁多的目标,对精确检测海面目标提出了更高要求,特别是海面小目标检测。进入21世纪以来,以大数据、人工智能为代表的新一代信息技术快速发展,为推动海洋事业发展做出了重要贡献。深度学习模型强大的特征提取能力,使其在目标检测技术中得到广泛应用,使用深度学习模型进行海面目标检测,可为海洋搜救、无人艇业务和智能船舶等提供技术支持。
目标检测技术主要包括基于图像处理并结合机器学习算法的传统目标检测方法和基于深度学习的目标检测方法,如图 1所示。
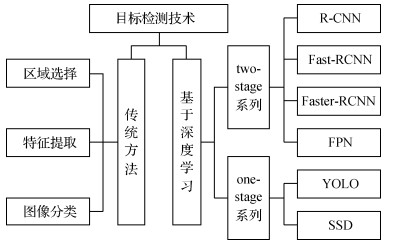

传统的目标检测方法主要有特征匹配法、背景差分法、帧差法和光流法。背景差分法、帧差法和光流法多用于运动目标检测,特征匹配法适用于图像目标检测,主要分为区域选择、特征提取和图像分类3部分。虽然有一些检测效果较好的传统目标检测方法,但面临检测精度低和检测速度慢等问题。相比传统目标检测方法,基于深度学习的目标检测方法在速度和准确率方面均有明显优势。基于深度学习的目标检测方法大致分为两个研究方向:基于目标候选框检测与卷积神经网络结合的two-stage目标检测系列和基于回归的一体化卷积网络one-stage目标检测系列。在two-stage系列中,以区域卷积神经网络(region convolutional neural network, R-CNN)的系列算法为代表算法,逐步实现端到端的目标检测,检测精度得到大幅提升,但网络参数庞大,检测速度较慢(Ren等,2017)。以单次检测器YOLO(you only look once)(Redmon等,2016)和单网多尺度检测器SSD(single shot multiBox detector)(Liu等,2016)为代表算法的one-stage系列算法,相比two-stage检测器,检测速度得到一定幅度提升,但定位精度有所下降,且仍有模型参数过大问题。
基于深度学习的目标检测方法通常是针对通用目标数据集设计的检测模型,对于图像中的小目标来说,检测效果并不是很理想。定义小目标一般有根据绝对尺寸进行定义和根据相对尺寸进行定义两种方式。根据绝对尺寸进行定义时,以COCO(common objects in context)数据集为例,尺寸小于32 × 32像素的目标即为小目标;根据相对尺寸进行定义时,国际光学工程学会(International Society of Photo-Optical Instrumentation Engineers,SPIE)将小目标定义为在256 × 256像素的图像中目标面积小于80像素的目标,即目标面积小于图像面积的0.12%。针对图像中的小目标检测,部分研究在现有检测模型基础上提出了一些改进方法。特征金字塔网络(feature pyramid network,FPN)(Lin等,2017)采用多尺度特征融合方式,通过融合高层语义信息和低层位置信息后的结果来检测目标,该方法是针对通用目标的检测方法,在小目标检测中起到了关键作用,但结果不可控。Bell等人(2016)提出利用上下文信息和多尺度特征改善小目标检测效果。Yang等人(2016)提出根据候选区域尺寸大小提取不同卷积层特征,并使用级联分类器快速提取不含目标的候选区域,提高了小目标的检测精度和速度。检测小目标可以通过使用高层特征图来加强低层特征图的语义信息(Cao等,2018)、增加图像分辨率或融合高分辨率特征与低分辨率图像的高维特征来解决(Menikdiwela等,2017),然而使用较高分辨率的图像会增加计算开销,对设备要求较高。Singh等人(2018)提出一种新的训练思路,利用类似滑动窗口的碎片chips,先粗略定位正负样本的所在区域,然后将该区域作为卷积网络的输入,进行精确检测。该方法摆脱了模型训练时对较高分辨率图像的依赖,对小目标的检测效果也有所提升,但实现过程相对复杂。感知生成对抗网络(perceptual generative adversarial network,PGAN)(Li等,2017)使用生成对抗网络(generative adversarial network, GAN)在卷积网络中构建特征,其中生成器生成小目标的超分表达,判别器能从生成的超分图形中的检测获益量来计算损失值,然后交替执行生成器和判别器网络对抗训练过程,利用大小目标的结构相关性来增强小目标的表达,使其与对应大目标的表达相似,从而提高小目标检测性能,但网络构建的特征在交通标志和行人检测上下文中难以区分大小目标。Chen等人(2016)改进候选区域生成网络,并结合上下文信息采用上采样策略用于小目标检测。Cheng等人(2018)和Ren等人(2018)通过添加上下文信息提高小目标检测的检测效果。Hu和Ramanan(2017)提出一种无约束条件下的低分辨率人脸检测方法,通过在不同大小的模板上分别寻找对应大小的目标,采用超分辨率和细化网络生成真实清晰的高分辨率图像,并引入判别网络对人脸与非人脸进行分类,从而增强人脸检测算法的鲁棒性,但对其他小目标的检测效果有待验证。另外,Kisantal等人(2019)通过对数据集进行预处理,利用过采样和增强的方法提高小目标的检测性能,但大目标的检测效果会受到影响。
目前,基于深度学习的目标检测方法的研究更多集中于构建更深的网络,以达到提高检测精度的目的,网络模型一般存在参数量过于庞大,从而导致检测速度过慢等问题,且大部分检测效果优秀的网络仅能在高性能的图形处理器(graphics processing unit,GPU)上运行,对设备计算能力要求较高,而压缩模型又会影响模型的检测精度。同时,海面图像中目标复杂多样,其中小目标相对较多,通用目标检测模型和一些特定的小目标检测模型对海面目标的检测效果还有待验证。因此,本文在标准的SSD目标检测模型基础上,结合Xception深度可分卷积神经网络结构,在保证一定检测精度的情况下,提出了轻量化的SSD海面目标检测模型。同时,基于提出的轻量化SSD海面目标检测模型,引入轻量级注意力机制模块,在压缩模型的同时保证了目标检测精度,并可有效实现对海面小目标的检测,降低了小目标漏检率。
1 理论基础
1.1 标准的SSD目标检测算法
SSD目标检测算法是Liu等人(2016)提出的一种one-stage深度学习目标检测算法。标准的SSD目标检测算法基于VGG-16(Visual Geometry Group network-16)网络模型,删除末端全连接层,添加辅助卷积层和池化层,提取特征的同时减小特征图的尺寸,并在6个不同尺寸的特征图上进行预测。标准的SSD目标检测算法架构细节如图 2所示。

SSD目标检测算法结合了YOLO算法检测速度快和区域候选网络(region proposal network, RPN)定位精准的优点,采用RPN中的多参考窗口技术,进一步提出在多个分辨率的特征图上进行检测,训练过程中融入难分样本挖掘操作,对图像中难分样本进行聚焦,针对具有多种尺度的目标检测效果较好,但对小目标的检测通常效果不佳。
1.2 Xception网络结构
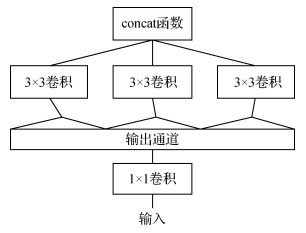
Xception(Chollet,2017)是谷歌公司继inception后提出的inceptionV3的一种改进模型,采用深度可分卷积替换inceptionV3中的多尺寸卷积核。简化的inception模块如图 3所示。

深度可分卷积是轻量化网络的主要结构,由3 × 3和1 × 1卷积核组成,将标准卷积分为深度卷积和逐点卷积,即在输入的每个通道独立执行空间卷积,再进行逐点卷积,将深度卷积的通道输出映射到新的通道空间,简化结构如图 4所示,其主要作用是减少网络参数,加快网络运行速度。
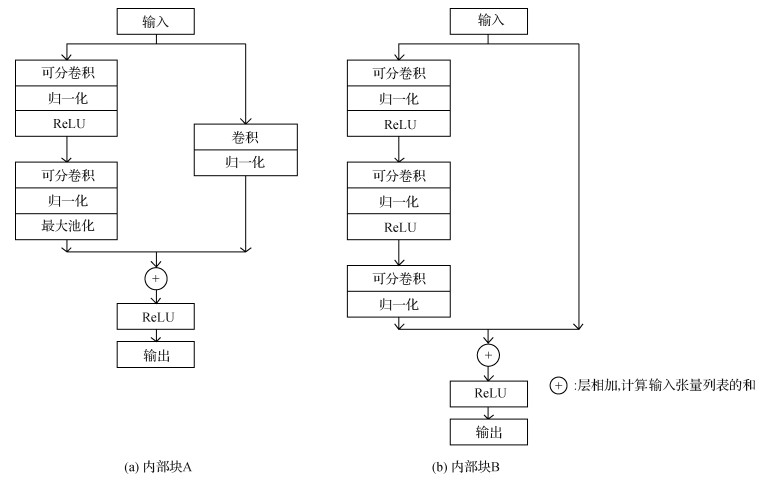
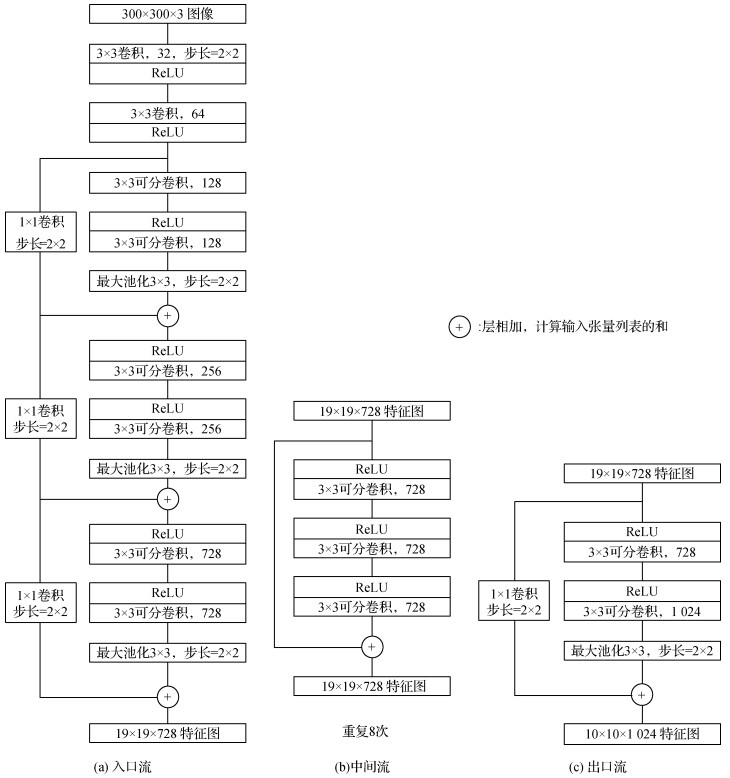
Xception网络是带有残差连接的深度可分卷积层的线性堆叠。基于深度可分卷积,搭配线性残差卷积网络实现内部结构的每个块,使得该结构非常容易定义和修改,主要块结构有两种,如图 5所示。
1.3 注意力机制
深度学习中的注意力机制借鉴了人类的视觉注意力机制,在快速扫描全局图像的同时,获得需要重点关注的目标区域,并对此区域投入更多的注意力资源,以获取关注目标的细节信息,从而抑制其他无用信息。在计算能力有限的情况下,注意力机制是解决信息超载问题的一种分配方案,可将计算资源更多地分配给表征中较有价值的部分。
近年来,在计算机视觉领域中注意力机制的应用逐渐增加,Wang等人(2017)提出使用一种基于注意力的可堆叠的残差学习网络结构,在前向过程中提取模型的注意力,使模型训练更加简单,且易优化和学习,具有较好的性能。Hu等人(2018)通过显式地建立通道间的依赖关系,使网络能够执行动态通道特征,重新自适应地校准通道式的特征响应,提高了网络的表征能力。受此启发,结合SSD目标检测算法的特点,本文引入了轻量级注意力机制模块进行进一步研究。
2 本文模型
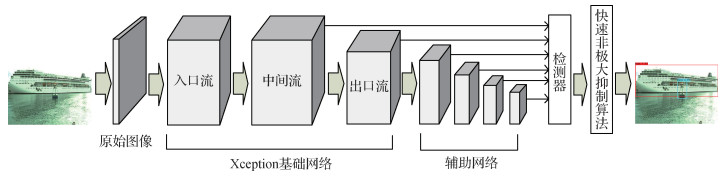
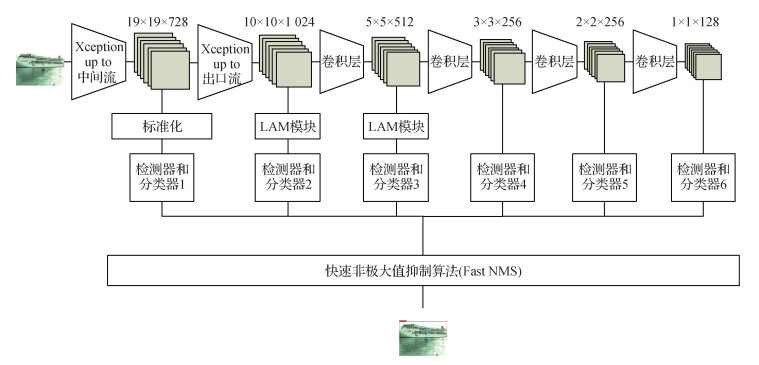
2.1 基于Xception网络的深度可分卷积特征提取网络
标准的SSD目标检测模型采用VGG-16作为特征提取网络,其中使用标准的卷积方式进行密集链接,参数量相对较大。而Xception网络采用深度可分卷积,对过参数化的标准卷积进行压缩,使网络轻量化得到体现。基于Xception网络的深度可分卷积特征提取网络分为入口流(entry flow)、中间流(middle flow)和出口流(exit flow) 3部分,共13个块,其中entry flow有4个,exit flow有1个,主要由Xception内部块结构A组成;middle flow有8个,主要由Xception内部块结构B组成,结构如图 8所示。
本文模型使用深度可分卷积层替代标准卷积层,其中Xception网络的entry flow替代VGG-16中的前4个块,middle flow和exit flow替代VGG-16中的第5个块,后接4个标准卷积层,作为整体特征提取网络。同时,将其中6个卷积层生成的特征图输入到检测模块中进行回归和分类,包括middle flow生成的特征图、exit flow生成的特征图以及后4个标准卷积层生成的特征图。
2.2 轻量级注意力机制模块
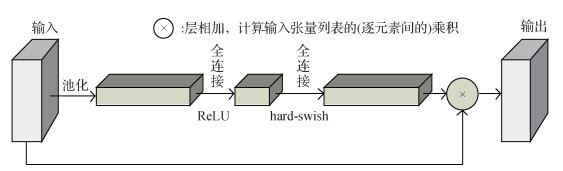
使用深度可分卷积可以减少参数量,但由于失去了大部分可调参数,在一定程度上牺牲了检测精度。为保证轻量化后的SSD目标检测模型的检测精度,本文引入轻量级注意力机制模块(lightweight attention modules,LAM)来提升目标的检测效果。
轻量级注意力机制模块对输入的特征层进行全局平均池化,再分别采用线性整流函数ReLU(rectified linear unit)和
| $ {relu}(\boldsymbol{x})=\min (\max (\boldsymbol{x}, 0), 6) \in[0, 6] $ | (1) |
| $ h-{swish}[\boldsymbol{x}]=\boldsymbol{x} \frac{{relu}(\boldsymbol{x}+3)}{6} $ | (2) |
式中,变量
3 实验与分析
3.1 实验平台
在Windows10 64位操作系统上搭建深度学习开发环境,选用PyCharm作为集成开发环境,实验框架基于Python语言实现。主要配置为16.0 GB内存,Intel Core i7-9750H @ 2.60 GHz CPU,显卡(GPU)型号为NVIDIA GeForce RTX 2060,显存6 GB,显卡计算能力为7.5。深度学习开发环境为JetBrains PyCharm Community Edition 2017.2.4 x64,Python 3.6.5,CUDA 9.0,cuDNN7.6.4.38,tensorflow-GPU 1.9.0和Keras 2.2.0。
3.2 实验数据
实验原始数据来源于海洋障碍检测数据集MODD 2(marine obstacle detection dataset 2)(Bovcon等,2018)。该数据集图像由船(boat)和浮标(buoy)等海面物体组成,原始图像大小为1 278 × 958像素,本文实验采用其中5 050幅图像,检测目标设定为船(boat)和浮标(buoy)两类,并将图像直接缩小到300 × 300像素,如图 10所示,其中包含目标的图像共3 823幅,包含船的图像2 571幅,包含浮标的图像2 041幅,随机选取2 140幅图像用于训练,1 147幅图像用于测试,通过标注软件(LabelImg)对船和浮标进行标定,按照VOC2007(visual object class 2007)数据集格式进行处理,包含目标总数为5 019,其中标签boat的数量为2 840,标签buoy的数量为2 179,构建海面目标检测数据集,并定义本数据集中所占像素面积小于32 × 32像素的目标为小目标。据实验统计,本数据集标签boat的小目标数量为1 150,标签buoy的小目标数量为1 408。

由于本文选取的海面目标检测的数据集样本量不大,若直接使用该数据集从零开始进行训练会导致网络收敛速度慢,检测效果也会受到一定影响。因此,采用迁移学习的方法,利用预训练的模型,对本文数据集进行微调训练。同时,在对海面图像采集设备不做高要求的基础上,一般采集到的海面图像分辨率相对较低,为使本文模型在此情况下也有较好的检测效果,在训练模型前,将图像直接缩小至300 × 300像素。图像缩小后对原始图像中的小目标的分辨率会有一定的影响,后续工作中将考虑直接使用原始图像进行实验,并将图像缩小后的实验结果与直接使用原始图像的实验结果进行对比,为得到检测效果更好的网络模型做准备。
3.3 实验分析
训练过程中,对输入图像进行归一化处理,缩小为300 × 300像素的RGB图像,基于Xception在COCO数据集上预训练的模型进行训练,使用模型参数量(model parameters, params)、浮点计算量(floating-point operations per second,FLOPs)、每秒内可处理的图像数量(frames per second,FPS)、检测精度(precision rate)和漏检率(miss rate)对模型进行评估,并采用平均精度均值(mean average precision,mAP)评估模型在本文数据集上的各类别的性能。检测精度和漏检率的计算公式为
| $ f_{\text {prec }} =\frac{T P}{T P+F P} $ | (3) |
| $ f_{\text {miss }} =\frac{F N}{T P+F N} $ | (4) |
式中,
3.3.1 实验1
实验使用基于Xception网络的深度可分卷积特征提取网络替换VGG-16骨干网络,并通过控制变量,对比不同网络模型的检测效果,包括基于VGG-16的SSD网络(SSD + VGG-16模型)、基于Mobilenet的SSD网络(SSD + Mobilenet模型)以及基于Xception的SSD网络(SSD + Xception模型)。
4种模型的浮点运算量如表 1所示,标准的SSD目标检测模型的浮点运算集中于乘(Mul)和加(Add)运算,计算量较大,内存访问成本较高;其他模型则通过减少Mul和Add运算,提高内存的读写速度,从而达到网络轻量化的效果。
表 1
4种模型的浮点运算量
Table 1
Floating-point operations of four models
| 方法 | Mul | Add | Sub | AssignSub | RealDiv | Rsqrt | AssignAdd | Pow | FLOPs |
| SSD+VGG-16 | 23.87M | 23.87M | 35 | / | / | / | / | / | 47 741 347 |
| SSD+Mobilenet | 6.42M | 6.37M | 63.58 k | 50.69 k | 25.38 k | 25.34 k | 70 | 70 | 12 954 509 |
| SSD+Xception | 19.36M | 19.26M | 127.36 k | 101.63 k | 50.86 k | 50.82 k | 92 | 92 | 38 956 918 |
| 本文 | 20.02M | 19.92M | 127.36 k | 101.63 k | 50.86 k | 50.82 k | 92 | 92 | 40 267 642 |
| 注:“/”表示该网络模型中无此操作。Sub表示减;AssignSub表示赋值,变量减去值;RealDiv表示除;Rsqrt表示平方根;AssignAdd表示赋值,将值加到变量上;Pow表示乘方。 | |||||||||
4种模型的轻量化评价指标的实验结果如表 2所示。对比第1行和第2行结果可以看出,Mul和Add运算的大量减少使得以Mobilenet为特征提取网络的目标检测模型的参数量和浮点运算量均有所降低,同时每秒内可处理图像的数量有所增加,但检测模型的轻量化导致其特征表达能力降低,从而影响了检测精度,mAP降低了2.28%。对比第1行和第3行结果可以看出,以Xception为特征提取网络的SSD + Xception目标检测模型转化一定量的Mul和Add运算,使其参数量降低了19.01%,浮点运算量降低了18.40%,保证了模型的特征表达能力,在减少参数量和浮点运算量的同时,保持每秒内处理图像数量基本不变,检测精度降低较少,达到了在保证一定的检测精度情况下,对网络轻量化的效果。
表 2
4种模型的轻量化评价指标的实验结果
Table 2
Experimental results of lightweight evaluation indexes of four models
| 网络模型 | params | FLOPs | FPS | mAP/% |
| SSD+VGG-16 | 23 879 570 | 47 741 347 | 30.876 97 | 96.39 |
| SSD+Mobilenet | 6 408 110 | 12 954 509 | 38.543 15 | 94.11 |
| SSD+Xception | 19 339 406 | 38 956 918 | 30.080 06 | 95.68 |
| 本文 | 19 996 686 | 40 267 642 | 30.055 49 | 96.90 |
| 注: 加粗字体表示各列最优结果。 | ||||
3.3.2 实验2
实验以基于Xception特征提取网络的SSD+ Xception目标检测模型为轻量化SSD模型,分别在不同输出层引入轻量级注意力机制模块来提高模型的检测精度,并进行检测效果对比,实验结果如表 3所示。
表 3
不同输出层引入轻量化注意力机制对实验结果的影响
Table 3
Effects of different output layers on experimental results by introducing lightweight attention mechanism
| /% | |||||||||||||||||||||||||||||
| 引入轻量化注意力机制的输出层 | mAP | ||||||||||||||||||||||||||||
| 未引入 | 95.68 | ||||||||||||||||||||||||||||
| 中间流+出口流+卷积层1+卷积层2+卷积层3+卷积层4 | 83.76 | ||||||||||||||||||||||||||||
| 中间流+出口流+卷积层1+卷积层2+卷积层3 | 92.65 | ||||||||||||||||||||||||||||
| 中间流+出口流+卷积层1+卷积层2 | 94.18 | ||||||||||||||||||||||||||||
| 中间流+出口流+卷积层1 | 95.41 | ||||||||||||||||||||||||||||
| 中间流+出口流 | 92.81 | ||||||||||||||||||||||||||||
| 中间流 | 88.63 | ||||||||||||||||||||||||||||
| 出口流 | 95.79 | ||||||||||||||||||||||||||||
| 卷积层1 | 93.88 | ||||||||||||||||||||||||||||
| 中间流+卷积层1 | 93.13 | ||||||||||||||||||||||||||||
| 出口流+卷积层1 | 96.90 | ||||||||||||||||||||||||||||
| 注:加粗字体表示最优结果。 | |||||||||||||||||||||||||||||
虽然网络高层的特征语义信息比较丰富,但随着网络逐层升高,图像中的小目标的特征语义信息逐渐淡化,使得检测过程中小目标易漏检。网络低层的特征语义信息较少,但小目标的特征语义信息明确,且目标位置准确,在低层引入注意力机制模块可以将注意力集中在部分显著或感兴趣的信息上,对小目标的特征语义信息表达起到一定积极作用。
从表 3可以看出,在不同输出层引入LAM得到的mAP也不同。在6个特征层均引入LAM的情况下,mAP反而有所下降,随着LAM在特征层的引入逐渐趋于低层化,mAP逐渐增加,在中间流、出口流和卷积层1分别引入LAM时,mAP达到局部最大值。单独在出口流引入LAM时,与未引入LAM的轻量化SSD模型相比,mAP提高了0.11%。在出口流和卷积层1分别引入LAM时,检测效果最好,与未引入LAM的轻量化SSD模型相比,mAP提高了1.22%。
本文模型为在出口流和卷积层1分别引入LAM的轻量化SSD目标检测模型,与其他改进SSD模型的目标检测效果评价指标进行对比,实验结果如表 4和图 11—图 15所示。综合表 2的实验结果,对比本文模型和其他3种模型的目标检测效果,与SSD+Mobilenet和SSD + Xception两种模型相比,虽然本文模型的参数量和浮点计算量有所增加,但检测效果也有所增强,甚至部分指标超过了标准SSD目标检测模型;与标准SSD目标检测模型相比,本文模型每秒处理图像的数量基本不变,并且在参数量降低16.26%、浮点运算量降低15.65%的情况下,buoy的平均精度提高了1.1%,漏检率减小了3%,mAP提高了0.51%,同时保证了boat的平均检测精度,并保证了其漏检率不增加。综上所述,本文模型在使网络轻量化的同时,提高了检测准确率。
表 4
4种模型的目标检测效果评价指标的实验结果
Table 4
Experimental results of object detection effect evaluation indexes of four models
| /% | |||||||||||||||||||||||||||||
| 网络模型 | AP | mAP | 漏检率 | ||||||||||||||||||||||||||
| boat | buoy | boat | buoy | ||||||||||||||||||||||||||
| SSD+VGG-16 | 99.48 | 93.31 | 96.39 | 1 | 12 | ||||||||||||||||||||||||
| SSD+Mobilenet | 97.96 | 90.25 | 94.11 | 3 | 15 | ||||||||||||||||||||||||
| SSD+Xception | 99.02 | 92.34 | 95.68 | 1 | 13 | ||||||||||||||||||||||||
| 本文 | 99.39 | 94.41 | 96.90 | 1 | 9 | ||||||||||||||||||||||||
| 注:加粗字体表示各列最优结果;AP(average precision)为平均精度。 | |||||||||||||||||||||||||||||

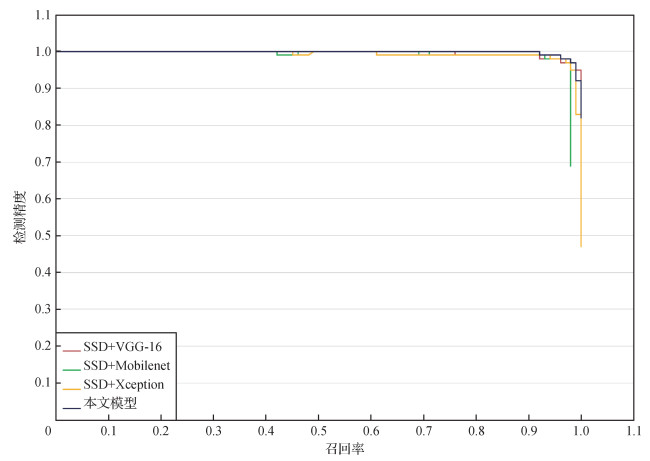
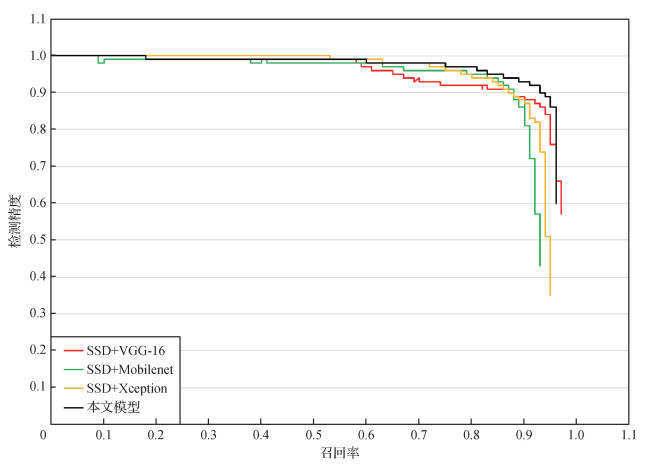
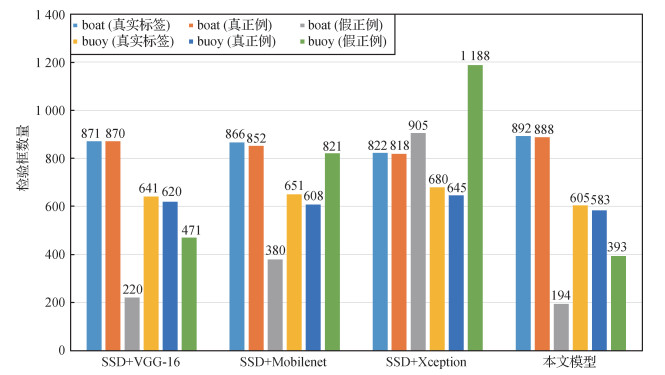
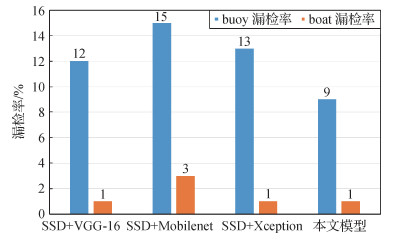
使用本文模型和其他模型分别对图像中的小目标和非小目标进行测试,效果如图 16和图 17所示。可以看出,对图像中的小目标测试时,本文模型优于其他模型,但是对图像中非小目标测试时,几种模型的测试效果基本相同。同时,由图 17可以看出,在对图像中的重叠目标测试时,本文模型的检测效果并不明显。对此,本文从构建的数据集中选取457幅含重叠目标的图像作为测试集对重叠目标进行检测实验,结果如表 5所示,本文模型在对重叠目标进行检测时,mAP值均高于其他3种模型,但是浮标漏检率略高于标准的SSD模型。


表 5
4种模型对重叠目标的检测效果评价指标的实验结果
Table 5
Experimental results of overlapping object detection effect evaluation indexes of four models
| /% | |||||||||||||||||||||||||||||
| 网络模型 | AP | mAP | 漏检率 | ||||||||||||||||||||||||||
| boat | buoy | boat | buoy | ||||||||||||||||||||||||||
| SSD+VGG-16 | 99.78 | 96.86 | 98.32 | 0 | 0 | ||||||||||||||||||||||||
| SSD+Mobilenet | 99.78 | 97.25 | 98.52 | 0 | 3 | ||||||||||||||||||||||||
| SSD+Xception | 99.78 | 96.77 | 98.28 | 0 | 6 | ||||||||||||||||||||||||
| 本文 | 99.78 | 98.77 | 99.28 | 0 | 2 | ||||||||||||||||||||||||
| 注:加粗字体表示各列最优结果。 | |||||||||||||||||||||||||||||
由此可见,由于较低层的特征图蕴含更多小目标的信息,本文模型在较低的特征层中引入轻量级注意力机制,能有效提升小目标检测性能,同时能有效提升重叠目标的检测效果。
使用本文模型与其他目前流行的轻量化目标检测模型进行对比实验,选择在PASCAL VOC2007(pattern analysis, statistical modeling and computational learning visual object classes 2007)数据集上对模型进行训练,并在VOC2007测试集上进行测试。实验结果如表 6所示,虽然Tiny SSD模型最小,但其检测精度相对较低;本文模型比Tiny YOLOv2、Tiny YOLOv3和PeleeNet更轻量化,但在检测精度上优于以上模型。权衡两个检测标准,本文模型取得了较好的检测效果。
表 6
本文模型与其他轻量化目标检测模型的对比实验结果
Table 6
The comparison experimental results between the proposed model and other popular lightweight object detection models
| 网络模型 | 模型大小/MB | mAP/% |
| Tiny YOLOv2 | 59.36 | 57.10 |
| Tiny YOLOv3 | 34.00 | 57.30 |
| PeleeNet | 20.71 | 70.90 |
| LVP-DN | 18.50 | 73.20 |
| Tiny SSD | 2.30 | 61.30 |
| 本文 | 19.07 | 80.10 |
| 注:加粗字体表示最优结果。 | ||
4 结论
本文提出一种注意力机制改进的轻量SSD模型用于海面小目标检测,针对标准的SSD目标检测模型参数量较大、对设备计算能力要求较高等特点,在保证一定的检测精度的情况下,以Xception网络作为特征提取模块对其进行轻量化操作,基于轻量化的SSD目标检测网络,引入轻量级注意力机制模块,对轻量化后的网络进行优化,弥补由于参数量降低带来的检测精度损失,同时提高了对小目标的检测效果。
目前,本文实验只针对船和浮标两类海面目标进行检测,后续考虑增加检测目标种类,统计数据集中的大小目标检测情况,对在不同层引入注意力机制时大小目标的检测精度进行量化对比分析。本文模型将注意力集中于较低特征层,使得高层的特征语义信息相对忽略,从而对图像中部分重叠目标的检测效果有一定的影响,后续考虑利用高层语义特征增加经验知识,继续对网络进行优化,并对海面目标与岸边目标重叠的检测情况进行实验对比分析,以寻求效果更好的网络模型用于海面目标检测。
参考文献
-
Bell S, Zitnick C L, Bala K and Girshick R. 2016. Inside-outside net: detecting objects in context with skip pooling and recurrent neural networks//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE: 2874-2883 [DOI: 10.1109/CVPR.2016.314]
-
Bovcon B, Mandeljc R, Perš J, Kristan M. 2018. Stereo obstacle detection for unmanned surface vehicles by IMU-assisted semantic segmentation. Robotics and Autonomous Systems, 104: 1-13 [DOI:10.1016/j.robot.2018.02.017]
-
Cao G M, Xie X M, Yang W Z, Liao Q, Shi G M and Wu J J. 2018. Feature-fused SSD: fast detection for small objects//Proceedings of SPIE 10615 9th International Conference on Graphic and Image Processing (ICGIP 2017). Qingdao, China: SPIE: 106151E [DOI: 10.1117/12.2304811]
-
Chen C Y, Liu M Y, Tuzel O and Xiao J X. 2016. R-CNN for small object detection//Proceedings of the 13th Asian Conference on Computer Vision. Taipei, China: Springer: 214-230 [DOI: 10.1007/978-3-319-54193-8_14]
-
Cheng P, Liu W, Zhang Y F and Ma H D. 2018. Loco: local context based faster R-CNN for small traffic sign detection//Proceedings of the 24th International Conference on Multimedia Modeling. Bangkok, Thailand: Springer: 329-341 [DOI: 10.1007/978-3-319-73603-7_27]
-
Chollet F. 2017. Xception: deep learning with depthwise separable convolutions//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE: 1800-1807 [DOI: 10.1109/CVPR.2017.195]
-
Hu J, Shen L and Sun G. 2018. Squeeze-and-excitation networks//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, USA: IEEE: 7132-7141 [DOI: 10.1109/CVPR.2018.00745]
-
Hu P Y and Ramanan D. 2017. Finding tiny faces//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE: 1522-1530 [DOI: 10.1109/CVPR.2017.166]
-
Kisantal M, Wojna Z, Murawski J, Naruniec J and Cho K. 2019. Augmentation for small object detection [EB/OL]. [2021-08-20] https://arxiv.org/pdf/1902.07296.pdf
-
Li J N, Liang X D, Wei Y C, Xu T F, Feng J S and Yan S C. 2017. Perceptual generative adversarial networks for small object detection//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE: 1951-1959 [DOI: 10.1109/CVPR.2017.211]
-
Lin T Y, Dollár P, Girshick R, He K M, Hariharan B and Belongie S. 2017. Feature pyramid networks for object detection//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE: 936-944 [DOI: 10.1109/CVPR.2017.106]
-
Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu C Y and Berg A C. 2016. SSD: single shot MultiBox detector//Proceedings of the 14th European Conference on Computer Vision. Amsterdam, the Netherlands: Springer: 21-37 [DOI: 10.1007/978-3-319-46448-0_2]
-
Menikdiwela M, Nguyen C, Li H D and Shaw M. 2017. CNN-based small object detection and visualization with feature activation mapping//Proceedings of 2017 International Conference on Image and Vision Computing New Zealand (IVCNZ). Christchurch, New Iealand: IEEE: 1-5 [DOI: 10.1109/IVCNZ.2017.8402455]
-
Redmon J, Divvala S, Girshick R and Farhadi A. 2016. You only look once: unified, real-time object detection//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE: 779-788 [DOI: 10.1109/CVPR.2016.91]
-
Ren S Q, He K M, Girshick R, Sun J. 2017. Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(6): 1137-1149 [DOI:10.1109/TPAMI.2016.2577031]
-
Ren Y, Zhu C R, Xiao S P. 2018. Small object detection in optical remote sensing images via modified Faster R-CNN. Applied Sciences, 8(5): #813 [DOI:10.3390/app8050813]
-
Singh B, Najibi M and Davis L S. 2018. SNIPER: efficient multi-scale training//Proceedings of the 32nd International Conference on Neural Information Processing Systems. New York, USA: Curran Associates Inc. : 9333-9343
-
Wang F, Jiang M Q, Qian C, Yang S, Li C, Zhang H G, Wang X G and Tang X O. 2017. Residual attention network for image classification//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, USA: IEEE: 6450-6458 [DOI: 10.1109/CVPR.2017.683]
-
Yang F, Choi W and Lin Y Q. 2016. Exploit all the layers: fast and accurate CNN object detector with scale dependent pooling and cascaded rejection classifiers//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE: 2129-2137 [DOI: 10.1109/CVPR.2016.234]
-
Zhao R, Hynes S, He G S. 2014. Defining and quantifying China's ocean economy. Marine Policy, 43: 164-173 [DOI:10.1016/j.marpol.2013.05.008]


