|
|
|
发布时间: 2022-04-16 |
图像分析和识别 |
|
|
|


|
收稿日期: 2020-08-26; 修回日期: 2021-01-07; 预印本日期: 2021-01-14
基金项目: 国家重点研发计划资助(2018YFB1601200); 中国民航大学天津市智能信号与图像处理重点实验室开放基金资助项目(2019ASP-TJ06)
作者简介:
张红颖,1978年生,女,教授,主要研究方向为图像工程与计算机视觉。E-mail: carole_zhang0716@163.com
包雯静,女,硕士研究生,主要研究方向为步态识别与深度学习。E-mail: wjbao_cauc@hotmail.com *通信作者: 张红颖 carole_zhang0716@163.com
中图法分类号: TP391.41
文献标识码: A
文章编号: 1006-8961(2022)04-1097-13
|
摘要
目的 针对目前基于生成式的步态识别方法采用特定视角的步态模板转换、识别率随视角跨度增大而不断下降的问题,本文提出融合自注意力机制的生成对抗网络的跨视角步态识别方法。方法 该方法的网络结构由生成器、视角判别器和身份保持器构成,建立可实现任意视角间步态转换的网络模型。生成网络采用编码器—解码器结构将输入的步态特征和视角指示器连接,进而实现不同视角域的转换,并通过对抗训练和像素级损失使生成的目标视角步态模板与真实的步态模板相似。在判别网络中,利用视角判别器来约束生成视角与目标视角相一致,并使用联合困难三元组损失的身份保持器以最大化保留输入模板的身份信息。同时,在生成网络和判别网络中加入自注意力机制,以捕捉特征的全局依赖关系,从而提高生成图像的质量,并引入谱规范化使网络稳定训练。结果 在CASIA-B(Chinese Academy of Sciences' Institute of Automation gait database——dataset B)和OU-MVLP(OU-ISIR gait database-multi-view large population dataset)数据集上进行实验,当引入自注意力模块和身份保留损失训练网络时,在CASIA-B数据集上的识别率有显著提升,平均rank-1准确率比GaitGAN(gait generative adversarial network)方法高15%。所提方法在OU-MVLP大规模的跨视角步态数据库中仍具有较好的适用性,可以达到65.9%的平均识别精度。结论 本文方法提升了生成步态模板的质量,提取的视角不变特征更具判别力,识别精度较现有方法有一定提升,能较好地解决跨视角步态识别问题。
关键词
机器视觉; 步态识别; 跨视角; 自注意力; 生成对抗网络(GANs)
Abstract
Objective Gait is a sort of human behavioral biometric feature, which is clarified as a style of person walks. Compared with other biometric features like human face, fingerprint and iris, the feature of gait is that it can be captured at a long-distance without the cooperation of the subjects. Gait recognition has its potential in surveillance security, criminal investigation and medical diagnosis. However, gait recognition is changed clearly in the context of clothing, carrying status, view variation and other factors, resulting in strong intra gradient changes in the extracted gait features. The relevant view change is a challenging issue as appearance differences are introduced for different views, which leads to the significant decline of cross view recognition performance. The existing generative gait recognition methods focus on transforming gait templates to a specific view, which may decline the recognition rate in a large variation of multi-views. A cross-view gait recognition analysis is demonstrated based on generative adversarial networks (GANs) derived of self-attention mechanism. Method Our network structure analysis is composed of generator G, view discriminator D and identity preserver Φ. Gait energy images (GEI) is used as the input of network to achieve view transformation of gaits across two various views for cross view gait recognition task. The generator is based on the encoder-decoder structure. First, the input GEI image is disentangled from the view information and the identity information derived of the encoder Genc, which is encoded into the identity feature representation f(x) in the latent space. Next, it is concatenated with the view indicator v, which is composed of the one-hot coding with the target view assigned 1. To achieve different views of transformation, the concatenated vector as input is melted into the decoder Gdec to generate the GEI image from the target view. In order to generate a more accurate gait template in the target view for view transformation task, pixel-wise loss is introduced to constrain the generated image at the end of decoder. In the discriminant network, the view discriminator learning distinguishes the true or false of the input images and classifies them to its corresponding view domain. It is composed of four Conv-LeakyReLU blocks and in-situ two convolution layers those are real/fake discrimination and view classification each. For the constraint of the generated images inheriting identity information in the process of gait template view transformation, an identity preserver is introduced to bridge the gap between the target and generated gait templates. The input of identity preserver are three generated images, which are composed of anchor samples, positive samples from other views with the same identity as anchor samples, and negative samples are from the same view in related to different identities. The following Tri-Hard loss is used to enhance the discriminability of the generated image. The GAN-based gait recognition method can achieve the view transformation of gait template but it cannot capture the global, long-range dependency within features in the process of view transformation effectively. The details of the generated image are not clear result in blurred artifacts. The self-attention mechanism can efficiently sort the long-range dependencies out within internal representations of images. We yield the self-attention mechanism into the generator and discriminator network, and the self-attention module is integrated into the up-sampling area of the generator, which can involve the global and local spatial information. The self-attention module derived discriminator can clarify the real image originated from the generated. We update parameters of one module while keeping parameters of the other two modules fixed, and spectral normalization is used to increase the stable training of the network. Result In order to verify the effectiveness of the proposed method for cross-view gait recognition, several groups of comparative experiments are conducted on Chinese Academy of Sciences' Institute of Automation gait database——dataset B (CASIA-B) as mentioned below: 1) To clarify the influence of self-attention module plus to identify positions of the generator on recognition performance, the demonstrated results show that it is prior to add self-attention module to the feature map following de-convolution in the second layer of decoder; 2) Ablation experiment on self-attention module and identity preserving loss illustrates that the recognition rate is 15% higher than that of GaitGAN method when self-attention module and identity preserving loss are introduced simultaneously; 3) The frame-shifting method is used to enhance the GEI dataset on CASIA-B, and the improved recognition accuracy of the method is significantly harnessed following GEI data enhancement. Our illustration is derived of the OU-MVLP (OU-ISIR gait database-multi-view large population dataset) large-scale cross-view gait database, which has a rank-1 average recognition rate of 65.9%. The demonstrated results based on OU-MVLP are quantitatively analyzed, and the gait templates synthesized at four views (0°, 30°, 60°, and 90°) are visualized in the dataset. The results show that the generated gait images are highly similar to the gait images with real and target views even when the difference of views is large. Conclusion A generative adversarial network framework derived of self-attention mechanism is implemented, which can achieve view transformation of gait templates across two optioned views using one uniform model, and retain the gait feature information in the process of view transformation while improving the quality of generated images. The effective self-attention module demonstrates that the generated gait templates in the target view is incomplete, and improves the matching of the generated images; The identity preserver based on Tri-Hard loss constrains the generated gait templates inheriting identity information via input gaits and the discrimination of the generated images is enhanced. The integration of the self-attention module and the Tri-Hard loss identity preserver improves the effect and quality of transformation of gaits, and the recognition accuracy is improved for qualified cross-view gait recognition. As the GEI input of the model, the quality of pedestrian detection and segmentation will intend to the quality loss of the synthesized GEI images straightforward in real scenarios. The further research will focus on problem solving of cross-view gait recognition in complex scenarios.
Key words
machine vision; gait recognition; cross-view; self-attention; generative adversarial networks(GANs)
0 引言
步态识别是通过人走路的姿势进行身份识别。与人脸、指纹或虹膜等其他生物特征相比,步态的优势在于无需受试者的配合即可进行远距离身份识别(支双双等,2019)。因此,步态识别在视频监控、刑事侦查和医疗诊断等领域具有广泛的应用前景。然而,步态识别易受衣着、携带物和视角等因素的影响,提取的步态特征呈现很强的类内变化(王科俊等,2019),其中视角变化从整体上改变步态特征,从而导致跨视角识别性能明显下降。
针对跨视角步态识别问题,提出了许多先进方法,这些方法通常分为基于模型的方法和基于外观的方法两类。其中,基于外观的方法可以更好地处理低分辨图像并且计算成本低,表现出很大优势。Makihara等人(2006)提出以步态能量图(gait energy image,GEI)(Han和Bhanu,2006)为步态模板的视角转换模型(view transformation model,VTM),利用奇异值分解来计算GEI的投影矩阵和视角不变特征。Hu等人(2013)提出视角无关判别投影(view-invariant discriminative projection,ViDP)方法,在无需知道视角情况下使用线性变换将步态模板投影到特征子空间中,但在视角变化大时识别率较低。近年来,深度学习应用于解决步态识别问题已成为主流方向。Wu等人(2017)提出基于卷积神经网络(convolutional neural network,CNN)的方法从任意视角中自动识别具有判别性的步态特征,在跨视角和多状态识别中效果显著。Shiraga等人(2016)提出基于CNN框架的GEINet应用于大型步态数据集,将GEI作为模型输入,其在视角变化范围较小时有较好表现。基于CNN提取视角不变特征进行跨视角步态识别方法表现出卓越的性能,但CNN是一个黑盒模型,缺乏视角变化的可解释性。生成对抗网络(generative adversarial network,GAN)(Goodfellow等,2014)对数据分布建模具有强大性能,在人脸旋转(Tran等,2017)和风格转换(Zhu等,2017)等应用中取得显著效果。目前,基于GAN的方法重构目标视角的身份特征进行步态识别,可提供良好的可视化效果。Yu等人(2017a)提出步态生成对抗网络(gait generative adversarial network,GaitGAN),将不同视角的步态模板标准化为侧面视角的步态模板进行匹配。He等人(2019)提出多任务生成对抗网络(multi-task generative adversarial network,MGAN)用于学习特定视角的步态特征表示。Wang等人(2019)提出双通道生成对抗网络(two-stream generative adversarial network,TS-GAN)进行步态模板的视角转换以学习标准视角的步态特征。尽管目前基于GAN的步态识别方法通过合成图像提供了良好的可视化效果,但这些方法只能进行特定视角的步态转换,误差随视角跨度增大而不断累积,而且在视角转换过程中未能充分利用特征间的全局依赖关系进行建模,生成图像的细节信息仍然不够清晰。而自注意力机制能更好地建立像素点远近距离依赖关系并且在计算效率上表现出良好性能,在图像生成(Zhang等,2018)和图像超分辨率重建(欧阳宁等,2019)上有较好表现。
为了实现任意视角间的步态模板转换并提升生成图像的质量,本文提出融合自注意力机制的生成对抗网络的跨视角步态识别方法。通过设计带有自注意力机制的生成器和判别器网络,学习更多全局特征的相关性,进而提高生成图像的质量并增强提取特征的区分度,同时在网络结构中引入谱规范化,提高训练过程的稳定性。本文网络框架由生成器
1 本文方法
1.1 网络模型的整体结构
本文网络模型的整体框架如图 1所示,包括生成器
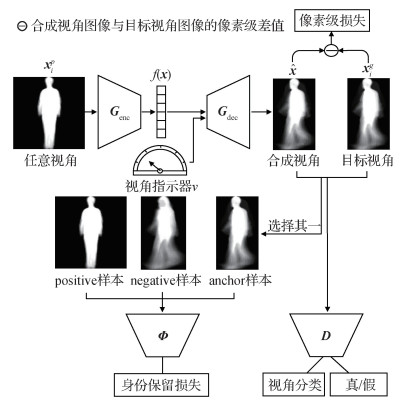

生成器
在训练网络时,利用对抗损失来约束生成器和判别器,目标函数为
| $ \begin{gathered} \min \limits_{G} \max \limits_{D} L_{\mathrm{adv}}=E_{\boldsymbol{x}_{i}^{g}: P_{\mathrm{data}}}\left[\log \boldsymbol{D}_{\mathrm{dis}}\left(\boldsymbol{x}_{i}^{g}\right)\right]+ \\ E_{x_{i}^{p}: P_{\mathrm{data}, v: P_{v}}}\left[\log \left(1-\boldsymbol{D}_{\mathrm{dis}}\left(\boldsymbol{G}\left(\boldsymbol{x}_{i}^{p}, \boldsymbol{v}\right)\right)\right)\right] \end{gathered} $ | (1) |
式中,
1.2 生成器网络
为了在步态视角转换任务中获取高质量的生成图像,生成器基于DRGAN(disentangled representation learning generative adversarial network)(Tran等,2017)网络架构中的generator结构,并引入自注意力机制。如图 2所示,生成器网络结构包括由卷积神经网络组成的下采样区
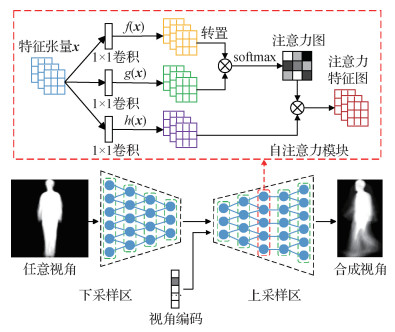
生成器网络结构参数设置如表 1所示,对于下采样区
表 1
生成器网络结构参数设置
Table 1
The parameter setting of generator
| 区域划分 | 层类型 | 卷积核 | 步长 | 深度 | 归一化 | 激活函数 |
| 下采样 | 卷积层 | 4×4 | 2 | 96 | BN | ReLU |
| 下采样 | 卷积层 | 4×4 | 2 | 192 | BN | ReLU |
| 下采样 | 卷积层 | 4×4 | 2 | 384 | BN | ReLU |
| 下采样 | 卷积层 | 4×4 | 2 | 768 | BN | ReLU |
| 特征连接 | 全连接层 | - | - | - | - | - |
| 上采样 | 反卷积层 | 4×4 | 2 | 768 | SN、BN | ReLU |
| 上采样 | 反卷积层 | 4×4 | 2 | 384 | SN、BN | ReLU |
| 上采样 | 自注意力模块 | - | - | - | - | - |
| 上采样 | 反卷积层 | 4×4 | 2 | 192 | SN、BN | ReLU |
| 上采样 | 卷积层 | 4×4 | 2 | 96 | - | Tanh |
| 注:“-”代表无具体参数。 | ||||||
生成器
| $ \min \limits_{\boldsymbol{G}} L_{\text {pixel }}=E_{\boldsymbol{x}_{i:} P_{\text {data }}, v: P_{v}}\left[\left\|\boldsymbol{G}\left(\boldsymbol{x}_{i}^{p}, \boldsymbol{v}\right)-\boldsymbol{x}_{i}^{g}\right\|_{1}\right] $ | (2) |
式中,
1.3 判别器网络
本文构建了两个判别器:视角判别器
1.3.1 视角判别器
对于给定的注册集视角的步态模板
表 2
视角判别器网络结构参数设置
Table 2
The parameter setting of view classifier
| 层类型 | 卷积核 | 步长 | 深度 | 归一化 | 激活函数 |
| 卷积层 | 4×4 | 2 | 64 | - | LeakyReLU |
| 卷积层 | 4×4 | 2 | 128 | SN | LeakyReLU |
| 卷积层 | 4×4 | 2 | 256 | SN | LeakyReLU |
| 自注意力模块 | - | - | - | - | - |
| 卷积层 | 4×4 | 2 | 512 | SN | LeakyReLU |
| 输出层( |
3×3 | 1 | 1 | - | - |
| 输出层( |
4×4 | 1 | - | - | |
| 注:“-”代表无具体参数。 | |||||
对于给定的训练图像
| $ L_{\mathrm{cls}}^{\mathrm{D}}=E_{\boldsymbol{x}_{i}: P_{\mathrm{data}}}\left[\log \boldsymbol{D}_{\mathrm{cls}}\left(\boldsymbol{x}_{i}\right)\right] $ | (3) |
式中,
| $ L_{\mathrm{cls}}^{\mathrm{D}}=E_{\boldsymbol{x}_{i}^{p}: P_{\mathrm{data}}}\left[\log \boldsymbol{D}_{\mathrm{cls}}\left(\boldsymbol{G}\left(\boldsymbol{x}_{i}^{p}, \boldsymbol{v}\right)\right)\right] $ | (4) |
通过最小化该目标函数,生成器
1.3.2 身份保持器
传统的GAN模型生成的样本缺乏多样性,生成器会在某种情况下重复生成完全一致的图像,而对于跨视角步态识别任务,在步态模板视角转换过程中保持身份信息是至关重要的。因此,在本文模型中引入身份保持器
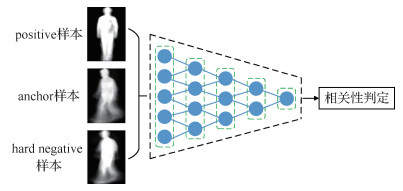
为了使生成的步态模板更好地保持身份信息,本文引入困难样本三元组Tri-Hard损失(Hermans等,2017)作为身份保留损失来增强生成图像的可判别性。以
| $ \begin{gathered} L_{\text {trihard }}\left(\boldsymbol{x}_{\mathrm{anc}}, \boldsymbol{x}_{\mathrm{pos}}, \boldsymbol{x}_{\mathrm{ncg}}\right)=\frac{1}{P \times K} \times \\ \sum\limits_{x_{\mathrm{anc}} \in \boldsymbol { batch }}\left(\max \limits_{x_{\mathrm{pos}} \in \boldsymbol{A}} d\left(\boldsymbol{x}_{\mathrm{anc}}, \boldsymbol{x}_{\mathrm{pos}}\right)-\min \limits_{x_{\mathrm{neg}} \in \boldsymbol{B}} d\left(\boldsymbol{x}_{\mathrm{anc}}, \boldsymbol{x}_{\mathrm{neg}}\right)+\delta\right) \end{gathered} $ | (5) |
式中,
身份保持器
1.4 自注意力机制
虽然基于GAN的步态识别方法可实现步态模板的视角转换,但在视角转换过程中未能有效捕获特征间的全局依赖关系,生成图像的细节信息不够清晰,而且会伴随模糊的伪影。这是由于卷积核大小受限,无法在有限的网络层次结构中直接获取图像所有位置特征间的关联关系;而自注意力机制可以更好地处理图像中长范围、多层次的依赖关系,有助于增强步态特征的表达能力,提高步态识别的性能。因此,本文将自注意力机制(Zhang等,2018)引入到生成器和判别器网络中,在生成器的上采样区引入自注意力模块能更好地整合全局和局部的空间信息,提高生成图像的协调性和质量;在判别器引入自注意力模块可以更准确地将真实图像和生成图像进行区分。
如图 2所示,自注意力模块将前一层提取的特征图
| $ \beta_{j, i}=\frac{\exp \left(s_{i j}\right)}{\sum\limits_{i=1}^{N} \exp \left(s_{i j}\right)}, \quad s_{i j}=f\left(\boldsymbol{x}_{i}\right)^{\mathrm{T}} g\left(\boldsymbol{x}_{j}\right) $ | (6) |
随后,将特征图
| $ o_{i}=\sum\limits_{i=1}^{N} \beta_{j, i} h\left(\boldsymbol{x}_{i}\right), \quad h\left(\boldsymbol{x}_{i}\right)=\boldsymbol{W}_{h} \boldsymbol{x}_{i} $ | (7) |
式中,
最后,将注意力层的输出与比例系数
| $ \boldsymbol{y}_{i}=\gamma o_{i}+\boldsymbol{x}_{i} $ | (8) |
式中,
2 网络训练
本文采用Goodfellow等人(2014)提出的交替迭代训练的策略,当更新一方的参数时,另一方的参数固定住不更新。网络的训练过程如下:
输入:训练集
输出:网络
1) 判别过程:
(1) 训练集
(2) 视角判别器
(3) 身份判别器
(4)
2) 生成过程:
(1) 验证集任意视角的步态模板
(2) 对目标视角以等概率来随机采样目标视角指示器
(3) 步态特征
(4) 视角判别器
(5) 身份判别器
(6) 反向传递损失至
(7) 根据
3) 重复步骤1)和2),直至网络收敛。
本文的目标是将步态模板从验证集中的任意视角转换至注册集中的目标视角,同时保留身份信息。为了实现这个目标,联合上述损失函数协同训练,总体目标函数为
| $ L=\lambda_{1} L_{\mathrm{adv}}+\lambda_{2} L_{\mathrm{cls}}^{\mathrm{D}}+\lambda_{3} L_{\mathrm{tri}}^{\mathrm{G}}+\lambda_{4} L_{\text {pixel }} $ | (9) |
式中,
3 实验结果及分析
3.1 数据集
3.1.1 公共数据集
CASIA-B(Chinese Academy of Sciences’ Institute of Automation gait database——dataset B)步态数据集(Yu等,2006)是广泛用于评估跨视角步态识别效果的公共数据集,包含124人、3种行走状态和11个不同视角(0°, 18°, …, 180°)。每个人在正常状态下有6个序列(NM #01—06),穿着外套状态下有2个序列(CL#01—02),携带背包状态下有2个序列(BG#01—02),所以,每个人有11×(6+2+2)=110个序列。
OU-MVLP(multi-view large population dataset)步态数据集(Takemura等,2018)是迄今为止世界上最大的跨视角步态数据库,包含10 307人、14个不同视角(0°, 15°, …, 90°;180°, 195°, …, 270°)以及每个角度有2个序列(#00—01),步行状态没有变化。官方将数据库分为5 153人的训练集和5 154人的测试集。在测试阶段,序列#01作为注册集,序列#00作为测试集。
3.1.2 帧移式合成GEI数据集
本文方法是基于CNN实现的GAN网络,其性能在一定程度上取决于训练样本的数据规模。考虑到CASIA-B数据量较少,而OU-MVLP数据量大,因此通过对CASIA-B的GEI数据集进行数据增强来评估对步态识别准确率的影响。
本文采用帧移式方法来增加合成GEI的数量,帧移式生成GEI的原理如图 4所示。输入步态序列为

3.2 评价指标及实验设置
3.2.1 评价指标
步态识别任务中常用的评价指标是CMC(cumulative matching characteristic)曲线中的rank-1识别准确率,是由最近邻分类器计算得出的。对于行人
| $ d=\sqrt{f\left(\boldsymbol{x}_{i}^{p}\right)^{2}-f\left(\boldsymbol{x}_{i}^{g}\right)^{2}} $ | (10) |
然后根据欧氏距离搜寻注册集中距离最近的步态特征,从而判断是否具有相同身份。
3.2.2 实验设置
实验基于深度学习框架Pytorch在显卡为NVIDA RTX2080Ti×2的Dell工作站上进行训练。本文在CASIA-B数据集的实验设置是将数据集均匀划分为两组,前62人用于训练,后62人用于测试。网络输入和输出的GEI尺寸设置为64 × 64像素,批量大小batch_size设为64。考虑到CASIA-B数据集训练人数较少,使用GEI数据增强进行实验。在OU-MVLP数据集的设置与官方(Takemura等,2018)一致,由于OU-MVLP中GEI数据量远超CASIA-B,故将batch_size设为32。
如第2节所述,本文采用交替训练
3.3 实验结果与分析
3.3.1 消融实验
为探究自注意力模块在网络中所处位置对识别性能的影响,本文将自注意力模块添加到生成器的不同位置,并在CASIA-B数据集进行对比实验,如表 3所示。可以看出,自注意力模块添加到解码器第2层反卷积之后位置识别效果更好,而位置靠前、靠后或添加到编码器的识别效果均不理想。当添加位置较靠前时,采集到的信息较粗糙,噪声较大;而当对较小的特征图建立依赖关系时,其作用与局部卷积作用相似。因此在特征图较大情况下,自注意力能捕获更多的信息,选择区域的自由度也更大,从而使生成器和判别器能建立更稳定的依赖关系。自注意力模块需在中高层特征图之间使用,所以本文将自注意力机制添加到解码器第2层反卷积后的特征图上。而同时在编码器中加入自注意力模块会导致部分生成的步态模板信息丢失,所以没有单独在解码器中加入自注意力模块的效果好。此外,通过对比生成器中添加自注意力模块与未使用自注意力模块的实验结果,前者识别率较高,进一步验证了自注意力模块的有效性。
表 3
自注意力模块处于生成器不同位置对识别率的影响
Table 3
The effect of different position of the generator of self-attention module on recognition performance
| /% | |||||||||||||||||||||||||||||
| 网络模型 | 验证集角度 | 平均值 | |||||||||||||||||||||||||||
| 54° | 90° | 126° | |||||||||||||||||||||||||||
| 79.5 | 70.2 | 78.4 | 76.0 | ||||||||||||||||||||||||||
| 80.7 | 71.4 | 80.1 | 77.4 | ||||||||||||||||||||||||||
| 81.7 | 72.0 | 80.7 | 78.1 | ||||||||||||||||||||||||||
| 81.2 | 71.7 | 80.4 | 77.8 | ||||||||||||||||||||||||||
| 81.0 | 71.3 | 80.1 | 77.5 | ||||||||||||||||||||||||||
| 81.1 | 71.5 | 80.2 | 77.6 | ||||||||||||||||||||||||||
| 注:加粗字体表示各列最优结果。 |
|||||||||||||||||||||||||||||
通过上述实验,自注意力模块对步态模板生成具有较好的识别效果,为进一步提高生成图像的判别能力,在身份保持器中融合身份保留损失,为验证其对步态识别效果的影响,在CASIA-B数据集进行消融实验。实验结果如表 4所示。
表 4
本文不同方案在CASIA-B的识别率对比
Table 4
Comparison of recognition performance among different schemes under proposed framework
| /% | |||||||||||||||||||||||||||||
| 方法 | 验证集角度 | 平均值 | |||||||||||||||||||||||||||
| 54° | 90° | 126° | |||||||||||||||||||||||||||
| GaitGAN | 64.5 | 58.2 | 65.7 | 62.8 | |||||||||||||||||||||||||
| GaitGAN+自注意力模块 | 79.3 | 67.7 | 77.3 | 74.8 | |||||||||||||||||||||||||
| GaitGAN+身份保留损失 | 79.5 | 70.2 | 78.4 | 76.0 | |||||||||||||||||||||||||
| GaitGAN+自注意力模块+身份保留损失 | 81.7 | 72.0 | 80.7 | 78.1 | |||||||||||||||||||||||||
| 注:加粗字体表示各列最优结果。 | |||||||||||||||||||||||||||||
从表 4可以看出,在网络模型中没有自注意力模块或身份保留损失的情况下,本文方法仍然比基准方法GaitGAN的识别率高。当引入自注意力模块和身份保留损失训练网络时,在CASIA-B数据集上的识别率有显著提升,平均rank-1准确率提升了15%。实验结果表明,自注意力模块有效解决了目标视角步态模板生成的不完全的问题,提升了生成图像的协调性;身份保留损失使生成的步态模板更好地保持身份信息,增强了生成图像的可判别性。自注意力模块和身份保留损失两者结合有效提高了步态视角转换的效果与质量。
为进一步验证GEI数据增强对步态识别效果的影响,在CASIA-B数据集上进行实验,结果如图 5所示。
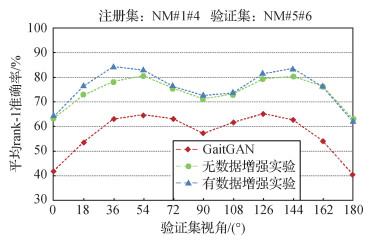
从图 5可以看出,经过GEI数据增强,达到了最佳识别精度。与GaitGAN方法相比,即使未经数据增强训练的方法也能取得较高的识别率。通过GEI数据增强,既避免了因生成的步态能量图过少导致的识别率不高问题,也避免了不同身份的GEI样本过于接近问题,有助于提高跨视角步态识别率。
3.3.2 与最新方法对比
1) 在CASIA-B数据集实验结果。为验证本文方法的有效性,与C3A(complete canonical correlation analysis)(Xing等,2016)、SPAE(stacked progressive auto-encoders)(Yu等,2017b)、GaitGAN(Yu等,2017a)和MGAN(He等,2019)等最新方法进行比较,选择验证集视角为54°、90°、126°进行跨视角步态识别的对比实验。图 6显示了排除相同视角的所有注册集视角的跨视角步态识别率。
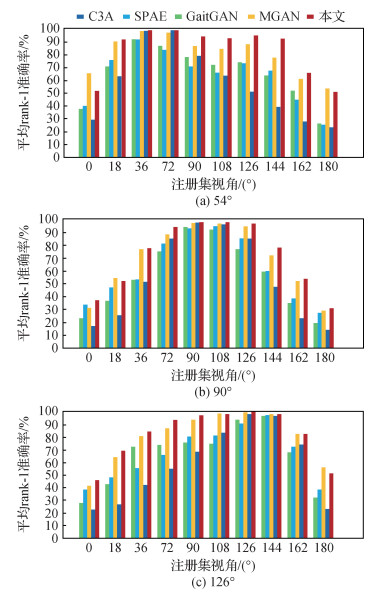
从图 6可以看出,本文方法在3个验证集视角下的识别率均优于其他4种方法。当注册集视角与验证集视角相邻近时,识别效果最好;且当视角跨度逐渐增大时,其他方法识别率下降幅度剧烈,本文方法仍能表现良好。为了更明显展示跨视角步态识别性能,在排除相同视角下,对验证集视角为54°、90°、126°时的平均识别率进行比较,结果如表 5所示。可以看出,本文方法优于GaitGAN、TS-GAN、MGAN和DV-GEIs(Liao等,2020),平均rank-1识别率达到79.8%,比MGAN方法提升了2.1%。DV-GEIs采用线性插值方法以1°为间隔生成0°~180°的密集视角步态特征,但会使生成的GEI出现边缘模糊和振铃等瑕疵,引入不必要的噪声;而本文方法加入自注意力机制并扩充了GEI数据集,所以识别率较高于DV-GEIs。实验结果表明,注册集视角为54°和126°时的识别率明显高于90°。这是因为除了0°和180°与摄像头拍摄方向几乎相同或相反的视角,侧面90°视角与其他角度的步态外观差别最大,而视角为54°和126°时的样本更具有区分性的步态特征,所以识别率更高。
表 5
排除相同视角下,在CASIA-B数据集中3种验证集视角的平均识别率比较
Table 5
Comparison of average identification rates among three probe views excluding identical view on CASIA-B dataset
| /% | |||||||||||||||||||||||||||||
| 方法 | 验证集角度 | 平均值 | |||||||||||||||||||||||||||
| 54° | 90° | 126° | |||||||||||||||||||||||||||
| GaitGAN | 64.5 | 58.2 | 65.7 | 62.8 | |||||||||||||||||||||||||
| TS-GAN | 67.3 | 63.1 | 68.2 | 66.2 | |||||||||||||||||||||||||
| MGAN | 81.6 | 71.2 | 80.3 | 77.7 | |||||||||||||||||||||||||
| DV-GEIs | 80.8 | 72.6 | 78.9 | 77.4 | |||||||||||||||||||||||||
| 本文 | 83.7 | 73.2 | 82.4 | 79.8 | |||||||||||||||||||||||||
| 注:加粗字体表示最优结果。 | |||||||||||||||||||||||||||||
2) 在OU-MVLP数据集实验结果。本文对4个在OU-MVLP数据集实验的方法不多,所以选择与GEINet(Shiraga等,2016)、3in+2diff(Takemura等,2019)和GaitSet(Chao等,2019)等3种方法进行比较,结果如表 6所示,所有结果都是在排除相同视角的注册集视角下取平均值得到的识别率。从表 6可以看出,GEINet和3in+2diff方法在OU-MVLP这种典型视角(0°、30°、60°、90°)进行实验,由于近几年大规模的跨视角步态识别评估实验中识别性能较差,而本文方法可以达到65.9%的平均识别精度,远高于这两种方法。由于GaitSet采用人体轮廓序列作为输入特征,比GEI包含更多的时空特征信息,所以识别率更高。实验结果表明,与采用GEI步态模板的其他方法相比,本文方法在大规模的跨视角步态数据库中仍具有较好的适用性。
表 6
排除相同视角下,在OU-MVLP数据集中4种典型视角的平均识别率比较
Table 6
Comparison of average identification rates among four representative probe views on OU-MVLP dataset
| /% | |||||||||||||||||||||||||||||
| 方法 | 验证集角度 | 平均值 | |||||||||||||||||||||||||||
| 0° | 30° | 60° | 90° | ||||||||||||||||||||||||||
| GEINet | 8.2 | 32.3 | 33.6 | 28.5 | 25.7 | ||||||||||||||||||||||||
| 3in+2diff | 25.5 | 50.0 | 45.3 | 40.6 | 40.4 | ||||||||||||||||||||||||
| GaitSet | 77.7 | 86.9 | 85.3 | 83.5 | 83.35 | ||||||||||||||||||||||||
| 本文 | 58.4 | 70.6 | 67.9 | 66.7 | 65.9 | ||||||||||||||||||||||||
| 注:加粗字体表示最优结果。 | |||||||||||||||||||||||||||||
3.3.3 实验结果定性分析
目前基于GAN的步态识别方法中,MGAN需要事先对视角进行估计才能实现特定视角的步态图像生成,GaitGAN和TS-GAN则是将任意视角的步态模板标准化到侧面视角进行识别,如果要将某一视角的步态模板转换到任意视角,则需构建多个模型,而本文方法建立的统一模型可将步态模板从任意视角转换到目标视角。本文将OU-MVLP数据集中的4个典型视角(0°,30°,60°,90°)合成的步态模板进行可视化,如图 7所示。其中,左侧图像为验证集中的输入GEI,上侧图像是注册集中真实的目标GEI,右下4 × 4矩阵中的图像是生成的GEI。由图 7可以看出,本文训练的任意视角间步态模板转换模型即使在视角变化较大情况下,生成的步态图像也与真实的目标视角的步态图像高度相似。

4 结论
针对步态识别中的跨视角问题,本文提出融合自注意力机制的生成对抗网络框架,建立可实现任意视角间的步态模板转换模型,由生成器、视角判别器和身份保持器构成,解决了目前生成式方法只能进行特定视角的步态转换并且生成图像的特征信息容易丢失问题,达到了使用统一模型生成任意视角的步态模板的效果,并在视角转换过程中保留步态特征信息,提升了生成图像的质量。
为验证本文方法对跨视角步态识别的有效性,在CASIA-B步态数据库上分别进行对比、消融和增强实验,设计将自注意力模块添加到生成器的不同位置进行对比实验,结果表明在解码器第2层反卷积后加入自注意力模块效果更好;对自注意力模块和身份保留损失进行消融实验,相比于Gait GAN方法,两者结合时的步态识别率有显著提升;采用帧移式方法对CASIA-B数据集进行GEI数据增强实验,进一步提升了识别率。在OU-MVLP大规模的跨视角步态数据库中进行对比实验,与GEINet、3in+2diff两种方法相比,所提方法仍具有较好的适用性,可以达到65.9%的平均识别精度。
本文方法以步态能量图为模型输入,计算简单有效,但在实际场景中,行人检测与分割的好坏会直接影响合成步态能量图的质量;同时在实际应用中,视角变化会与其他协变量(如衣着、携带物)结合。因此,如何建立功能更强大的网络模型来解决复杂场景的步态识别问题,仍是未来步态识别研究的技术难点。
参考文献
-
Chao H Q, He Y W, Zhang J P and Feng J F. 2019. GaitSet: regarding gait as a set for cross-view gait recognition//Proceedings of 2019 AAAI Conference on Artificial Intelligence. Honolulu, USA: AAAI Press: 8126-8133 [DOI: 10.1609/aaai.v33i01.33018126]
-
Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A and Bengio Y. 2014. Generative adversarial nets//Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: ACM: 2672-2680 [DOI: 10.5555/2969033.2969125]
-
Han J, Bhanu B. 2006. Individual recognition using gait energy image. IEEE Transactions on Pattern Analysis and Machine Intelligence, 28(2): 316-322 [DOI:10.1109/TPAMI.2006.38]
-
He Y W, Zhang J P, Shan H M, Wang L. 2019. Multi-task GANs for view-specific feature learning in gait recognition. IEEE Transactions on Information Forensics and Security, 14(1): 102-113 [DOI:10.1109/TIFS.2018.2844819]
-
Hermans A, Beyer L and Leibe B. 2017. In defense of the triplet loss for person re-identification [EB/OL]. [2020-08-10]. https://arxiv.org/pdf/1703.07737.pdf
-
Hu M D, Wang Y H, Zhang Z X, Little J J, Huang D. 2013. View-invariant discriminative projection for multi-view gait-based human identification. IEEE Transactions on Information Forensics and Security, 8(12): 2034-2045 [DOI:10.1109/TIFS.2013.2287605]
-
Liao R J, An W Z, Yu S Q, Li Z and Huang Y Z. 2020. Dense-view GEIs set: view space covering for gait recognition based on dense-view GAN//Proceedings of 2020 IEEE International Joint Conference on Biometrics. Houston, USA: IEEE: 1-9 [DOI: 10.1109/IJCB48548.2020.9304910]
-
Makihara Y, Sagawa R, Mukaigawa Y, Echigo T and Yagi Y. 2006. Gait recognition using a view transformation model in the frequency domain//Proceedings of the 9th European Conference on Computer Vision. Graz, Austria: ACM: 151-163 [DOI: 10.1007/11744078_12]
-
Miyato T, Kataoka T, Koyama M and Yoshida Y. 2018. Spectral normalization for generative adversarial networks [EB/OL]. [2020-08-10]. https://arxiv.org/pdf/1802.05957.pdf
-
Ouyang N, Liang T, Lin L P. 2019. Self-attention network based image super-resolution. Journal of Computer Applications, 39(8): 2391-2395 (欧阳宁, 梁婷, 林乐平. 2019. 基于自注意力网络的图像超分辨率重建. 计算机应用, 39(8): 2391-2395) [DOI:10.11772/j.issn.1001-9081.2019010158]
-
Shiraga K, Makihara Y, Muramatsu D, Echigo T and Yagi Y. 2016. GEINet: view-invariant gait recognition using a convolutional neural network//Proceedings of 2016 International Conference on Biometrics (ICB). Halmstad, Sweden: IEEE: 1-8 [DOI: 10.1109/ICB.2016.7550060]
-
Takemura N, Makihara Y, Muramatsu D, Echigo T, Yagi Y. 2018. Multi-view large population gait dataset and its performance evaluation for cross-view gait recognition. IPSJ Transactions on Computer Vision and Applications, 10(4): #4 [DOI:10.1186/s41074-018-0039-6]
-
Takemura N, Makihara Y, Muramatsu D, Echigo T, Yagi Y. 2019. On input/output architectures for convolutional neural network-based cross-view gait recognition. IEEE Transactions on Circuits and Systems for Video Technology, 29(9): 2708-2719 [DOI:10.1109/TCSVT.2017.2760835]
-
Tran L, Yin X and Liu X M. 2017. Disentangled representation learning GAN for pose-invariant face recognition//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE: 1283-1292 [DOI: 10.1109/CVPR.2017.141]
-
Wang K J, Ding X N, Xing X L, Liu M C. 2019. A survey of multi-view gait recognition. Acta Automatica Sinica, 45(5): 841-852 (王科俊, 丁欣楠, 邢向磊, 刘美辰. 2019. 多视角步态识别综述. 自动化学报, 45(5): 841-852) [DOI:10.16383/j.aas.2018.c170599]
-
Wang Y Y, Song C F, Huang Y, Wang Z Y, Wang L. 2019. Learning view invariant gait features with Two-Stream GAN. Neurocomputing, 339: 245-254 [DOI:10.1016/j.neucom.2019.02.025]
-
Wu Z F, Huang Y Z, Wang L, Wang X G, Tan T N. 2017. A comprehensive study on cross-view gait based human identification with deep CNNs. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(2): 209-226 [DOI:10.1109/TPAMI.2016.2545669]
-
Xing X L, Wang K J, Yan T, Lyu Z W. 2016. Complete canonical correlation analysis with application to multi-view gait recognition. Pattern Recognition, 50: 107-117 [DOI:10.1016/j.patcog.2015.08.011]
-
Yu S Q, Chen H F, Reyes E B G and Poh N. 2017a. GaitGAN: invariant gait feature extraction using generative adversarial networks//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Honolulu, USA: IEEE: 532-539 [DOI: 10.1109/CVPRW.2017.80]
-
Yu S Q, Chen H F, Wang Q, Shen L L, Huang Y Z. 2017b. Invariant feature extraction for gait recognition using only one uniform model. Neurocomputing, 239: 81-93 [DOI:10.1016/j.neucom.2017.02.006]
-
Yu S Q, Tan D L and Tan T N. 2006. A framework for evaluating the effect of view angle, clothing and carrying condition on gait recognition//Proceedings of the 18th International Conference on Pattern Recognition. Hong Kong, China: IEEE: 441-444 [DOI: 10.1109/ICPR.2006.67]
-
Zhang H, Goodfellow I, Metaxas D and Odena A. 2018. Self-attention Generative Adversarial Networks [EB/OL]. [2020-08-10]. https://arxiv.org/pdf/1805.08318.pdf
-
Zhi S S, Zhao Q H, Tang J. 2019. Semantic segmentation of gait body with multilayer semantic fusion convolutional neural network. Journal of Image and Graphics, 24(8): 1302-1314 (支双双, 赵庆会, 唐琎. 2019. 多层语义融合CNN的步态人体语义分割. 中国图象图形学报, 24(8): 1302-1314) [DOI:10.11834/jig.180597]
-
Zhu J Y, Park T, Isola P and Efros A A. 2017. Unpaired image-to-image translation using cycle-consistent adversarial networks//Proceedings of 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE: 2242-2251 [DOI: 10.1109/ICCV.2017.244]


