|
|
|
发布时间: 2022-04-16 |
图像处理和编码 |
|
|
|


|
收稿日期: 2020-11-11; 修回日期: 2021-01-06; 预印本日期: 2021-01-13
基金项目: 国家自然科学基金项目(61772294);山东省自然科学基金项目(ZR2019LZH002)
作者简介:
宋田田,1996年生,女,硕士研究生,主要研究方向为变分图像去噪与加速算法。E-mail: songtiantian_1@163.com
潘振宽,通信作者,男,教授,主要研究方向为计算机视觉和图像处理。E-mail: zkpan@126.com 魏伟波,男,副教授,主要研究方向为图像处理、目标识别与跟踪。E-mail: njustwwb@163.com 李青,女,硕士研究生,主要研究方向为计算机视觉图像处理。E-mail: macchiato_2013@163.com *通信作者: 潘振宽 zkpan@126.com
中图法分类号: TP391
文献标识码: A
文章编号: 1006-8961(2022)04-1066-18
|
摘要
目的 基于二阶导数的图像恢复变分模型可以同时保持图像边缘与光滑特征,但其规则项的非线性、非光滑性,甚至非凸性制约着其快速算法的设计。针对总拉普拉斯(total Laplacian,TL)与欧拉弹性能(Euler’s elastica,EE)两种图像恢复变分模型,在设计快速交替方向乘子法(fast alternating direction methods of multipliers,fast ADMM)的基础上引入重启动策略,以有效消除解的振荡,从而大幅提高该类模型计算效率,并为其他相近模型的快速算法设计提供借鉴。方法 基于原始ADMM方法设计反映能量泛函变化的残差公式,在设计的快速ADMM方法中根据残差的变化重新设置快速算法的相关参数,以避免计算过程中的能量振荡,达到算法加速目的。结果 通过大量实验发现,采用原始ADMM、快速ADMM和重启动快速ADMM算法恢复图像的峰值信噪比(peak signal-to-noise ratio,PSNR)基本一致,但计算效率有不同程度的提高。与原始ADMM算法相比,在消除高斯白噪声和椒盐噪声中,对TL模型,其快速ADMM算法分别提高6%~50%和13%~240%;重启动快速ADMM算法提高100%~433%和100%~466%;对EE模型,其快速ADMM算法分别提高14%~54%和10%~83%;重启动快速ADMM算法分别提高100%~900%和66%~800%。此外,对于不同的惩罚参数组合,相同模型的快速ADMM算法的计算效率基本相同。结论 对于两种典型的二阶变分图像恢复模型,本文提出的快速重启动ADMM算法比原始ADMM算法及快速ADMM算法在计算效率方面有较大提高,计算效率对不同惩罚参数组合具有鲁棒性。本文设计的算法对于含其他形式二阶导数规则项的变分图像分析模型的重启动快速算法的设计可提供有益借鉴。
关键词
图像恢复; 二阶变分模型; 快速交替方向乘子方法(fast ADMM); 重启动; 总拉普拉斯模型; 欧拉弹性能模型
Abstract
Objective To develop image processing and computer vision, variational models have been widespread used in image de-noising, image segmentation and image restoration. Variational model of image restoration has a fundamental position. Variational model of image restoration can maintain the image edge and smooth features based on the second-order derivative. However, its regular terms are generally non-linear, non-smooth, or even non-convex. These features have their numerical algorithm design difficulty and the low computational efficiency of its numerical method. These features restrict the design of its fast algorithm as well. The designated acceleration method is essential to design optimal inertial parameters. The variational image processing models are often locally strongly convex or completely non-convex, which makes it difficult or time-consuming to estimate the optimal inertial parameters. Its inertial acceleration algorithms can cause ripples and fail to achieve the targeted acceleration effect. The analyzed results of developed monotonic algorithm, backtracking algorithm and restart algorithm can yield ripples phenomenon to keep algorithm convergence rate. Our research facilitates framework-based fast alternating direction methods of multipliers (ADMM) method to explore possibility of the restart fast algorithm in second-order variational models. Total-Laplacian based model (TL-based) and Euler's elastic based model (EE-based) are illustrated to develop testart fast algorithms. Method Our research demonstrated second-order variational model of image restoration with nonlinear, non-smooth TL regular terms and non-linear, non-smooth, non-convex EE regular terms. The following restart fast ADMM algorithm is developed based on the alternation of direction methods of multipliers, Nesterov's inertial acceleration method and ripples-yielded restart idea. TL model transformed into constrained equivalent convex optimization based on auxiliary variables and linear constraint equations. EE model transformed into equivalent constrained convex optimization based on auxiliary variables, linear constraint equations and relaxed nonlinear constraint equations. Restart fast ADMM algorithm determine the requirement of restarted algorithm based on the integrated residual scale. Our demonstrated restart fast ADMM algorithm can identify a reference for the context fast algorithm models. The number of iterations, total CPU running time and peak signal-to-noise ratio (PSNR) are tracked in our tests. Each of the algorithms described energy change curve and convergence curve respectively. Result The PSNR of three algorithms shows that de-noising effect of fast algorithm and original ADMM algorithm keeps same in terms of denoising effect. Fast algorithm maintains the quality the original model and image quality of the original ADMM algorithm. In terms of computational efficiency, three algorithms are compared in the TL model and the EE model. Compared with original ADMM algorithm, fast ADMM algorithm improves 6%~50% and 14%~54% each. Compared with original ADMM algorithm, restart fast ADMM algorithm improves 100%~433% and 100%~900% respectively. In addition, the result of iterations to restart the fast ADMM algorithm obtained value 3 all in same scenario, and running time significantly reduced as well. This shows that restart fast ADMM algorithm is very robust. It is obvious from the energy change curve and the convergence curve that the fast ADMM algorithm generated ripples and decreased the restart fast ADMM algorithm. In calculation process, restart fast ADMM algorithm adaptively adjust step size to eliminate ripples and improve computational efficiency in accordance of the scale of the integrated residual. Conclusion The sub issues of alternate optimization are resolved in each iteration loop via fast Fourier transform method (FFT) or generalized soft thresholding formulas. Numerical experiments show that restart strategy can improve computational efficiency of original ADMM greatly as well as algorithm robustness on penalty parameters. Our contribution provides a qualified reference for fast algorithm of the second-order variational model in context of image restoration. The restart fast algorithm can be extended to variational model of image analysis with second-order derivative regular terms. However, ADMM algorithm and its restart fast algorithm lack sufficient theoretical support for the design of nonlinear, non-smooth, and non-convex variational models with high-order derivatives. Current theoretical research is limited to the optimization issue of objective function composed of two functions. For fast algorithm research of non-smooth and non-convex variational models of high-order derivatives in computer vision, our research is limited to tentative algorithm design and numerical verification.
Key words
image restoration; second-order variational model; fast alternating direction methods of multipliers (fast ADMM); restart; total Laplacian model; Euler's elastica model
0 引言
经过近30年的发展,变分方法已经成为图像处理与分析的重要数学基础(Scherzer,2015;Paragios等,2006;Aubert和Kornprobst,2006;Chan和Shen,2005),其中,图像恢复的变分模型具有基础地位。该类模型一般包含数据项和规则项,出于对图像特征保持的考虑,其规则项往往是非线性、非光滑,甚至是非凸的。这些特点不仅导致数值算法设计的困难,且其数值方法的计算效率往往较低,成为变分图像处理与分析模型工程应用的主要瓶颈之一(Kimmel和Tai,2019;Glowinski等,2016)。
以总变差(total variation,TV)(Rudin等,1992)为代表的一阶变分模型可以保持图像的边缘特征,是变分图像处理与分析问题的基础模型。为了克服基于原变量的时间步进方法(Rudin等,1992)和固定点迭代方法(Vogel和Oman,1996)计算效率低的问题,Chan等人(1999)提出了原—对偶变量方法(primal-dual method,PD),Chambolle(2004)提出了经典的对偶方法(dual method,DM),Goldstein和Osher(2009)提出了SB(split bregman) 方法。Wu和Tai(2010)证明,SB算法与增广Lagrange方法(augmented Lagrangian method,ALM)或交替方向乘子法(alternating direction methods of multipliers,ADMM)(Glowinski和Le Tallec,1989)是等价的。Daubechies等人(2004)以交替迭代优化为框架提出了经典的软阈值迭代算法(iterative shirinkage-thresholding algorithm,ISTA)。上述方法均为基于一阶导数或梯度的一阶方法,其收敛率为O (1/
早在20世纪80年代初,Nesterov(1983)针对光滑凸目标函数的优化问题,基于函数外插或惯性加速的思想,通过设计适当的惯性参数,将基于梯度的方法的算法收敛率提高至O (1/
基于二阶导数的变分模型可有效克服一阶导数模型引起的阶梯效应问题,其规则项的形式多样,且由于模型的非线性、非光滑性和非凸性,其计算效率低的问题更加突出。Bredies等人(2010)直接将Nesterov型加速方案应用于基于二阶导数的总广义变差(total generalized variation,TGV)模型计算;Liu等人(2012)设计了基于总海森(total Hessian,TH)变分模型的快速PDHG算法;Yashtini和Kang(2016)则用相同的方法设计了基于欧拉弹性能(Euler’s elastica,EE)的算法设计。Bredies等人(2010)的方法包含2个凸的非光滑规则项,Liu等人(2012)的方法包含1个凸的非光滑规则项,Yashtini和Kang(2016)的方法包含非凸、非光滑规则项,除快速算法本身可能引起的振荡问题,非凸性亦可引起能量上升,但前期研究均未考虑这些因素。重启动策略有望一并克服这些问题。
含二阶导数变分图像恢复模型的规则项主要包括总广义变差(TGV)(Bredies等,2010)、总拉普拉斯(total Laplacian,TL)(Chan等,2010)、总海森(total Hessian,TH)(Lysaker等,2003)、总平均曲率(total mean curvature,TMC)(Zhu等,2014)和欧拉弹性能(Euler’s elastica,EE)(Yashtini和Kang,2016;Tai等,2011;Kang等,2019)等形式,均为非强凸项,其中,TGV、TL和TH为凸非光滑项,TMC和EE为非凸非光滑项。
本文的目的是以快速ADMM方法为框架,探讨重启动快速算法在这些模型算法设计中应用的可能性。原始ADMM方法的收敛速率为O (1/
本文针对二阶模型在加速后进行重启动,真正提高算法的收敛速率。重启动快速ADMM方法的时间复杂度的精确分析很困难,故本文选用两种典型的基于拉普拉斯以及基于曲率的二阶模型进行研究,以探讨重启动快速ADMM方法的计算效率问题。本文方法亦可自然拓展到基于类似模型的重启动快速算法。
1 TV模型的重启动快速ADMM算法
图像噪声去除是图像恢复的基本问题,图像噪声去除的TV模型(Rudin等,1992)可表达为能量泛函极值问题,具体为
| $ \min E(u)=\frac{1}{2}\|u-f\|^{2}+\gamma\|\nabla u\| $ | (1) |
式中,
求解式(1)的ADMM方法(Goldstein等,2014;Buccini等,2020)是通过变量分裂将原优化问题转化为交替方向优化乘子方法,即引入辅助变量
| $ \left\{\begin{aligned} &\left(u^{k+1}, \boldsymbol{w}^{k+1}\right)=\operatorname{argmin} E(u, \boldsymbol{w}) \\ &\boldsymbol{\beta}^{k+1} =\boldsymbol{\beta}^{k}+\mu\left(\boldsymbol{w}^{k+1}-\nabla u^{k+1}\right) \\ &\ \ \ \ k =0, 1, \cdots, K \end{aligned}\right. $ | (2) |
式中,增广Lagrange函数为
| $ \begin{gathered} E(u, \boldsymbol{w})=\frac{1}{2}\|u-f\|^{2}+\gamma\|\boldsymbol{w}\|+\left\langle\boldsymbol{\beta}^{k}, \boldsymbol{w}-\nabla u\right\rangle+ \\ \frac{\mu}{2}\|\boldsymbol{w}-\nabla u\|^{2} \end{gathered} $ |
在交替优化过程中的两个子优化问题分别为
| $ \left\{\begin{array}{l} u^{k+1}=\operatorname{argmin} E\left(u, \boldsymbol{w}^{k}\right) \\ \boldsymbol{w}^{k+1}=\operatorname{argmin} E\left(u^{k+1}, \boldsymbol{w}\right) \end{array}\right. $ | (3) |
采用标准的变分方法,这两个子优化问题可应用一阶方法求解,其收敛率为O (1/
| $ \left\{\begin{array}{l} \boldsymbol{w}^{k+1} \longleftarrow \boldsymbol{w}^{k+1}+\boldsymbol{\theta}^{k+1}\left(\boldsymbol{w}^{k+1}-\boldsymbol{w}^{k}\right) \\ \boldsymbol{\beta}^{k+1} \longleftarrow \boldsymbol{\beta}^{k+1}+\boldsymbol{\theta}^{k+1}\left(\boldsymbol{\beta}^{k+1}-\boldsymbol{\beta}^{k}\right) \end{array}\right. $ | (4) |
Goldstein等人(2014)证明,采用该加速方案,其算法的收敛率可提高为O(1/
| $ c^{k+1}=\frac{1}{\mu}\left\|\boldsymbol{\beta}^{k+1}-\boldsymbol{\beta}^{k}\right\|^{2}+\mu\left\|\boldsymbol{w}^{k+1}-\boldsymbol{w}^{k}\right\|^{2} $ | (5) |
该残差公式包括原变量残差
| $ \alpha^{k+1}=1, \boldsymbol{w}^{k+1} \longleftarrow \boldsymbol{w}^{k}, \boldsymbol{\beta}^{k+1} \longleftarrow \boldsymbol{\beta}^{k}, c^{k+1} \longleftarrow c^{k} $ | (6) |
重启动快速ADMM方法不仅可以应用于强凸问题,亦可以应用于非完全凸的问题。当重启动快速ADMM方法应用于非完全凸的问题时,尽管不能像强凸情况那样保证全局收敛速度,但仍然可以确保目标的收敛并且进行加速。在实际的算法设计中,将重启动判断条件严格化为
算法1:TV模型的重启动快速ADMM算法
初始化:
| $ \alpha^{0}=1, c^{0}>0, \eta \in(0, 1) $ |
for
| $ u^{k+1}=\operatorname{argmin} E\left(u, \boldsymbol{w}^{k}\right) ; $ |
| $ \boldsymbol{w}^{k+1}=\operatorname{argmin} E\left(u^{k+1}, \boldsymbol{w}\right); $ |
| $ \boldsymbol{\beta}^{k+1} =\boldsymbol{\beta}^{k}+\mu\left(\boldsymbol{w}^{k+1}-\nabla u^{k+1}\right) ; $ |
| $ c^{k+1} =\mu\left|\boldsymbol{w}^{k+1}-\boldsymbol{w}^{k}\right|^{2}+\frac{1}{\mu}\left|\boldsymbol{\beta}^{k+1}-\boldsymbol{\beta}^{k}\right|^{2} ; $ |
| $ \text { if } c^{k+1}<\eta c^{k} \text { then } $ |
| $ \alpha^{k+1}=\frac{1+\sqrt{1+4\left(\alpha^{k}\right)^{2}}}{2} ; $ |
| $ \theta^{k+1}=\frac{\alpha^{k}-1}{\alpha^{k+1}} ; $ |
| $ \boldsymbol{w}^{k+1} \leftarrow \boldsymbol{w}^{k+1}+\theta^{k+1}\left(\boldsymbol{w}^{k+1}-\boldsymbol{w}^{k}\right) ; $ |
| $ \boldsymbol{\beta}^{k+1} \leftarrow \boldsymbol{\beta}^{k+1}+\theta^{k+1}\left(\boldsymbol{\beta}^{k+1}-\boldsymbol{\beta}^{k}\right) ; $ |
else;
| $ \alpha^{k+1}=1 ; $ |
| $ \boldsymbol{w}^{k+1} \longleftarrow \boldsymbol{w}^{k} ; $ |
| $ \boldsymbol{\beta}^{k+1} \longleftarrow \boldsymbol{\beta}^{k} ; $ |
| $ c^{k+1} \longleftarrow \frac{c^{k}}{\eta} ; $ |
end if;
直到
end for。
重启动快速ADMM方法的每次迭代属于以下3种类型之一:1)当算法中
这样,算法使用“重启动”方法增强函数值的单调性。这种类似的重启动规则已经用于针对无约束最小化的研究(Kim和Fessler,2018)。
2 TL模型的重启动快速ADMM算法
基于二阶导数图像恢复变分TL模型是为克服一阶TV模型的阶梯效应问题提出的(Lysaker等,2003),其能量泛函极小值问题为
| $ \min E(u)=\frac{1}{2}\|u-f\|^{2}+\gamma\|\Delta u\| $ | (7) |
式中,
为了克服TL规则项变分引起的计算困难,引入了两组辅助变量、Lagrange乘子及惩罚参数设计其ADMM算法,以便将原复杂优化问题转化为交替优化的一系列简单子优化问题求解。然后,这些子问题可以通过快速傅里叶变换(fast Fourier transform,FFT)和解析形式的软阈值公式进行求解。
引入辅助变量
| $ \left\{\begin{array}{l} \left(u^{k+1}, \boldsymbol{w}^{k+1}, v^{k+1}\right)=\operatorname{argmin} E(u, \boldsymbol{w}, v) \\ \boldsymbol{\beta}_{1}^{k+1}=\boldsymbol{\beta}_{1}^{k}+\mu_{1}\left(\boldsymbol{w}^{k+1}-\nabla u^{k+1}\right) \\ \beta_{2}^{k+1}=\beta_{2}^{k}+\mu_{2}\left(v^{k+1}-\nabla \cdot \boldsymbol{w}^{k+1}\right) \\ k=0, 1, \cdots, K \end{array}\right. $ | (8) |
式中,增广Lagrange函数为
| $ \begin{array}{c} E(u, \boldsymbol{w}, v)=\frac{1}{2}\|u-f\|^{2}+\gamma\|v\|+ \\ \left\langle\boldsymbol{\beta}_{1}^{k}, \boldsymbol{w}-\nabla u\right\rangle+\frac{\mu_{1}}{2}\|\boldsymbol{w}-\nabla u\|^{2}+ \\ \left\langle\beta_{2}^{k}, v-\nabla \cdot \boldsymbol{w}\right\rangle+\frac{\mu_{2}}{2}\|v-\nabla \cdot \boldsymbol{w}\|^{2} \end{array} $ |
式(8)中的3个子优化问题分别为
| $ \left\{\begin{array}{l} u^{k+1}=\operatorname{argmin} E\left(u, \boldsymbol{w}^{k}, v^{k}\right) \\ \boldsymbol{w}^{k+1}=\operatorname{argmin} E\left(u^{k+1}, \boldsymbol{w}, v^{k}\right) \\ v^{k+1}=\operatorname{argmin} E\left(u^{k+1}, \boldsymbol{w}^{k+1}, v^{k}\right) \end{array}\right. $ | (9) |
使用标准变分方法求解式(9)第1行,可得关于
| $ \begin{cases}u-f-\mu_{1} \nabla \cdot\left(\nabla u-\boldsymbol{w}^{k}-\frac{\boldsymbol{\beta}_{1}^{k}}{\mu_{1}}\right)=0 & x \in \boldsymbol{\varOmega} \\ \left(\nabla u-\boldsymbol{w}^{k}-\frac{\boldsymbol{\beta}_{1}^{k}}{\mu_{1}}\right) \cdot \boldsymbol{n}=0 & x \in \partial \boldsymbol{\varOmega}\end{cases} $ | (10) |
令
| $ u_{i, j}^{k+1}=R\left(F^{-1}\left(\frac{F\left(f_{i, j}^{k}\right)}{d}\right)\right) $ | (11) |
式中,
同样,使用标准变分方法求解式(9)第2行,可得关于
| $ \begin{cases}\mu_{1}\left(\boldsymbol{w}-\nabla \boldsymbol{u}^{k+1}+\frac{\boldsymbol{\beta}_{1}^{k}}{\mu_{1}}\right)-\mu_{2} \times & \\ \nabla\left(\nabla \cdot \boldsymbol{w}-v^{k}-\frac{\beta_{2}^{k}}{\mu_{2}}\right)=0 & x \in \boldsymbol{\varOmega} \\ \left(\nabla \cdot \boldsymbol{w}-v^{k}-\frac{\beta_{2}^{k}}{\mu_{2}}\right) n=0 & x \in \partial \boldsymbol{\varOmega}\end{cases} $ | (12) |
该方程组亦可采用FFT求解,即
| $ \left\{\begin{array}{l} w_{1_{i, j}}^{k+1}=\mathfrak{R}\left(F^{-1}\left(\frac{a_{22}\left(h_{1_{i, j}}^{k}\right)-a_{12}\left(h_{2_{i, j}}^{k}\right)}{D}\right)\right) \\ w_{2_{i, j}}^{k+1}=\mathfrak{R}\left(F^{-1}\left(\frac{a_{11} F\left(h_{2_{i, j}}^{k}\right)-a_{21} F\left(h_{1_{i, j}}^{k}\right)}{D}\right)\right) \end{array}\right. $ | (13) |
式中,
| $ h_{2_{i, j}}^{k}=-\mu_{2} \partial_{y}^{+}\left(v_{i, j}^{k}+\frac{\beta_{2}^{k}}{\mu_{2}}\right)+\mu_{1} \partial_{y}^{+}\left(u_{i, j}^{k}\right)-\beta_{1_{2 i, j}}^{k}, $ |
| $ \begin{aligned} &D=\operatorname{det}\left(\begin{array}{ll} a_{11} & a_{12} \\ a_{21} & a_{22} \end{array}\right)=\mu_{1}^{2}- \\ &2 \mu_{1} \mu_{2}\left(\cos \frac{2 {\rm{ \mathsf{ π} }} s}{N}+\cos \frac{2 {\rm{ \mathsf{ π} }} r}{M}-2\right), \end{aligned} $ |
| $ a_{11}=-2 \mu_{2}\left(\cos \frac{2 {\rm{ \mathsf{ π} }} s}{N}-1\right)+\mu_{1}, $ |
| $ \begin{aligned} &a_{12}=-\mu_{2}\left(1-\cos \frac{2 {\rm{ \mathsf{ π} }} r}{M}+\sqrt{-1} \sin \frac{2 {\rm{ \mathsf{ π} }} r}{M}\right) \times \\ &\left(-1+\cos \frac{2 {\rm{ \mathsf{ π} }} s}{N}+\sqrt{-1} \sin \frac{2 {\rm{ \mathsf{ π} }} s}{N}\right), \end{aligned} $ |
| $ \begin{aligned} &a_{21}=-\mu_{2}\left(1-\cos \frac{2 {\rm{ \mathsf{ π} }} s}{N}+\sqrt{-1} \sin \frac{2 {\rm{ \mathsf{ π} }} s}{N}\right) \times \\ &\left(-1+\cos \frac{2 {\rm{ \mathsf{ π} }} r}{M}+\sqrt{-1} \sin \frac{2 {\rm{ \mathsf{ π} }} r}{M}\right), \end{aligned} $ |
| $ a_{22}=-2 \mu_{2}\left(\cos \frac{2 {\rm{ \mathsf{ π} }} r}{M}-1\right)+\mu_{1} 。$ |
对于式(9)第3行,其解
| $ \begin{gathered} v_{i, j}^{k+1}=\max \left(\left|\nabla \cdot \boldsymbol{w}_{i, j}^{k+1}-\frac{\beta_{2_{i, j}}^{k}}{\mu_{2}}\right|-\frac{\gamma}{\mu_{2}}, 0\right) \times \\ \frac{\nabla \cdot \boldsymbol{w}_{i, j}^{k+1}-\frac{\beta_{2_{i, j}}^{k}}{\mu_{2}}}{\nabla \cdot \boldsymbol{w}_{i, j}^{k+1}-\frac{\beta_{2_{i, j}}^{k}}{\mu_{2}}+\varepsilon} \end{gathered} $ | (14) |
采用与Goldstein等人(2014)和Buccini等人(2020)相同的思路,可设计TL模型原变量与对偶变量组合残差公式,即
| $ \begin{gathered} c^{k+1}=\mu_{1}\left|\boldsymbol{w}^{k+1}-\boldsymbol{w}^{k}\right|^{2}+\mu_{2}\left|v^{k+1}-v^{k}\right|^{2}+\\ \frac{1}{\mu_{1}}\left|\beta_{1}^{k+1}-\beta_{1}^{k}\right|^{2}+\frac{1}{\mu_{2}}\left|\beta_{2}^{k+1}-\beta_{2}^{k}\right|^{2} \end{gathered} $ | (15) |
由此,得到应用于TL模型的重启动快速ADMM算法,描述如下。
算法2:TL模型的重启动快速ADMM算法
初始化:
| $ \alpha^{0}=1, c^{0}>0, \eta \in(0, 1) ; $ |
for
| $ u^{k+1}=\operatorname{argmin} E\left(u, \boldsymbol{w}^{k}, v^{k}\right) ; $ |
| $ \boldsymbol{w}^{k+1}=\operatorname{argmin} E\left(u^{k+1}, \boldsymbol{w}, v^{k}\right) ; $ |
| $ v^{k+1}=\operatorname{argmin} E\left(u^{k+1}, \boldsymbol{w}^{k+1}, v^{k}\right) ; $ |
| $ \boldsymbol{\beta}_{1}^{k+1}=\boldsymbol{\beta}_{1}^{k}+\mu_{1}\left(\boldsymbol{w}^{k+1}-\nabla u^{k+1}\right) ; $ |
| $ \boldsymbol{\beta}_{2}^{k+1}=\boldsymbol{\beta}_{2}^{k}+\mu_{2}\left(v^{k+1}-\nabla \cdot \boldsymbol{w}^{k+1}\right) ; $ |
| $ \begin{aligned} c^{k+1}=&\mu_{1}\left|\boldsymbol{w}^{k+1}-\boldsymbol{w}^{k}\right|^{2}+\mu_{2}\left|v^{k+1}-v^{k}\right|^{2}+ \\ &\frac{1}{\mu_{1}}\left|\boldsymbol{\beta}_{1}^{k+1}-\boldsymbol{\beta}_{1}^{k}\right|^{2}+\frac{1}{\mu_{2}}\left|\beta_{2}^{k+1}-\beta_{2}^{k}\right|^{2} ; \end{aligned} $ |
if
| $ \alpha^{k+1}=\frac{1+\sqrt{1+4\left(\alpha^{k}\right)^{2}}}{2} ; $ |
| $ \theta^{k+1}=\frac{\alpha^{k}-1}{\alpha^{k+1}} ; $ |
| $ \boldsymbol{w}^{k+1} \leftarrow \boldsymbol{w}^{k+1}+\theta^{k+1}\left(\boldsymbol{w}^{k+1}-\boldsymbol{w}^{k}\right) ; $ |
| $ \boldsymbol{\beta}_{1}^{k+1} \leftarrow \boldsymbol{\beta}_{1}^{k+1}+\theta^{k+1}\left(\boldsymbol{\beta}_{1}^{k+1}-\boldsymbol{\beta}_{1}^{k}\right) ; $ |
| $ \boldsymbol{\beta}_{2}^{k+1} \leftarrow \boldsymbol{\beta}_{2}^{k+1}+\theta^{k+1}\left(\boldsymbol{\beta}_{2}^{k+1}-\boldsymbol{\beta}_{2}^{k}\right) ; $ |
else
| $ \alpha^{k+1}=1 ; $ |
| $ \boldsymbol{w}^{k+1} \leftarrow \boldsymbol{w}^{k} ; $ |
| $ \boldsymbol{\beta}_{1}^{k+1} \leftarrow \boldsymbol{\beta}_{1}^{k} ; $ |
| $ \boldsymbol{\beta}_{2}^{k+1} \leftarrow \boldsymbol{\beta}_{2}^{k} ; $ |
| $ c^{k+1} \leftarrow \frac{c^{k}}{\eta} ; $ |
end if;
直至
end for。
3 EE模型的重启动快速ADMM算法
EE模型结合了TV规则项和曲率项,使用欧拉的弹性项作为规则项,相应的图像噪声去除变分模型为
| $ \begin{gathered} \min \limits_{u} E(u)=\frac{1}{2}\|\boldsymbol{u}-\boldsymbol{f}\|^{2}+\\ \left\langle a+b\left(\nabla \cdot\left(\frac{\nabla u}{|\nabla u|}\right)\right)^{2}, |\nabla u|\right\rangle \end{gathered} $ | (16) |
欧拉弹性能最早由Nitzberg等人(1993)应用于深度图像分割与虚幻轮廓恢复。Masnou和Morel(1998)将其推广到大破损图像修复,Zhu等人(2013)将其推广到图像分割变分模型。EE模型可以有效减少阶梯效应并产生更接近原图的图像,而且可以在去除噪声的同时保留图像的边缘信息。
在上述模型中,欧拉弹性项
引入辅助变量
| $ \begin{gathered} \min E(u)=\frac{1}{2}\|u-f\|^{2}+\left\langle a+b v^{2}, |\boldsymbol{w}|\right\rangle \\ \text { s.t. } \quad \boldsymbol{w}=\nabla u, \boldsymbol{p}=\frac{\boldsymbol{w}}{|\boldsymbol{w}|}, v=\nabla \cdot \boldsymbol{p} \end{gathered} $ | (17) |
但
| $ |\boldsymbol{p}| \leqslant 1, |\boldsymbol{w}|-\boldsymbol{p} \cdot \boldsymbol{w} \geqslant 0 $ | (18) |
为了进一步简化每个子优化问题的目标函数,再引入一个新的辅助向量
| $ \left\{\begin{array}{l} \boldsymbol{w}=\nabla u \\ |\boldsymbol{w}|-\boldsymbol{m} \cdot \boldsymbol{w} \geqslant 0 \\ v=\nabla \cdot \boldsymbol{p} \\ \boldsymbol{m}=\boldsymbol{p} \\ |\boldsymbol{m}| \leqslant 1 \end{array}\right. $ | (19) |
为表达方便,引入
在EE模型中,引入4个辅助变量
| $ \left\{\begin{array}{l} \left(u^{k+1}, \boldsymbol{w}^{k+1}, \boldsymbol{p}^{k+1}, v^{k+1}, \boldsymbol{m}^{k+1}\right)= \\ \operatorname{argmin} E(u, \boldsymbol{w}, \boldsymbol{p}, v, \boldsymbol{m}) \\ \boldsymbol{\beta}_{1}^{k+1}=\beta_{1}^{k}+\mu_{1}\left(\left|\boldsymbol{w}^{k+1}\right|-\boldsymbol{m}^{k+1} \cdot \boldsymbol{w}^{k+1}\right) \\ \boldsymbol{\beta}_{2}^{k+1}=\boldsymbol{\beta}_{2}^{k}+\mu_{2}\left(\boldsymbol{w}^{k+1}-\nabla u^{k+1}\right) \\ \boldsymbol{\beta}_{3}^{k+1}=\beta_{3}^{k}+\mu_{3}\left(v^{k+1}-\nabla \cdot \boldsymbol{p}^{k+1}\right) \\ \boldsymbol{\beta}_{4}^{k+1}=\boldsymbol{\beta}_{4}^{k}+\mu_{4}\left(\boldsymbol{m}^{k+1}-\boldsymbol{p}^{k+1}\right) \\ k=0, 1, \cdots, K \end{array}\right. $ | (20) |
式中,增广Lagrange函数为
| $ \begin{gathered} E(u, \boldsymbol{w}, \boldsymbol{p}, v, \boldsymbol{m})=\frac{1}{2}\left\|_{u}-f\right\|^{2}+\left\langle a+b v^{2}, |\boldsymbol{w}|\right\rangle+ \\ \left\langle\beta_{1}^{k}, |\boldsymbol{w}|-\boldsymbol{m} \cdot \boldsymbol{w}\right\rangle+\left\langle\mu_{1}, |\boldsymbol{w}|-\boldsymbol{m} \cdot \boldsymbol{w}\right\rangle+ \\ \left\langle\boldsymbol{\beta}_{2}^{k}, \boldsymbol{w}-\nabla u\right\rangle+\frac{\mu_{2}}{2}\|\boldsymbol{w}-\nabla u\|_{2}^{2}+ \\ \left\langle\beta_{3}^{k}, v-\nabla \cdot \boldsymbol{p}\right\rangle+\frac{\mu_{3}}{2}\|v-\nabla \cdot \boldsymbol{p}\|^{2}+ \\ \left\langle\boldsymbol{\beta}_{4}^{k}, \boldsymbol{m}-\boldsymbol{p}\right\rangle+\frac{\mu_{4}}{2}\|\boldsymbol{m}-\boldsymbol{p}\|_{2}^{2}+\delta(\boldsymbol{m}) \end{gathered} $ |
应用交替优化技术,式(20)中的5个子优化问题分别为
| $ \left\{\begin{array}{l} \boldsymbol{u}^{k+1}=\operatorname{argmin} E\left(u, \boldsymbol{w}^{k}, \boldsymbol{p}^{k}, v^{k}, \boldsymbol{m}^{k}\right) \\ \boldsymbol{w}^{k+1}=\operatorname{argmin} E\left(u^{k+1}, \boldsymbol{w}, \boldsymbol{p}^{k}, v^{k}, \boldsymbol{m}^{k}\right) \\ \boldsymbol{p}^{k+1}=\operatorname{argmin} E\left(u^{k+1}, \boldsymbol{w}^{k+1}, \boldsymbol{p}, v^{k}, \boldsymbol{m}^{k}\right) \\ v^{k+1}=\operatorname{argmin} E\left(u^{k+1}, \boldsymbol{w}^{k+1}, \boldsymbol{p}^{k+1}, v, \boldsymbol{m}^{k}\right) \\ \boldsymbol{m}^{k+1}=\operatorname{argmin} E\left(u^{k+1}, \boldsymbol{w}^{k+1}, \boldsymbol{p}^{k+1}, v^{k+1}, \boldsymbol{m}\right) \end{array}\right. $ | (21) |
使用标准变分方法求解式(21)第1行,得到关于
| $ \begin{cases}u-f-\mu_{2} \nabla \cdot\left(\nabla u-\boldsymbol{w}^{k}-\frac{\boldsymbol{\beta}_{2}^{k}}{\mu_{2}}\right)=0 & x \in \boldsymbol{\varOmega} \\ \left(\nabla u-\boldsymbol{w}^{k}-\frac{\boldsymbol{\beta}_{2}^{k}}{\mu_{2}}\right) \cdot \boldsymbol{n}=0 & x \in \partial \boldsymbol{\varOmega}\end{cases} $ | (22) |
令
| $ u_{i, j}^{k+1}=R\left(F^{-1}\left(\frac{F\left(f_{i, j}^{k}\right)}{d}\right)\right) $ | (23) |
式中,
对于式(21)第2行,其解
| $ \begin{gathered} \boldsymbol{w}_{i, j}^{k+1}=\max \left(\left|\boldsymbol{A}_{i, j}\right|-\frac{a+b\left(v_{i, j}^{k}\right)^{2}+\beta_{1_{i, j}}^{k}+\mu_{1}}{\mu_{2}}, 0\right) \times \\ \frac{\boldsymbol{A}_{i, j}}{\left|\boldsymbol{A}_{i, j}\right|}+\varepsilon \\ \boldsymbol{A}_{i, j}=\nabla u_{i, j}^{k+1}-\frac{\boldsymbol{\beta}_{2_{i, j}}^{k}}{\mu_{2}}+\frac{\beta_{1_{i, j}}^{k}+\mu_{1}}{\mu_{2}} \boldsymbol{m}_{i, j}^{k} \end{gathered} $ | (24) |
同样,使用标准变分方法求解式(21)第3行,可得关于
| $ \left\{\begin{array}{cl} -\mu_{3} \nabla\left(\nabla \cdot \boldsymbol{p}-v^{k}-\frac{\beta_{3}^{k}}{\mu_{3}}\right)+ & \\ \mu_{4}\left(\boldsymbol{m}^{k}-\boldsymbol{p}+\frac{\boldsymbol{\beta}_{4}^{k}}{\mu_{4}}\right)=0 & x \in \boldsymbol{\varOmega} \\ \left(\nabla \cdot \boldsymbol{p}-v^{k}-\frac{\beta_{3}^{k}}{\mu_{3}}\right) \boldsymbol{n}=0 & x \in \partial \boldsymbol{\varOmega} \end{array}\right. $ | (25) |
该方程组亦可采用FFT求解,即
| $ \left\{\begin{array}{l} p_{1_{i, j}}^{k+1}=\mathfrak{R}\left(F^{-1}\left(\frac{a_{22} F\left(h_{1_{i, j}}^{k}\right)-a_{12} F\left(h_{2_{i, j}}^{k}\right)}{D}\right)\right) \\ p_{2_{i, j}}^{k+1}=\mathfrak{R}\left(F^{-1}\left(\frac{a_{11} F\left(h_{2_{i, j}}^{k}\right)-a_{21} F\left(h_{1_{i, j}}^{k}\right)}{D}\right)\right) \end{array}\right. $ | (26) |
式中,
| $ h_{1_{i, j}}^{k}=-\mu_{3} \partial_{x}^{+}\left(v_{i, j}^{k}+\frac{\beta_{3_{1_{i, j}}}^{k}}{k}\right)-\mu_{4} m_{1_{i, j}}^{k}-\beta_{4_{1_{i, j}}}^{k}, $ |
| $ \begin{aligned} &D=\operatorname{det}\left(\begin{array}{ll} a_{11} & a_{12} \\ a_{21} & a_{22} \end{array}\right)=\mu_{4}^{2}+2 \mu_{3}\ \mu_{4} \times \\ &\left(\cos \frac{2 {\rm{ \mathsf{ π} }} s}{N}+\cos \frac{2 {\rm{ \mathsf{ π} }} r}{M}-2\right), \end{aligned} $ |
| $ a_{11}=-2 \mu_{3}\left(\cos \frac{2 {\rm{ \mathsf{ π} }} s}{N}-1\right)-\mu_{4}, $ |
| $ \begin{aligned} &a_{12}=-\mu_{3}\left(1-\cos \frac{2 {\rm{ \mathsf{ π} }} r}{M}+\sqrt{-1} \sin \frac{2 {\rm{ \mathsf{ π} }} r}{M}\right) \times \\ &\left(-1+\cos \frac{2 {\rm{ \mathsf{ π} }} s}{N}+\sqrt{-1} \sin \frac{2 {\rm{ \mathsf{ π} }} s}{N}\right), \end{aligned} $ |
| $ \begin{aligned} &a_{21}=-\mu_{3}\left(1-\cos \frac{2 {\rm{ \mathsf{ π} }} s}{N}+\sqrt{-1} \sin \frac{2 {\rm{ \mathsf{ π} }} s}{N}\right) \times \\ &\left(-1+\cos \frac{2 {\rm{ \mathsf{ π} }} r}{M}+\sqrt{-1} \sin \frac{2 {\rm{ \mathsf{ π} }} r}{M}\right), \end{aligned} $ |
| $ a_{22}=-2 \mu_{3}\left(\cos \frac{2 {\rm{ \mathsf{ π} }} r}{M}-1\right)-\mu_{4}。$ |
使用标准变分方法求解式(21)第4行,可得关于
| $ 2 b\left|\boldsymbol{w}^{k+1}\right| v+\mu_{3}\left(v-\nabla \cdot \boldsymbol{p}^{k+1}+\frac{\beta_{3}^{k}}{\mu_{3}}\right)=0 $ | (27) |
相应的解析解为
| $ v_{i, j}^{k+1}=\frac{\mu_{3} \nabla \cdot \boldsymbol{p}_{i, j}^{k+1}-\beta_{3_{i, j}}^{k}}{2 b\left|\boldsymbol{w}_{i, j}^{k+1}\right|+\mu_{3}} $ | (28) |
使用标准变分方法求解式(21)第5行,可得关于
| $ -\left(\mu_{1}+\beta_{1}^{k}\right) \boldsymbol{w}^{k+1}+\mu_{4}\left(\boldsymbol{m}-\boldsymbol{p}^{k+1}+\frac{\boldsymbol{\beta}_{4}^{k}}{\mu_{4}}\right)=0 $ | (29) |
相应的解析解为
| $ \tilde{\boldsymbol{m}}_{i, j}^{k+1}=\frac{\mu_{1}+\boldsymbol{\beta}_{1_{i, j}}^{k}}{\mu_{4}} \boldsymbol{w}_{i, j}^{k+1}-\frac{\boldsymbol{\beta}_{4_{i, j}}^{k}}{\mu_{4}}+\boldsymbol{p}_{i, j}^{k+1} $ | (30) |
为了满足
| $ \boldsymbol{m}_{i, j}^{k+1}=\frac{\tilde{\boldsymbol{m}}_{i, j}^{k+1}}{\max \left(\left|\tilde{\boldsymbol{m}}_{i, j}^{k+1}\right|, 1\right)} $ | (31) |
采用与Goldstein等人(2014)和Buccini等人(2020)相同的策略,设计EE模型的原变量和对偶变量组合残差公式,即
| $ \begin{gathered} c^{k+1}=\mu_{1}\left|\boldsymbol{p}^{k+1}-\boldsymbol{p}^{k}\right|^{2}+\mu_{2}\left|\boldsymbol{w}^{k+1}-\boldsymbol{w}^{k}\right|^{2}+ \\ \mu_{3}\left|v^{k+1}-v^{k}\right|^{2}+\mu_{4}\left|\boldsymbol{m}^{k+1}-\boldsymbol{m}^{k}\right|^{2}+ \\ \frac{1}{\mu_{1}}\left|\beta_{1}^{k+1}-\beta_{1}^{k}\right|^{2}+\frac{1}{\mu_{2}}\left|\boldsymbol{\beta}_{2}^{k+1}-\boldsymbol{\beta}_{2}^{k}\right|^{2}+ \\ \frac{1}{\mu_{3}}\left|\beta_{3}^{k+1}-\beta_{3}^{k}\right|^{2}+\frac{1}{\mu_{4}}\left|\boldsymbol{\beta}_{4}^{k+1}-\boldsymbol{\beta}_{4}^{k}\right|^{2} \end{gathered} $ | (32) |
由此,得到应用于EE模型的重启动快速ADMM算法,描述如下。
算法3:EE模型的重启动快速ADMM算法
初始化:
| $ \begin{aligned} &\left(\mu_{1}, \mu_{2}, \mu_{3}, \mu_{4}\right)>0, \alpha^{0}=1, c^{0}>0, \eta \in\\ (0, 1)& \end{aligned} $ |
for
| $ u^{k+1}=\operatorname{argmin} E\left(u, \boldsymbol{w}^{k}, \boldsymbol{p}^{k}, v^{k}, \boldsymbol{m}^{k}\right) ; $ |
| $ \boldsymbol{w}^{k+1}=\operatorname{argmin} E\left(u^{k+1}, \boldsymbol{w}, \boldsymbol{p}^{k}, v^{k}, \boldsymbol{m}^{k}\right) ; $ |
| $ \boldsymbol{p}^{k+1}=\operatorname{argmin} E\left(u^{k+1}, \boldsymbol{w}^{k+1}, \boldsymbol{p}, v^{k}, \boldsymbol{m}^{k}\right) ; $ |
| $ v^{k+1}=\operatorname{argmin} E\left(u^{k+1}, \boldsymbol{w}^{k+1}, \boldsymbol{p}^{k+1}, v, \boldsymbol{m}^{k}\right) ; $ |
| $ \boldsymbol{m}^{k+1}=\operatorname{argmin} E\left(u^{k+1}, \boldsymbol{w}^{k+1}, \boldsymbol{p}^{k+1}, v^{k+1}, \boldsymbol{m}\right) ; $ |
| $ \beta_{1}^{k+1}=\beta_{1}^{k}+\mu_{1}\left(\left|\boldsymbol{w}^{k+1}\right|-\boldsymbol{m}^{k+1} \cdot \boldsymbol{w}^{k+1}\right) ; $ |
| $ \boldsymbol{\beta}_{2}^{k+1}=\boldsymbol{\beta}_{2}^{k}+\mu_{2}\left(\boldsymbol{w}^{k+1}-\nabla u^{k+1}\right) ; $ |
| $ \beta_{3}^{k+1}=\beta_{3}^{k}+\mu_{3}\left(v^{k+1}-\nabla \cdot \boldsymbol{p}^{k+1}\right) ; $ |
| $ \boldsymbol{\beta}_{4}^{k+1}=\boldsymbol{\beta}_{4}^{k}+\mu_{4}\left(\boldsymbol{m}^{k+1}-\boldsymbol{p}^{k+1}\right) ; $ |
| $ \begin{aligned} c^{k+1}=& \mu_{1}\left|\boldsymbol{p}^{k+1}-\boldsymbol{p}^{k}\right|^{2}+\mu_{2}\left|\boldsymbol{w}^{k+1}-\boldsymbol{w}^{k}\right|^{2}+\\ & \mu_{3}\left|v^{k+1}-v^{k}\right|^{2}+\mu_{4}\left|\boldsymbol{m}^{k+1}-\boldsymbol{m}^{k}\right|^{2}+\\ & \frac{1}{\mu_{1}}\left|\beta_{1}^{k+1}-\beta_{1}^{k}\right|^{2}+\frac{1}{\mu_{2}}\left|\boldsymbol{\beta}_{2}^{k+1}-\boldsymbol{\beta}_{2}^{k}\right|^{2}+\\ & \frac{1}{\mu_{3}}\left|\beta_{3}^{k+1}-\beta_{3}^{k}\right|^{2}+\frac{1}{\mu_{4}}\left|\boldsymbol{\beta}_{4}^{k+1}-\boldsymbol{\beta}_{4}^{k}\right|^{2} ; \end{aligned} $ |
if
| $ \alpha^{k+1} =\frac{1+\sqrt{1+4\left(\alpha^{k}\right)^{2}}}{2} ; $ |
| $ \theta^{k+1} =\frac{\alpha^{k}-1}{\alpha^{k+1}} ; $ |
| $ \boldsymbol{w}^{k+1} \leftarrow \boldsymbol{w}^{k+1}+\theta^{k+1}\left(\boldsymbol{w}^{k+1}-\boldsymbol{w}^{k}\right) ; $ |
| $ \beta_{1}^{k+1} \leftarrow \beta_{1}^{k+1}+\theta^{k+1}\left(\beta_{1}^{k+1}-\beta_{1}^{k}\right) ; $ |
| $ \boldsymbol{\beta}_{2}^{k+1} \leftarrow \boldsymbol{\beta}_{2}^{k+1}+\theta^{k+1}\left(\boldsymbol{\beta}_{2}^{k+1}-\boldsymbol{\beta}_{2}^{k}\right) ; $ |
else
| $ \boldsymbol{\alpha}^{k+1}=1; $ |
| $ \boldsymbol{w}^{k+1} \longleftarrow \boldsymbol{w}^{k}; $ |
| $ \beta_{1}^{k+1} \longleftarrow \beta_{1}^{k}; $ |
| $ \boldsymbol{\beta}_{2}^{k+1} \longleftarrow \boldsymbol{\beta}_{2}^{k}; $ |
| $ c^{k+1} \longleftarrow \frac{c^{k}}{\eta}; $ |
end if;
直到
end for。
4 数值实验
针对TL模型和EE模型在噪声去除和边缘保持等方面的性能已经有了大量研究。本文研究的重点是在相关惩罚参数确定的情况下,在保持原有模型噪声去除性态的基础上,比较原始ADMM、快速ADMM和重启动快速ADMM方法的计算效率。
实验使用了15幅测试图像分别比较了3种方法的计算效率,其结论基本一致。本文选取具有代表性的5组实验进行说明,实验中使用的5幅测试图像来自美国南加州大学信号与图像处理研究所数据库,如图 1所示。用0~255范围内的像素值缩放图像,图 1(b)为方差


由于TL模型和EE模型的解决方案通常不是唯一的,无法比较均方根差(root mean square error,RMSE)。实验时,使用相对能量误差
实验使用3.19 GHz CPU,在Windows 10(64位)操作系统下用MATLAB R2016a版本进行。
4.1 Total Laplacian模型
TL模型如式(7)所示。
快速算法的目标是在保证图像质量不降低的基础上,提高算法的收敛速率从而加快计算效率。以Texture图像(图 1第3行)为例,图 2展示了原始ADMM、快速ADMM和重启动快速ADMM这3种算法应用到TL模型后输出的图像,3种算法的参数取值均为

惩罚参数的数值理论上可以无穷大,但由于引入了Lagrange方程,惩罚可以通过Lagrange乘子
表 1为3种算法在TL模型中去除高斯白噪声的性能比较。可以看出: 1)当惩罚参数相同时,对同一模型3种算法的PSNR基本一致,说明快速算法没有破坏原有模型的性态,没有影响原始ADMM算法的图像质量。2)对不同图像选取了大量的惩罚参数。与原始ADMM算法相比,大部分快速ADMM算法的计算效率提高了6%~50%,最高可以提高50%,如实验10—12等。需要注意的是,实验1—3、7—9、13—15、19—21、25—27中,快速ADMM算法加速无效。这是由于快速ADMM算法的最优步长依赖于目标函数的凸性和光滑性,但TL模型是非光滑的,理论上相关的光滑参数和Lipschitz参数很难估计,故快速ADMM算法无法计算最优步长(O’Donoghue和Candès,2015)。3)相同的模型对相同的图像无论取什么参数,重启动快速ADMM算法的迭代次数都是3,运行时间也明显下降,说明重启动快速ADMM算法非常稳健。与原始ADMM算法相比,重启动快速ADMM算法的计算效率提高了100%~433%,最高可以提高433%,如实验4—6等;4)重启动快速ADMM算法将TL模型中的复杂优化问题转化的一系列子问题,通过FFT和解析形式的软阈值公式进行求解,使迭代步数比传统ADMM方法大幅降低。
表 1
TL模型消除高斯白噪声的运行结果
Table 1
Running results of TL model to eliminate Gaussian noise
| 序号 | 图像 | 原始ADMM | 快速ADMM | 重启动快速ADMM | ||||||||||
| 步数 | 时间/s | PSNR/dB | 步数 | 时间/s | PSNR/dB | 步数 | 时间/s | PSNR/dB | ||||||
| 1 | Lena | 5 | 0.001 | 11 | 0.244 | 24.998 | 11 | 0.400 | 25.012 | 3 | 0.124 | 25.076 | ||
| 2 | Lena | 5 | 0.01 | 11 | 0.209 | 24.978 | 11 | 0.252 | 25.023 | 3 | 0.081 | 25.062 | ||
| 3 | Lena | 5 | 0.1 | 11 | 0.208 | 25.018 | 8 | 0.156 | 24.953 | 3 | 0.066 | 25.103 | ||
| 4 | Lena | 20 | 0.001 | 16 | 0.262 | 22.838 | 15 | 0.296 | 22.831 | 3 | 0.065 | 22.142 | ||
| 5 | Lena | 20 | 0.01 | 16 | 0.367 | 22.826 | 15 | 0.265 | 22.869 | 3 | 0.060 | 22.154 | ||
| 6 | Lena | 20 | 0.1 | 16 | 0.242 | 22.858 | 11 | 0.213 | 22.770 | 3 | 0.063 | 22.152 | ||
| 7 | Castle | 5 | 0.001 | 10 | 0.957 | 24.057 | 7 | 0.770 | 24.038 | 3 | 0.443 | 24.409 | ||
| 8 | Castle | 5 | 0.01 | 10 | 0.851 | 24.079 | 7 | 0.626 | 24.063 | 3 | 0.392 | 24.423 | ||
| 9 | Castle | 5 | 0.1 | 10 | 0.826 | 24.092 | 7 | 0.619 | 24.063 | 3 | 0.351 | 24.412 | ||
| 10 | Castle | 20 | 0.001 | 15 | 1.266 | 22.762 | 10 | 0.898 | 22.732 | 3 | 0.349 | 22.640 | ||
| 11 | Castle |
20 | 0.01 | 15 | 1.300 | 22.761 | 10 | 0.917 | 22.746 | 3 | 0.348 | 22.635 | ||
| 12 | Castle | 20 | 0.1 | 15 | 1.314 | 22.788 | 10 | 0.896 | 22.778 | 3 | 0.342 | 22.631 | ||
| 13 | Texture | 5 | 0.001 | 10 | 6.314 | 26.518 | 10 | 10.621 | 26.542 | 3 | 2.706 | 26.969 | ||
| 14 | Texture | 5 | 0.01 | 10 | 5.930 | 26.532 | 11 | 10.513 | 26.598 | 3 | 2.386 | 26.963 | ||
| 15 | Texture | 5 | 0.1 | 11 | 6.262 | 26.585 | 8 | 5.021 | 26.551 | 3 | 2.292 | 26.951 | ||
| 16 | Texture | 20 | 0.001 | 15 | 8.859 | 24.823 | 10 | 5.973 | 24.755 | 3 | 2.241 | 24.685 | ||
| 17 | Texture | 20 | 0.01 | 15 | 12.230 | 24.824 | 10 | 5.971 | 24.762 | 3 | 2.202 | 24.690 | ||
| 18 | Texture | 20 | 0.1 | 15 | 13.796 | 24.838 | 10 | 5.888 | 24.786 | 3 | 2.277 | 24.684 | ||
| 19 | Barbara | 5 | 0.001 | 10 | 1.333 | 22.498 | 7 | 1.147 | 22.484 | 3 | 0.533 | 22.683 | ||
| 20 | Barbara | 5 | 0.01 | 10 | 1.340 | 22.502 | 7 | 1.012 | 22.495 | 3 | 0.468 | 22.678 | ||
| 21 | Barbara | 5 | 0.1 | 10 | 1.263 | 22.521 | 8 | 1.138 | 22.510 | 3 | 0.480 | 22.660 | ||
| 22 | Barbara | 20 | 0.001 | 14 | 1.634 | 21.606 | 10 | 1.377 | 21.589 | 3 | 0.479 | 21.391 | ||
| 23 | Barbara | 20 | 0.01 | 14 | 1.769 | 21.604 | 10 | 1.466 | 21.590 | 3 | 0.460 | 21.393 | ||
| 24 | Barbara | 20 | 0.1 | 14 | 1.657 | 21.612 | 10 | 1.298 | 21.604 | 3 | 0.461 | 21.392 | ||
| 25 | Peppers | 5 | 0.001 | 10 | 3.298 | 27.516 | 10 | 1.701 | 27.550 | 3 | 1.125 | 27.627 | ||
| 26 | Peppers | 5 | 0.01 | 10 | 2.227 | 27.574 | 7 | 1.486 | 27.531 | 3 | 0.888 | 27.651 | ||
| 27 | Peppers | 5 | 0.1 | 10 | 2.015 | 27.589 | 7 | 1.587 | 27.542 | 3 | 0.788 | 27.608 | ||
| 28 | Peppers | 20 | 0.001 | 6 | 0.892 | 26.517 | 11 | 3.534 | 25.875 | 3 | 1.277 | 25.053 | ||
| 29 | Peppers | 20 | 0.01 | 15 | 1.736 | 25.930 | 11 | 2.872 | 25.873 | 3 | 1.310 | 25.082 | ||
| 30 | Peppers | 20 | 0.1 | 6 | 0.727 | 26.490 | 11 | 2.366 | 25.923 | 3 | 1.293 | 25.077 | ||
| 注:加粗字体为快速算法迭代步数的最优结果。 | ||||||||||||||
表 2为3种算法在TL模型中去除椒盐噪声的性能比较。TL模型在消除椒盐噪声中的各项实验数据与消除高斯白噪声的实验数据基本类似。如不同参数对于快速ADMM方法的计算效率影响较大。当
表 2
TL模型消除椒盐噪声的运行结果
Table 2
Running results of TL model to eliminate salt and pepper noise
| 序号 | 图像 | 原始ADMM | 快速ADMM | 重启动快速ADMM | ||||||||||
| 步数 | 时间/s | PSNR/dB | 步数 | 时间/s | PSNR/dB | 步数 | 时间/s | PSNR/dB | ||||||
| 1 | Lena | 5 | 0.001 | 11 | 0.226 | 25.585 | 11 | 0.250 | 25.548 | 3 | 0.151 | 25.5 | ||
| 2 | Lena | 5 | 0.01 | 11 | 0.148 | 25.591 | 11 | 0.208 | 25.609 | 3 | 0.091 | 25.478 | ||
| 3 | Lena | 5 | 0.1 | 12 | 0.165 | 25.615 | 8 | 0.137 | 25.579 | 3 | 0.063 | 25.478 | ||
| 4 | Lena | 20 | 0.001 | 17 | 0.237 | 22.965 | 15 | 0.238 | 22.999 | 3 | 0.062 | 22.23 | ||
| 5 | Lena | 20 | 0.01 | 17 | 0.232 | 22.997 | 15 | 0.250 | 23.018 | 3 | 0.074 | 22.233 | ||
| 6 | Lena | 20 | 0.1 | 17 | 0.277 | 23 | 11 | 0.191 | 22.959 | 3 | 0.060 | 22.215 | ||
| 7 | Castle | 5 | 0.001 | 10 | 1.325 | 22.826 | 7 | 1.063 | 22.803 | 3 | 0.575 | 22.881 | ||
| 8 | Castle | 5 | 0.01 | 10 | 1.179 | 22.826 | 7 | 0.881 | 22.828 | 3 | 0.509 | 22.874 | ||
| 9 | Castle | 5 | 0.1 | 10 | 1.164 | 22.839 | 7 | 0.883 | 22.819 | 3 | 0.494 | 22.855 | ||
| 10 | Castle | 20 | 0.001 | 14 | 1.603 | 21.715 | 10 | 1.258 | 21.697 | 3 | 0.446 | 21.426 | ||
| 11 | Castle |
20 | 0.01 | 14 | 1.636 | 21.71 | 10 | 1.253 | 21.702 | 3 | 0.458 | 21.424 | ||
| 12 | Castle | 20 | 0.1 | 14 | 1.746 | 21.716 | 10 | 1.240 | 21.704 | 3 | 0.446 | 21.420 | ||
| 13 | Texture | 5 | 0.001 | 10 | 0.889 | 24.563 | 10 | 0.932 | 24.594 | 3 | 0.385 | 24.768 | ||
| 14 | Texture | 5 | 0.01 | 10 | 0.777 | 24.578 | 7 | 0.574 | 24.561 | 3 | 0.325 | 24.775 | ||
| 15 | Texture | 5 | 0.1 | 11 | 0.855 | 24.601 | 11 | 0.908 | 24.609 | 3 | 0.314 | 24.748 | ||
| 16 | Texture | 20 | 0.001 | 16 | 1.239 | 22.939 | 10 | 0.825 | 22.903 | 3 | 0.299 | 22.715 | ||
| 17 | Texture | 20 | 0.01 | 15 | 1.191 | 22.930 | 10 | 0.827 | 22.914 | 3 | 0.622 | 22.723 | ||
| 18 | Texture | 20 | 0.1 | 15 | 1.213 | 22.919 | 10 | 0.818 | 22.91 | 3 | 0.309 | 22.713 | ||
| 19 | Barbara | 5 | 0.001 | 4 | 2.172 | 28.121 | 11 | 6.636 | 27.458 | 3 | 2.360 | 27.614 | ||
| 20 | Barbara | 5 | 0.01 | 4 | 2.116 | 28.119 | 11 | 6.092 | 27.503 | 3 | 2.111 | 27.616 | ||
| 21 | Barbara | 5 | 0.1 | 11 | 5.750 | 27.468 | 11 | 6.146 | 27.513 | 3 | 1.971 | 27.590 | ||
| 22 | Barbara | 20 | 0.001 | 16 | 8.317 | 25.102 | 10 | 5.694 | 25.051 | 3 | 1.990 | 24.863 | ||
| 23 | Barbara | 20 | 0.01 | 15 | 7.777 | 25.116 | 10 | 5.845 | 25.053 | 3 | 1.947 | 24.863 | ||
| 24 | Barbara | 20 | 0.1 | 16 | 8.288 | 25.118 | 10 | 5.846 | 25.069 | 3 | 1.954 | 24.857 | ||
| 25 | Peppers | 5 | 0.001 | 11 | 1.497 | 28.680 | 11 | 1.504 | 28.677 | 3 | 0.554 | 28.381 | ||
| 26 | Peppers | 5 | 0.01 | 11 | 1.348 | 28.681 | 11 | 1.389 | 28.739 | 3 | 0.481 | 28.357 | ||
| 27 | Peppers | 5 | 0.1 | 11 | 1.369 | 28.689 | 11 | 1.427 | 28.735 | 3 | 0.459 | 28.314 | ||
| 28 | Peppers | 20 | 0.001 | 6 | 0.695 | 26.874 | 5 | 0.640 | 26.891 | 3 | 0.441 | 25.225 | ||
| 29 | Peppers | 20 | 0.01 | 6 | 0.784 | 26.863 | 5 | 0.633 | 26.897 | 3 | 0.443 | 25.218 | ||
| 30 | Peppers | 20 | 0.1 | 17 | 2.143 | 26.236 | 5 | 0.614 | 26.887 | 3 | 0.444 | 25.214 | ||
| 注:加粗字体为快速算法迭代步数的最优结果。 | ||||||||||||||
为了可以更清晰地了解在计算过程中3种算法的能量值和相对能量误差的变化趋势,以TL模型消除高斯白噪声为例,对3种算法在TL模型中迭代40次的能量值进行比较,结果如图 3所示。图 4表示使用相对能量误差作为停止准则时,3种算法在TL模型中的收敛曲线。参数取值均为
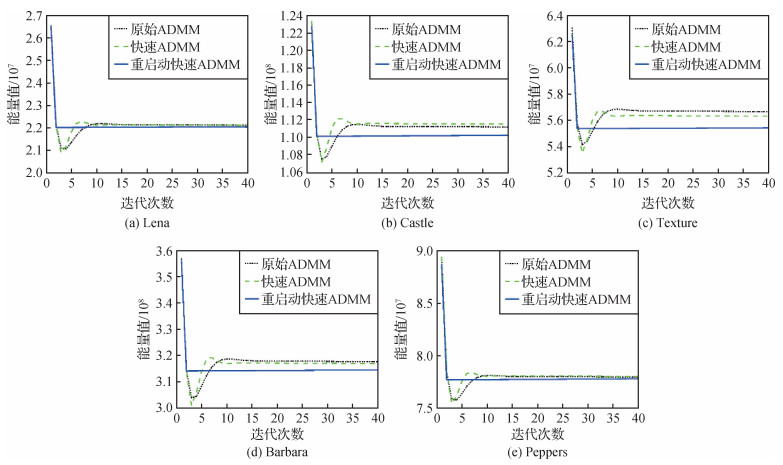
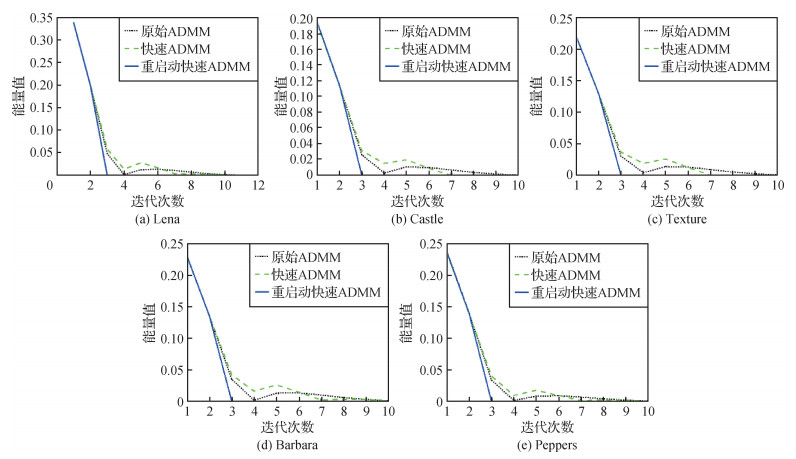
从图 3和图 4可以看出,重启动快速ADMM算法的能量值和相对能量误差是单调下降的,且能量值达到稳定状态最快;快速ADMM算法会产生振荡。这是由于TL模型的非光滑性,使光滑参数和Lipschitz参数很难估计,导致振荡的周期很难估计。重启动快速ADMM算法在计算过程中根据组合残差的大小,自适应地调整步长从而消除振荡现象,提高了计算效率。
4.2 Euler’s elastica模型
EE模型如式(16)所示。其中
3种算法在EE模型中消除高斯白噪声的性能比较如表 3所示。由于数据过多,表 3只显示Lena图像的数据结果。从表 3可以看出: 1)惩罚参数相同时,对同一模型3种算法的峰值信噪比(PSNR)基本一致,说明快速算法没有影响原始ADMM算法的图像质量。2)惩罚参数不同的情况下,与原始ADMM算法相比,大部分快速ADMM算法的计算效率提高了14%~54%,最优结果为实验13。与TL模型相似,实验2、4中快速ADMM算法在EE模型存在加速无效的情况,EE模型的非凸性和非光滑性加大了计算最优步长的难度。3)相同的模型无论取什么参数,重启动快速ADMM算法的迭代次数都是3,运行时间明显下降,说明重启动快速ADMM算法非常稳健。与原始ADMM算法相比,重启动快速ADMM算法的计算效率提高了100%~900%,最优结果为实验14。4)
表 3
EE模型消除高斯白噪声的运行结果
Table 3
Running results of EE model to eliminate Gaussian noise
| 序号 | 图像 | 原始ADMM | 快速ADMM | 重启动快速ADMM | ||||||||||||
| 步数 | 时间/s | PSNR/dB | 步数 | 时间/s | PSNR/dB | 步数 | 时间/s | PSNR/dB | ||||||||
| 1 | Lena | 0.06 | 2 | 2 000 | 400 | 8 | 0.614 | 26.174 | 6 | 0.243 | 26.188 | 3 | 0.179 | 26.555 | ||
| 2 | Lena | 0.06 | 2 | 2 000 | 40 000 | 8 | 0.259 | 26.188 | 8 | 0.273 | 26.223 | 3 | 0.124 | 26.527 | ||
| 3 | Lena | 0.06 | 2 | 20 000 | 400 | 8 | 0.336 | 26.217 | 6 | 0.191 | 26.188 | 3 | 0.111 | 26.541 | ||
| 4 | Lena | 0.06 | 2 | 20 000 | 40 000 | 8 | 0.248 | 26.191 | 8 | 0.314 | 26.251 | 3 | 0.107 | 26.515 | ||
| 5 | Lena | 0.06 | 20 | 2 000 | 400 | 16 | 0.444 | 23.135 | 14 | 0.464 | 23.163 | 3 | 0.109 | 22.405 | ||
| 6 | Lena | 0.06 | 20 | 2 000 | 40 000 | 15 | 0.430 | 23.122 | 10 | 0.339 | 23.130 | 3 | 0.114 | 22.378 | ||
| 7 | Lena | 0.06 | 20 | 20 000 | 400 | 15 | 0.411 | 23.135 | 10 | 0.353 | 23.109 | 3 | 0.111 | 22.417 | ||
| 8 | Lena | 0.06 | 20 | 20 000 | 40 000 | 15 | 0.415 | 23.142 | 10 | 0.401 | 23.114 | 3 | 0.107 | 22.398 | ||
| 9 | Lena | 0.6 | 2 | 2 000 | 400 | 13 | 0.359 | 26.334 | 10 | 0.389 | 26.114 | 3 | 0.106 | 26.564 | ||
| 10 | Lena | 0.6 | 2 | 2 000 | 40 000 | 20 | 0.565 | 24.281 | 15 | 0.700 | 23.241 | 3 | 0.109 | 26.582 | ||
| 11 | Lena | 0.6 | 2 | 20 000 | 400 | 16 | 0.583 | 26.018 | 13 | 0.434 | 23.124 | 3 | 0.109 | 26.594 | ||
| 12 | Lena | 0.6 | 2 | 20 000 | 40 000 | 20 | 0.689 | 23.953 | 15 | 0.457 | 23.042 | 3 | 0.109 | 26.608 | ||
| 13 | Lena | 0.6 | 20 | 2 000 | 400 | 17 | 0.467 | 23.130 | 11 | 0.345 | 23.151 | 3 | 0.108 | 22.368 | ||
| 14 | Lena | 0.6 | 20 | 2 000 | 40 000 | 33 | 0.887 | 22.505 | 26 | 0.784 | 22.041 | 3 | 0.118 | 22.409 | ||
| 15 | Lena | 0.6 | 20 | 20 000 | 400 | 6 | 0.191 | 23.660 | 5 | 0.160 | 23.759 | 3 | 0.109 | 22.379 | ||
| 16 | Lena | 0.6 | 20 | 20 000 | 40 000 | 30 | 0.851 | 22.507 | 24 | 0.724 | 22.039 | 3 | 0.111 | 22.379 | ||
| 注:加粗字体为快速算法迭代步数的最优结果。 | ||||||||||||||||
3种算法在EE模型中消除椒盐噪声的性能比较如表 4所示。可以看出: 1)惩罚参数相同时,对同一模型,3种算法的峰值信噪比(PSNR)基本一致。2)与原始ADMM算法相比,大部分快速ADMM算法的计算效率提高了10%~83%,最优结果为实验16。与TL模型相似,快速ADMM算法在EE模型存在加速无效的情况,如实验1、3、10、11。3)结合表 3可以得出,在模型不同、参数不同和噪声不同的情况下,重启动快速ADMM算法的迭代次数都是3,说明重启动快速ADMM算法非常稳健。与原始ADMM算法相比,重启动快速ADMM算法的计算效率提高了66%~800%,最优结果为实验14。
表 4
EE模型消除椒盐噪声的运行结果
Table 4
Running results of EE model to eliminate salt and pepper noise
| 序号 | 图像 | 原始ADMM | 快速ADMM | 重启动快速ADMM | ||||||||||||
| 步数 | 时间/s | PSNR/dB | 步数 | 时间/s | PSNR/dB | 步数 | 时间/s | PSNR/dB | ||||||||
| 1 | Lena | 0.06 | 2 | 2 000 | 400 | 8 | 0.275 | 27.737 | 11 | 0.510 | 27.753 | 3 | 0.147 | 27.946 | ||
| 2 | Lena | 0.06 | 2 | 2 000 | 40 000 | 8 | 0.233 | 27.625 | 8 | 0.275 | 27.680 | 3 | 0.110 | 27.925 | ||
| 3 | Lena | 0.06 | 2 | 20 000 | 400 | 9 | 0.244 | 27.605 | 23 | 0.785 | 27.396 | 3 | 0.109 | 27.891 | ||
| 4 | Lena | 0.06 | 2 | 20 000 | 40 000 | 8 | 0.227 | 27.666 | 8 | 0.267 | 27.560 | 3 | 0.110 | 27.885 | ||
| 5 | Lena | 0.06 | 20 | 2 000 | 400 | 17 | 0.481 | 23.280 | 14 | 0.470 | 23.324 | 3 | 0.133 | 22.460 | ||
| 6 | Lena | 0.06 | 20 | 2 000 | 40 000 | 15 | 0.403 | 23.297 | 17 | 0.568 | 23.415 | 3 | 0.117 | 22.471 | ||
| 7 | Lena | 0.06 | 20 | 20 000 | 400 | 16 | 0.432 | 23.301 | 15 | 0.487 | 23.342 | 3 | 0.122 | 22.480 | ||
| 8 | Lena | 0.06 | 20 | 20 000 | 40 000 | 15 | 0.406 | 23.324 | 17 | 0.541 | 23.409 | 3 | 0.120 | 22.473 | ||
| 9 | Lena | 0.6 | 2 | 2 000 | 400 | 11 | 0.303 | 27.447 | 10 | 0.313 | 27.279 | 3 | 0.121 | 27.846 | ||
| 10 | Lena | 0.6 | 2 | 2 000 | 40 000 | 20 | 0.597 | 24.490 | 25 | 0.813 | 23.306 | 3 | 0.130 | 27.860 | ||
| 11 | Lena | 0.6 | 2 | 20 000 | 400 | 11 | 0.296 | 26.842 | 13 | 0.421 | 26.027 | 3 | 0.138 | 27.800 | ||
| 12 | Lena | 0.6 | 2 | 20000 | 40 000 | 20 | 0.530 | 24.280 | 19 | 0.579 | 23.228 | 3 | 0.139 | 27.764 | ||
| 13 | Lena | 0.6 | 20 | 2 000 | 400 | 18 | 0.478 | 23.324 | 11 | 0.346 | 23.324 | 3 | 0.128 | 22.472 | ||
| 14 | Lena | 0.6 | 20 | 2 000 | 40 000 | 36 | 0.953 | 22.528 | 27 | 0.825 | 22.057 | 3 | 0.348 | 22.453 | ||
| 15 | Lena | 0.6 | 20 | 20 000 | 400 | 6 | 0.164 | 23.863 | 5 | 0.163 | 23.902 | 3 | 0.138 | 22.481 | ||
| 16 | Lena | 0.6 | 20 | 20 000 | 40 000 | 44 | 1.162 | 22.560 | 24 | 0.748 | 22.062 | 3 | 0.118 | 22.467 | ||
| 注:加粗字体为快速算法迭代步数的最优结果。 | ||||||||||||||||
同样,为了可以更清楚地了解在计算过程中3种算法能量值和相对能量误差的变化趋势,以EE模型消除高斯白噪声为例,对3种算法在EE模型中迭代40次的能量值进行比较,结果如图 5所示。图 6表示使用相对能量误差作为停止准则时,3种算法在EE模型中的收敛曲线。参数取值均为
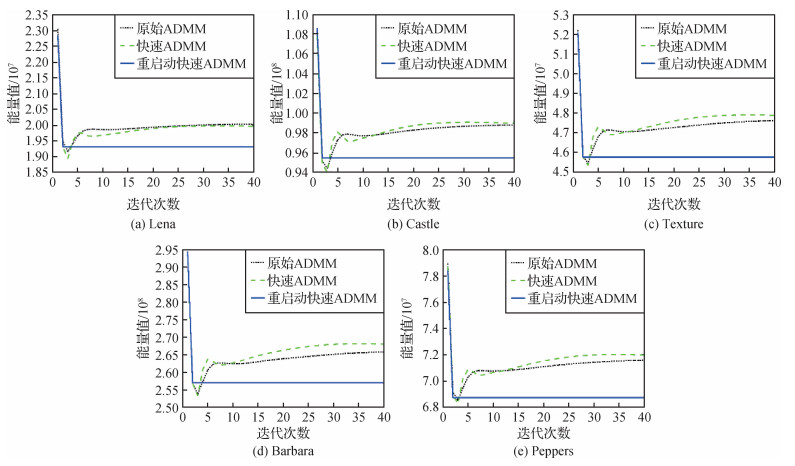
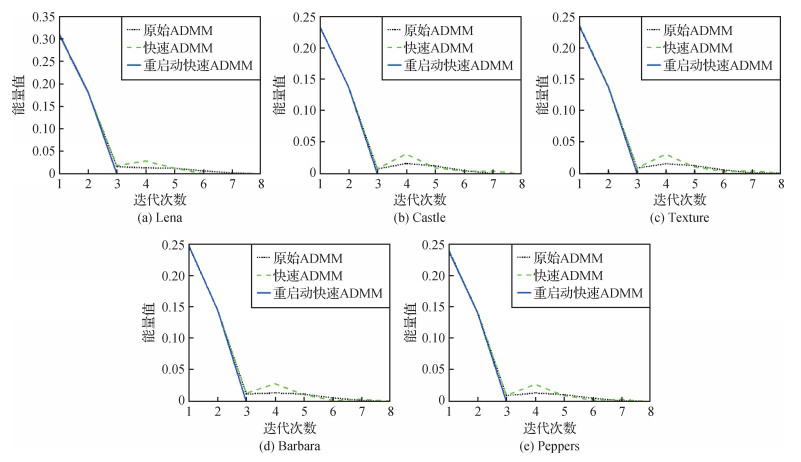
从图 5和图 6可以看出: 1)通过函数的能量值曲线,重启动快速ADMM的函数值相较于其他两种算法能够更快地接近稳定。2)快速ADMM算法在图 5的5幅图像中都出现了函数值不单调下降的情况,这种缺陷极大降低了算法效率。这是因为快速ADMM无法计算最优步长,加速步长过大,导致错过了极小值从而出现了函数值不单调下降情况,因此产生振荡。3)重启动快速ADMM算法的能量值和相对能量误差是单调下降的,且能量值达到稳定状态最快。
5 结论
本文以图像噪声去除为背景,针对含二阶导数规则项的非线性、非光滑的TL模型及非线性、非光滑、非凸的EE模型,以ADMM方法为基础,引入Neserov惯性加速及重启动策略设计了相应的快速算法及重启动快速算法。对不同的变量进行加速,重启动快速算法的计算效率较原始的ADMM方法和快速ADMM方法均有较大提高,为更明显地显示实验效果,本文选取加速效率较为明显的变量进行加速实验。重启动算法的计算效率对所选惩罚参数具有鲁棒性,其计算效率的提高还得益于优化子问题的快速FFT求解及解析形式的软阈值公式的使用。这些有益的探索可为其他形式高阶变分图像处理与分析模型的快速求解提供借鉴。
但是,含高阶导数的非线性、非光滑和非凸变分模型的ADMM方法及其重启动快速算法设计还缺乏足够的理论支撑。目前的理论研究还局限于由两个函数组合的目标函数的优化问题,且确定性的理论成果集中于光滑、强凸及含一个线性约束的优化问题。对于计算机视觉中的含高阶导数的非光滑、非凸变分模型的快速算法研究,本文的工作仅限于尝试性算法设计及数值验证,后续复杂的算法理论分析对算法的推广将具有重要价值。
参考文献
-
Aubert G, Kornprobst P. 2006. Mathematical Problems in Image Processing: Partial Differential Equations and the Calculus of Variations. 2nd ed. New York: Springer: 1-377
-
Beck A, Teboulle M. 2009a. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM Journal on Imaging Sciences, 2(1): 183-202 [DOI:10.1137/080716542]
-
Beck A, Teboulle M. 2009b. Fast gradient-based algorithms for constrained total variation image denoising and deblurring problems. IEEE Transactions on Image Processing, 18(11): 2419-2434 [DOI:10.1109/TIP.2009.2028250]
-
Beck A, Teboulle M. 2014. A fast dual proximal gradient algorithm for convex minimization and applications. Operations Research Letters, 42(1): 1-6 [DOI:10.1016/j.orl.2013.10.007]
-
Bredies K, Kunisch K, Pock T. 2010. Total generalized variation. SIAM Journal on Imaging Sciences, 3(3): 492-526 [DOI:10.1137/090769521]
-
Buccini A, Dell'Acqua P, Donatelli M. 2020. A general framework for ADMM acceleration. Numerical Algorithms, 85(3): 829-848 [DOI:10.1007/s11075-019-00839-y]
-
Calatroni L, Chambolle A. 2019. Backtracking strategies for accelerated descent methods with smooth composite objectives. SIAM Journal on Optimization, 29(3): 1772-1798 [DOI:10.1137/17M1149390]
-
Chambolle A. 2004. An algorithm for total variation minimization and applications. Journal of Mathematical Imaging and Vision, 20(1-2): 89-97 [DOI:10.1023/B:JMIV.0000011325.36760.1e]
-
Chambolle A, Pock T. 2011. A first-order primal-dual algorithm for convex problems with applications to imaging. Journal of Mathematical Imaging and Vision, 40(1): 120-145 [DOI:10.1007/s10851-010-0251-1]
-
Chan T F, Esedoglu S and Park F. 2010. A fourth order dual method for staircase reduction in texture extraction and image restoration problems//Proceedings of 2010 IEEE International Conference on Image Processing. Hong Kong, China: IEEE, 4137-4140[DOI: 10.1109/ICIP.2010.5653199]
-
Chan T F, Golub G H, Mulet P. 1999. A nonlinear primal-dual method for total variation-based image restoration. SIAM Journal on Scientific Computing, 20(6): 1964-1977 [DOI:10.1137/S1064827596299767]
-
Chan T F and Shen J. 2005. Image processing and analysis: variational, PDE, wavelet, and stochastic methods. Society for Industrial and Applied Mathematics: 1-400[DOI: 10.1137/1.9780898717877]
-
Chen S L. 2017. First-order forward backward algorithm for image restoration based on total variational model. Nanjing: Nanjing University of Posts and Telecommunications (陈少利. 2017. 全变分模型图像复原的一阶前向后向优化算法研究. 南京: 南京邮电大学)
-
Daubechies I, Defrise M, De Mol C. 2004. An iterative thresholding algorithm for linear inverse problems with a sparsity constraint. Communications on Pure and Applied Mathematics, 57(11): 1413-1457 [DOI:10.1002/cpa.20042]
-
Glowinski R and Le Tallec P. 1989. Augmented lagrangian and operator-splitting methods in nonlinear mechanics. Society for Industrial and Applied Mathematics: 1-295[DOI: 10.1137/1.9781611970838]
-
Glowinski R, Osher S J and Yin W T. 2016. Splitting Methods in Communication, Imaging, Science, and Engineering//Fitter Scientific Computation Cham, Switzerland: Springer: 1-17[DOI: 10.1007/978-3-319-41589-5-1]
-
Goldstein T, Osher S. 2009. The split bregman method for l1-regularized problems. SIAM Journal on Imaging Sciences, 2(2): 323-343 [DOI:10.1137/080725891]
-
Goldstein T, O'Donoghue B, Setzer S, Baraniuk R. 2014. Fast alternating direction optimization methods. SIAM Journal on Imaging Sciences, 7(3): 1588-1623 [DOI:10.1137/120896219]
-
Kang S H, Ta X C, Zhu W. 2019. Survey of fast algorithms for Euler's elastica-based image segmentation. Handbook of Numerical Analysis, 20: 533-552 [DOI:10.1016/bs.hna.2019.05.005]
-
Kim J, Fessler J A. 2018. Adaptive restart of the optimized gradient method for convex optimization. Journal of Optimization Theory and Applications, 178(1): 240-263 [DOI:10.1007/s10957-018-1287-4]
-
Kimmel R, Tai X C. 2019. Processing, analyzing and learning of images, shapes, and forms: part 2. Handbook of Numerical Analysis, 20: 1-684
-
Li Q P. 2018. Research on Fast Iterative Shrinage-Thresholding Algorithm for Non-Smooth Convex Optimization Problems. Xi'an: Xidian University (李启朋. 2018. 非光滑凸优化问题的快速迭代收缩阈值算法研究. 西安: 西安电子科技大学)
-
Li X, Deng K K, Li C. 2019. A fast proximal Barzilai-Borwein gradient method for solving decomposable strongly convex optimization problems. Journal of Wuyi University, 38(3): 12-16 (李星, 邓康康, 李超. 2019. 求解可分解强凸优化问题的FISTA-Barzilai-Borwein算法. 武夷学院学报, 38(3): 12-16) [DOI:10.14155/j.cnki.35-1293/g4.2019.03.003]
-
Liu C X, Kong D X, Zhu S F. 2012. A primal-dual hybrid gradient algorithm to solve the LLT model for image denoising. Numerical Mathematics: Theory, Methods and Applications, 5(2): 260-277 [DOI:10.1017/S1004897900000817]
-
Lysaker M, Lundervold A, Tai X C. 2003. Noise removal using fourth-order partial differential equation with applications to medical magnetic resonance images in space and time. IEEE Transactions on Image Processing, 12(12): 1579-1590 [DOI:10.1109/TIP.2003.819229]
-
Masnou S and Morel J M. 1998. Level lines based disocclusion//Proceedings of 1998 International Conference on Image Processing. Chicago, USA: IEEE: 259-263[DOI: 10.1109/ICIP.1998.999016]
-
Nesterov Y E. 1983. A method for solving the convex programming problem with convergence rate O(1/k2). Dokl Akad Nauk SSSR, 269(3): 543-547
-
Nitzberg M, Mumford D, Shiota T. 1993. Filtering, Segmentation and Depth. Berlin: Springer [DOI:10.1007/3-540-56484-5]
-
O'Donoghue B, Candès E. 2015. Adaptive restart for accelerated gradient schemes. Foundations of Computational Mathematics, 15(3): 715-732 [DOI:10.1007/s10208-013-9150-3]
-
Pan S L, Yan K, Li L Y, Jiang C Y, Shi L G. 2019. Sparse-spike deconvolution based on adaptive step FISTA algorithm. Oil Geophysics, 54(4): 737-743 (潘树林, 闫柯, 李凌云, 蒋从元, 石林光. 2019. 自适应步长FISTA算法稀疏脉冲反褶积. 石油地球物理勘探, 54(4): 737-743) [DOI:10.13810/j.cnki.issn.1000-7210.2019.04.002]
-
Paragios N, Chen Y M, Faugeras O. 2006. Handbook of Mathematical Models in Computer Vision. Boston, USA: Springer [DOI:10.1007/0-387-28831-7]
-
Rudin L I, Osher S, Fatemi E. 1992. Nonlinear total variation based noise removal algorithms. Physica D: Nonlinear Phenomena, 60(1/4): 259-268 [DOI:10.1016/0167-2789(92)90242-F]
-
Scherzer O. 2015. Handbook of Mathematical Methods in Imaging. 2nd ed. New York, USA: Springer [DOI:10.1007/978-1-4939-0790-8]
-
Tai X C, Hahn J, Chung G J. 2011. A fast algorithm for Euler's elastica model using augmented Lagrangian method. SIAM Journal on Imaging Sciences, 4(1): 313-344 [DOI:10.1137/100803730]
-
Vogel C R, Oman M E. 1996. Iterative methods for total variation denoising. Siam Journal on Scientific Computing, 17(1): 227-238 [DOI:10.1137/0917016]
-
Wu C L, Tai X C. 2010. Augmented lagrangian method, dual methods, and split bregman iteration for ROF, vectorial TV, and high order models. SIAM Journal on Imaging Sciences, 3(3): 300-339 [DOI:10.1137/090767558]
-
Yashtini M, Kang S H. 2016. A fast relaxed normal two split method and an effective weighted TV approach for Euler's elastica image inpainting. SIAM Journal on Imaging Sciences, 9(4): 1552-1581 [DOI:10.1137/16M1063757]
-
Zhu M and Chan T. 2008. An Efficient Primal-Dual Hybrid Gradient Algorithm for Total Variation Image Restoration. CAM Reports 08-34. UCLA, Center for Applied Math
-
Zhu W, Tai X C, Chan T. 2013. Image segmentation using Euler's elastica as the regularization. Journal of Scientific Computing, 57(2): 414-438 [DOI:10.1007/s10915-013-9710-3]
-
Zhu W, Tai X C and Chan T. 2014. A Fast algorithm for a mean curvature based image denoising model using augmented lagrangian method//Bruhn A, Pock T and Tai X C, eds. Efficient Algorithms for Global Optimization Methods in Computer Vision. Berlin, Germany: Springer, 104-118[DOI: 10.1007/978-3-642-54774-4_5]


