|
|
|
发布时间: 2022-04-16 |
综述 |
|
|
|


|
收稿日期: 2020-08-26; 修回日期: 2020-12-15; 预印本日期: 2020-12-22
基金项目: 国家自然科学基金项目(62171324);湖北省重大科技创新计划项目(2020BAB018)
作者简介:
曹申豪,1997年生,男,硕士研究生,主要研究方向为计算机视觉和深度学习。E-mail: caoshenhao@whu.edu.cn
刘晓辉,男,高级工程师,主要研究方向为计算机网络、网络安全和数据分析。E-mail: tjulxh@126.com 毛秀青,男,副教授,主要研究方向为计算机视觉和人工智能安全。E-mail: mxq_zf@163.com 邹勤,通信作者,男,副教授,主要研究方向为计算机视觉、模式识别和机器学习。E-mail: qzou@whu.edu.cn *通信作者: 邹勤 qzou@whu.edu.cn
中图法分类号: TP301.6
文献标识码: A
文章编号: 1006-8961(2022)04-1023-16
|
摘要
人脸伪造技术的恶意使用,不仅损害公民的肖像权和名誉权,而且会危害国家政治和经济安全。因此,针对伪造人脸图像和视频的检测技术研究具有重要的现实意义和实践价值。本文在总结人脸伪造和伪造人脸检测的关键技术与研究进展的基础上,分析现有伪造和检测技术的局限。在人脸伪造方面,主要包括利用生成对抗技术的全新人脸生成技术和基于现有人脸的人脸编辑技术,介绍生成对抗网络在人脸图像生成的发展进程,重点介绍人脸编辑技术中的人脸交换技术和人脸重现技术,从网络结构、通用性和生成效果真实性等角度对现有的研究进展进行深入阐述。在伪造人脸检测方面,根据媒体载体的差异,分为伪造人脸图像检测和伪造人脸视频检测,首先介绍利用统计分布差异、拼接残留痕迹和局部瑕疵等特征的伪造人脸图像检测技术,然后根据提取伪造特征的差异,将伪造人脸视频检测技术分为基于帧间信息、帧内信息和生理信号的伪造视频检测技术,并从特征提取方式、网络结构设计特点和使用场景类型等方面进行详细阐述。最后,分析了当前人脸伪造技术和伪造人脸检测技术的不足,提出可行的改进意见,并对未来发展方向进行展望。
关键词
人脸伪造; 伪造人脸检测; 生成对抗网络(GAN); 人脸交换; 人脸重现
Abstract
Face image synthesis is one of the most important sub-topics in image synthesis. Deep learning methods like the generative adversarial networks and autoencoder networks enable the current generation technology to generate facial images that are indistinguishable by human eyes. The illegal use of face forgery technology has damaged citizens' portrait rights and reputation rights and weakens the national political and economic security. Based on summarizing the key technologies and critical review of face forgery and forged-face detection, our research analyzes the limitations of current forgery and detection technologies, which is intended to provide a reference for subsequent research on fake-face detection. Our analysis is shown as bellows: 1) the technologies for face forgery are mainly divided into the use of generative confrontation technology to generate a category of new faces and the use of existing face editing techniques. First, our review introduces the development of generative adversarial network and its application in human face image generation, shows the face images generated at different development stages, and targets that generative adversarial network provides the possibility of generating fake face images with high resolution, real look and feel, diversified styles and fine details; furthermore, it introduces face editing technology like face swap, face reenactment and the open-source implementation of the current face swap and face reenactment technology on the aspects of network structure, versatility and authenticity of the generated image. In particular, face exchange and face reconstruction technologies both decompose the face into two spaces of appearance and attributes, design different network structures and loss functions to transfer targeted features, and use an integrated generation adversarial network to improve the reality of the generated results. 2) The technologies for fake face detection, according to the difference of media carriers, can be divided into fake face image detection and fake face video detection. Our review first details the use of statistical distribution differences, splicing residual traces, local defects and other features to identify fake facial image generated from straightforward generative adversarial network and face editing technologies. Next, in terms of the difference analysis of extracting forged features, the fake facial video detection technology is classified into technology based on inter-frame information, intra-frame information and physiological signals. The methodology of extracting features, the design of network structures and the use scenarios were illustrated in detail. The current fake image detection technology mainly uses convolutional neural networks to extract fake features, and realizes the location and detection of fake regions simultaneously, while fake video detection technologies mainly use a integration of convolutional neural networks and recurrent neural networks to extract the same features inter and inner frames; after that, the public data sets of fake-face detection are sorted out, and the comparison results of multiple fake-face detection methods are illustrated for multiple public data sets. 3) The summary and the prospect part analyze the weaknesses of the current face forgery technologies and forged-face detection technologies, and gives feasible directions for improvement. The current face video forgery technology mainly uses the method of partially modifying the face area with the following defects. There are forgery traces in a single video frame, such as blurred side faces and missing texture details in the face parts. The relevance of video frames was not considered and there were inconsistencies amongst the generated video frames, such as frame jumps, and the large difference in the position of key points of the two frames before and after; and the generated face video lacks normal biological information, such as blinks and micro expressions. The current forgery-detection technologies have poor robustness to real scenes and poor robustness against image and video compression algorithms. The detection methods trained on high-resolution datasets are not suitable for low-resolution images and videos. Forgery detection technologies are difficult to review the issue of continuous upgrade and evolution of forged technology. The further improvement is illustrated on forgery-detection technologies. For instance, when generating videos, it would be useful to add the location information of the face into the network to improve the coherence of the generated video. In related to forgery detection, the forgery features in the space and frequency domains can be fused together for feature extraction, and the 3D convolution and metric learning can be used to form a targeted feature distribution for forged faces and the genuine faces. The development of face forgery is featured by few-shot learning, strong versatility and high fidelity. Forgery-face detection technology is intended to high versatility, strong compression resistance, few-shot learning and efficient computing.
Key words
face forgery; face forgery detection; generative adversarial network (GAN); face swap; face reenactment
0 引言
人脸图像生成一直是图像生成领域的热点。深度学习的快速发展,尤其是生成对抗网络(generative adversarial network,GAN)和自编码器使得现有生成技术能够生成极为逼真、肉眼难以鉴别的人脸图像。StyleGAN和ProGAN(progressive growing GAN)等生成对抗网络可根据输入的随机向量直接生成一幅高质量人脸图像。人脸检测、人脸分割等技术与生成对抗网络技术结合,可实现只修改人脸图像中的特定区域,加快了人脸交换、人脸重现等人脸编辑技术的发展。
根据生成方式的不同,人脸伪造技术可以分为生成对抗网络(GAN)生成人脸技术和人脸编辑技术。二者的区别在于GAN根据输入的随机向量生成一张世界上不存在的人脸,人脸编辑技术如人脸交换和人脸重现技术是在已存在的人脸上进行修改。对于给定的两幅人脸图像:原始人脸图像和目标人脸图像,人脸交换技术指对目标人脸图像进行修改,使修改后的人脸区域既有原始人脸的长相,又有目标人脸的属性(如表情、肤色和光照等),典型技术如DeepFake、Zao等开源软件的方法。人脸重现技术与人脸交换技术类似,其对目标人脸图像进行修改,使修改后的人脸保留目标人脸的长相和原始人脸的表情与姿态,典型技术包括face2face等。
人脸伪造技术有利有弊。人脸伪造技术可应用于影视作品制作中,增加趣味性和观赏性。另一方面,人脸伪造技术在未经当事人允许的情况下可能存在滥用,对个人的肖像权和名誉权甚至个人的形象造成极大损害。因此,伪造人脸检测技术尤为重要。根据传播载体的不同,伪造人脸检测包括鉴别伪造人脸图像和鉴别伪造人脸视频。
为维护互联网安全,保护互联网用户的隐私权,许多科技公司和研究机构参与到伪造人脸检测技术中。谷歌、Facebook和商汤等科技公司聘请影视演员和发动互联网用户提供人脸视频,斥巨资制作伪造人脸数据集。Facebook举办DeepFake Detection竞赛,促进了伪造人脸检测技术的发展。一些针对伪造人脸检测的高水平论文也陆续发表于IEEE国际计算机视觉大会(International Conference on Computer Vision,ICCV)和IEEE计算机视觉模式识别会议(IEEE Conference on Computer Vision and Pattern Recognition,CVPR)等计算机视觉学术会议。
根据媒体载体的差异,已有的伪造人脸检测技术可分为伪造人脸图像检测技术和伪造人脸视频检测技术。伪造人脸图像检测技术主要以真实图像与生成图像统计分布的差异、图像拼接引入的伪造痕迹以及生成图像的真实性作为判别依据。由于视频在生成和传播过程中可能经过压缩,造成一定程度的伪造信息丢失,已有的伪造人脸图像检测技术并不能完全适用于压缩伪造视频的检测。现有的伪造视频检测方法主要以视频帧内的伪造信息、视频帧间的不一致性和生理信号跳跃性作为判别依据。
1 人脸伪造技术
人脸伪造技术以人脸图像生成技术为核心。由于视频可视为图像的集合,人脸图像伪造技术也可用于人脸视频伪造。人脸伪造技术主要分为生成对抗网络直接生成伪造人脸技术和人脸编辑技术。其中,人脸编辑技术又包括人脸交换、人脸重现和人脸老化等技术,由于人脸交换技术和人脸重现技术对网络环境安全的危害程度最大,本文主要探讨这两种方法。
1.1 人脸生成
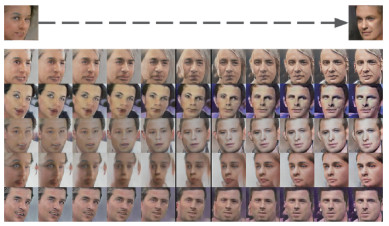
深度学习模型可以分为判别模型和生成模型。随着BP(back propagation)算法的提出,判别模型取得快速发展,而生成模型发展相对缓慢。生成对抗网络(GAN)(Goodfellow等,2014)的提出,为生成模型注入了活力。曹仰杰等人(2018)对GAN及其在计算机视觉领域的应用进行了详细介绍。受博弈问题的启发,GAN将生成模型的生成过程建模为生成器和判别器两个网络的博弈过程。生成器依据给定的均匀分布或正态分布的随机向量生成数据,判别器区分出生成数据和真实数据。生成器和判别器的权重交替更新,两个网络在对抗过程中进步,生成器生成的数据越来越接近真实数据。原始的GAN只能生成分辨率较低的图像,图像效果相对真实效果较差。图 1展示了GAN根据Toronto Faces Dataset数据集的生成结果,最右侧为真实数据。


深度卷积神经网络比多层感知机(multilayer perceptron,MLP)有更强的拟合与表达能力,并在判别式模型中取得了很大进展。Radford等人(2015)将卷积神经网络(convolutional neural network,CNN)引入生成器和判别器,称作深度卷积对抗神经网络(deep convolutional GAN,DCGAN)。DCGAN是在GAN的基础上提出的一种网络架构,几乎完全用卷积层取代了全连接层,去掉池化层,采用批标准化(batch normalization, BN)(Ioffe和Szegedy,2015),将判别模型的发展成果应用到了生成模型中。图 2为DCGAN生成的人脸图像,生成效果相对GAN有了很大提升,但视觉效果仍然较差。
生成对抗网络直接生成高分辨图像会出现模型崩塌现象,生成器直接生成“鬼脸”骗过判别器,导致生成图像效果很差。Karras等人(2018)提出ProGAN用于生成高分辨率图像,先训练一个小分辨率图像生成网络,然后逐步增大网络模型,生成更高分辨率的图像。具体而言,生成器最初生成4×4像素图像,然后生成8×8像素图像,以此类推,最终生成1 024×1 024像素图像。图 3展示了生成的1 024×1 024像素的人脸图像。

ProGAN由粗到细逐层生成图像,能够生成极为真实的人脸图像,但是ProGAN无法通过改变输入的随机向量来改变输出图像的特定特征。StyleGAN(Karras等,2019)通过对输入向量进行解耦合,并使用AdaIn(adaptive instance normalization)模块(Huang和Belongie,2017),使生成器能够生成指定特征(如发色、肤色等)的人脸图像。图 4展示了StyleGAN生成的人脸图像。

1.2 人脸交换
假设原始人脸为Xs,目标人脸为Xt,人脸交换即生成一幅保留Xt人脸属性(如表情、光照和角度等),同时具有Xs长相的图像。Deepfake是一项以深度学习为基础的开源人脸交换典型技术,使用者不需要具有专业的剪辑技能,只需要收集足够多的原始人物和目标人物的人脸图像,就能生成真实的换脸图像。除了Deepfake等开源技术,学术界也对人脸交换技术展开了深入研究。
1.2.1 Deepfake技术原理
Deepfake是应用广泛的人脸交换技术,可用于生成换脸图像和视频。Deepfake技术以自编码器(Baldi,2011)为基础。自编码器对输入进行编码,对编码进行解码得到输出,使输入等于输出的网络结构,本质上是一种数据压缩算法。自编码器分为编码器和解码器两部分,编码器将输入转换为隐层空间的表征,解码器对表征进行重建,使输出与输入相等。Deepfake整个网络结构包括一个编码器和两个解码器,如图 5所示。编码器用于将输入人脸的属性进行编码,得到Latent隐层空间向量,解码器将隐层空间编码还原为人脸图像。两个解码器Decoder A和Decoder B分别用于对两个人脸编码进行解码,即Decoder A只能将属性编码还原成人脸Face A的长相。Face A人脸通过编码器得到隐层向量Latent Face A,Latent Face A经过Decoder A得到重建人脸Face A,Latent Face A经过Decoder B可得到具有Face A属性和Face B长相的图像。
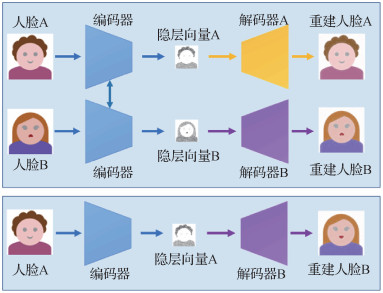
表 1整理了已有的开源Deepfake技术实现,它们原理相似,都采用上述编解—码器结构,但在编程框架等实现方式上存在差异。
表 1
Deepfake开源代码整合
Table 1
Open-source codes for Deepfake
| 项目 | 代码网址 |
| Faceswap | https://github.com/deepfakes/faceswap |
| Faceswap-GAN | https://github.com/shaoanlu/faceswap-GAN |
| DFaker | https://github.com/dfaker/df |
| Deepfacelab | https://github.com/iperov/DeepFaceLab |
1.2.2 人脸交换研究进展
Deepfake技术虽然能够生成真实的换脸图像,但是需要先收集大量用于交换的两个人的人脸图像,且Deepfake只适用于特定的两个人的人脸图像交换,如果需要交换另两个人的人脸,需要重新收集这两个人的人脸图像,并重新训练。由此可见,Deepfake框架通用性较差。人脸交换领域的学者旨在发明一种通用所有人的、仅需少量样本的人脸交换框架。
Suwajanakorn等人(2015)使用3D建模的方法进行人脸交换,在有数百幅原始人脸和目标人脸图像的情况下取得了出色效果,但不适用于仅有单幅人脸图像的情况。Korshunova等人(2017)使用风格迁移(Johnson等,2016)进行人脸交换,将原始图像的表情、姿态和光线等视为内容,将目标图像的长相视为风格,将换脸过程视为风格迁移过程,实现了在仅一幅原始图像和数十幅目标图像上的人脸交换框架。RSGAN(region separative generative adversarial network)(Natsume等,2018a)同时使用变分自编码器(variational autoencoder,VAE)(Kingma和Welling,2014)和GAN,提出一种可同时用于头发编辑的人脸交换方法。此方法包括两个VAE和一个GAN,首先对人脸中的人脸区域和头发区域进行分割,两个VAE分别将人脸区域和头发区域用隐层向量表征,GAN用隐层表征重建人脸图像,实现了单幅源人脸图像和单幅目标人脸图像的人脸交换。考虑到RSGAN生成的换脸图像头发与原始人脸头发不同,FSGAN(face swapping GAN)(Natsume等,2018b)对RSGAN进行了改进,使生成的换脸图像真实性更高。与RSGAN相似,FSGAN由两个VAE和一个GAN组成,两个VAE分别将人脸区域和非人脸区域(包括头发和背景)编码,GAN用于重建人脸图像。
上述换脸方法存在两个问题:1)生成图像的人脸形状与原始人脸的形状相同,由于要求生成图像人脸长相与目标图像相同,生成图像人脸形状与目标任务相同时真实性更高;2)当原始图像中人物面部带有遮挡物时,如眼镜、头饰等物体,生成图像不包含遮挡物。为解决上述问题,Li等人(2020a)提出了两阶段的换脸框架FaceShifter,第1阶段网络用于生成高保真的换脸图像;第2阶段网络在第1阶段网络基础上为换脸图像增加面部遮挡物。为了保证生成图像的人脸形状与目标图像的人脸形状相同,FaceShifter没有使用人脸检测和人脸分割技术对原始图像人脸区域进行换脸,而是使用类似U-Net(Ronneberger等,2015)的结构直接输出一幅具有目标图像人脸形状的图像。此外,FaceShifter使用自适应注意力反规范化(adaptive attentional denormalization,ADD)对原始图像的人脸长相特征和目标图像的属性特征进行整合,并在整合过程中使用注意力机制动态分配人脸长相特征和属性特征的权重。
1.3 人脸重现
假设原始人脸为Xs,目标人脸为Xt,人脸重现即生成一幅同时具有Xt长相和Xs属性(表情、姿势等)的人脸。根据生成方法的差异,已有的人脸重现方法可以分为基于建模的方法和基于网络前馈的方法两类。
1.3.1 基于建模的方法
基于建模的方法主要分为3个步骤。1)对于采集的RGB或RGB-D原始人脸和目标人脸数据,使用人脸追踪或光流的方法对人脸进行建模;2)用原始人脸模型的参数替换目标人脸模型的相应参数;3)利用新的人脸模型生成图像或视频。
Thies等人(2015, 2016)提出两种方法,适用于RGB-D视频但仅能应用于表情迁移的实时人脸重现框架以及适用于RGB视频的实时人脸重现框架Face2face。两种方法类似,首先分别对视频中的原始人脸和目标人脸进行建模,得到身份、光照、角度和表情等参数,然后用原始人脸的表情参数替换目标人脸的表情参数,保留目标人脸的身份、光照和角度等参数,最后使用优化的方法并根据新的人脸参数合成换表情后的人脸。两种方法都只对人脸区域进行修改,非人脸区域保持不变。Kim等人(2018)提出可同时迁移表情、角度和眼神的视频人脸重现框架,使用单目人脸重建技术获取人脸的光照、身份、角度、表情和眼神等参数,然后替换目标人脸参数的角度、表情和眼神参数,并根据新参数重建人脸模型。区别于上述两种方法使用优化的方法生成人脸区域图像,此方法将重建的人脸模型作为条件,使用cGAN(conditional GAN)(Isola等,2017)和自编码器结构生成包括人脸区域和非人脸区域的整幅图像。
1.3.2 基于前馈网络的方法
基于建模的方式难以捕捉细微的表情变化,且过程烦琐、复杂度高。随着深度学习的发展,基于前馈网络的方法使用生成对抗网络和自编码器提升人脸重现的效果。基于前馈网络的方法与基于建模的方法整体过程相似,区别在于前者使用神经网络获取人脸参数和生成人脸。
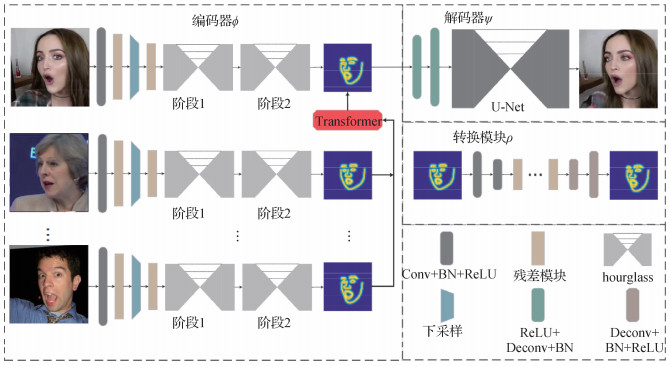
基于前馈的神经网络面临以下问题:1)视频或图像仅包含有限多个人脸表情、光照和角度等状态,因此,在有限训练样本情况下直接训练一个适用于复杂场景的人脸到人脸转换的前馈转换网络是困难的;2)缺少成对的原始人脸和目标人脸用做监督训练。为解决以上问题,基于前馈网络的人脸重现框架借用了Pix2pix(Isola等,2017)和CycleGAN(Zhu等,2017)等结构,在缺少成对样本的情况下使用自监督的方式进行训练。ReenactGAN(Wu等,2018)使用人脸边界轮廓设计了一个多对一的前馈网络结构,如图 6所示,整个网络结构分为3部分:第1部分为编码器,实现提取人脸边界轮廓;第2部分为转换模块,实现原始人脸到目标人脸的边界轮廓转换;第3部分为解码器,根据转换后的边界轮廓生成具有目标人脸长相的人脸图像。
基于建模和基于前馈网络的方法都需要多幅的原始和目标人脸图像,且只能生成特定的目标人脸。Zhang等人(2019)提出单幅图像的换表情方法,仅用一幅原始图像和目标图像实现多对多的人脸重现,生成结果可以媲美使用多幅图像的ReenactGAN,并能生成更真实的胡子和头发。此方法将人脸图像分解到长相和形状两个空间,使用人脸解析网络生成人脸解析特征图并用于指导生成过程,使用自编码器对图像进行重建。然后将长相特征、人脸解析特征图进行特征融合,再与生成网络的中间层特征融合,得到换表情后的图像。
人脸老化等人脸编辑技术也取得了快速发展,宋昊泽和吴小俊(2019)使用条件对抗自编码器,可将每幅人脸图像分别生成10幅不同年龄且细节逼真的图像。
1.4 人脸视频伪造
人脸视频伪造技术主要通过局部修改人脸区域的人脸图像伪造技术实现。视频是视频帧的集合,对于视频的伪造,通常先将视频解码成多个视频帧,然后应用伪造人脸图像技术对单个帧进行修改,最后将修改后的视频帧合成视频。由于生成人脸区域和非人脸区域的整幅图像技术在生成的背景区域存在模糊,且通常仅在人脸区域所占大小相对固定的数据集上训练,不适合人脸区域大小变化明显的视频场景,因而现有的人脸视频伪造技术都是通过局部修改人脸区域的方法实现。
将语音风格迁移技术应用于人脸视频伪造技术,可提高伪造视频的真实性。伪造的人脸视频中通常含有讲话的场景,如果伪造视频中的语音音色与讲话人的不一致,则视觉和听觉感官上存在不一致。例如,在将视频中人物A换脸成人物B时,同时也希望视频中的语音具有人物B的音色。语音风格迁移是将一个人的语音音色迁移到另一个人的音色,同时语音的语义保持不变。Hu等人(2019)和Fang等人(2018)分别使用具有编解码结构的CycleGAN和StarGAN实现了语音风格迁移。
2 伪造人脸检测技术
伪造人脸以图像和视频为载体传播。根据媒体载体的差异,伪造人脸检测技术可分为对伪造人脸图像的检测技术和对伪造人脸视频的检测技术。伪造图像的检测技术主要基于伪造过程残留的痕迹或伪造图像与真实图像统计分布的差异。由于视频在生成和传播过程中经过压缩,导致丢失单个视频帧中的伪造痕迹,因而对图像的检测方法难以直接应用于伪造视频的检测。针对视频具有连续性和时序性的特点,伪造视频的检测技术主要依据多个相邻的连续视频帧的关联性。
2.1 伪造人脸图像检测
伪造人脸图像技术包括GAN直接生成人脸和人脸编辑技术。前者直接生成一幅原本不存在的人脸图像,后者在已有的人脸图像上进行修改,生成人脸区域图像或包括背景在内的整幅图像。因而,伪造人脸图像检测技术可分为对生成对抗网络直接生成图像的检测和对人脸编辑技术(如换脸、换表情)的检测。
2.1.1 针对GAN生成的人脸图像的检测技术
ProGAN和StarGAN能够生成视觉效果极为逼真的人脸图像,难以肉眼区分真伪。当前的检测方法普遍将检测问题视为二分类问题,基于统计特征或神经网络学习的特征进行鉴别。
McCloskey和Albright(2018)提出GAN生成图像的颜色图像与真实图像在颜色分布上存在差异,通过构建颜色特征并使用支持向量机进行分类。Liu等人(2020)提出生成的图像和真实图像存在纹理差异,并使用Gram矩阵(Gatys等,2015)表示纹理。Xuan等人(2019)提出对图像进行高斯混合和高斯噪声预处理,能提高神经网络的表征能力和泛化能力。FakeSpotter(Wang等,2020)通过监控神经元的激活值以筛选有效特征,先将人脸图像输入到一个人脸识别网络,并求每层激活的平均值,然后将大于均值的激活值作为另一个全连接神经网络的输入,最后用支持向量机分类。
2.1.2 针对人脸交换和人脸重现图像的检测方法
人脸交换和人脸重建技术分为生成包括人脸及背景的方法和仅替换图像中人脸区域的方法两类。对于生成整幅图像的检测,可以借用上述针对GAN生成图像的检测方法。
局部修改的人脸图像的伪造方法存在以下问题:1)在生成过程中往往需要将生成的人脸图像缝合到目标图像上,并在人脸边缘区域进行高斯模糊,使人脸轮廓区域与其他区域存在差异;2)由于生成网络模型只能生成特定分辨率的图像,需将生成的人脸图像经插值放缩到与目标人脸大小一致,使人脸区域与非人脸区域的分辨率不一致;3)在少样本的情况下,生成的人脸图像可能会存在五官变形、细节模糊等问题;4)生成网络生成的图像与真实图像存在统计分布差异。
已有的方法主要针对以上问题进行检测。孙鹏等人(2017)提出一种基于偏色估计的拼接篡改伪造图像检测方法,能够自动检测拼接篡改图像中的色彩偏移量不一致并定位拼接篡改区域。李杭和郑江滨(2017)提出基于噪声方差估计的检测方法,实现对伪造图像的盲检测。Rössler等人(2019)直接使用Xception网络结构在大规模伪造人脸数据集上训练一个二分类网络,证明了仅使用人脸区域图像参与训练效果优于使用整幅图像。同时,伪造图像和视频的压缩程度越高,分类器的检测正确率越低。Li和Lyu(2019)通过生成图像与真实图像在分布上的差异检测真伪,为增强模型的泛化能力,降低制造伪造数据集的消耗,直接将两幅图像的人脸区域进行拼接用于训练,使用图像分割的方法直接输出修改区域的轮廓。Dang等人(2020)引入注意力机制(Choe和Shim,2019)促使模型关注更有意义的信息,并在伪造数据集上进行训练,同时输出分类结果和修改区域的热度图。此方法也适用于对GAN直接生成的人脸图像的检测。FakeLocator(Huang等,2020)使用语义分割方法,采用编解码器的结构对篡改区域进行定位,输出修改区域的热力图。此方法也同时适用于GAN生成的整幅图像和局部修改图像的检测。
俞能海和张卫明团队通过数据增强解决训练集与测试集不匹配问题,提高检测模型在不匹配的数据集之间的迁移能力,并基于Efficient-Net B3网络结构,采用适用于人脸伪造检测的注意力机制,使网络聚焦于篡改痕迹而非其他干扰因素,在Facebook主办的Deepfake检测挑战赛中取得了第2名的优异成绩。商汤团队(Qian等,2020)提出一种局部频域特征网络提取频率域的伪造特征,并使用注意力机制融合时间域信息和频率域信息,该方法对于压缩伪造图像具有鲁棒性。
总体来说,现有的伪造人脸图像检测方法大都使用神经网络提取特征,并进行二分类。此外,针对伪造人脸图像检测方法关注以下研究内容:1)模型能够同时检测GAN生成的整幅图像和局部修改的图像;2)模型能够准确定位修改的区域;3)模型具有较强的泛化能力,即能对训练集未出现的伪造类型和真实场景中的伪造类型进行检测。
2.2 伪造人脸视频检测
由于GAN生成整幅图像的方式容易造成背景扭曲等问题,且无法考虑视频帧间的关联性,因而难以用于生成伪造人脸视频。现有伪造人脸视频技术大多是基于局部修改人脸区域的方法,存在以下缺陷:1)与伪造人脸图像技术相同,单个视频帧内存在伪造痕迹;2)在视频生成过程中,没有考虑视频帧的关联性,生成的视频帧间存在不一致性,如帧跳跃、前后两帧生成细节存在差异;3)生成的人脸视频缺乏正常的生物信息,如眨眼、微表情等。
由于图像在合成视频和视频在传输过程中经过压缩处理,存在一定程度的伪造信息丢失,伪造图像检测方法难以直接应用于伪造视频检测。区别于多幅图像,视频的多个帧间具有时序特征,这是图像检测方法无法捕捉到的。针对上述伪造视频存在的问题,伪造视频检测方法主要分为3类:1)基于帧内检测的方法;2)基于帧间检测的方法;3)基于生理信号的检测方法。
2.2.1 帧内检测方法
基于帧内检测的方法主要针对单个视频帧的伪造信息进行检测,如人脸区域与背景分辨率的差异、生成人脸细节、篡改图像与真实图像存在分布上的差异。已有的方法大都使用卷积神经网络(CNN)提取伪造信息特征,并用全连接网络进行分类。
由于Deepfake生成算法只能生成特定分辨率的图像并放缩到合适大小,拼接到原始视频帧中。Li等人(2018)使用CNN捕捉这种拼接引入的差异进而区分Deepfake视频。相对于以前需要大量伪造的数据集,此方法不需要Deepfake生成的图像作为负样本进行训练,而是采用图像拼接的方法,直接交换两幅图像的人脸区域得到负样本,既避免了生成大量Deepfake视频的算力消耗,又增加了算法的鲁棒性。该方法定义正负样本中人脸的图像为兴趣区,只将兴趣区送入到CNN,训练了VGG16(Visual Geometry Group 16-layer network)(Simonyan和Zisserman,2015)、ResNet50(residual neural network)、ResNet101和ResNet152(He等,2016)4个模型,取平均值作为最终的预测结果。Matern等人(2019)指出生成的人脸在视觉上与真实人脸存在差异,首先得到人脸图像的关键点,通过眼睛和嘴部位关键点的凸包得到眼睛区域和牙齿区域,然后使用纹理表征方法得到眼睛、牙齿区域和整幅图像的特征向量,最后用逻辑斯蒂回归和全连接神经网络进行分类。Nguyen等人(2019a)提出多任务的训练方式,同时检测伪造图像和定位修改的区域,并使用半监督的方法增强网络的泛化能力,整个网络包括1个编码器和2个Y型的解码器,如图 7所示,编码器为卷积神经网络,为分割和分类任务提取特征;解码器分为两个分支,一个分支进行分割输出修改区域的分割图,另一个分支用于分类输出判定的真假。相似地,胡永健等人(2021)提出基于图像分割网络的深度假脸视频篡改检测方法。Afchar等人(2018)利用卷积神经网络捕捉帧内信息检测伪造视频,提出两个卷积神经网络Meso-4和MesoInception-4,Meso-4为小规模网络,包括4个卷积层和两个全连接层,MesoInception-4为大规模网络,借鉴Inception模块,将单个视频帧作为输入,将伪造检测作为二分类处理。Yang等人(2019)使用头部的3D姿态估计进行Deepfake伪造视频的检测,发现Deepfake不能保证输入人脸与输出人脸的关键点完全匹配,对于64 × 64像素大小的人脸图像,平均每个关键点存在1.54个像素的差异。在换脸过程中,只交换面部中心区域,保留面部轮廓,因而原始图像与生成图像的所有面部中心区域关键点和面部轮廓的关键点分布存在差异,可以通过3D头部姿态估计进行建模。因此,首先使用Openface2开源软件进行面部姿态估计,得到位移矢量和旋转矢量。然后对位移矢量和旋转矢量作变换,得到特征向量,并用支持向量机分类。
2.2.2 帧间检测方法
伪造的人脸视频存在帧间不一致性,原因在于已有的伪造视频方法将视频分解为单视频帧分别进行处理,很少考虑视频帧前后的关联性。例如,许多人脸伪造技术都使用人脸关键点检测技术用于定位人脸的位置,但人脸关键点检测技术本身存在几个像素的误差,如果没有将误差考虑在内,生成的相邻视频帧的人脸位置就会存在明显的视觉差异。已有的伪造视频检测方法使用长短时记忆网络(long short term memory,LSTM)(Hochreiter和Schmidhuber,1997)或光流估计对视频帧间的关联性进行建模。
考虑到生成的伪造视频缺乏时间相关性,Sabir等人(2019)利用视频的时序信息检测伪造视频,结合DenseNet和门递归单元的递归卷积模型(recurrent convolutional network,RCN)挖掘帧间的不一致性,如图 8所示,该方法分为两个阶段,第1阶段检测视频帧的人脸区域,然后对人脸区域进行裁剪、对齐;第2阶段将多帧的人脸区域送入RCN中训练学习。相似的,Güera和Delp(2018)结合CNN和LSTM检测Deepfake视频,首先使用InceptionV3提取单帧的特征,然后用LSTM捕捉时序特征,如图 9所示。


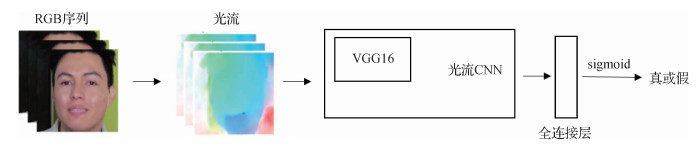
Amerini等人(2019)使用光流估计的方法检测伪造视频。光流指光的流动,比如人眼感受到的夜空中划过的流星。在计算机视觉中,用光流定义图像中对象的移动,这个移动可以是相机移动或者物体移动引起的。具体是指视频图像的一帧中代表同一对象(物体)像素点移动到下一帧的移动量,使用2维向量表示。区别于直接将视频帧作为网络的输入,如图 10所示,此方法首先根据相邻的两个帧计算出光流图,然后将光流图作为输入送入VGG16网络。Masi等人(2020)提出结合频率域和RGB域的两分支递归网络用于伪造视频检测。具体地,一个分支使用高斯拉普拉斯滤波器提取频率域特征,另一个分支使用卷积神经网络提取RGB域特征,使用组卷积将频率域和RGB域的特征整合,并输入到LSTM中。区别于先前方法使用交叉熵作为分类的损失函数,该方法使用欧氏距离作为损失函数和测试阶段分类的指标。在训练过程中,预先给定一个常向量,并训练网络缩小真实视频编码与常向量的欧氏距离,同时增大伪造视频编码与常向量的欧氏距离。在测试阶段,如果一个视频的编码与常向量的欧氏距离大于给定的阈值,则将此视频判别为假视频。Li等人(2020c)提出一个部分人脸伪造问题,即视频同一帧内包含多个不同人物,其中只有一个特定人物的人脸区域被伪造。在此情况下,以往基于投票策略的检测方法正确率急剧下降。Amerini等人(2019)针对此场景提出了基于多实例学习的检测方法,将单个视频帧的每个人脸都视为一个实例,并将人脸序列编码成一个时序特征包,利用多实例学习方法对不同包实例的特征进行集成,实现了对部分人脸伪造视频的准确检测。张怡暄等人(2020)提出基于局部二值模式、方向梯度直方图特征和孪生神经网络提取帧间差异特征的人脸篡改视频检测框架。
2.2.3 基于生理信号的检测方法
在生成伪造视频过程中,往往缺少对生理信号的监督,导致生成的伪造人脸视频缺乏正常的生理信息。
Li等人(2018)提出基于眨眼检测的方法鉴别伪造视频,针对人眼眨眼具有很强的时间依赖性,采用长期递归卷积网络(long-term recurrent convolutional neural networks,LRCN)模型捕捉这种时间依赖性。LRCN模型由特征提取、序列学习和状态预测3部分组成。特征提取模块基于VGG16框架的卷积神经网络(CNN)将输入的眼睛区域(眼部图像)转化为可识别的特征。序列学习模块,以提取的人眼区域特征作为输入,由具有长短期记忆(LSTM)单元的递归神经网络(recurrent neural network, RNN)实现。使用LSTM-RNN是为了提高RNN模型的存储容量,避免训练阶段的反向传播算法出现梯度消失问题。在最后的状态预测阶段,每个RNN神经元的输出进一步发送到神经网络,神经网络由一个全连接层组成,用一个概率预测的二值化表示眼睛状态,即睁眼(0)和闭眼(1)。
2.2.4 公开数据集
表 2列举了伪造人脸检测领域公开数据集,包括UADFV(University at Albany Deepfake Videos)数据集(Li等,2018)、Google DeepFakeDetection数据集、DFDC(deepfake detection contest)数据集(Dolhansky等,2019)、TIMIT(Texas Instruments/Massachusetts Institute of Technology)数据集(Korshunov和Marcel,2018)、Celeb-DF(celeb deepfakeforensics)数据集(Li等,2020d)、FaceForensics数据集(Rössler等,2018)、FaceForensics++数据集(Rössler等,2019)、DFDC(deepfake detection contest)数据集(Dolhansky等,2019)和DeeperForensics数据集(Jiang等,2020)。
表 2
伪造人脸检测公开数据集
Table 2
The datasets of forgery face detection
| 数据集 | 视频数量/个 | 链接 |
| UADFV | 98 | https://drive.google.com/drive/folders/1GEk1DSxmlV_61JtpEGzC9Fo_BffvyxpH |
| TIMIT | 320 | https://www.idiap.ch/dataset/deepfaketimit |
| Celeb-DF | 1 203 | https://github.com/danmohaha/celeb-deepfakeforensics |
| FaceForensics | 2 008 | https://github.com/ondyari/FaceForensics |
| FaceForensics++ | 5 000 | https://github.com/ondyari/FaceForensics |
| DeepFakeDetection | 3 363 | https://ai.googleblog.com/2019/09/contributing-data-to-deepfake-detection.html |
| DFDC | 5 214 | https://deepfakedetectionchallenge.ai/ |
| DeeperForensics | 70 000 | https://github.com/EndlessSora/DeeperForensics-1.0 |
Li和Lyu(2019)在多个数据集上对几种开源的伪造人脸检测方法进行评估,以帧级AUC(area under the ROC curve)作为评价指标,结果如表 3所示。
表 3
伪造人脸检测方法AUC结果对比(Li和Lyu,2019)
Table 3
AUC results of forgery face detection methods (Li and Lyu, 2019)
| /% | |||||||||||||||||||||||||||||
| 方法 | 数据集 | ||||||||||||||||||||||||||||
| UADFV | FaceForensics++ | DFDC | Celeb-DF | ||||||||||||||||||||||||||
| Muti-task(Nguyen等,2019a) | 65.8 | 76.3 | 53.6 | 54.3 | |||||||||||||||||||||||||
| Xception-raw(Rössler等,2019) | 80.4 | 99.7 | 49.9 | 48.2 | |||||||||||||||||||||||||
| Xception-c23(Rössler等,2019) | 91.2 | 99.7 | 72.2 | 65.3 | |||||||||||||||||||||||||
| Xception-c40(Rössler等,2019) | 83.6 | 95.5 | 69.7 | 65.5 | |||||||||||||||||||||||||
| Meso4(Afchar等,2018) | 84.3 | 84.7 | 75.3 | 54.8 | |||||||||||||||||||||||||
| MesoInception4(Afchar等,2018) | 82.1 | 83.0 | 73.2 | 53.6 | |||||||||||||||||||||||||
| Headpose(Yang等,2019) | 89.0 | 47.3 | 55.9 | 54.6 | |||||||||||||||||||||||||
| 注:加粗字体表示各列最优结果。 | |||||||||||||||||||||||||||||
3 问题与展望
3.1 人脸伪造存在的问题
从最初的GAN到最新的StyleGAN,基于生成对抗网络的人脸生成技术已经能够生成高分辨率、真实性高以至于肉眼难以区分真伪的人脸图像。已有GAN直接生成人脸技术仅存在一些细节问题,如生成的头发部分模糊、在生成图像的微小区域存在明显瑕疵、生成的人脸存在局部不对称等。此外,为了使生成对抗网络关注于人脸区域,在生成过程中往往对背景区域进行虚化,因而生成图像的背景缺乏真实性。局部修改人脸区域的人脸伪造技术仅对部分人脸区域进行修改,必然包含图像的裁剪、拼接等操作,从而引入了伪造痕迹,主要体现在:1)生成的人脸区域与非人脸区域统计分布存在差异,且整幅拼接图像与真实图像的分布存在差异;2)由于人脸轮廓区域经过高斯模糊处理,引入了分布误差;3)如果原始人脸与目标人脸像素大小不同,需对生成的人脸区域图像进行放缩,引入了生成区域与原始区域分辨率的差异。
生成整幅图像的人脸技术能够生成包含人脸和背景区域的整幅图像,但存在以下问题:1)因参与训练的样本较少,在原始人脸与目标人脸姿态差异较大时,生成的人脸不逼真;2)直接生成整幅图像的方式难以应用于伪造视频的生成。
现有的人脸视频伪造技术主要使用局部修改人脸区域的方法,存在以下缺陷:1)单个视频帧内存在伪造痕迹,如侧脸生成模糊、人脸部分缺失纹理细节等;2)在视频生成过程中,没有考虑视频帧的关联性,生成的视频帧间存在不一致性,如帧跳跃、前后两帧人脸关键点位置差异较大;3)生成的人脸视频缺乏正常的生物信息,如眨眼、微表情等。
3.2 伪造人脸检测存在的问题
目前针对伪造人脸图像的检测方法主要使用卷积神经网络提取特征用于分类,加入注意力机制以提取更有效的特征,同时采用编解码结构输出伪造区域的热度图。针对伪造人脸视频的方法主要是用CNN与LSTM结合的方式提取时序特征。这些伪造检测方法在公开数据集上取得了较高的准确率。
然而,无论是伪造人脸图像检测还是伪造人脸视频检测,都存在以下问题:1)现有伪造人脸检测方法对真实场景的鲁棒性较差。许多方法都是在已有的公开数据集上进行,但数据集与真实场景的伪造数据存在差异,许多检测方法都只在特定数据上针对某种伪造方法进行训练,在伪造方法未知的真实场景下准确率较低。2)现有的检测方法对图像视频压缩算法的鲁棒性较差。图像和视频在生成和传播过程中经过压缩过程,部分伪造信息丢失,现有在高分辨率数据集上训练的检测方法不适合于低分辨图像、视频的检测,即压缩和非压缩伪造图像视频检测方法存在不一致问题。例如,一段伪造的人脸视频,无论其中的人脸是经过变换、合成还是重构生成的,一定含有伪造的“痕迹”。但是,经过图像压缩之后,这种“痕迹”将变淡,伪造的特征变得“模糊”,从而增加了检测难度。因而,当前研究主要关注于具有压缩不变性的特征提取方法(Cao等,2021)。3)伪造人脸检测技术难以及时应对伪造技术不断升级进化问题。例如,2019年6月,美国加州大学伯克利分校研发的DeepFake假视频识别方法,准确率达到92%,但是随着深度伪造技术的发展,到2019年12月,其对新产生的伪造视频的识别准确率下降到56%。伪造技术不断进化,检测算法往往难以及时应付。如何在获得新的、少量的伪造数据的条件下,更新和优化检测模型,使其能够适应进化后的伪造技术,也是一个亟待解决的难题。4) 现有的检测方法不适用于部分人脸伪造的场景,即视频的同一帧内包含多个不同人物,其中只有一个特定人物的人脸区域被伪造。现有的方法大都基于投票策略,检测视频帧中所有人脸的真实性,将其中伪造人脸所占的比例作为评判依据,在部分人脸伪造的场景下准确率下降。
3.3 展望
基于生成对抗网络的人脸生成技术已经能生成极为真实的高分辨率人脸图像。以后的研究应丰富生成图像中存在的细节、并修补图像中偶尔出现的微小区域瑕疵,还可考虑生成包含真实场景背景的人脸图像。人脸编辑技术如人脸交换和人脸重现正朝着小样本、通用性和高保真性的方向发展,即在使用样本数目少的前提下,研究适用于多对多的通用性强的人脸编辑技术。
当前针对伪造视频检测技术方法主要使用CNN与LSTM结合的方式,使用CNN捕捉帧内特征,再用LSTM捕捉帧间信息,方法较为单一。可以考虑将视频行为识别、度量学习等领域的方法应用于伪造视频检测。1)可以尝试使用基于区域3D卷积模型,以候选提议的方式将视频划分为多个候选区域,并给予额外的监督,使其重点关注具有伪造信息人脸区域的特征;2)可加入非局部神经网络,学习视频帧间的远距离相关性,使网络模型关注于视频帧间的差异;3)可同时提取频率域和RGB域的特征,伪造图像和视频在频率域含有伪造信息,且对压缩具有鲁棒性;4)可使用度量学习促使伪造特征与真实特征满足指定的分布,如使伪造特征与真实特征的编码距离尽可能远。针对生成伪造视频缺少面部细微活动的特点,可尝试使用微表情捕捉进行伪造人脸视频检测。可以使用面部行为编码系统对人脸的行为建模,并用深度学习方法学习正常视频与伪造视频面部行为的差异。此外,研究通用性高、鲁棒性强、计算资源占用少的伪造人脸检测技术也是未来的发展方向。
4 结语
本文总结了人脸伪造技术和伪造人脸检测技术的研究进展,将人脸伪造技术分为生成对抗网络直接生成人脸、人脸交换和人脸重现3个部分,从网络结构、通用性和生成效果方面进行深入阐述,并介绍了一种整合伪造音频的伪造视频生成方案。将伪造人脸检测技术分为伪造人脸图像检测技术和伪造人脸视频检测技术,详细介绍了其提取伪造特征的种类、方式以及适用场景的差异。最后提出人脸伪造技术和伪造人脸检测技术研究方法的不足,并对未来的研究方向进行了展望。
目前的生成对抗网络技术能够生成真实性极高的高分辨率人脸图像,但存在局部微小瑕疵、缺乏纹理细节等问题。人脸交换和人脸重建技术都将人脸分解到长相和属性两个空间,设计不同的网络结构和损失函数对特定的特征进行迁移,并采用对抗的思想提高生成结果的真实性。研究少样本、多对多和真实性高的人脸编辑框架是人脸伪造领域的发展方向。
当前伪造图像检测技术主要使用神经网络依据统计分布差异、纹理细节等特征进行检测,并结合语义分割任务同时实现伪造区域的定位。伪造视频检测技术使用结合卷积神经网络和递归神经网络的方式提取帧间和帧内的特征。研究通用性高、鲁棒性强、计算资源占用少的伪造人脸检测技术是未来的发展方向。
参考文献
-
Afchar D, Nozick V, Yamagishi J and Echizen I. 2018. MesoNet: a compact facial video forgery detection network//Proceedings of 2018 IEEE International Workshop on Information Forensics and Security. Hong Kong, China: IEEE: 1-7[DOI: 10.1109/WIFS.2018.8630761]
-
Amerini I, Galteri L, Caldelli R and Del Bimbo A. 2019. Deepfake video detection through optical flow based CNN//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision Workshop. Seoul, Korea (South): IEEE: 1205-1207[DOI: 10.1109/ICCVW.2019.00152]
-
Baldi P. 2011. Autoencoders, unsupervised learning and deep architectures//Proceedings of 2011 International Conference on Unsupervised and Transfer Learning workshop. Washington, USA: JMLR. org: 37-50
-
Cao S H, Zou Q, Mao X Q, Ye D P and Wang Z Y. 2021. Metric learning for anti-compression facial forgery detection//Proceedings of 2021 ACM International Conference on Multimedia. Chengdu, China: ACM: 1-10[DOI: 10.1145/3474085.3475347]
-
Cao Y J, Jia L L, Chen Y X, Lin N, Li X X. 2018. Review of computer vision based on generative adversarial networks. Journal of Image and Graphics, 23(10): 1433-1449 (曹仰杰, 贾丽丽, 陈永霞, 林楠, 李学相. 2018. 生成式对抗网络及其计算机视觉应用研究综述. 中国图象图形学报, 23(10): 1433-1449) [DOI:10.11834/jig.180103]
-
Choe J and Shim H. 2019. Attention-based dropout layer for weakly supervised object localization//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE: 2214-2223[DOI: 10.1109/CVPR.2019.00232]
-
Dang H, Liu F, Stehouwer J, Liu X M and Jain A K. 2020. On the detection of digital face manipulation//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE: 5780-5789[DOI: 10.1109/CVPR42600.2020.00582]
-
Dolhansky B, Howes R, Pflaum B, Baram N and Ferrer C C. 2019. The deepfake detection challenge (DFDC) preview dataset[EB/OL]. [2020-08-10]. https://arxiv.org/pdf/1910.08854.pdf
-
Fang F M, Yamagishi J, Echizen I and Lorenzo-Trueba J. 2018. High-quality nonparallel voice conversion based on cycle-consistent adversarial network//Proceedings of 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Calgary, Canada: IEEE: 5279-5283[DOI: 10.1109/ICASSP.2018.8462342]
-
Gatys L A, Ecker A S and Bethge M. 2015. Texture synthesis using convolutional neural networks//Proceedings of the 28th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press: 262-270
-
Goodfellow I J, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A and Bengio Y. 2014. Generative adversarial nets//Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada: MIT Press: 2672-2680
-
Güera D and Delp E J. 2018. Deepfake video detection using recurrent neural networks//Proceedings of the 15th IEEE International Conference on Advanced Video and Signal Based Surveillance. Auckland, New Zealand: IEEE: 1-6[DOI: 10.1109/AVSS.2018.8639163]
-
He K M, Zhang X Y, Ren S Q and Sun J. 2016. Deep residual learning for image recognition//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE: 770-778[DOI: 10.1109/CVPR.2016.90]
-
Hochreiter S, Schmidhuber J. 1997. Long short-term memory. Neural Computation, 9(8): 1735-1780 [DOI:10.1162/neco.1997.9.8.1735]
-
Hu J S, Yu C Y and Guan F Q. 2019. Non-parallel many-to-many singing voice conversion by adversarial learning//Proceedings of 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference. Lanzhou, China: IEEE: 125-132[DOI: 10.1109/APSIPAASC47483.2019.9023357]
-
Hu Y J, Gao Y F, Liu B B, Liao G J. 2021. Deepfake videos detection based on image segmentation with deep neural networks. Journal of Electronics and Information Technology, 43(1): 162-170 (胡永健, 高逸飞, 刘琲贝, 廖广军. 2021. 基于图像分割网络的深度假脸视频篡改检测. 电子与信息学报, 43(1): 162-170) [DOI:10.11999/JEIT200077]
-
Huang X and Belongie S. 2017. Arbitrary style transfer in real-time with adaptive instance normalization//Proceedings of 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE: 1510-1519[DOI: 10.1109/ICCV.2017.167]
-
Huang Y H, Juefei-Xu F, Wang R, Guo Q, Xie X F, Ma L, Li J W, Miao W K, Liu Y and Pu G G. 2020. FakeLocator: robust localization of GAN-based face manipulations[EB/OL]. [2020-08-10]. https://arxiv.org/pdf/2001.09598.pdf
-
Ioffe S and Szegedy C. 2015. Batch normalization: Accelerating deep network training by reducing internal covariate shift//Proceedings of the 32nd International Conference on International Conference on Machine Learning. Lille, France: JMLR. org: 448-456
-
Isola P, Zhu J Y, Zhou T H and Efros A A. 2017. Image-to-image translation with conditional adversarial networks//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE: 5967-5976[DOI: 10.1109/CVPR.2017.632]
-
Jiang L M, Li R, Wu W, Qian C and Loy C C. 2020. Deeperforensics-1.0: a large-scale dataset for real-world face forgery detection//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE: 2886-2895[DOI: 10.1109/CVPR42600.2020.00296]
-
Johnson J, Alahi A and Li F F. 2016. Perceptual losses for real-time style transfer and super-resolution//Proceedings of the 14th European Conference on Computer Vision. Amsterdam, the Netherlands: Springer: 694-711[DOI: 10.1007/978-3-319-46475-6_43]
-
Karras T, Aila T, Laine S and Lehtinen J. 2018. Progressive growing of gans for improved quality, stability, and variation//Proceedings of the 6th International Conference on Learning Representations (ICLR). Vancouver, Canada: 1-26
-
Karras T, Laine S and Aila T. 2019. A style-based generator architecture for generative adversarial networks//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE: 4396-4405[DOI: 10.1109/CVPR.2019.00453]
-
Kim H, Garrido P, Tewari A, Xu W P, Thies J, Niessner M, Pérez P, Richardt C, Zollhöfer M, Theobalt C. 2018. Deep video portraits. ACM Transactions on Graphics, 37(4): #163 [DOI:10.1145/3197517.3201283]
-
Kingma D P and Welling M. 2014. Auto-encoding variational Bayes//Proceedings of the 2nd International Conference on Learning Representations. Ithaca, USA: #14
-
Korshunov P and Marcel S. 2018. DeepFakes: a new threat to face recognition? Assessment and detection[EB/OL]. [2020-08-10]. https://arxiv.org/pdf/1812.08685.pdf
-
Korshunova I, Shi W Z, Dambre J and Theis L. 2017. Fast face-swap using convolutional neural networks//Proceedings of 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE: 3697-3705[DOI: 10.1109/ICCV.2017.397]
-
Li H, Zheng J B. 2017. Blind image forgery detection method based on noise variance estimation. Application Research of Computers, 34(1): 314-316 (李杭, 郑江滨. 2017. 基于噪声方差估计的伪造图像盲检测方法. 计算机应用研究, 34(1): 314-316) [DOI:10.3969/j.issn.1001-3695.2017.01.071]
-
Li L Z, Bao J M, Yang H, Chen D and Wen F. 2020a. Advancing high fidelity identity swapping for forgery detection//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE: 5073-5082[DOI: 10.1109/CVPR42600.2020.00512]
-
Li L Z, Bao J M, Zhang T, Yang H, Chen D, Wen F and Guo B N. 2020b. Face X-ray for more general face forgery detection//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE: 5000-5009[DOI: 10.1109/CVPR42600.2020.00505]
-
Li X D, Lang Y N, Chen Y F, Mao X F, He Y, Wang S H, Xue H and Lu Q. 2020c. Sharp multiple instance learning for DeepFake video detection//Proceedings of the 28th ACM International Conference on Multimedia. Seattle, USA: ACM: 1864-1872[DOI: 10.1145/3394171.3414034]
-
Li Y Z and Lyu S. 2019. Exposing DeepFake videos by detecting face warping artifacts//Proceedings of 2019 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Washington, USA: IEEE: 46-52
-
Li Y Z, Yang X, Sun P, Qi H G and Lyu S W. 2020d. Celeb-DF: a large-scale challenging dataset for DeepFake forensics//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE: 3207-3216
-
Li Y Z, Chang M C and Lyu S W. 2018. In ictu oculi: exposing AI created fake videos by detecting eye blinking//Proceedings of 2018 IEEE International Workshop on Information Forensics and Security (WIFS). Hong Kong, China: IEEE: 1-7[DOI: 10.1109/WIFS.2018.8630787]
-
Liu Z Z, Qi X J and Torr P H S. 2020. Global texture enhancement for fake face detection in the wild//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, USA: IEEE: 8057-8066[DOI: 10.1109/CVPR42600.2020.00808]
-
Masi I, Killekar A, Mascarenhas R M, Gurudatt S P and Abdalmageed W. 2020. Two-branch recurrent network for isolating deepfakes in videos//Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer: 667-684[DOI: 10.1007/978-3-030-58571-6_39]
-
Matern F, Riess C and Stamminger M. 2019. Exploiting visual artifacts to expose deepfakes and face manipulations//Proceedings of 2019 IEEE Winter Applications of Computer Vision Workshops. Waikoloa, USA: IEEE: 83-92[DOI: 10.1109/WACVW.2019.00020]
-
McCloskey S and Albright M. 2018. Detecting GAN-generated imagery using color cues[EB/OL]. [2020-08-10]. https://arxiv.org/pdf/1812.08247.pdf
-
Natsume R, Yatagawa T and Morishima S. 2018a. RSGAN: face swapping and editing using face and hair representation in latent spaces//Proceedings of Special Interest Group on Computer Graphics and Interactive Techniques Conference. Vancouver, Canada: ACM: #69[DOI: 10.1145/3230744.3230818]
-
Natsume R, Yatagawa T and Morishima S. 2018b. FSNet: an identity-aware generative model for image-based face swapping//Proceedings of the 14th Asian Conference on Computer Vision. Perth, Australia: Springer: 117-132[DOI: 10.1007/978-3-030-20876-9_8]
-
Nguyen H H, Fang F M, Yamagishi J and Echizen I. 2019a. Multi-task learning for detecting and segmenting manipulated facial images and videos//Proceedings of 2019 IEEE 10th International Conference on Biometrics Theory, Applications and Systems (BTAS). Tampa, USA: IEEE: 1-8[DOI: 10.1109/BTAS46853.2019.9185974]
-
Nguyen T T, Nguyen Q V H, Nguyen C M, Nguyen D, Nguyen D T and Nahavandi S. 2019b. Deep learning for deepfakes creation and detection: a survey[EB/OL]. [2020-08-10]. https://arxiv.org/pdf/1909.11573.pdf
-
Qian Y Y, Yin G J, Sheng L, Chen Z X and Shao J. 2020. Thinking in frequency: face forgery detection by mining frequency-aware clues//Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer: 86-103[DOI: 10.1007/978-3-030-58610-2_6]
-
Radford A, Metz L and Chintala S. 2015. Unsupervised representation learning with deep convolutional generative adversarial networks[EB/OL]. [2020-08-10]. https://arxiv.org/pdf/1511.06434.pdf
-
Ronneberger O, Fischer P and Brox T. 2015. U-Net: convolutional networks for biomedical image segmentation//Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention. Munich, Germany: Springer: 234-241[DOI: 10.1007/978-3-319-24574-4_28]
-
Rössler A, Cozzolino D, Verdoliva L, Riess C, Thies J and Nieβner M. 2018. FaceForensics: a large-scale video dataset for forgery detection in human faces[EB/OL]. [2020-08-10]. https://arxiv.org/pdf/1803.09179.pdf
-
Rössler A, Cozzolino D, Verdoliva L, Riess C, Thies J and Niessner M. 2019. FaceForensics++: learning to detect manipulated facial images//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Seoul, Korea (South): IEEE: 1-11[DOI: 10.1109/ICCV.2019.00009]
-
Sabir E, Cheng J X, Jaiswal A, Wael A, Masi I and Natarajan P. 2019. Recurrent convolutional strategies for face manipulation detection in videos//Proceedings of 2019 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Long Beach, USA: IEEE: 80-87
-
Simonyan K and Zisserman A. 2015. Very deep convolutional networks for large-scale image recognition//Proceedings of the 3rd International Conference on Learning Representations. San Diego, USA
-
Song H Z, Wu X J. 2019. High-quality image generation model for face aging/processing. Journal of Image and Graphics, 24(4): 592-602 (宋昊泽, 吴小俊. 2019. 人脸老化/去龄化的高质量图像生成模型. 中国图象图形学报, 24(4): 592-602) [DOI:10.11834/jig.180272]
-
Sun P, Lang Y B, Gong J C, Shen Z. 2017. Authentication method for splicing manipulation with inconsistencies in color shift. Journal of Computer-Aided Design and Computer Graphics, 29(8): 1408-1415 (孙鹏, 郎宇博, 巩家昌, 沈喆. 2017. 拼接篡改伪造图像的色彩偏移量不一致取证方法. 计算机辅助设计与图形学学报, 29(8): 1408-1415)
-
Suwajanakorn S, Seitz S M and Kemelmacher-Shlizerman I. 2015. What makes tom hanks look like tom hanks//Proceedings of 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE: 3952-3960[DOI: 10.1109/ICCV.2015.450]
-
Thies J, Zollhöfer M, Nieβner M, Valgaerts L, Stamminger M, Theobalt C. 2015. Real-time expression transfer for facial reenactment. ACM Transactions on Graphics, 34(6): #183 [DOI:10.1145/2816795.2818056]
-
Thies J, Zollhofer M, Stamminger M, Theobalt C and Nieβner M. 2016. Face2face: real-time face capture and reenactment of RGB videos//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, USA: IEEE: 2387-2395[DOI: 10.1109/CVPR.2016.262]
-
Wang R, Juefei-Xu F, Ma L, Xie X F, Huang Y H, Wang J and Liu Y. 2020. FakeSpotter: a simple yet robust baseline for spotting AI-synthesized fake faces[EB/OL]. [2020-08-10]. https://arxiv.org/pdf/1909.06122.pdf
-
Wu W, Zhang Y X, Li C, Qian C and Loy C C. 2018. ReenactGAN: learning to reenact faces via boundary transfer//Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer: 622-638[DOI: 10.1007/978-3-030-01246-5_37]
-
Xuan X S, Peng B, Wang W and Dong J. 2019. On the generalization of GAN image forensics//Proceedings of the 14th Chinese Conference on Biometric Recognition. Zhuzhou, China: Springer: 2019: 134-141[DOI: 10.1007/978-3-030-31456-9_15]
-
Yang X, Li Y Z and Lyu S. 2019. Exposing deep fakes using inconsistent head poses//Proceedings of ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing. Brighton, UK: IEEE: 8261-8265[DOI: 10.1109/ICASSP.2019.8683164]
-
Zhang Y X, Li G, Cao Y, Zhao X F. 2020. A Method for Detecting Human-face-tampered Videos based on Interframe Difference. Journal of Cyber Security, 5(2): 49-72 (张怡暄, 李根, 曹纭, 赵险峰. 2020. 基于帧间差异的人脸篡改视频检测方法. 信息安全学报, 5(2): 49-72) [DOI:10.19363/J.cnki.cn10-1380/tn.2020.02.05]
-
Zhang Y X, Zhang S W, He Y, Li C, Loy C C and Liu Z W. 2019. One-shot face reenactment//Proceedings of the 30th British Machine Vision Conference 2019. Cardiff, UK: BMVA Press: 1-10
-
Zhu J Y, Park T, Isola P and Efros A A. 2017. Unpaired image-to-image translation using cycle-consistent adversarial networks//Proceedings of 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE: 2242-2251[DOI: 10.1109/ICCV.2017.244]


