|
|
|
发布时间: 2022-11-16 |
综述 |
|
|
|


|
收稿日期: 2021-09-02; 修回日期: 2021-11-19; 预印本日期: 2021-11-26
基金项目: 国家重点研发计划资助(2018YFC0407905);江苏省重点研发计划资助(BE2016904);中央高校基本科研业务费专项资金资助(B20020188);江苏省水利科技项目(2018057)
作者简介:
王帅琛,男,硕士研究生,主要研究方向为计算机视觉、行为识别。E-mail: wsc543079267@gmail.com
黄倩,通信作者,男,副研究员,主要研究方向为多媒体数据处理、云计算、机器学习。E-mail:huangqian@hhu.edu.cn 张云飞,男,博士,主要研究方向为数据挖掘、知识工程。E-mail: zhangyunfei@hhu.edu.cn 李兴,男,博士研究生,主要研究方向为行为识别和机器视觉。E-mail: 340299042@qq.com 聂云清,男,硕士研究生,主要研究方向为行为识别。E-mail: 15161663997@163.com 雒国萃,女, 硕士研究生, 主要研究方向为行为识别。E-mail: 993499805@qq.com *通信作者: 黄倩 huangqian@hhu.edu.cn
中图法分类号: TP391
文献标识码: A
文章编号: 1006-8961(2022)11-3139-21
|
摘要
行为识别是当前计算机视觉方向中视频理解领域的重要研究课题。从视频中准确提取人体动作的特征并识别动作,能为医疗、安防等领域提供重要的信息,是一个十分具有前景的方向。本文从数据驱动的角度出发,全面介绍了行为识别技术的研究发展,对具有代表性的行为识别方法或模型进行了系统阐述。行为识别的数据分为RGB模态数据、深度模态数据、骨骼模态数据以及融合模态数据。首先介绍了行为识别的主要过程和人类行为识别领域不同数据模态的公开数据集;然后根据数据模态分类,回顾了RGB模态、深度模态和骨骼模态下基于传统手工特征和深度学习的行为识别方法,以及多模态融合分类下RGB模态与深度模态融合的方法和其他模态融合的方法。传统手工特征法包括基于时空体积和时空兴趣点的方法(RGB模态)、基于运动变化和外观的方法(深度模态)以及基于骨骼特征的方法(骨骼模态)等;深度学习方法主要涉及卷积网络、图卷积网络和混合网络,重点介绍了其改进点、特点以及模型的创新点。基于不同模态的数据集分类进行不同行为识别技术的对比分析。通过类别内部和类别之间两个角度对比分析后,得出不同模态的优缺点与适用场景、手工特征法与深度学习法的区别和融合多模态的优势。最后,总结了行为识别技术当前面临的问题和挑战,并基于数据模态的角度提出了未来可行的研究方向和研究重点。
关键词
计算机视觉; 行为识别; 深度学习; 神经网络; 多模态; 模态融合
Abstract
Body action oriented recognition issue is an essential domain for video interpretation of computer vision analysis. Its potentials can be focused on accurate video-based features extraction for body actions and the related recognition for multiple applications. The data modes of body action recognition modals can be segmented into RGB, depth, skeleton and fusion, respectively. Our multi-modals based critical analysis reviews the research and development of body action recognition algorithm. Our literature review is systematically focused on current algorithms or models. First, we introduce the key aspects of body action recognition method, which can be divided into video input, feature extraction, classification and output results. Next, we introduce the popular datasets of different data modal in the context of body action recognition, including human motion database(HMDB-51), UCF101 dataset, Something-Something datasets of RGB mode, depth modal and skeleton-mode MSR-Action3D dataset, MSR daily activity dataset, UTD-multimodal human action recognition dataset(MHAD) and RGB mode/depth mode/skeleton modal based NTU RGB + D 60/120 dataset, the characteristics of each dataset are explained in detail. Compared to more action recognition reviews, our contributions can be proposed as following: 1) data modal/method/datasets classifications are more instructive; 2) data modal/fusion for body action recognition is discussed more comprehensively; 3) recent challenges of body action recognition is just developed in deep learning and lacks of early manual features methods. We analyze the pros of manual features and deep learning; and 4) their advantages and disadvantages of different data modal, the challenges of action recognition and the future research direction are discussed. According to the data modal classification, the traditional manual feature and deep learning action recognition methods are reviewed via modals analysis of RGB/depth modal/skeleton, as well as multi-modal fused classification and related fusion methods of RGB modal and depth modal. For RGB modal, the traditional manual feature method is related to spatiotemporal volume, spatiotemporal based interest points and the skeleton trajectory based method. The deep learning method involves 3D convolutional neural network and double flow network. 3D convolution can construct the relationship between spatial and temporal dimensions, and the spatiotemporal features extraction is taken into account. The manual feature depth modal methods involve motion change/appearance features. The depth learning method includes representative point cloud network. Point cloud network is leveraged from image processing network. It can extract action features better via point sets processing. The skeleton modal oriented manual method is mainly based on skeleton features, and the deep learning technique mainly uses graph convolution network. Graph convolution network is suitable for the graph shape characteristics of skeleton data, which is beneficial to the transmission of information between skeletons. Next, we summarize the recognition accuracy of representative algorithms and models on RGB modal HMDB-51 dataset, UCF101 dataset and Something-Something V2 dataset, select the data representing manual feature method and depth learning method, and accomplish a histogram for more specific comparative results. For depth modal, we collect the recognition rates of some algorithms and models on MSR-Action3D dataset and NTU RGB + D 60 depth dataset. For skeleton data, we select NTU RGB + D 60 skeleton dataset and NTU RGB + D 120 skeleton dataset, the recognition accuracy of the model is compared. At the same time, we draw the clue of the parameters that need to be trained in the model in recent years. For the multi-modal fusion method, we adopt NTU RGB + D 60 dataset including RGB modal, depth modal and skeleton modal. The comparative recognition rate of single modal is derived of the same algorithm or model and the improved accuracy after multi-modal fusion. We sorted out that RGB modal, depth modal and skeleton modal have their potentials/drawbacks to match applicable scenarios. The fusion of multiple modals can complement mutual information to a certain extent and improve the recognition effect; manual feature method is suitable for some small datasets, and the algorithm complexity is lower; deep learning is suitable for large datasets and can automatically extract features from a large number of data; more researches have changed from deepening the network to lightweight and high recognition rate network. Finally, the current problems and challenges of body action recognition technology are summarized on the aspects of multiple body action recognition, fast and similar body action recognition, and depth and skeleton data collection. At the same time, the data modal issues are predicted further in terms of effective modal fusion, novel network design, and added attention module.
Key words
computer vision; action recognition; deep learning; neural network; multimodal; modal fusion
0 引言
人体行为识别是计算机视觉、深度学习、视频处理和模式识别等学科交叉的研究课题,是当前计算机视觉的一个研究热点。行为识别是对包含人体动作行为的视频序列进行动作特征提取、特征表示和动作识别等操作的过程。由于视频采集传感器的成本降低和快速发展,使得行为识别有了广泛的应用前景,例如视频检索、人机交互、医学监测和自动驾驶等领域,都涉及行为识别的相关技术。
行为识别属于视频理解的范畴,所以特征的提取和表示至关重要。这两个过程的好坏会直接影响最终的分类结果。特征可以通过手工制作和网络学习获取,图 1介绍了两种方法的基本过程。手工特征的方法利用图像和数学等知识,设计出一种表达动作的方式,通过表达动作的信息区分不同类别的动作。算法实现更简单,但是常常局限于某个数据集。深度学习网络自适应性更好,能够根据输入数据和设计的网络提取出侧重的特征,并能依靠反向传播等手段优化提取特征的过程,最终得到一个能高效提取动作特征和正确分类的网络模型。


从数据驱动的角度出发,可将行为识别方法分为基于RGB数据的方法、基于深度数据的方法、基于骨骼数据的方法和融合以上模态数据的方法,如图 2所示。每种数据的模态都有自身特性导致的优缺点,如RGB模态数据易采集但鲁棒性较差。因此提出了融合多模态的方法,以克服一些单模态存在的问题。

本文相比较其他行为识别综述的贡献在于:1)本文的数据模态分类、方法分类和数据集分类一一对应,对初学者或者长期研究者都提供了一个结构清晰的介绍和对比;2)其他的行为识别综述通常注重单一模态下的论述,而本文更加全面地论述了多种数据模态和数据融合的行为识别;3)近年的行为识别综述只包含深度学习,缺少早期手工特征的方法,本文分析手工特征的思想优点和深度学习的优势,进而实现优势互补;4)讨论了不同数据模态的优劣性和动作识别的挑战以及未来研究方向。
1 行为识别数据集
在评价不同识别方法的性能时,数据集有非常重要的作用。目前有许多公开的行为数据集供研究人员使用。主流数据集的详细信息如表 1所示。
表 1
当前主流的行为识别数据集
Table 1
Mainstream action recognition datasets
| 数据库 | 年份 | 类别数 | 样本数 | 数据模态 |
| HMDB-51 | 2011 | 51 | 6 849 | RGB |
| UCF101 | 2013 | 101 | 13 320 | RGB |
| Kinetics-400/600/700 | 2016/2017/2018 | 400/600/700 | 306 245/495 547/650 317 | RGB |
| Something-Something v1/v2 | 2017/2018 | 174 | 108 499/220 847 | RGB |
| MSR-Action3D | 2010 | 20 | 567 | 深度图,骨骼 |
| MSR-Daily Activity | 2012 | 16 | 320 | RGB,深度图,骨骼 |
| UTD-MHAD | 2015 | 27 | 861 | RGB,深度图,骨骼 |
| NTU RGB+D 60/120 | 2016/2019 | 60/120 | 56 880/114 480 | RGB,深度图,骨骼 |
HMDB-51(human motion database)(Kuehne等,2011)中数字51代表类别数量。它是从各种互联网资源和数字化电影中收集形成,此数据集的动作主要是日常行为,如图 3所示。该数据集包含6 849个视频,分为51个动作类别,每种动作包含101个视频片段。该数据集的干扰因素主要是摄像机视角和运动的变化、背景杂乱、志愿者位置和外观的变化。

UCF101(Soomro等,2012)是由美国中佛罗里达大学(University of Central Florida,UCF)计算机视觉研究中心发布的数据集,是UCF50数据集的扩展,收集自YouTube,提供了包含101个动作类别的13 320个视频样本数据。UCF101在动作方面提供了最大的多样性,在摄像机运动、对象的外观和姿态、对象规模、视点、杂乱的背景以及照明条件等方面有很大的变化。
Kinetics(Carreira和Zisserman,2017)是一个大规模、高质量的YouTube视频数据集,其中包括各种各样的以人为中心的动作。该数据集由大约300 000个视频片段组成,涵盖400种动作类别,每个动作至少有400个视频片段。每个片段持续大约10 s,并标记为一个动作类别。所有片段都经过多轮人工标注,都是从一个独特的YouTube视频中获得。这些动作涵盖了广泛的动作类别,包括人与物的交互,如演奏乐器;以及人与人的交互,如握手和拥抱。发布者先后在2016年、2017年、2018年相继发布了Kinetics-400、Kinetics-600(Carreira等,2018)和Kinetics-700(Carreira等,2019)系列,代表视频中的动作可分为400、600、700个类别。
Something-Something数据集(Goyal等,2017)是一个中等规模的数据集,它与一般数据集的最大区别在于,其内容定义的是原子动作,并且该数据集特别注重时序上的关系。第1版本和第2版本数据集由108 499个和220 847个视频组成,均可分为174个动作类别。
MSR-Action3D(Li等,2010)是微软研究院(Microsoft Research,MSR)利用Kinect深度相机捕获的动作数据集。它包含20种与人类运动相关的活动,如慢跑、高尔夫挥杆等。图 4为其中3个动作的深度图实例。这个数据集中的每个动作由10个人执行2~3次,总共包含567个样本。因为动作的高度相似性,该数据集具有一定的挑战性。

MSR-Daily Activity(Wang等,2012)是微软研究院(MSR)利用Kinect相机拍摄日常活动采集而成的数据集,共有16种动作类别,320个活动样本。其中,骨骼跟踪器提取的3维关节位置信息非常嘈杂,大部分活动都涉及人与物的交互。因此,动作的识别难度较大。
UTD-MHAD(Chen等,2015a)数据集是美国得克萨斯大学达拉斯分校(The University of Texas at Dallas,UTD)发布的多模态人体行为识别数据集(multimodal human action recognition dataset,MHAD),由8个表演者执行27个类别的动作组成。每个表演者重复动作4次,总共包括861个视频序列。该数据集包含RGB模态、深度模态、骨架模态和惯性传感器信号。
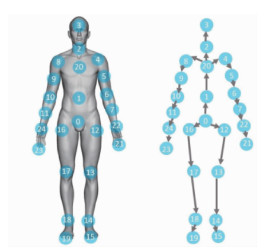
NTU RGB+D(Shahroudy等,2016a)数据集由新加坡南洋理工大学(Nanyang Technological University,NTU)创建,包含RGB模态和深度模态。它是迄今为止最大的动作数据集,包含56 880个样本数据和超过400万帧的视频。该数据集一共有60个动作类别,基于3台摄像机,在3个不同的视角,拍摄表演者的动作过程。这个数据集对于不同的视频序列具有可变的序列长度,并且表现出很高的类内变化。该数据集包含了RGB模态、深度模态和骨骼模态。骨骼模态的数据集包含了25个关节记录信息,图 5为人体的25个关节示意图。NTU RGB+D 120(Liu等,2020a)是NTU RGB+D数据集的扩展,添加了另外60个类别动作和57 600个视频样本,与之前的工作叠加形成120个动作类别和114 480个样本的大型数据集。
2 基于RGB数据的行为识别方法
RGB数据的优点在于成本低、易获取,缺点在于对外观的变化(如光线变化)缺少鲁棒性。当识别目标与背景具有相似颜色和纹理时,仅用RGB数据很难处理这个问题,这些局限妨碍了基于RGB数据的行为识别技术在复杂环境中的应用。基于RGB的行为特征的生成方式可分为手工制作和机器学习。
2.1 基于手工特征的方法
手工制作的目的是得到人体行为动作的运动和时空变化,包括基于时空体积的动作表示法、基于时空兴趣点的方法和基于骨骼关节轨迹的方法。
基于时空体积的动作表示法利用3维的时空模板进行动作识别,关键在于匹配模板的构造和编码运动信息。Bobick和Davis(2001)提出了MEI(motion-energy images)和MHI(motion-history images)分别表示动作发生的空间位置和动作发生的时间过程,如图 6所示,MEI提取空间特征,MHI提取时间特征。在前期阶段,运动历史图和运动能量图十分相似,但在后期阶段两者有较大的区别。Klaser等人(2008)在2D HOG(histogram of oriented gradient)的基础上,拓展出3D HOG特征来描述人体行为,提高了识别准确率。上述文献的创新在于特征的表示,新颖的特征表示思想十分具有参考价值。但背景的噪声和遮挡会使特征提取十分困难,并且忽略了一些局部特征,对近似动作识别具有局限性。

基于时空兴趣点的方法较时空体积法对背景的要求降低,它通过提取运动变化明显的关键区域来表示动作,重点在于关键兴趣点的检测方法、描述的特征和分类方法。最常见的方法是基于3D-Harris时空特征点来检测关键区域。Chakraborty等人(2012)提出了一种改进后的3D-Harris方法,将局部特征检测技术从图像扩展到3维时空域,然后计算特征描述子,并利用描述行为的视觉词袋模型来构建视觉单词词汇表,用于加强对行为的描述。Nguyen等人(2015)提出了一种基于时空注意机制的关键区域提取方法,将密集采样与视频显著信息驱动的时空特征池相结合,构造视觉词典和动作特征。密集采样能更好地表示动作,但是增加了算法的复杂度,因此平衡采样密集度和算法复杂度的关系是时空兴趣点方法的重点之一。
上述方法易受遮挡和相机视角变化的干扰,所以提出了基于骨骼和关节轨迹的动作表示方法,用于分析人体的局部运动信息。该方法从RGB图像中提取骨骼关键点或者跟踪人体骨骼运动的轨迹,根据关键点和轨迹判断动作的类别。该方法的关键在于使用何种算法和模型从RGB图像中提取关键点或者轨迹。Gaidon等人(2014)基于分裂聚类法表示局部运动轨迹,计算轨迹特征并用聚类结果表示不同运动类别。Wang和Schmid(2013)借鉴兴趣点密集采样的思想,通过采集密集点云和光流法跟踪特征点,获取密集轨迹(improved dense trajectories,iDT),然后计算位移信息进行识别。RGB模态的骨骼和关节轨迹方法仍然存在背景和遮挡的干扰。但是识别动作的准确性提高,促使之后的科研人员依靠传感器采集骨骼模态形成数据集,从骨骼模态的角度研究行为识别。
2.2 基于深度学习的方法
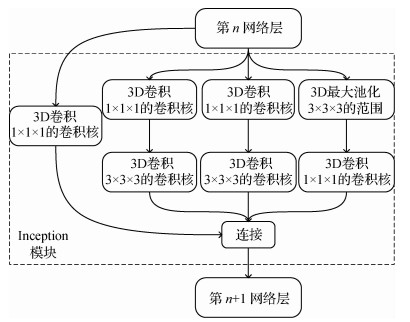
深度学习的崛起逐渐影响了行为识别领域。基于深度学习网络提取的高层次特征,信息量丰富、有区分性,优于传统手工特征,应用于行为识别领域取得了重大的突破。在2D-CNN(convolutional neural networks)的基础上,Carreira和Zisserman(2017)提出了一种I3D(two-stream inflated 3D ConvNets)模型,将卷积从2维扩展到3维,并提出了双流3D卷积网络用于动作识别,双流网络也成为后人模仿借鉴的经典方法。图 7为I3D中改进后的Inception模块,其中大小为1的3D卷积作用为减少参数量,尺寸都为3的最大池化和3D卷积提取不同尺度的特征,同时残差连接输入与输出,保持模型的稳定性。同时Carreira和Zisserman(2017)提出了Kinetics数据集,将许多经典算法在此数据集上进行实验对比,分析各算法的优缺点。Zhu等人(2018)提出了一种名为隐式双流神经网络结构的CNN体系结构(hidden two-stream convolutional networks),将原始视频帧作为输入并直接预测动作类别,通过隐式捕获相邻帧之间的运动信息,使用端到端的方法解决了需要计算光流的问题。研究者通过改进卷积网络的模块和深度,行为识别的准确率大幅提升。虽然加深网络能更有效地提取特征,但网络也会变得臃肿和训练缓慢。为了保证时空流之间的可分辨性和探索互补信息,Zhang等人(2019)提出了一种新颖的协同跨流网络,该网络调查多种不同模式中的联合信息,通过端到端的学习方式提取共同空间和时间流的网络特征,探索出不同流特征之间的相关性,从中提取不同模态的互补信息。神经网络方便了特征提取的方法,但不能拘泥于网络深度等方面,更应该从多个角度(帧选择和跨流网络的想法)优化识别过程。为了解决光流的计算复杂度问题,Kwon等人(2020)用运动特征的内部信息和轻量级学习代替对光流的繁重计算,提出了一种名为MotionSqueeze的可训练神经模块,用于有效的运动特征提取。该模块即插即用,能插入任何神经网络的中间来学习帧间关系,并将其转换为运动特征,然后送到下一个网络层进行更好的预测。
学者的创新曾经局限在提取特征的技术,Gowda等人(2020)从帧选择的角度出发,保留行为特征在时间序列上区别明显的“好”帧,剔除特征类似和无法分类的帧,提出一种名为SMART的智能帧选择网络,如图 8所示,综合考虑单个帧和多个帧的质量,而不是一次仅考虑一个帧。在降低计算量的同时,提高了识别准确率。Qiu等人(2019)注意到视频是具有复杂时间变化的信息密集型媒体,而神经网络中的卷积滤波器都是局部操作,忽略了视频帧之间的相关性,提出了一种新的基于局部和全局扩散的时空表示学习框架,并行学习局部和全局表示。每个块建模这两种表示方式,并且两者之间交换信息来更新局部和全局特征,多个块组成此网络结构,有效地保持了信息的局部性和整体性,获得了强大的特征学习方式。这些行为识别技术的革新都是在其他研究的基础上,保留优点,减弱负面影响或者解决存在的问题,最终实现行为识别技术的突破。

3 基于深度数据的行为识别方法
RGB数据受干扰性较大,促使了深度数据的产生。深度图中的纹理和颜色信息少,将图像采集器到场景中各点的距离(深度)作为像素值,对光照的鲁棒性强。深度传感器的产生极大地扩展了计算机系统感知3D视觉世界和获取视觉信息的能力。深度数据的信息与RGB数据本质上不同,它对场景的距离信息进行编码,而不是对颜色强度进行编码。因此,深度数据可以更简单精确地获取关键区域。但深度信息也不是一直具有鲁棒性,遮挡物和闪烁噪声可能会对行为识别造成误差。
3.1 基于运动变化和外观信息的方法
基于深度数据的行为识别方法主要利用人体深度图中的运动变化来描述动作。动作的特征由深度变化的外观或运动信息进行描述。Yang等人(2012)通过深度运动图(depth motion map,DMM)来投影和压缩时空深度结构,再从正面,侧面和俯视图形成3个运动历史图。然后,利用HOG(histogram of oriented gradient)特征表示这些运动历史图,并将生成的HOG特征串联起来以描述动作。除了计算运动变化来描述动作的方法外,另一种流行的方法是通过外观信息来描述动作。Yang等人(2012)基于深度序列构造一个超向量特征来表示动作,通过连接来自深度视频的局部相邻超曲面法线来扩展HON4D(histogram oriented 4D normals),联合局部形状和运动信息,引入了一种自适应时空金字塔,将深度视频细分为一组时空单元,以获得更具鉴别力的特征。
为了剔除噪声影响,Xia和Aggarwal(2013)提出了一种新的深度长方体相似性特征,用来描述具有自适应支撑尺寸的3维深度长方体,从而获得更可靠的时空兴趣点。Chen和Guo(2015)通过分析前、侧和上方向的时空结构,提取时空兴趣点的运动轨迹形状和边界直方图特征,以及每个视图中的密集样本点和关节点来描述动作。
深度模态较RGB模态多了深度这一信息,因此如何充分利用深度相关信息,如大小、变化等,是基于深度模态的行为识别的关键。这一思想不但适用于手工特征法,也适用于深度学习法。
3.2 基于深度学习的方法
深度模态下基于深度学习的方法可分为两类:一类是深度特征图和卷积神经网络的结合;另一类是提取深度信息的点集与点云网络的结合。
为了充分利用深度序列中的空间、时间和结构信息进行不同时间尺度的动作识别,Wang等人(2018a)提出了3种简单、紧凑而有效的深度序列表示方法,分别称为动态深度图像(dynamic depth images,DDI)、动态深度法线图像(dynamic depth normal images,DDNI)和动态深度运动法线图像(dynamic depth motion normal images,DDMNI),用于孤立和连续动作识别。其中,DDI记录了随时间变化的动态姿势,DDNI和DDMNI记录了深度图捕获的3维结构信息。然后将3种特征图输入神经网络,提取不同的特征。Trelinski和Kwolek(2019)提出了一种基于深度图序列的动作识别算法。首先,在单个深度图中提取描述人形的特征,然后,对每个类单独训练提取单个类的特征,同时对每个深度图中代表人形的像素计算手工的特征。最后,所有动作共用的手工特征和特定动作的特征连接在一起,形成动作特征向量。
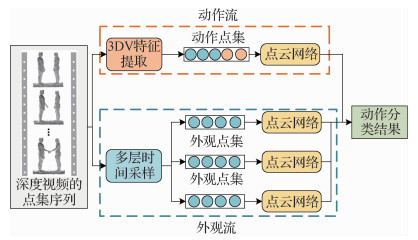
深度图和点云可以相互转换,并且点云的表示简单,有非常统一的结构,避免组合的不规则性和复杂性。因此,Wang等人(2020)提出了3维动态像素(3D dynamic voxel,3DV)作为新颖的3维运动表示。通过时间顺序池化将深度视频中的3维运动信息压缩成规则的3DV像素点集,每个可用的3DV像素本质上涉及3维空间和运动功能,然后将3DV抽象为一个点集。由于3维点集的不规则,常规的卷积神经网络不适合处理不规则的信息形状,将点集输入点云网络(PointNet++),保持了点集的置换不变形。如图 9所示,动作流提取3D像素表示的人体动作特征,外观流提取人体的外观特征,结合两个特征的信息进行行为识别。Wang等人(2015)将卷积网络与深度图结合起来,通过卷积网络来学习深度图像序列的动作特征。利用分层深度运动映射(hierarchical depth motion maps,HDMMs)来提取人体的形状和运动信息,然后在HDMMs上训练一个卷积神经网络进行人体动作识别。在此基础上,Liu和Xu(2021)设计一个端到端的几何运动网络(GeometryMotion-Net),分别利用点云网络提取运动特征和几何特征,而3DV PointNet不能进行端到端的训练。3DV PointNet并没有充分考虑时间信息,而GeometryMotion-Net将每个点云序列表示为一个虚拟整体几何点云和多个虚拟运动点云来明确时间信息。两项改进措施使得识别准确率有了较大提升。
4 基于骨骼数据的行为识别方法
该方法通过骨骼关节实时对3D人体关节位置进行编码,实现人体行为的动作识别。由于人体骨骼的运动可以区分许多动作,利用骨骼数据进行动作识别是一个有前景的方向。骨骼数据包含的时空信息丰富,关节节点与其相邻节点之间存在着很强的相关性,使得骨架数据不但能在同一帧中发现丰富的人体结构信息,帧与帧之间也存在着强相关性。同时考虑骨骼和帧序列、时域和空域之间的共现关系能准确地描述动作。
4.1 基于骨骼特征提取的方法
对现有的基于骨骼数据的特征提取方法进行分析,根据其所对应的识别位置可分为基于关节和基于身体部位的行为识别方法。
Vemulapalli等人(2014)提出了一种新的骨骼表示法,利用3维空间中的旋转和平移来模拟身体各个部位之间的3维几何关系。人体骨骼作为李群(Lie group)中的一点,人的行为可以被建模为这个李群中的曲线,将李群中的动作曲线映射到它的李代数上,形成一个向量空间。然后结合线性支持向量机进行分类。Koniusz等人(2016)使用张量表示来捕捉3维人体关节之间的高阶关系,用于动作识别,该方法采用两种不同的核,称为序列相容核和动态相容核。前者捕捉关节的时空相容性,后者则模拟序列的动作动力学。然后在这些核的线性化特征映射上训练支持向量机进行动作分类。
4.2 基于深度学习的方法
Liu等人(2016)通过对骨架序列进行树结构的遍历,获得了空间域的隐藏关系。其他方法进行关节遍历只是把骨架作为一条链,忽略了相邻关节之间存在的依赖关系,而此遍历方法不会增加虚假连接。同时使用带信任门的长短期记忆网络(long short-term memory, LSTM)对输入进行判别,通过潜在的空间信息来更新存储单元。Caetano等人(2019)提出了一种基于运动信息的新表示,称为SkeleMotion。它通过计算骨骼关节的大小和方向值来编码形成每行的动作信息和每列的描述时间信息,形成调整后的骨骼图像。
然而,人类3维骨骼数据是一个拓扑图,而不是基于RNN(recurrent neural network)或CNN的方法处理的序列向量或伪图像,而图卷积网络(graph convolution network,GCN)具有天生处理图结构的优势,使得它在基于骨骼的行为识别技术取得了重大突破。基于图卷积的行为识别技术关键在于骨骼的表示,即如何将原始数据组织成拓扑图。Yan等人(2018)首先提出了一种新的基于骨架的动作识别模型,即时空图卷积网络(spatial-temporal graph convolutional networks,ST-GCN),该网络首先将人的关节作为时空图的顶点,将人体物理关节连接和时间作为图的边;然后使用ST-GCN网络进行信息的传递汇集,获取高级的特征图,并用Softmax分类器划分为对应的类别。
在此基础上,Li等人(2019)提出的AS-GCN(actional-structural graph convolutional networks)不仅可以识别人的动作,而且可以利用多任务学习策略输出对物体下一个可能姿势的预测。构造的拓扑图通过动作连接和结构连接的两个模块来捕捉关节之间更丰富的相关性。Shi等人(2020)提出了一种新的多流注意增强自适应图卷积神经网络来进行基于骨架的动作识别。模型中的图拓扑可以基于输入数据以端到端的方式统一或单独地学习。这种数据驱动的方法增加了图形构造模型的灵活性,使其更具有通用性,以适应各种数据样本。同时关节差值和帧间差值的数据构造多流网络,在决策阶段融合,实现识别率的进一步提升。Obinata和Yamamoto (2021)从另一角度注意到帧间的拓扑图,不仅仅在帧间同一关节对应的顶点之间进行连接,在帧间多个相邻顶点之间添加连接,并提取额外的特征,实现识别率的提高。改进拓扑图后的识别效果理想,使得后续的许多研究都着重于这一点,如设计动态可训练拓扑图(Ye等,2020)、各通道独享的拓扑图(Cheng等,2020a)以及结合全局和局部的拓扑图(Chen等,2021a)。
如图 10所示,空间图卷积过程是离重心(3号下方的最小点)近的3号近心点和离重心远的6号和7号远心点通过骨骼连接向5号根节点传递信息,如此反复,获得提取空间特征;时间卷积是将同一关节在时间维度上进行信息汇集,即同一关节的部分帧序列进行信息汇集,得到时间特征。骨架序列的时空图表示是图卷积网络(GCN)的扩展,专门用于执行人类行为识别。首先,通过在人体骨架的相邻身体关节之间以及沿时间方向插入边来构造时空图。然后,应用GCN和分类器来推断图中的依赖关系并进行分类。

图卷积作为基于骨骼数据的行为识别的热点研究之一,其数据形式——拓扑图十分契合人体骨骼图,特征和信息的获取与传递在物理结构和语义层面都符合图结构,因此取得了较为理想的效果。但图结构也成为行为识别的限制,如坐标的分布会影响图卷积的鲁棒性,缺失一些重要的关节点会降低识别的效果。另外,图卷积将每个关节点视为图中的一个点,其复杂性和人数成正比,而现实中的许多动作涉及多人以及相关物体。成倍增加的计算消耗量使得图卷积难以在多人动作的任务上实现较好的应用。
5 基于数据融合的行为识别方法
RGB数据、深度数据和骨骼数据具有各自的优点。RGB数据的优点是外观信息丰富,深度数据的优点是不易受光照影响,骨骼数据的优点是通过关节能更准确地描述动作。所以,选择哪种模态进行行为识别也是研究人员权衡的方面之一。根据汇集的文献资料,本文总结了各类模态的特点和适用场景,如表 2所示。
表 2
各模态的优缺点和适用场景
Table 2
The advantages and disadvantages of each modal and the applicable scene
| 模态 | 优点 | 缺点 | 适用场景 |
| RGB | 成本低,易采集;丰富的外观信息;应用范围广 | 对光照、背景和视角变化十分敏感 | 无关内容较少,单一的场景 |
| 深度 | 提供了3维的结构信息和形状信息;对光照具有鲁棒性 | 缺少颜色和纹理信息;存在距离的限制;易受遮挡物的影响 | 昏暗或光亮,近距离、没有遮挡物的场景 |
| 骨骼 | 提供人体的姿态3维信息;表达方式简单有效;对视角和背景不敏感 | 缺少外观信息和形状信息;表示内容稀疏;信息嘈杂 | 能够有效提取骨骼关键点的场景 |
由于单模态始终存在一些问题,研究者尝试使用多种方式进行特征融合,克服这些问题。融合方式有3种:特征层融合、决策层融合和混合融合。不同的方式融合结果具有各自的优点,弥补缺点,得到对运动的动作有更好的描述。
5.1 基于RGB模态与深度模态的融合方法
根据模态产生的时间顺序,RGB模态与深度模态的融合是最先提出也是最为普遍的组合方式。Jalal等人(2017)从连续的深度图序列中分割人体深度轮廓,并提取4个骨骼关节特征和一个体形特征形成时空多融合特征,利用多融合特征的编码向量进行模型训练。Yu等人(2020)使用卷积神经网络分别训练多模态数据,并在适当位置进行RGB和深度特征的实时融合,通过局部混合的合成获得更具代表性的特征序列,提高了相似行为的识别性能。同时引入了一种改进的注意机制,实时分配不同的权值来分别关注每一帧。Ren等人(2021)设计了一个分段协作的卷积网络(segment cooperative ConvNets, SC-ConvNets)来学习RGB-D模式的互补特征,整个网络框架如图 11所示。首先将整个RGB和深度数据序列压缩成动态图像分别输入双流卷积网络中,再计算距离的平方值获得融合的特征。与先前基于卷积网络的多通道特征学习方法不同,这个分段协作的网络能够联合学习,通过优化单个损失函数,缩小了RGB和深度模态之间的差异, 进而提高了识别性能。

深度模态没有RGB模态的纹理和颜色信息,RGB模态比深度模态在空间上少一个深度信息的维度,因此两者的数据模态可以很好地互补对方缺失的特征信息。大量研究结果表明了此种融合方法的合理性和优越性。因此提取另一个模态缺少的信息,避免相同信息的冗余,是模态融合的重点和难点。
5.2 其他模态的融合方法
其他模态的关系,如骨骼模态与深度模态互补关系,稍弱于RGB和深度模态的互补关系。但不同模态仍有互补信息的存在,所以不同模态融合也是研究人员的研究方向之一。Elmadany等人(2018)使用规范相关分析(canonical crrelation analysis,CCA)来最大化从不同传感器提取的特征的相关性。此论文研究的特征包括从骨架数据中提取的角度数据、从深度视频中提取的深度运动图和从RGB视频提取的光流数据,通过学习这些特征共享的子空间,再使用平均池化来获取最终的特征描述符。Rahmani等人(2014)提出一种称为深度梯度直方图的描述子,结合深度图像和3维关节位置提取的4种局部特征来处理局部遮挡,分别计算深度、深度导数和关节位置差的直方图,将每个关节运动量的变化并入全局特征向量中,形成时空特征,并使用两个随机决策森林,一个用于特征修剪,另一个用于分类,提高识别的精度。
特征可以在初级阶段融合,也可以在高级阶段形成语义信息的时期融合。前者相当于对数据进行补充增广,后者形成新的语义信息。融合也可以发生在决策阶段,联合不同模态的预测结果后得到一个综合的预测结果。一般而言,越早期的模态融合需要的计算量越小,越后期的模态融合复杂度越大。研究者常常使用混合折中的方法,保持两者优势的同时,也克服了一些缺点。融合的具体方式及其优缺点如表 3所示。对于神经网络,不同模态的融合可以在特征提取阶段,可以将多流网络的输出汇集到单个网络中实现特征融合。融合的关键在于数据模态的选择和融合的时间。研究者需要思考一种模态融入另一种模态后的特征是否克服了原有模态的缺点,否则融合操作只会增加计算量。
表 3
不同融合方法的优缺点
Table 3
Advantages and disadvantages of different fusion methods
| 融合方式 | 优点 | 缺点 |
| 特征层融合 | 可选择的融合阶段灵活;复杂度较小 | 数据冗余,模态融合的阶段会直接影响互补性的利用 |
| 决策层融合 | 模态之间互相独立,错误无法互相影响;实现容易 | 计算量较大 |
| 混合融合 | 十分灵活,既能结合特征提取阶段前期后期的特征,也能结合决策层融合的方法 | 设计不当可能导致上述两者的缺点同时产生 |
6 行为识别方法对比
对不同数据模态下的行为识别方法进行比较,通过表格和柱状图等方式的对比,以期得出一些行为识别技术的结论。
Top-1代表概率最大的结果是正确答案的准确率,Top-5代表概率排名前5的结果是正确答案的准确率。交叉主题(cross subject)和交叉视角(cross view)是NTU RGB+D 60数据集中训练集和测试集的划分。交叉主题将40个志愿者划分为训练和测试两个队伍。每个队伍包含20个志愿者,其中1,2,4,5,8,9,13,14,15,16,17,18,19,25,27,28,31,34,35,38为训练集,其余为测试集。交叉视角将3个视角的相机中,相机2号和3号作为训练集,相机1号为测试集。NTU RGB+D 120中的训练集和测试集划分方式包括交叉主题(cross subject)和交叉设置(cross setup)两种。交叉主题表示训练集包含53个主题,测试集包含另外53个主题。交叉设置表示训练集样本来自偶数编号,测试集样本来自奇数编号。
6.1 RGB模态的方法对比
RGB模态数据集选取了经典的UCF101数据集和HMDB-51数据集,以及新颖的Something-Something数据集,对比了经典方法和新发表的效果最佳的方法,如表 4和表 5所示。
表 4
HMDB-51和UCF101数据集上的算法准确率对比
Table 4
Accuracies comparison of algorithms in HMDB-51 and UCF101 datasets
| /% | |||||||||||||||||||||||||||||
| 方法 | 深度学习 | HMDB-51 | UCF101 | ||||||||||||||||||||||||||
| actionlet ensemble (Wang等,2012) | 否 | 40.7 | - | ||||||||||||||||||||||||||
| iT(action recognition with improved trajectories) (Wang和Schmid,2013) | 否 | 60.1 | 86.0 | ||||||||||||||||||||||||||
| iDT(action detection with improved dense trajectories) (Shu等,2015) | 否 | 57.2 | 85.9 | ||||||||||||||||||||||||||
| TSN(temporal segment networks) (Wang等,2016) | 否 | 61.7 | 88.3 | ||||||||||||||||||||||||||
| STAP(spatial-temporal attention-aware pooling) (Nguyen等,2015) | 是 | 78.7 | 97.1 | ||||||||||||||||||||||||||
| Motion Hierarchies(Gaidon等,2014) | 是 | 63.5 | 93.2 | ||||||||||||||||||||||||||
| Embedding(Ye和Tian,2016) | 是 | 55.2 | 85.4 | ||||||||||||||||||||||||||
| 2s-R-CNN(Peng和Schmid,2016) | 是 | - | 78.9 | ||||||||||||||||||||||||||
| CRSN(cooperative cross-stream network) (Zhang等,2019) | 是 | 81.9 | 97.4 | ||||||||||||||||||||||||||
| Motionsqueeze(Kwon等,2020) | 是 | 77.4 | - | ||||||||||||||||||||||||||
| LSTR(learning spatio-temporal representation) (Qiu等,2019) | 是 | 80.5 | 98.2 | ||||||||||||||||||||||||||
| LTM(late temporal modeling) (Kalfaoglu等,2020) | 是 | 85.1 | 98.7 | ||||||||||||||||||||||||||
| 注:分隔号“-”表示不存在该项实验数据。 | |||||||||||||||||||||||||||||
表 5
Something-Something v2数据集上的算法准确率对比
Table 5
Accuracies comparison of algorithms in Something-Something v2 dataset
| 方法 | 深度学习 | Something-Something v2 | |
| Top-1准确率/% | Top-5准确率/% | ||
| TSM(temporal shift module)(Lin等,2019) | 是 | 66.6 | 91.3 |
| STM(spatiotemporal and motion encoding) (Jiang等,2019) | 是 | 64.2 | 89.8 |
| DTA(diverse temporal aggregation)(Lee等,2021) | 是 | 67.35 | 90.5 |
| MML(mutual modality learning) (Komkov等,2020) | 是 | 69.02 | 92.7 |
| Motionsqueeze(Kwon等,2020) | 是 | 66.6 | 90.6 |
| PAN(persistence of appearance)(Zhang等,2020a) | 是 | 66.5 | 90.6 |
| Mformer-L(Patrick等,2021) | 是 | 68.1 | 91.2 |
| MViT(multiscale vision transformers) (Fan等,2021b) | 是 | 68.7 | 91.5 |
| Swin Transformer(刘云等,2021) | 是 | 69.6 | 92.7 |
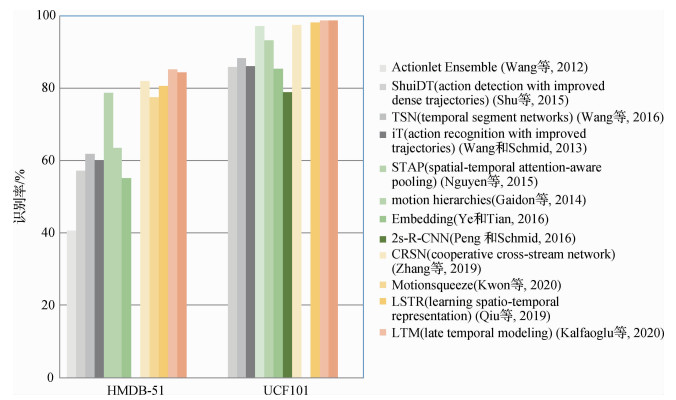
对于HMDB-51数据集,手工特征方法的准确率最高仅有61.7%,而深度学习方法的最低准确率是55.2%。基于深度学习的方法将该数据集的最高准确率提高到85.1%。对于UCF101数据集,手工特征方法的最高准确率88.3%,基于深度学习的方法将准确率提高到98.7%,已经基本符合应用的要求。在Something-Something数据集上,手工特征法鲜有研究,大都是基于深度学习方法的开展。原因是该数据集规模较大,手工制作的特征已经无法准确地描述动作。而且动作类别多,使得Top-1的最高识别率仅有69%,是RGB模态的行为识别方向下一个需要攻克的数据集。
根据大量文献和实验的依据,本文总结了两类方法的优缺点如表 6所示。
表 6
手工特征和深度学习的优缺点
Table 6
The advantages and disadvantages of manual features and deep learning
| 方法 | 优点 | 缺点 |
| 手工特征 | 适合小型数据集,速度快 | 需要一定的先验知识设计特征 |
| 深度学习 | 适合大型数据集,特征通过网络学习获得 | 速度较慢,硬件要求较高 |
本文将统计的数据绘制成柱状图,从图 12中能明显观察出,基于手工特征的方法(灰色表示的柱状)基本低于深度学习方法的识别率(灰色以外的其他颜色),说明深度学习的方法一般具有更好的识别性能。类似的情况也发生在其他模态中。
6.2 深度模态的方法对比
深度模态数据集选取了经典的MSR-Action3D数据集与当前主流的NTU RGB+D深度数据集,和RGB模态的实验思路相同,比较了经典算法和最新卓越方法,结果如表 7和表 8所示。
表 7
MSR-Action3D深度数据集上的算法准确率对比
Table 7
Accuracies comparison of algorithms in MSR-Action3D depth dataset
| /% | |||||||||||||||||||||||||||||
| 方法 | 深度学习 | MSR-Action3D | |||||||||||||||||||||||||||
| DMM-HOG(depth motion maps-based histograms of oriented gradients) (Yang等,2012) | 否 | 88.7 | |||||||||||||||||||||||||||
| HON4D(histogram of oriented 4D normals) (Oreifej和Liu,2013) | 否 | 88.9 | |||||||||||||||||||||||||||
| Holistic HOPC(histogram of oriented principal components)(Rahmani等,2016) | 否 | 86.5 | |||||||||||||||||||||||||||
| SEMP(skeleton embedded motion body partition)(Ji等,2018) | 否 | 90.8 | |||||||||||||||||||||||||||
| GLOSJ(global and local offsets of skeleton joints) (Sun等,2019) | 否 | 83.6 | |||||||||||||||||||||||||||
| CNN-DSD(convolutional neural network and depth sensor data) (Ahmad等,2019) | 否 | 87.1 | |||||||||||||||||||||||||||
| LPDMI(Laplacian pyramid depth motion images) (Li等,2021) | 否 | 93.4 | |||||||||||||||||||||||||||
| DMM-GLAC(depth motion maps-gradient local auto-correlations) (Chen等,2015a) | 是 | 88.9 | |||||||||||||||||||||||||||
| PointNet++(Qi等,2017) | 是 | 61.61 | |||||||||||||||||||||||||||
| BGLP-CAA(biset/multiset globality locality preserving canonical correlation analysis) (Elmadany等,2018) | 是 | 92.3 | |||||||||||||||||||||||||||
| CNN-HCF(convolutional neural network hand-crafted features) (Trelinski等,2019) | 是 | 90.6 | |||||||||||||||||||||||||||
| MeteorNet(Liu等,2019) | 是 | 88.50 | |||||||||||||||||||||||||||
| P4Transformer(Fan等,2021b) | 是 | 90.94 | |||||||||||||||||||||||||||
| STACOG(space-time auto-correlation of gradients) (Bulbul等,2021) | 是 | 93.4 | |||||||||||||||||||||||||||
表 8
RGB+D 60深度数据集上的算法准确率对比
Table 8
Accuracies comparison of algorithms in NTU RGB+D 60 depth dataset
| /% | |||||||||||||||||||||||||||||
| 方法 | 深度学习 | NTU RGB+D 60深度 | |||||||||||||||||||||||||||
| 交叉主题 | 交叉视角 | ||||||||||||||||||||||||||||
| HON4D(histogram of oriented 4D normals) (Oreifej和Liu,2013) | 否 | 30.6 | 7.3 | ||||||||||||||||||||||||||
| HOG2(histogram of oriented gradients2)(Ohn-Bar和Trivedi,2013) | 否 | 32.2 | 22.3 | ||||||||||||||||||||||||||
| SNV(super normal vector)(Yang和Tian,2014) | 否 | 31.8 | 13.6 | ||||||||||||||||||||||||||
| PointNet++(Qi等,2017) | 是 | 80.1 | 85.1 | ||||||||||||||||||||||||||
| v-iAR(view-invariant action representations)(Li等,2018) | 是 | 68.1 | 83.4 | ||||||||||||||||||||||||||
| DPl-s3d(depth pooling based large-scale 3D)(Wang等,2018a) | 是 | 87.1 | 84.2 | ||||||||||||||||||||||||||
| MVDI(multi-view dynamic images) (Xiao等,2018) | 是 | 84.6 | 87.3 | ||||||||||||||||||||||||||
| 3D dynamic voxel-PointNet++(Wang等,2020) | 是 | 88.8 | 96.3 | ||||||||||||||||||||||||||
| P4Transformer(Fan等,2021a) | 是 | 90.2 | 96.4 | ||||||||||||||||||||||||||
| GeometryMotion-Net(Liu和Xu,2021) | 是 | 92.7 | 98.9 | ||||||||||||||||||||||||||
当前的多数方法已经在MSR-Action3D深度数据集上达到了90%的准确率,说明该数据集的大部分价值已被挖掘,但MSR-Action3D仍然是评价一个算法好坏的经典数据集之一。近期主流的数据集是NTU RGB+D数据集中的深度模态部分,深度数据模态的人体行为数据集相较其他两个模态发布较少,在这方面还有很大的进步空间。
在NTU RGB+D数据集的深度模态部分,手工特征的方法在这个大型数据集上效果较差。原因与RGB模态的情况相似,该数据集规模大、样本多、类别多,手工制作的特征能表示部分动作信息,但难以覆盖整个数据集的动作范围。两个新发布的网络的变体:点云网络(PointNet++)和Transformer网络,在NTU RGB+D深度模态部分的识别率达到了近90%和90.2%的高度。研究者可以从不同的角度改进这两个网络,可能会达到新的性能高度。这也给了研究者另一种想法,通过移植或者改进领域外的新颖网络,适配到行为识别方向中,或许能取得意想不到的效果。
6.3 骨骼模态的方法对比
骨骼模态是近年越发流行的模态,本文选取了主流的NTU RGB+D skeleton骨骼数据集,对比了许多算法的差异。
在NTU RGB+D 60和120数据集的实验设置下,手工特征和深度学习的方法对比如表 9和表 10所示。深度学习的方法全面超越了手工特征方法。从中可发现,基于深度学习的方法几乎占据了全部范围。其中,早期研究者多使用标准卷积网络将骨骼数据编码成像素排列的伪图像,借鉴图像分类和视频分类的思想提取特征。这种方式取得的效果并不理想,因为它割裂了骨骼内在的连接性。之后,提出了卷积网络的变体——图卷积。由于图的结构十分符合人体骨骼连接,取得了理想的效果,也促进了图卷积在行为识别领域中快速发展。本文发现,初期研究者往往仅考虑识别率的高低,忽略了算法和模型的复杂度。
表 9
RGB+D 60骨骼数据集上的算法准确率对比
Table 9
Accuracies comparison of algorithms in NTU RGB+D 60 skeleton dataset
| /% | |||||||||||||||||||||||||||||
| 方法 | 深度学习 | NTU RGB+D 60骨骼 | |||||||||||||||||||||||||||
| 交叉主题 | 交叉视角 | ||||||||||||||||||||||||||||
| Lie group(Vemulapalli等,2014) | 否 | 50.1 | 52.8 | ||||||||||||||||||||||||||
| Skeletal quads (Evangelidis等,2014) | 否 | 38.6 | 41.4 | ||||||||||||||||||||||||||
| ST-GCN(spatial temporal graph convolutional networks) (Yan等,2018) | 是 | 81.5 | 88.3 | ||||||||||||||||||||||||||
| DGNN(directed graph neural networks) (Shi等,2019) | 是 | 89.9 | 96.1 | ||||||||||||||||||||||||||
| MS-AAGCN(multi-stream adaptive graph convolutional networks)(Shi等,2020) | 是 | 90.0 | 96.2 | ||||||||||||||||||||||||||
| DC-GCN(decoupling graph convolutional networks) (Cheng等,2020a) | 是 | 90.8 | 96.6 | ||||||||||||||||||||||||||
| shift-GCN(shift graph convolutional networks)(Cheng等,2020b) | 是 | 90.7 | 96.5 | ||||||||||||||||||||||||||
| Dynamic GCN(Ye等,2020) | 是 | 91.5 | 96.0 | ||||||||||||||||||||||||||
| DDGCN(dynamic directed graph convolutional networks) (Korban和Li,2020) | 是 | 91.1 | 97.1 | ||||||||||||||||||||||||||
| MST-GCN(multi-scale spatial temporal graph convolutional networks) (Chen等,2021b) | 是 | 91.5 | 96.6 | ||||||||||||||||||||||||||
| EfficientGCN(Song等,2022) | 是 | 91.7 | 95.7 | ||||||||||||||||||||||||||
| CTR-GCN(channel-wise topology refinement graph convolutional networks)(Chen等,2021a) | 是 | 92.4 | 96.8 | ||||||||||||||||||||||||||
| PoseC3D(Duan等,2022) | 是 | 94.1 | 97.1 | ||||||||||||||||||||||||||
表 10
RGB+D 120骨骼数据集上的算法准确率对比
Table 10
Accuracies comparison of algorithms in NTU RGB+D 120 skeleton dataset
| /% | |||||||||||||||||||||||||||||
| 方法 | 深度学习 | NTU RGB+D 120骨骼 | |||||||||||||||||||||||||||
| 交叉主题 | 交叉视角 | ||||||||||||||||||||||||||||
| ST-GCN(Yan等,2018) | 是 | 79.7 | 81.3 | ||||||||||||||||||||||||||
| DC-GCN(Cheng等,2020a) | 是 | 86.5 | 88.1 | ||||||||||||||||||||||||||
| MS-G3D(multi-scale graph convolutional networks)(Liu等,2020b) | 是 | 86.9 | 88.4 | ||||||||||||||||||||||||||
| shift-GCN(Cheng等,2020b) | 是 | 85.9 | 87.6 | ||||||||||||||||||||||||||
| Dynamic GCN(Ye等,2020) | 是 | 87.3 | 88.6 | ||||||||||||||||||||||||||
| EfficientGCN(Song等,2022) | 是 | 88.3 | 89.1 | ||||||||||||||||||||||||||
| PoseC3D(Duan等,2022) | 是 | 86.9 | 90.3 | ||||||||||||||||||||||||||
| CTR-GCN(Chen等,2021a) | 是 | 88.9 | 90.6 | ||||||||||||||||||||||||||
统计在骨骼模态上相关模型的训练参数量后如表 11所示。以ST-GCN为基础,科研人员通过加深模型层次和改进模型结构,设计出AS-GCN、2S-GCN等优秀模型。虽然提高了识别性能,但是模型越来越庞大,识别率也达到了瓶颈。意识到这一问题后,研究人员开始设计更轻量的网络,如MS-G3D、Dynamic GCN、CTR-GCN等。在达到相同识别效果的同时,设计了复杂度更小、训练速度更快的网络。从模型优化的角度进一步发展了行为识别技术。
表 11
不同模型的训练参数量对比
Table 11
Contrasts of training parameter quantities for different models
| 模型 | 训练参数量/M |
| ST-GCN(Yan等,2018) | 3.1 |
| Richly Activated-GCN(Song等,2019) | 6.21 |
| AS-GCN(Li等,2019) | 6.99 |
| 2 s-AGCN(Shi等,2020) | 6.94 |
| Semantics-guidedGCN(Zhang等,2020b) | 1.8 |
| Part-wise Attention-ResGCN(Song等,2022) | 3.26 |
| MS-G3D(Liu等,2020b) | 3.2 |
| Dynamic GCN(Ye等,2020) | 1.73 |
| CTR-GCN(Chen等,2021a) | 1.46 |
图卷积的应用将NTU RGB+D 60骨骼数据库的交叉识别率从50%快速提升至88%。经过科研人员的不断努力研究,目前交叉主题和交叉视角的最高识别率已经达到94.1%和97.1%。在NTU RGB+D 60数据集上已经基本完成行为识别的任务。在NTU RGB+D 120数据集,动作类别数更多,更加有挑战性和难度。目前的最高识别率只有90%左右。所以,NTU RGB+D 120数据集是目前最全面和权威评价一个算法和模型好坏的数据集。希望相关人员能首先考虑以该数据集作为基准,通过数据驱动行为识别的进一步发展。
本文发现,越高的识别率增长的幅度越小。这也从侧面反映了图卷积在行为识别领域达到了一定的瓶颈期。从本文数据模态的角度出发,有以下两点建议:1)融合其他模态的数据,补充骨骼数据的信息,进而获得更好的结果。2)使用一种新的方式代替拓扑图表示骨骼的信息,便于提取更多的动作特征。
6.4 多模态融合的方法对比
NTU RGB+D包括了RGB、深度和骨骼模态,选择该数据集作为基准对比不同的算法,结果如表 12所示。
表 12
NTU RGB+D 60数据集上多模态融合算法的识别率对比
Table 12
Accuracies comparison of modal fusion algorithms in NTU RGB+D 60 dataset
| /% | |||||||||||||||||||||||||||||
| 方法 | 深度学习 | 模态 | NTU RGB+D 60 | ||||||||||||||||||||||||||
| 交叉主题 | 交叉视角 | ||||||||||||||||||||||||||||
| TSN(temporal segment networks)(Wang等,2016) | 是 | RGB+深度 | 84.5 | 86.5 | |||||||||||||||||||||||||
| Pose-drive Attention(Baradel等,2018) | 是 | RGB | 75.6 | 80.5 | |||||||||||||||||||||||||
| Pose-drive Attention(Baradel等,2018) | 是 | 骨骼 | 77.1 | 84.5 | |||||||||||||||||||||||||
| Pose-drive Attention(Baradel等,2018) | 是 | RGB+骨骼 | 84.8 | 90.6 | |||||||||||||||||||||||||
| Deep Bilinear(Hu等,2018) | 是 | RGB+深度 | 79.2 | 81.1 | |||||||||||||||||||||||||
| Deep Bilinear(Hu等,2018) | 是 | RGB +骨骼 | 83.0 | 87.1 | |||||||||||||||||||||||||
| Deep Bilinear(Hu等,2018) | 是 | RGB+深度+骨骼 | 85.4 | 90.7 | |||||||||||||||||||||||||
| DSSCA-SSLM(Shahroudy等,2016b) | 是 | RGB+深度+骨骼 | 74.9 | - | |||||||||||||||||||||||||
| Cooperativec-ConvNets(Wang等,2018b) | 是 | RGB+深度 | 86.4 | 89.1 | |||||||||||||||||||||||||
| HAC(hierarchical action classification)(Davoodikakhki和Yin,2020) | 是 | RGB +骨骼 | 95.66 | 98.79 | |||||||||||||||||||||||||
| Video-Pose Net, VPN(Das等,2020) | 是 | RGB +骨骼 | 90.8 | 93.8 | |||||||||||||||||||||||||
| VPN++(Das等,2021) | 是 | RGB +骨骼 | 94.9 | 98.1 | |||||||||||||||||||||||||
| Spatial Cooperative-ConvNets(Ren等,2021) | 是 | RGB+深度 | 89.4 | 91.2 | |||||||||||||||||||||||||
| 注:“-”表示不存在该实验数据。 | |||||||||||||||||||||||||||||
选取其中的两个方法Pose-drive Attention和Deep Bilinear作为代表,比较其在不同模态下的识别率。从表 13中可以清楚地观察到,对于Pose-drive Attention模型,RGB和骨骼模态融合的识别率明显高于RGB或者骨骼单个模态的识别率。对于Deep Bilinear模型,3个模态融合后的识别率高于两个模态融合的识别率。因此,融合多个模态的方法十分有利于行为识别的效果提升。
表 13
单模态和多模态融合的识别效果比较
Table 13
Comparison of the recognition efficacy of single-modal and multimodal fusion
| /% | |||||||||||||||||||||||||||||
| 方法 | 交叉主题 | 交叉视角 | |||||||||||||||||||||||||||
| RGB(pose-drive attention) | 75.6 | 80.5 | |||||||||||||||||||||||||||
| 骨骼(pose-drive attention) | 77.1 | 84.5 | |||||||||||||||||||||||||||
| RGB+骨骼(pose-drive attention) | 84.8 | 90.6 | |||||||||||||||||||||||||||
| RGB+深度(deep bilinear) | 79.2 | 81.1 | |||||||||||||||||||||||||||
| RGB +骨骼(deep bilinear) | 83 | 87.1 | |||||||||||||||||||||||||||
| RGB+深度+骨骼(deep bilinear) | 85.4 | 90.7 | |||||||||||||||||||||||||||
| 注:加粗字体为融合模态后的最优值。 | |||||||||||||||||||||||||||||
最常用的组合是RGB模态和深度模态,原因是由于深度模态比RGB模态多了深度信息,而RGB模态比深度模态多了颜色纹理信息,两者能较好地互补信息,从而提取到描述更好的特征,达到提高识别率的效果。其次是骨骼和其他模态的组合,由于骨骼数据在早期较难与其他模态融合,研究者一般都选择在高维特征阶段进行融合,实现信息的互补。
最后,本文从各类模态内部比较和各类模态之间比较发现了一些规律和特点。骨骼模态数据和RGB模态数据是人体行为识别中使用较多的模态。在各类模态下,深度学习的方法一般都优于手工特征的方法,这是因为深度学习提取的特征基于数据集本身的数据信息,相较于手工特征,深度学习获得的特征更加准确地描述了动作。通过融合不同数据模态的特征或者决策层融合,实现信息互补,达到更优异的效果。
7 结语
目前,行为识别在一些数据集上的识别率已经很高,在日常生活中也有一些应用。但是行为识别仍然存在许多挑战。1)数据集的规模越来越大,环境越来越复杂,愈发符合现实场景。物体遮挡、视频的像素值和帧数、交互运动以及图像的多尺寸等因素,都会极大地影响识别过程。2)尽管目前有许多模态的数据,但并非所有模态的数据都易采集。RGB模态是能够利用一般相机直接获得,深度模态需要深度传感器(如Kinect相机)获得,而骨骼模态是从前两者模态中抽象得到的一种描述人体行为的模态数据。3)特殊动作的识别包括相似动作的识别、多人动作的识别以及高速动作的识别。对于这些挑战,研究者还需不断探索,寻找解决问题的方案。
本文总结了一些行为识别领域在未来可行的研究方向:1)多模态融合是一个具有前景的研究方向。无论是在特征层的特征融合,或者在预测阶段的决策融合,都已经被证明是一个可行的方案。除了上述所提的主流模态外,一些模态(如红外线、声音)等信息也能够融合其中,实现信息补充,提高识别性能。2) 深度学习网络已经成为主流,符合数据集规模增加的趋势。手工制作的特征并非完全舍弃。研究人员依然可以借鉴制作特征的思想,从视频中提取去除无关信息的手工特征后再输入深度学习的网络中,减少了网络参数,也提高了识别效果。3)设计和移植新型网络,增加注意力模块。自从2D卷积神经网络应用在行为识别领域,识别效果大幅提升。然后,3D卷积神经网络、图卷积网络的应用使识别效果又提升了一个层次。所以,设计新型的网络或者移植其他领域的网络是有参考价值的。同时,注意力模块在网络中愈发广泛应用。注意力模块能够较好地去除时间和空间特征中的无关信息,将重点放在显著区域,进而提升识别准确率。
本文从多模态的角度对行为识别的研究进行了综述,整理了主流的数据集,全面分析了各类模态的行为识别方法,重点分析了特征的设计和网络的结构,最后对比不同算法或网络的效果,总结出一些存在的问题和未来可行的方向。本文的分类结构希望能给初学者提供一个完整的行为识别领域的知识,使相关研究人员能从中获得一些创新的思路和启发。
参考文献
-
Ahmad Z, Illanko K, Khan N and Androutsos D. 2019. Human action recognition using convolutional neural network and depth sensor data//Proceedings of 2019 International Conference on Information Technology and Computer Communications. Singapore, Singapore: ACM: 1-5 [DOI:10.1145/3355402.3355419]
-
Baradel F, Wolf C and Mille J. 2018. Human activity recognition with pose-driven attention to RGB [EB/OL]. [2021-09-02]. https://hal.inria.fr/hal-01828083/document
-
Bobick A F, Davis J W. 2001. The recognition of human movement using temporal templates. IEEE Transactions on Pattern Analysis and Machine Intelligence, 23(3): 257-267 [DOI:10.1109/34.910878]
-
Bulbul M F, Tabussum S, Ali H, Zheng W L, Lee M Y, Ullah A. 2021. Exploring 3D human action recognition using STACOG on multi-view depth motion maps sequences. Sensors, 21(11): #3642 [DOI:10.3390/s21113642]
-
Caetano C, Sena J, Brémond F, Dos Santos J A and Schwartz W R. 2019. SkeleMotion: a new representation of skeleton joint sequences based on motion information for 3D action recognition//Proceedings of the 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS). Taipei, China: IEEE: 1-8 [DOI:10.1109/AVSS.2019.8909840]
-
Carreira J and Zisserman A. 2017. Quo vadis, action recognition? A new model and the kinetics dataset//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE: 4724-4733 [DOI:10.1109/CVPR.2017.502]
-
Carreira J, Noland E, Banki-Horvath A, Hillier C and Zisserman A. 2018. A short note about kinetics-600 [EB/OL]. [2021-09-02]. https://arxiv.org/pdf/1808.01340.pdf
-
Carreira J, Noland E, Hillier C and Zisserman A. 2019. A short note on the kinetics-700 human action dataset [EB/OL]. [2021-09-02]. https://arxiv.org/pdf/1907.06987.pdf
-
Chakraborty B, Holte M B, Moeslund T B, Gonzàlez J. 2012. Selective spatio-temporal interest points. Computer Vision and Image Understanding, 116(3): 396-410 [DOI:10.1016/j.cviu.2011.09.010]
-
Chen C, Jafari R and Kehtarnavaz N. 2015a. UTD-MHAD: a multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor//Proceedings of 2015 IEEE International Conference on Image Processing (ICIP). Quebec City, Canada: IEEE: 168-172 [DOI:10.1109/ICIP.2015.7350781]
-
Chen W B, Guo G D. 2015. TriViews: a general framework to use 3D depth data effectively for action recognition. Journal of Visual Communication and Image Representation, 26: 182-191 [DOI:10.1016/j.jvcir.2014.11.008]
-
Chen Y X, Zhang Z Q, Yuan C F, Li B, Deng Y and Hu W M. 2021a. Channel-wise topology refinement graph convolution for skeleton-based action recognition//Proceedings of 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, Canada: IEEE: 13339-13348 [DOI:10.1109/ICCV48922.2021.01311]
-
Chen Z, Li S C, Yang B, Li Q H and Liu H. 2021b. Multi-scale spatial temporal graph convolutional network for skeleton-based action recognition [EB/OL]. [2021-09-02]. https://www.aaai.org/AAAI21Papers/AAAI-5287.ChenZ.pdf
-
Cheng K, Zhang Y F, Cao C Q, Shi L, Cheng J and Lu H Q. 2020a. Decoupling GCN with dropgraph module for skeleton-based action recognition//Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer: 536-553 [DOI:10.1007/978-3-030-58586-0_32]
-
Cheng K, Zhang Y F, He X F, Chen W H, Cheng J and Lu H Q. 2020b. Skeleton-based action recognition with shift graph convolutional network//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE: 180-189 [DOI:10.1109/cvpr42600.2020.00026]
-
Das S, Sharma S and Dai R. 2020. VPN: learning video-pose embedding for activities of daily living//Proceedings of 2020 European Conference on Computer Vision. Online: Springer: 72-90
-
Das S, Dai R, Yang D and Bremond F. 2021. VPN++: rethinking video-pose embeddings for understanding activities of daily living[EB/OL]. [2021-09-02]. https://arxiv.org/pdf/2105.08141.pdf
-
Davoodikakhki M and Yin K K. 2020. Hierarchical action classification with network pruning//15th International Symposium on Visual Computing. San Diego, USA: Springer: 291-305 [DOI:10.1007/978-3-030-64556-4_23]
-
Duan H D, Zhao Y, Chen K, Lin D H and Dai B. 2022. Revisiting skeleton-based action recognition[EB/OL]. [2021-09-02]. https://arxiv.org/pdf/2104.13586.pdf
-
Elmadany N E D, He Y F, Guan L. 2018. Information fusion for human action recognition via Biset/Multiset globality locality preserving canonical correlation analysis. IEEE Transactions on Image Processing, 27(11): 5275-5287 [DOI:10.1109/tip.2018.2855438]
-
Evangelidis G, Singh G and Horaud R. 2014. Skeletal quads: human action recognition using joint quadruples//Proceedings of the 22nd International Conference on Pattern Recognition. Stockholm, Sweden: IEEE: 4513-4518 [DOI:10.1109/ICPR.2014.772]
-
Fan H H, Yang Y and Kankanhalli M. 2021a. Point 4D transformer networks for spatio-temporal modeling in point cloud videos//Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville, USA: IEEE: 14199-14208 [DOI:10.1109/CVPR46437.2021.01398]
-
Fan H Q, Xiong B, Mangalam K, Li Y H, Yan Z C, Malik J and Feichtenhofer C. 2021b. Multiscale vision transformers[EB/OL]. [2021-09-02]. https://arxiv.org/pdf/2104.11227.pdf
-
Gaidon A, Harchaoui Z, Schmid C. 2014. Activity representation with motion hierarchies. International Journal of Computer Vision, 107(3): 219-238 [DOI:10.1007/s11263-013-0677-1]
-
Gowda S N, Rohrbach M and Sevilla-Lara L. 2020. SMART frame selection for action recognition [EB/OL]. [2021-09-02]. https://arxiv.org/pdf/2012.10671.pdf
-
Goyal R, Kahou S E, Michalski V, Materzynska J, Westphal S, Kim H, Haenel V, Fruend I, Yianilos P, Mueller-Freitag M, Hoppe F, Thurau C, Bax I and Memisevic R. 2017. The "something something" video database for learning and evaluating visual common sense//Proceedings of 2017 IEEE International Conference on Computer Vision. Venice, Italy: IEEE: 5843-5851 [DOI:10.1109/ICCV.2017.622]
-
Hu J F, Zheng W S, Pan J H, Lai J H and Zhang J G. 2018. Deep bilinear learning for RGB-D action recognition//Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer: 346-362 [DOI:10.1007/978-3-030-01234-2_21]
-
Jalal A, Kim Y H, Kim Y J, Kamal S, Kim D. 2017. Robust human activity recognition from depth video using spatiotemporal multi-fused features. Pattern Recognition, 61: 295-308 [DOI:10.1016/j.patcog.2016.08.003]
-
Ji X P, Cheng J, Feng W, Tao D P. 2018. Skeleton embedded motion body partition for human action recognition using depth sequences. Signal Processing, 143: 56-68 [DOI:10.1016/j.sigpro.2017.08.016]
-
Jiang B Y, Wang M M, Gan W H, Wu W and Yan J J. 2019. STM: spatiotemporal and motion encoding for action recognition//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Seoul, Korea (South): IEEE: 2000-2009 [DOI:10.1109/iccv.2019.00209]
-
Kalfaoglu M E, Kalkan S and Alatan A A. 2020. Late temporal modeling in 3D CNN architectures with BERT for action recognition//Proceedings of 2020 European Conference on Computer Vision. Glasgow, UK: Springer: 731-747 [DOI:10.1007/978-3-030-68238-5_48]
-
Klaser A, Marszałek M and Schmid C. 2008. A spatio-temporal descriptor based on 3D-gradients//BMVC 2008-19th British Machine Vision Conference. [s. l. ]: British Machine Vision Association: #99 [DOI:10.5244/C.22.99]
-
Komkov S, Dzabraev M and Petiushko A. 2020. Mutual modality learning for video action classification[EB/OL]. [2021-09-02]. https://arxiv.org/pdf/2011.02543.pdf
-
Koniusz P, Cherian A and Porikli F. 2016. Tensor representations via kernel linearization for action recognition from 3D skeletons//Proceedings of the 14th European Conference on Computer Vision. Amsterdam, the Netherlands: Springer: 37-53 [DOI:10.1007/978-3-319-46493-0_3]
-
Korban M and Li X. 2020. DDGCN: a dynamic directed graph convolutional network for action recognition//Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer: 761-776 [DOI:10.1007/978-3-030-58565-5_45]
-
Kuehne H, Jhuang H, Garrote E, Poggio T and Serre T. 2011. HMDB: a large video database for human motion recognition//Proceedings of 2011 IEEE International Conference on Computer Vision. Barcelona, Spain: IEEE: 2556-2563 [DOI:10.1109/ICCV.2011.6126543]
-
Kwon H, Kim M, Kwak S and Cho M. 2020. MotionSqueeze: neural motion feature learning for video understanding//Proceedings of the 16th European Conference on Computer Vision. Glasgow, UK: Springer: 345-362 [DOI:10.1007/978-3-030-58517-4_21]
-
Lee Y, Kim H I, Yun K and Moon J. 2021. Diverse temporal aggregation and depthwise spatiotemporal factorization for efficient video classification[EB/OL]. [2021-09-02]. https://arxiv.org/pdf/2012.00317.pdf
-
Li C, Huang Q, Li X and Wu Q H. 2021. A multi-scale human action recognition method based on Laplacian pyramid depth motion images//Proceedings of the 2nd ACM International Conference on Multimedia in Asia. Singapore, Singapore: ACM: #31 [DOI:10.1145/3444685.3446284]
-
Li J N, Wong Y, Zhao Q and Mohan S K. 2018. Unsupervised learning of view-invariant action representations [EB/OL]. [2021-09-02]. https://arxiv.org/pdf/1809.01844.pdf
-
Li M S, Chen S H, Chen X, Zhang Y, Wang Y F and Tian Q. 2019. Actional-structural graph convolutional networks for skeleton-based action recognition//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, USA: IEEE: 3590-3598 [DOI:10.1109/CVPR.2019.00371]
-
Li W Q, Zhang Z Y and Liu Z C. 2010. Action recognition based on a bag of 3D points//Proceedings of 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition—Workshops. San Francisco, USA: IEEE: 9-14 [DOI:10.1109/CVPRW.2010.5543273]
-
Lin J, Gan C and Han S. 2019. TSM: temporal shift module for efficient video understanding//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision. Seoul, Korea (South): IEEE: 7082-7092 [DOI:10.1109/iccv.2019.00718]
-
Liu J, Shahroudy A, Perez M, Wang G, Duan L Y, Kot A C. 2020a. NTU RGB+D 120: a large-scale benchmark for 3D human activity understanding. IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(10): 2684-2701 [DOI:10.1109/TPAMI.2019.2916873]
-
Liu J, Shahroudy A, Xu D and Wang G. 2016. Spatio-temporal LSTM with trust gates for 3D human action recognition//Proceedings of the 14th European Conference on Computer Vision. Amsterdam, the Netherlands: Springer: 816-833 [DOI:10.1007/978-3-319-46487-9_50]
-
Liu J H, Xu D. 2021. GeometryMotion-net: a strong two-stream baseline for 3D action recognition. IEEE Transactions on Circuits and Systems for Video Technology, 31(12): 4711-4721 [DOI:10.1109/tcsvt.2021.3101847]
-
Liu X Y, Yan M Y and Bohg J. 2019. MeteorNet: deep learning on dynamic 3D point cloud sequences//Proceedings of 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South): IEEE: 9245-9254 [DOI:10.1109/iccv.2019.00934]
-
Liu Y, Xue P P, Li H, Wang C X. 2021. A review of action recognition using joints based on deep learning. Journal of Electronics and Information Technology, 43(6): 1789-1802 (刘云, 薛盼盼, 李辉, 王传旭. 2021. 基于深度学习的关节点行为识别综述. 电子与信息学报, 43(6): 1789-1802) [DOI:10.11999/JEIT200267]
-
Liu Z, Ning J, Cao Y, Wei Y X, Zhang Z, Lin S and Hu H. 2021. Video swin transformer [EB/OL]. [2021-09-02]. https://arxiv.org/pdf/2106.13230v1
-
Liu Z Y, Zhang H W, Chen Z H, Wang Z Y and Ouyang W L. 2020b. Disentangling and unifying graph convolutions for skeleton-based action recognition//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE: 140-149 [DOI:10.1109/cvpr42600.2020.00022]
-
Nguyen T V, Song Z, Yan S C. 2015. STAP: spatial-temporal attention-aware pooling for action recognition. IEEE Transactions on Circuits and Systems for Video Technology, 25(1): 77-86 [DOI:10.1109/TCSVT.2014.2333151]
-
Obinata Y and Yamamoto T. 2021. Temporal extension module for skeleton-based action recognition//Proceedings of the 25th International Conference on Pattern Recognition (ICPR). Milan, Italy: IEEE: 534-540 [DOI:10.1109/ICPR48806.2021.9412113]
-
Ohn-Bar E and Trivedi M M. 2013. Joint angles similarities and HOG2 for action recognition//Proceedings of 2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Portland, USA: IEEE: 465-470 [DOI:10.1109/cvprw.2013.76]
-
Oreifej O and Liu Z C. 2013. HON4D: histogram of oriented 4D normals for activity recognition from depth sequences//Proceedings of 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, USA: IEEE: 716-723 [DOI:10.1109/CVPR.2013.98]
-
Patrick M, Campbell D, Asano Y M, Misra I, Metze F, Feichtenhofer C, Vedaldi A and Henriques J F. 2021. Keeping your eye on the ball: trajectory attention in video transformers [EB/OL]. [2021-09-02]. https://arxiv.org/pdf/2106.05392.pdf
-
Peng X J and Schmid C. 2016. Multi-region two-stream R-CNN for action detection//Proceedings of the 14th European Conference on Computer Vision. Amsterdam, the Netherlands: Springer: 744-759 [DOI:doi.org/10.1007/978-3-319-46493-0_45]
-
Qi C R, Yi L, Su H and Guibas L J. 2017. PointNet++: deep hierarchical feature learning on point sets in a metric space [EB/OL]. [2021-09-02]. https://arxiv.org/pdf/1706.02413.pdf
-
Qiu Z F, Yao T, Ngo C W, Tian X M and Mei T. 2019. Learning spatio-temporal representation with local and global diffusion//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE: 12048-12057 [DOI:10.1109/CVPR.2019.01233]
-
Rahmani H, Mahmood A, Huynh D Q and Mian A. 2014. Real time action recognition using histograms of depth gradients and random decision forests//Proceedings of 2014 IEEE Winter Conference on Applications of Computer Vision. Steamboat Springs, USA: IEEE: 626-633 [DOI:10.1109/WACV.2014.6836044]
-
Rahmani H, Mahmood A, Huynh D, Mian A. 2016. Histogram of oriented principal components for cross-view action recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(12): 2430-2443 [DOI:10.1109/tpami.2016.2533389]
-
Ren Z L, Zhang Q S, Cheng J, Hao F S, Gao X Y. 2021. Segment spatial-temporal representation and cooperative learning of convolution neural networks for multimodal-based action recognition. Neurocomputing, 433: 142-153 [DOI:10.1016/j.neucom.2020.12.020]
-
Shahroudy A, Liu J, Ng T T and Wang G. 2016a. NTU RGB+D: a large scale dataset for 3D human activity analysis//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, USA: IEEE: 1010-1019 [DOI:10.1109/CVPR.2016.115]
-
Shahroudy A, Ng T T, Gong Y H and Wang G. 2016b. Deep multimodal feature analysis for action recognition in RGB+D videos [EB/OL]. [2021-09-02]. https://arxiv.org/pdf/1603.07120.pdf
-
Shi L, Zhang Y F, Cheng J and Lu H Q. 2019. Skeleton-based action recognition with directed graph neural networks//Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, USA: IEEE: 7904-7913 [DOI:10.1109/cvpr.2019.00810]
-
Shi L, Zhang Y F, Cheng J, Lu H Q. 2020. Skeleton-based action recognition with multi-stream adaptive graph convolutional networks. IEEE Transactions on Image Processing, 29: 9532-9545 [DOI:10.1109/TIP.2020.3028207]
-
Shu Z X, Yun K and Samaras D. 2015. Action detection with improved dense trajectories and sliding window//Proceedings of 2015 European Conference on Computer Vision. Zurich, Switzerland: Springer: 541-551 [DOI:10.1007/978-3-319-16178-5_38]
-
Song Y F, Zhang Z and Wang L. 2019. Richly activated graph convolutional network for action recognition with incomplete skeletons//Proceedings of 2019 IEEE International Conference on Image Processing (ICIP), Taibei, China: IEEE: 1-5
-
Song Y F, Zhang Z, Shan C F and Wang L. 2022. Constructing stronger and faster baselines for skeleton-based action recognition [EB/OL]. [2021-09-02]. https://arxiv.org/pdf/2106.15125.pdf
-
Soomro K, Zamir A R and Shah M. 2012. UCF101: a dataset of 101 human actions classes from videos in the wild [EB/OL]. [2021-09-02]. https://arxiv.org/pdf/1212.0402.pdf
-
Sun B, Kong D H, Wang S F, Wang L C, Wang Y P, Yin B C. 2019. Effective human action recognition using global and local offsets of skeleton joints. Multimedia Tools and Applications, 78(5): 6329-6353 [DOI:10.1007/s11042-018-6370-1]
-
Trelinski J and Kwolek B. 2019. Ensemble of classifiers using CNN and hand-crafted features for depth-based action recognition//Proceedings of the 18th International Conference on Artificial Intelligence and Soft Computing. Zakopane, Poland: Springer: 91-103 [DOI:10.1007/978-3-030-20915-5_9]
-
Vemulapalli R, Arrate F and Chellappa R. 2014. Human action recognition by representing 3D skeletons as points in a lie group//Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE: 588-595 [DOI:10.1109/CVPR.2014.82]
-
Wang H and Schmid C. 2013. Action recognition with improved trajectories//Proceedings of 2013 IEEE International Conference on Computer Vision. Sydney, Australia: IEEE: 3551-3558 [DOI:10.1109/ICCV.2013.441]
-
Wang J, Liu Z C, Wu Y and Yuan J S. 2012. Mining actionlet ensemble for action recognition with depth cameras//Proceedings of 2012 IEEE Conference on Computer Vision and Pattern Recognition. Providence, USA: IEEE: 1290-1297 [DOI:10.1109/CVPR.2012.6247813]
-
Wang L M, Xiong Y J, Wang Z, Qiao Y, Lin D H, Tang X O and Van Gool L. 2016. Temporal segment networks: towards good practices for deep action recognition [EB/OL]. [2021-09-02]. https://arxiv.org/pdf/1608.00859.pdf
-
Wang P, Li W, Wan J, Ogunbona P and Liu X. 2018b. Cooperative training of deep aggregation networks for RGB-D action recognition [EB/OL]. [2021-09-02]. https://arxiv.org/pdf/1801.01080v1.pdf
-
Wang P C, Li W Q, Gao Z M, Tang C, Ogunbona P O. 2018a. Depth pooling based large-scale 3-D action recognition with convolutional neural networks. IEEE Transactions on Multimedia, 20(5): 1051-1061 [DOI:10.1109/TMM.2018.2818329]
-
Wang P C, Li W Q, Gao Z M, Zhang J, Tang C and Ogunbona P. 2015. Deep convolutional neural networks for action recognition using depth map sequences [EB/OL]. [2021-09-02]. https://arxiv.org/pdf/1501.04686.pdf
-
Wang Y C, Xiao Y, Xiong F, Jiang W X, Cao Z G, Zhou J T and Yuan J S. 2020. 3DV: 3D dynamic voxel for action recognition in depth video//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE: 508-517 [DOI:10.1109/CVPR42600.2020.00059]
-
Xia L and Aggarwal J K. 2013. Spatio-temporal depth cuboid similarity feature for activity recognition using depth camera//Proceedings of 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland, USA: IEEE: 2834-2841 [DOI:10.1109/CVPR.2013.365]
-
Xiao Y, Chen J, Wang Y C, Cao Z G, Zhou J T and Bai X. 2018. Action recognition for depth video using multi-view dynamic images[EB/OL]. [2021-09-02]. https://arxiv.org/pdf/1806.11269v2.pdf
-
Yan S J, Xiong Y J and Lin D H. 2018. Spatial temporal graph convolutional networks for skeleton-based action recognition[EB/OL]. [2021-09-02]. https://arxiv.org/pdf/1801.07455.pdf
-
Yang X D and Tian Y L. 2014. Super normal vector for activity recognition using depth sequences//Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, USA: IEEE: 804-811 [DOI:10.1109/CVPR.2014.108]
-
Yang X D, Zhang C Y and Tian Y L. 2012. Recognizing actions using depth motion maps-based histograms of oriented gradients//Proceedings of the 20th ACM International Conference on Multimedia. Nara, Japan: ACM: 1057-1060 [DOI:10.1145/2393347.2396382]
-
Ye F F, Pu S L, Zhong Q Y, Li C, Xie D and Tang H M. 2020. Dynamic GCN: context-enriched topology learning for skeleton-based action recognition//Proceedings of the 28th ACM International Conference on Multimedia. Seattle, USA: ACM: 55-63 [DOI:10.1145/3394171.3413941]
-
Ye Y C and Tian Y L. 2016. Embedding sequential information into spatiotemporal features for action recognition//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Las Vegas, USA: IEEE: 1110-1118 [DOI:10.1109/cvprw.2016.142]
-
Yu J, Gao H, Yang W. 2020. A discriminative deep model with feature fusion and temporal attention for human action recognition. IEEE Access, 8: 43243-43255
-
Zhang C, Zou Y X, Chen G and Gan L. 2020a. Pan: towards fast action recognition via learning persistence of appearance[EB/OL]. [2021-09-02]. https://arxiv.org/pdf/2008.03462.pdf
-
Zhang J R, Shen F M, Xu X and Shen H T. 2019. Cooperative cross-stream network for discriminative action representation [EB/OL]. [2021-09-02]. https://arxiv.org/pdf/1908.10136.pdf
-
Zhang P F, Lan C L, Zeng W J, Xing J L, Xue J R and Zheng N N. 2020b. Semantics-guided neural networks for efficient skeleton-based human action recognition//Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle, USA: IEEE: 1109-1118 [DOI:10.1109/cvpr42600.2020.00119]
-
Zhu Y, Lan Z Z, Newsam S and Hauptmann A. 2018. Hidden two-stream convolutional networks for action recognition//Proceedings of the 14th Asian Conference on Computer Vision. Perth, Australia: Springer: 363-378 [DOI:10.1007/978-3-030-20893-6_23]


